今天测试app,开启安卓代理,一点击准备登录时,抛出了如下提示“java.security.cert.CertPathValidatorException: Trust anchor for certification path not found”,大概意思就是证书的安全性问题
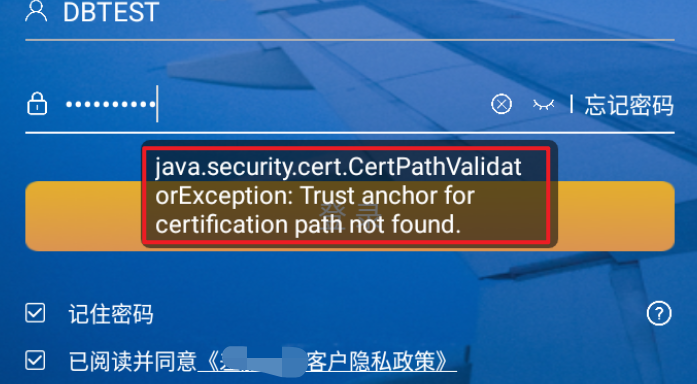
而当我把代理关闭了,就能正常登录,一切正常,但是我又抓不到数据包,这可不行!这里怀疑是证书信任的问题,当然可能还有其他原因,一个个尝试。
在Android 7.0以前,应用默认会信任系统证书和用户证书,Android 7.0开始,默认只信任系统证书。而我这里的安卓版本为7.1,如果是这个原因的话,那我们导入的burp证书就自然不会被信任了证书无效,从而抓取不到数据包
用户在手机里安装的证书如burpsuite证书,默认为用户证书。所以尝试将burp的证书安装成系统证书
openssl x509 -inform DER -in cacert.der -out cacert.pem
#计算hash值
mv cacert.pem `openssl x509 -inform PEM -subject_hash_old -in cacert.pem |head -1`'.0'
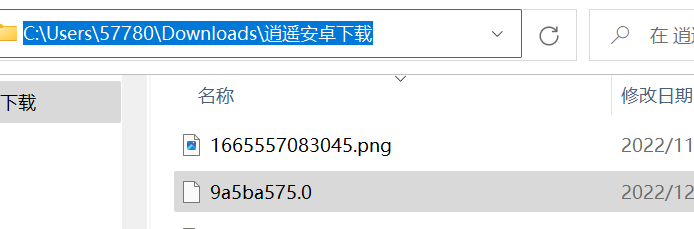
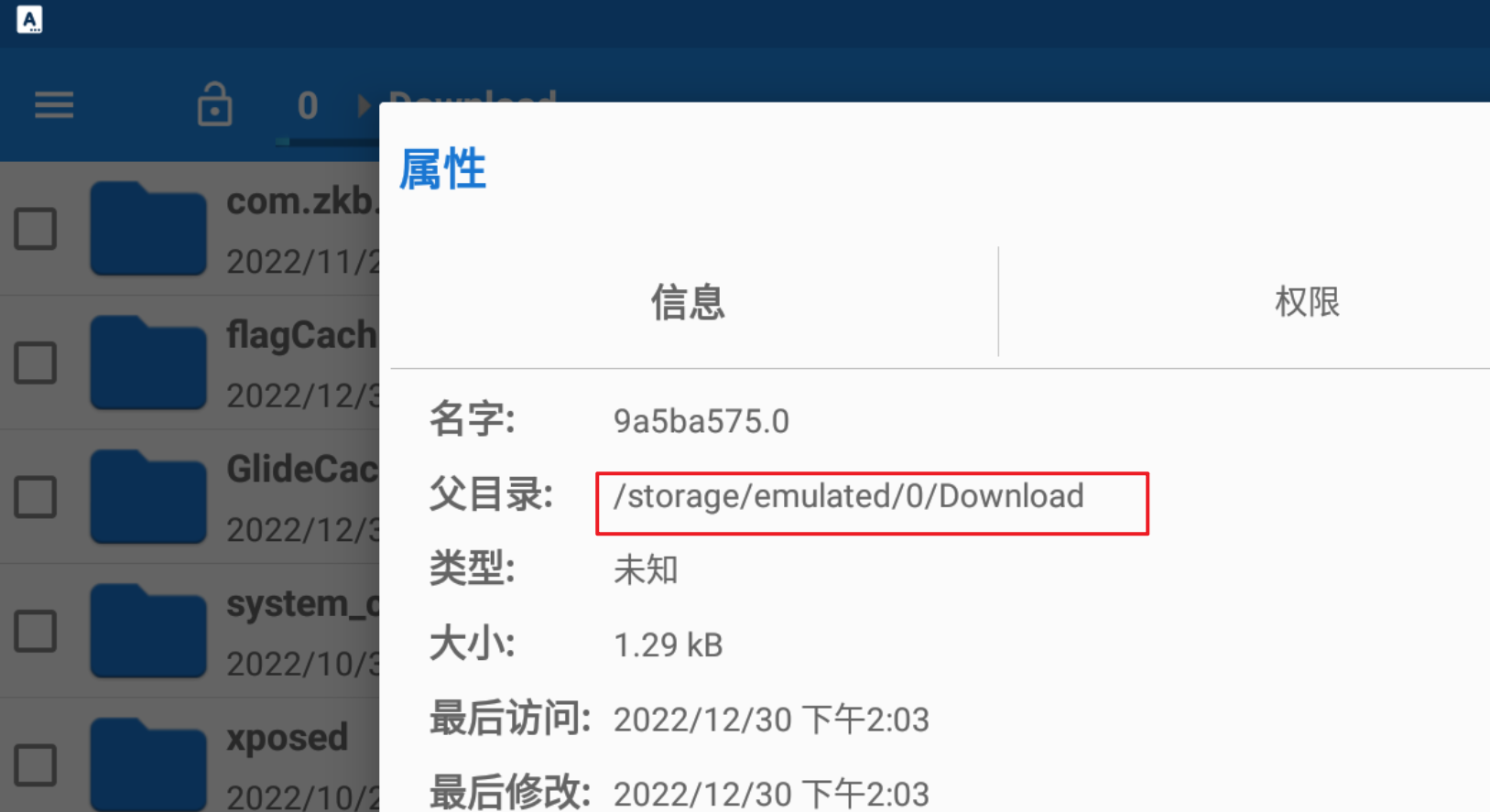
然后我们进入模拟器的文件管理Download中,查看9a5ba575.0文件所在的路径
进入adb所在的目录
执行adb命令
adb shell #进入adb
mount -o remount,rw /system #修改system目录读写权限
cp /storage/emulated/0/Download/9a5ba575.0 /system/etc/security/cacerts/ #将安卓共享目录中的证书文件复制到系统证书目录中去
chmod 644 /system/etc/security/cacerts/9a5ba575.0 #开启证书权限
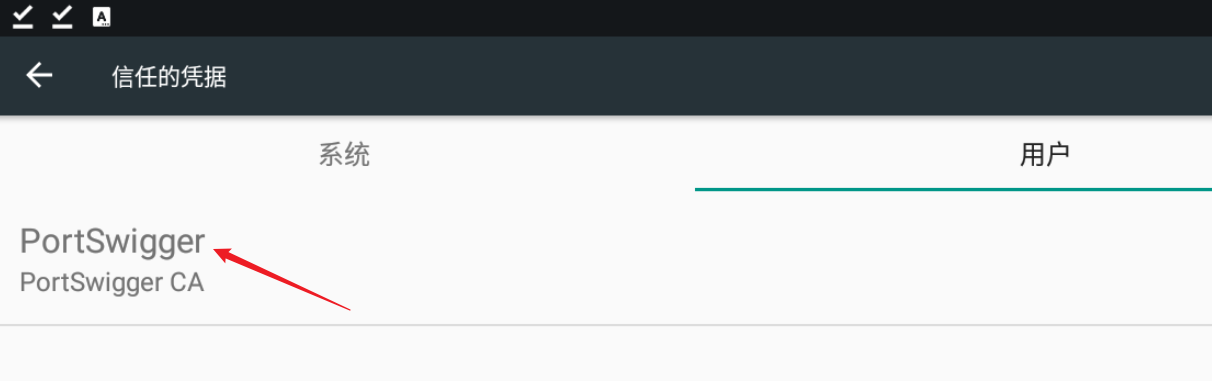
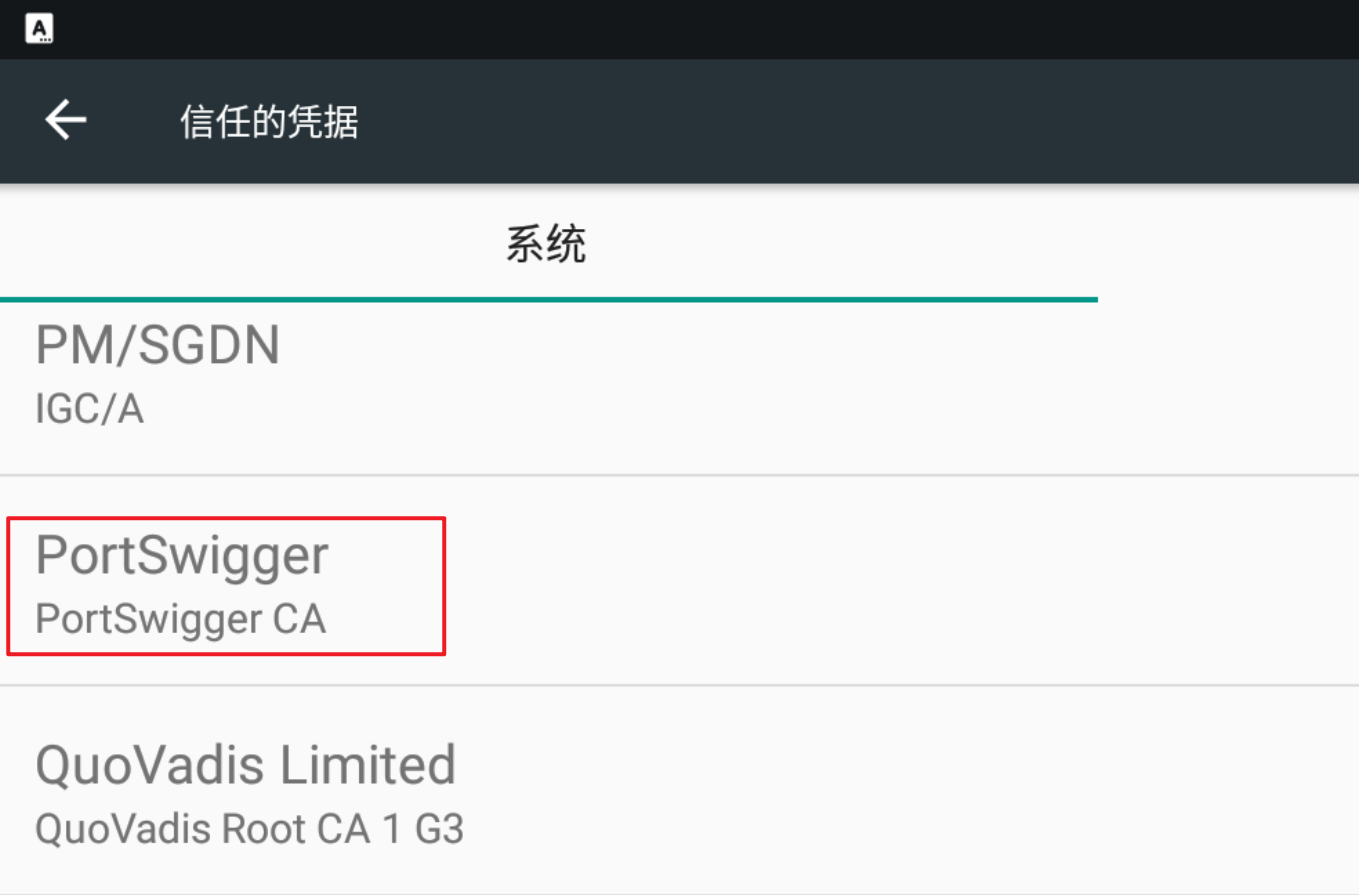
重启模拟器,即可在系统证书中看到burp证书,名为PortSwigger
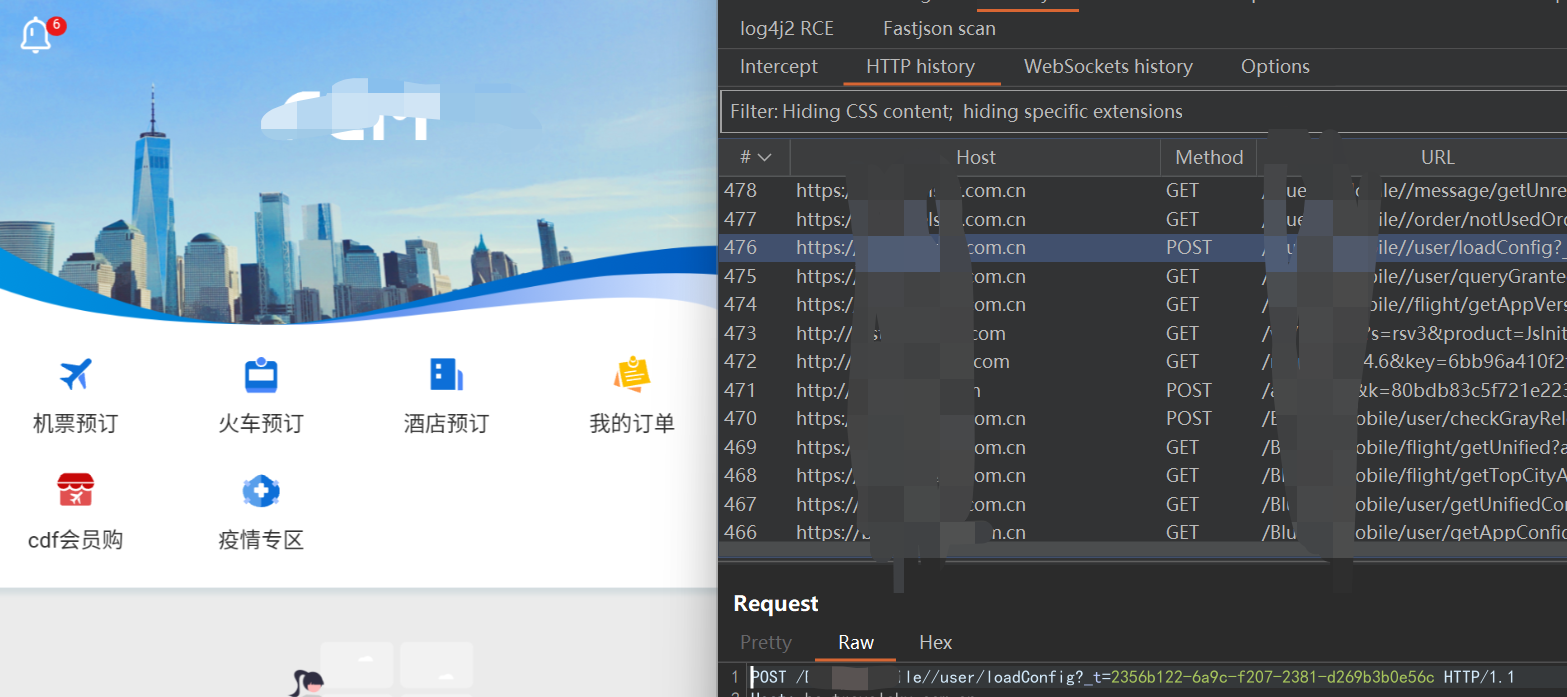
此时再尝试进行抓包,成功抓取
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
当我在我的Rails应用程序根目录中运行rakedoc:app时,API文档是使用/doc/README_FOR_APP作为主页生成的。我想向该文件添加.rdoc扩展名,以便它在GitHub上正确呈现。更好的是,我想将它移动到应用程序根目录(/README.rdoc)。有没有办法通过修改包含的rake/rdoctask任务在我的Rakefile中执行此操作?是否有某个地方可以查找可以修改的主页文件的名称?还是我必须编写一个新的Rake任务?额外的问题:Rails应用程序的两个单独文件/README和/doc/README_FOR_APP背后的逻辑是什么?为什么不只有一个?
我正在使用Postgres.app在OSX(10.8.3)上。我已经修改了我的PATH,以便应用程序的bin文件夹位于所有其他文件夹之前。Rammy:~phrogz$whichpg_config/Applications/Postgres.app/Contents/MacOS/bin/pg_config我已经安装了rvm并且可以毫无错误地安装pggem,但是当我需要它时我得到一个错误:Rammy:~phrogz$gem-v1.8.25Rammy:~phrogz$geminstallpgFetching:pg-0.15.1.gem(100%)Buildingnativeextension
我是Ruby的新手。我试过查看在线文档,但没有找到任何有效的方法。我想在以下HTTP请求botget_response()和get()中包含一个用户代理。有人可以指出我正确的方向吗?#PreliminarycheckthatProggitisupcheck=Net::HTTP.get_response(URI.parse(proggit_url))ifcheck.code!="200"puts"ErrorcontactingProggit"returnend#Attempttogetthejsonresponse=Net::HTTP.get(URI.parse(proggit_url)
有人知道如何将capybarapoltergeist的用户代理覆盖到移动用户代理以进行测试吗?我发现了一些有关为seleniumwebdriver配置它的信息:http://blog.plataformatec.com.br/2011/03/configuring-user-agents-with-capybara-selenium-webdriver/这在capybara闹鬼中怎么可能? 最佳答案 请参阅poltergeistgithub页面上的链接:https://github.com/teampoltergeist/polte
我正在使用Ruby/Mechanize编写一个“自动填写表格”应用程序。它几乎可以工作。我可以使用精彩CharlesWeb代理以查看服务器和我的Firefox浏览器之间的交换。现在我想使用Charles查看服务器和我的应用程序之间的交换。Charles在端口8888上代理。假设服务器位于https://my.host.com。.一件不起作用的事情是:@agent||=Mechanize.newdo|agent|agent.set_proxy("my.host.com",8888)end这会导致Net::HTTP::Persistent::Error:...lib/net/http/pe
我希望访问我机器上的所有HTTP流量(我的Windows机器-不是服务器)。据我了解,拥有一个本地代理是所有流量路线的必经之路。我一直在谷歌搜索但未能找到任何资源(关于Ruby)来帮助我。非常感谢任何提示或链接。 最佳答案 WEBrick中有一个HTTP代理(Rubystdlib的一部分)和here's一个实现示例。如果你喜欢生活在边缘,还有em-proxy伊利亚·格里戈里克。这postIlya暗示它似乎确实需要一些调整来解决您的问题。 关于ruby-如何捕获所有HTTP流量(本地代理)
我的测试尝试访问网页并验证页面上是否存在某些元素。例如,它访问http://foo.com/homepage.html并检查Logo图像,然后访问http://bar.com/store/blah.html并检查页面上是否出现了某些文本。我的目标是访问经过Kerberos身份验证的网页。我发现Kerberos代码如下:主文件uri=URI.parse(Capybara.app_host)kerberos=Kerberos.new(uri.host)@kerberos_token=kerberos.encoded_tokenkerberos.rb文件classKerberosdefini
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭9年前。Improvethisquestion首先,我想避免一场关于语言的口水战。可供选择的语言有Perl、Python和Ruby。我想提一下,我对所有这些都很满意,但问题是我不能只专注于一个。例如,如果我看到一个很棒的Perl模块,我必须尝试一下。如果我看到一个不错的Python应用程序,我必须知道它是如何制作的。如果我看到RubyDSL或一些Ruby巫术,我就会迷上Ruby一段时间。目前我是一名Java开发人员,但计划在不久的将来