我们在创建条形码时,如果以图片的方式将创建好的条码保存到指定文件夹路径,可以在程序中直接加载图片使用;已生成的条码图片,需要通过读取图片中的条码信息,如条码类型、条码绘制区域在图片中的四个顶点坐标位置等,可参考本文中的方法。
注:读取时,也支持读取二维码类型。
调用API:Spire.Barcode for .NET
两种方法:
★ 1. 在VS中通过“管理NuGet包”,搜索“Spire.Barcode”安装;
或者通过PM控制台安装:
PM> NuGet\Install-Package Spire.Barcode -Version 6.8.0
★ 2. 官网下载包,安装到本地路径,然后将安装路径下的Spire.Barcode.dll手动引入到VS程序。
C#
using Spire.Barcode;
using Spire.Barcode.Settings;
using System.Drawing;
namespace GetBarcode
{
class Program
{
static void Main(string[] args)
{
//加载条码图片
BarcodeInfo[] barcodeInfos = BarcodeScanner.ScanInfo("img.png");
for (int i = 0; i < barcodeInfos.Length; i++)
{
//获取条码类型
BarCodeReadType barCodeReadType = barcodeInfos[i].BarCodeReadType;
System.Console.WriteLine("Barcode Type is:" + barCodeReadType.ToString());
//获取条形码图片中的四个顶点坐标位置
Point[] vertexes = barcodeInfos[i].Vertexes;
//输出结果
for(int j = 0; j < vertexes.Length; j++)
{
System.Console.WriteLine(vertexes[j]);
}
System.Console.ReadKey();
}
}
}
}VB.NET
Imports Spire.Barcode
Imports Spire.Barcode.Settings
Imports System.Drawing
Namespace GetBarcode
Class Program
Private Shared Sub Main(args As String())
'加载条码图片
Dim barcodeInfos As BarcodeInfo() = BarcodeScanner.ScanInfo("img.png")
For i As Integer = 0 To barcodeInfos.Length - 1
'获取条码类型
Dim barCodeReadType As BarCodeReadType = barcodeInfos(i).BarCodeReadType
System.Console.WriteLine("Barcode Type is:" + barCodeReadType.ToString())
'获取条形码图片中的四个顶点坐标位置
Dim vertexes As Point() = barcodeInfos(i).Vertexes
'输出结果
For j As Integer = 0 To vertexes.Length - 1
System.Console.WriteLine(vertexes(j))
Next
System.Console.ReadKey()
Next
End Sub
End Class
End Namespace读取结果:
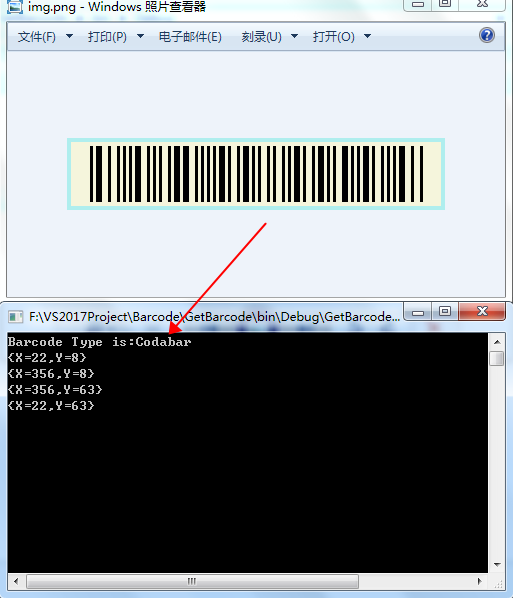
—END—
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
是的,我知道最好使用webmock,但我想知道如何在RSpec中模拟此方法:defmethod_to_testurl=URI.parseurireq=Net::HTTP::Post.newurl.pathres=Net::HTTP.start(url.host,url.port)do|http|http.requestreq,foo:1endresend这是RSpec:let(:uri){'http://example.com'}specify'HTTPcall'dohttp=mock:httpNet::HTTP.stub!(:start).and_yieldhttphttp.shou
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur