slava是作者参与的一个github开源项目,该项目的目标是用Go语言构建一个高性能K-V云数据库。
在本文中,作者将介绍Slava中内存淘汰策略的实现。Slava中目前实现了四种内存淘汰策略,分别是maxMemoryLruAllKeys,maxMemoryLfuAllKeys,maxMemoryLruTtl和maxMemoryLfuTtl。当内存淘汰被触发时,会根据配置来调用对应的内存淘汰策略,如果是前两者那么将会根据近似LRU或LFU算法从全部的Key中挑选一部分进行淘汰,如果是后两者则只会从设置了过期时间的Key中挑选一部分进行淘汰。下面作者将以回答问题的方式来进行详细介绍。
首先来看LRU(Least recently used,最近最少使用),LRU算法的核心思想是“如果数据最近被访问过,那么将来被访问的几率也高”,所以该算法会选择最近最久没有使用的内容将其淘汰。那么如何实现LRU算法呢?想要淘汰最久没有被使用的数据,那么我们或者需要记录下每个数据的使用时间,或者是维护一个数据结构,该数据结构应该满足两个需求:
(1)通过该数据结构我们能够快速的获取我们想要的最久没有被使用的数据
(2)当我们访问某个数据的时候,需要对该数据结构进行修改并且代价要够低
传统的LRU借助哈希表和双向链表来维护了一个数据结构来满足LRU算法的需求,其详细实现可以参考https://juejin.cn/post/7027062270702125093
如果我们采用传统的实现(哈希表+双向链表),那么会存在两个问题:
(1)内存占用的问题,我们需要一个Map来存储每个Key对应到链表中节点的指针,还需要一个链表来维护所有当前在内存中的数据。
(2)并发安全问题,我们每次对数据进行读或写都需要对链表进行更新操作来维护LRU的正确性,由于Slava采用的是多协程并发进行业务处理的工作方式,那么对链表的操作就需要加锁来保证并发安全。那么在高并发的场景下,协程每次读/写操作都需要获取锁来修改链表,会造成大量的阻塞,过于影响运行效率。所以,这种方法不适合Slava高并发的场景。根据上述分析我们可以知道,像传统实现那样维护一个数据结构来满足需求所带来的性能损耗是难以接受的。
而LFU的传统实现同样需要借助哈希表和链表,或是借助堆,使用传统LFU方法带来的性能损耗同样是难以接受的。
如果我们记录下每个数据最近被访问的时间或是最近被访问的次数,在需要淘汰时遍历数据找出需要淘汰的那个呢?这里首先牵扯到如何记录下每个数据被访问的时间,由于Slava内部k-v数据库对于数据对象的存储方式是将其封装为一个DataEntity对象,也就是在Slava内部数据库中每一个Key都对应了一个DataEntity对象,DataEntity结构体中Data字段被声明为接口类型,从而能够容纳各种数据。我们可以在DataEntity中新增两个字段用于记录数据被访问的最新时间和访问次数。
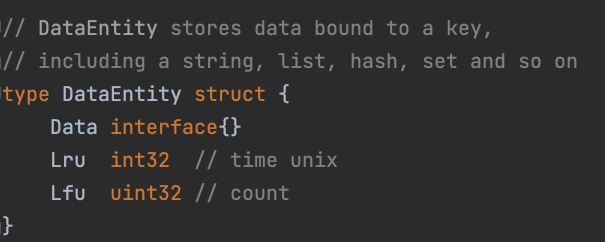
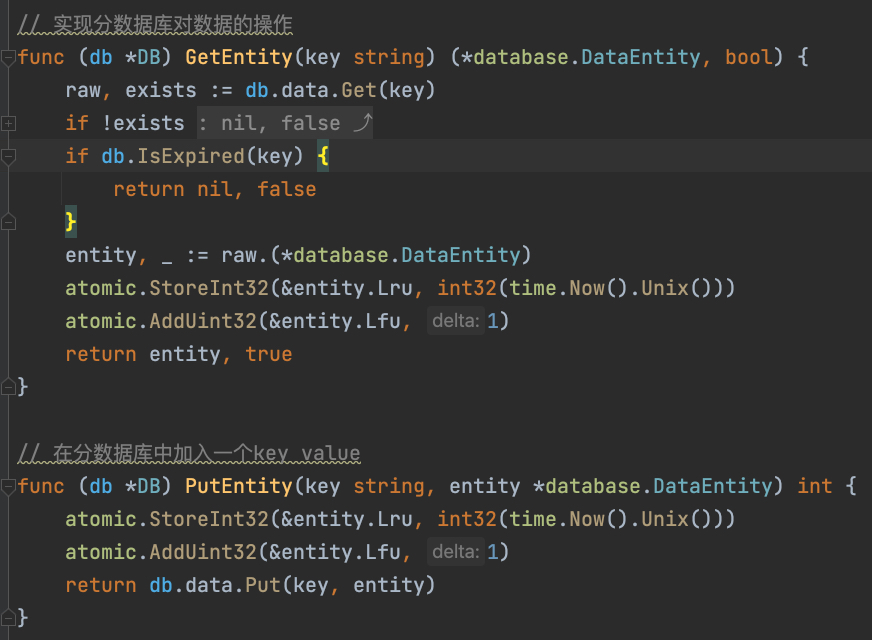
分析到这里可以发现,记录下每个Key最近被访问的时间和次数是可行的,但是在需要淘汰数据时,对所有数据进行遍历的时间开销过大,是难以接受的。综上所述,我们需要近似算法来实现内存淘汰策略。
如何实现近似算法呢?前文已经说过,记录下每个Key最近被访问的时间和次数是可行的。我们是否可以不去遍历所有的Key而只随机挑选一些Key,从这些Key中找出最近访问时间最久的一个或是多个去淘汰呢?
事实上在Redis中,对于LRU和LFU的实现采取的正是类似的近似算法,并且证明了其可行性。https://redis.io/docs/reference/eviction/

由于没删除一个Key就进行一次内存检查太过奢侈,于是作者就结合了Slava自身的特点(内存数据库由多个分库组成),提出了以下方案:每次随机挑选几个分数据库,然后每个数据库都从自己所存储的Key中进行随机挑选,从挑选中的Key中删除一个,之后再检查内存占用,必要情况下循环进行。这么做的优势有以下几点:
func (server *Server) freeMemoryIfNeeded(keyNumsOneRound int, dbNumsOneRound int) {
var memUsed uint64
var memStats runtime.MemStats
for {
runtime.ReadMemStats(&memStats)
//memUsed = memStats.HeapAlloc + memStats.HeapIdle // question
memUsed = memStats.HeapAlloc
// 不需要清除,直接return
if memUsed <= server.maxMemory {
return
}
if dbNumsOneRound > len(server.dbSet) {
dbNumsOneRound = len(server.dbSet)
}
// 挑选需要释放key的db,挑选策略可以更改,目前采用简单的随机方式
dbIds := randomSelectDB(len(server.dbSet), dbNumsOneRound)
var wg sync.WaitGroup
for i := 0; i < dbNumsOneRound; i++ {
slavaDb, _ := server.selectDB(dbIds[i])
// 暂时不支持random 只支持lru和lfu
if server.maxMemoryPolicy == maxMemoryLruAllKeys || server.maxMemoryPolicy == maxMemoryLruTtl {
wg.Add(1)
if server.maxMemoryPolicy == maxMemoryLruTtl {
// ttl
go func() {
defer wg.Done()
approximateLruTtl(slavaDb, keyNumsOneRound)
}()
} else {
go func() {
defer wg.Done()
approximateLruAll(slavaDb, keyNumsOneRound)
}()
}
}
if server.maxMemoryPolicy == maxMemoryLfuAllKeys || server.maxMemoryPolicy == maxMemoryLfuTtl {
wg.Add(1)
if server.maxMemoryPolicy == maxMemoryLfuTtl {
// ttl
go func() {
defer wg.Done()
approximateLfuTtl(slavaDb, keyNumsOneRound)
}()
} else {
func() {
defer wg.Done()
approximateLfuAll(slavaDb, keyNumsOneRound)
}()
}
}
}
// 等待该轮多个db的清除操作完成后再循环
wg.Wait()
}
}
func randomSelectDB(dbNums int, selectNums int) []int {
rand.Seed(time.Now().UnixNano()) // 设置随机数种子,使用当前时间戳
nums := make(map[int]struct{})
for i := 0; i < selectNums; i++ {
num := rand.Intn(dbNums)
if _, ok := nums[num]; !ok {
nums[num] = struct{}{}
}
}
result := make([]int, selectNums)
i := 0
for key := range nums {
result[i] = key
i++
}
return result
}
func approximateLruAll(slavaDb *DB, nums int) {
data := slavaDb.data.(*dict.ConcurrentDict)
keyLruMap := data.RandomDistinctKeysWithTime(nums)
if len(keyLruMap) < 1 {
return
}
var earliestTimestamp int64
var earliestKey string
i := 0
for key, ts := range keyLruMap {
ts64 := int64(ts)
t := time.Unix(ts64, 0)
if i == 0 || t.Before(time.Unix(earliestTimestamp, 0)) {
earliestTimestamp = ts64
earliestKey = key
}
i++
}
slavaDb.Remove(earliestKey)
return
}
func approximateLfuAll(slavaDb *DB, nums int) {
data := slavaDb.data.(*dict.ConcurrentDict)
keyLfuMap := data.RandomDistinctKeysWithCount(nums)
if len(keyLfuMap) < 1 {
return
}
var minimumCount uint32
var minimumKey string
i := 0
for key, count := range keyLfuMap {
if i == 0 || count > minimumCount {
minimumCount = count
minimumKey = key
}
i++
}
slavaDb.Remove(minimumKey)
return
}
func approximateLruTtl(slavaDb *DB, nums int) {
data := slavaDb.data.(*dict.ConcurrentDict)
ttlMap := slavaDb.ttlMap
candidateKeys := ttlMap.RandomDistinctKeys(nums)
if len(candidateKeys) < 1 {
return
}
// len(keyLruMap) 可能小于nums
var earliestTimestamp int64
var earliestKey string
for i, key := range candidateKeys {
val, ok := data.Get(key)
if ok {
ts := int64(val.(*database.DataEntity).Lru)
t := time.Unix(ts, 0)
if i == 0 || t.Before(time.Unix(earliestTimestamp, 0)) {
earliestTimestamp = ts
earliestKey = key
}
}
}
slavaDb.Remove(earliestKey)
return
}
func approximateLfuTtl(slavaDb *DB, nums int) {
data := slavaDb.data.(*dict.ConcurrentDict)
ttlMap := slavaDb.ttlMap
candidateKeys := ttlMap.RandomDistinctKeys(nums)
if len(candidateKeys) < 1 {
return
}
// len(keyLruMap) 可能小于nums
var minimumCount uint32
var minimumKey string
for i, key := range candidateKeys {
val, ok := data.Get(key)
if ok {
count := val.(*database.DataEntity).Lfu
if i == 0 || count > minimumCount {
minimumCount = count
minimumKey = key
}
}
}
slavaDb.Remove(minimumKey)
return
}
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO