大家鲜少提到如何正确地测量一个(区块链)系统,但它却是系统设计和评估过程中最重要的步骤。系统中有许多共识协议、各种性能的变量和对可扩展性的权衡。
然而,直到目前都没有一种所有人都认同的可靠方法,能够让人进行苹果对比苹果这种同一范畴内的合理比较。在本文,我们将概述受到数据中心化系统测量机制启发的一种方法,并探讨在评估一个区块链系统时可以避免的一些常见错误。
关键指标及其相互作用
在开发区块链系统时,我们应该将两个重要指标考量在内:延迟和吞吐量。
用户关心的第一件事就是交易延迟,即发起交易或支付和收到确认交易有效性信息(比如,确认交易发起方有足够的钱)之间的时间。
在传统的 BFT 系统中(如 PBFT、Terdermint、Tusk 和 Narwhal 等),一旦交易被确认就会被敲定,而最长链共识机制(如 Nakamoto Consensus、Solana/Ethereum PoS)中,一笔交易可能会被打包进区块,然后再重组。结果就是,我们需要一直等到交易达到“k 个区块深”了才能进行敲定,这就导致了延迟的时间大大超过了单次确认的时间。
其次,系统的吞吐量一般对于系统设计者来说十分重要。这就是系统每单位时间所处理的总负载,一般表达为每秒交易量 (TPS)。
乍一看,这两个关键指标看起来是完全相反的东西。但因为吞吐量由每秒的交易量得出,而延迟则是以秒为单位进行测量。自然而然地,我们会认为吞吐量 = 负载/延迟。
但事实并非如此。因为许多系统倾向于生成在 y 轴上展示吞吐量或延迟,而在 x 轴上展示节点数量的图表,所以这种计算方式的实现是不可能的。相反,我们能生成一个更好的、包含吞吐量/延迟指标的图表,它以非线性的方式呈现让图表清晰易读。

当没有竞争时,延迟是恒定的,仅是改变系统的负载,就可以改变吞吐量。会发生这种情况,是因为低竞争情况下,发送交易的最小开销是固定的,且队列延迟为 0,致使“无论进来什么,都能直接出去”。
在竞争激烈的情况下,吞吐量是恒定的,但仅是改变负载就可以让延迟发生变化。
这是因为系统已经超负载了,而增加更多负载会造成等待队列无限变长。更反常的是,延迟似乎会随着实验长度而发生变化,这是一个无限增长队列的人为结果。
这些表现都可以在典型的“曲棍球图”或“L型图”上看到,它取决于到达间隔的分布(下文会谈论到)。因此,这篇文章的关键要点是,我们应该在热区进行测量,这里的吞吐量和延迟都会影响我们的基准;而不用测量边缘区域,这里的吞吐量和延迟只有一个是重要的。

测量方法论
在做实验时,实验者有三种主要的设计选项:
开环 vs. 闭环
现在有两种可以控制对目标发出请求流的主要方法。开环系统基于 n = ∞ 个客户端进行建模,这些客户端根据速率 λ 和到达间隔分布(例如 Poisson)向目标发送请求。闭环系统会在任何给定时间内限制未完成请求的数量。开环系统和闭环系统的区别是特定部署的特点,同一个系统可以部署在不同的场景中。
例如,一个键值存储(key-value store)可以在一个开环部署中为数千个应用程序服务器提供服务,或在一个闭环部署中只为几个阻塞客户端提供服务。
对正确的部署场景进行测试是必不可少的,因为比起闭环系统的延迟通常受制于潜在的未完成请求数量,而开环系统可能会产生大量的等待队列,所以,延迟会更长。一般来说,区块链协议可以被任意数量的客户端使用,所以在开环环境下对其做评估会更准确。
综合基准测试的到达间隔分布
在创建合成工作负载时,我们必然会问:如何向系统提交请求?许多系统在测量之前会先预加载事务,但这会使测量产生偏差,因为系统从异常状态 0 开始运行。此外,预加载的请求已经在主存储器中,也因此绕过了其网络堆栈。
更好一些的方法则是以确定的速率发送请求(比如,1000 TPS),这会导致 L 型的图表(橙线)的出现,因为系统的容量得到了最佳使用。

然而,开放系统往往不以可预测的方式运作。相反,它们有处于高负载和低负载的时间段。为了对此进行建模,我们可以采用概率间隔分布,该分布一般是基于泊松分布。它将导致“曲棍球”图表(蓝线),因为即使平均速率低于最佳值,泊松爆发也会导致一些排队延迟(最大容量)。但这对我们十分有利,因为我们可以看到系统如何处理高负载以及负载恢复正常时,系统恢复的速度有多快。
热身阶段
最后要考虑的一点是何时开始测量。我们希望流水线在开始之前充满事务;否则,将需要测量预热延迟。理想情况下,预热延迟的测量应该通过热身阶段中的延迟测量来完成,直到测量结果遵循预期的分布。
如何进行比较
最后一个难题是合理比较系统的各种部署。同样,难点在于延迟和吞吐量是相互依赖的,因此我们可能难以生成公平的吞吐量/节点数图表。
最好的方法是定义服务级别目标 (SLO) 并测量当时的吞吐量,而不是简单地将每个系统推到其最高吞吐量(这种情况下,延迟毫无意义)。在吞吐量/延迟图上绘制一条与延迟轴相交 SLO 处的水平线并对相交点进行采样,这是一种可视化的好方法。
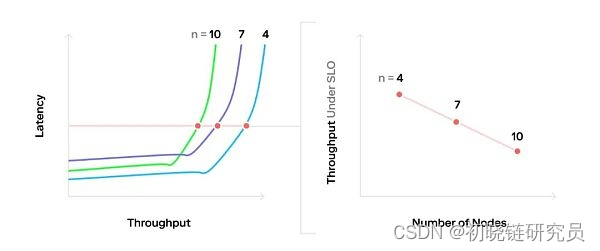
但我设置了 5 秒的 SLO,它只需要 2 秒
有人可能想要增加这里的负载,以便利用饱和点之后稍高的可用吞吐量。但是这很危险。如果系统操作配置不足,意外的请求爆发将导致系统达到完全饱和,致使延迟激增且很快会违背 SLO。实质上,在饱和点之后运行会导致一种不稳定的平衡。
因此,有两点需要考虑:
过度配置系统。本质上,系统应该在饱和点以下运行,以便吸收到达间隔分布中的爆发,而不会导致排队延迟增加。
如果 SLO 下方有空间,请增加 batch 的大小。这会增加系统关键路径上的负载,而不会增多排队延迟,它为你提供更高的吞吐量以获得你所要的更高延迟权衡。
我正在产生巨大的负载,该如何测量延迟呢?
当系统的负载很高时,尝试访问本地时钟,并为到达系统的每个事务添加时间戳可能会导致结果出现偏差。
相反,还有两个更可行的选择。第一种也是最简单的方法是对事务进行抽样;例如,在某些事务中可能存在一个魔数(magic number),而这些事务是客户端为其保留计时器的事务。在提交时间之后,任何人都可以检查区块链以确定这些事务何时提交,从而计算它们的延迟。这种做法的主要优点是,它不会干扰到达间隔分布。但是,因为必须修改某些事务,所以它可能被认为是“hacky(具有攻击性质的)”。
而更系统的方法则是使用两个负载生成器。第一个是主要的负载生成器,由它来遵循泊松分布。第二个请求生成器则用来测量延迟,并且它的负载会低得多;与系统的其余部分相比,可以将这个请求生成器视为单个客户端。即使系统向每个请求发送回复(就像某些系统所做的那样,例如 一个键值存储),我们也可以轻松地将所有回复放到负载生成器中,并只测量来自请求生成器的延迟。
唯一棘手的部分是,实际的到达间隔分布是两个随机变量的总和;但是,两个泊松分布的总和仍然是泊松分布,所以数学并不难 : )。
总结
测量大规模分布式系统对于识别瓶颈和分析压力下的预期行为是至关重要的。希望通过使用上述方法,我们都可以朝着公用语言迈出第一步,这最终将让区块链系统更适用于他们所做的工作以及他们对终端用户的承诺。
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
是否可以在所有delayed_job任务之前运行一个方法?基本上,我们试图确保每个运行delayed_job的服务器都有我们代码的最新实例,所以我们想运行一个方法来在每个作业运行之前检查它。(我们已经有了“check”方法并在别处使用它。问题只是关于如何从delayed_job中调用它。) 最佳答案 现在有一种官方方法可以通过插件来做到这一点。这篇博文通过示例清楚地描述了如何执行此操作http://www.salsify.com/blog/delayed-jobs-callbacks-and-hooks-in-rails(本文中描述
我经常将预配置的lambda插入可枚举的方法中,例如“map”、“select”等。但是“注入(inject)”的行为似乎有所不同。例如与mult4=lambda{|item|item*4}然后(5..10).map&mult4给我[20,24,28,32,36,40]但是,如果我制作一个2参数lambda用于像这样的注入(inject),multL=lambda{|product,n|product*n}我想说(5..10).inject(2)&multL因为“inject”有一个可选的单个初始值参数,但这给了我......irb(main):027:0>(5..10).inject
是否有self验证的问题列表。看着那个,我可以确定我知道。我应该复习一下。在学习的过程中,我列了一个这样的list,但它只包含我在某处听说过的项目。我需要一段时间才能找到新的东西。 最佳答案 以下是针对ruby和Rails的一些测试列表。证书名称:RubyonRails谁提供:oDeskIncorporation认证费用:免费网站:https://www.odesk.com/tests/985?pos=0证书名称:RubyonRails提供者:Techgig.com(TimesBusinessSolutionsLimited(T
我想覆盖store_accessor的getter。可以查到here.代码在这里:#Fileactiverecord/lib/active_record/store.rb,line74defstore_accessor(store_attribute,*keys)keys=keys.flatten_store_accessors_module.module_evaldokeys.eachdo|key|define_method("#{key}=")do|value|write_store_attribute(store_attribute,key,value)enddefine_met
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我最近开始学习Ruby,这是我的第一门编程语言。我对语法感到满意,并且我已经完成了许多只教授相同基础知识的教程。我已经写了一些小程序(包括我自己的数组排序方法,在有人告诉我谷歌“冒泡排序”之前我认为它非常聪明),但我觉得我需要尝试更大更难的东西来理解更多关于Ruby.关于如何执行此操作的任何想法?
文章目录1.任务背景2.任务目标3.相关知识点4.任务实操4.1安装配置JDK4.2启动FISCOBCOS4.3下载解压WeBASE-Front4.4拷贝sdk证书文件4.5启动节点4.6访问节点4.7检查运行状态5.任务总结1.任务背景FISCOBCOS其实是有控制台管理工具,用来对区块链系统进行各种管理操作。但是对于初学者来说,还是可视化界面更友好,本节就来介绍WeBASE管理平台,这是一款微众银行开源的自研区块链中间件平台,可以降低区块链使用的门槛,大幅提高区块链应用的开发效率。微众银行是腾讯牵头设立的民营银行,在国内民营银行里还是比较出名的。微众银行参与FISCOBCOS生态建设,一定
当音乐碰上区块链技术,会擦出怎样的火花?或许周杰伦已经给了我们答案。8月29日下午,B站独家首发周杰伦限定珍藏Demo独家访谈VCR,周杰伦在VCR里分享了《晴天》《青花瓷》《搁浅》《爱在西元前》四首经典歌曲Demo背后的创作故事,并首次公布18年前未发布的神秘作品《纽约地铁》的Demo。在VCR中,方文山和杰威尔音乐提及到“多亏了区块链技术,现在我们可以将这些Demos,变成独一无二具有收藏价值的艺术品,这些Demos可以在薄盒(国内数藏平台)上听到。”如何将音乐与区块链技术相结合,薄盒方面称:“薄盒作为区块链技术服务方,打破传统对于区块链技术只能作为数字收藏的理解。聚焦于区块链技术赋能,在
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。我一直在Rails上做两个项目,它们运行良好,但在这个过程中重新发明了轮子,自来水(和热水)和止痛药,正如我随后了解到的那样,这些已经存在于框架中。那么基本上,正确了解框架中所有智能部分的最佳方法是什么,这将节省时间而不是自己构建已经实现的功能?从第1页开始阅读文档?是否有公开所有内容的特定示例应用程序?一个特定的开源项目?所有的rails交通?还是完全
我有一些使用delayed_job的小程序。在我的本地主机上一切正常,但是当我将我的应用程序部署到Heroku并单击应该由delayed_job执行的链接时,没有任何反应,“任务”只是保存到表delayed_job中。Inthisarticleonherokublog写入时,执行delayed_job表中的任务,当运行此命令时rakejobs:work。但是我怎样才能运行这个命令呢?命令应该放在哪里?在代码中,还是从终端控制台? 最佳答案 如果您正在运行Cedar堆栈,请从终端控制台运行以下命令:herokurunrakejobs: