1. Redis 底层数据结构
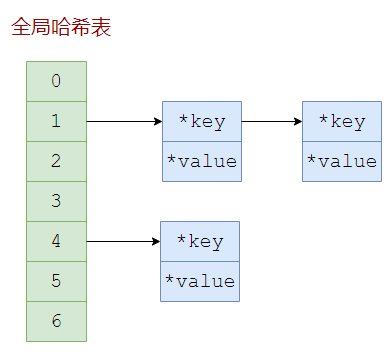
Redis数据库就像是一个哈希表,首先对key进行哈希运算得到哈希值再取模得到一个下标,每个元素是一个节点,节点之间形成链表。这感觉有点像Java中的HashMap。
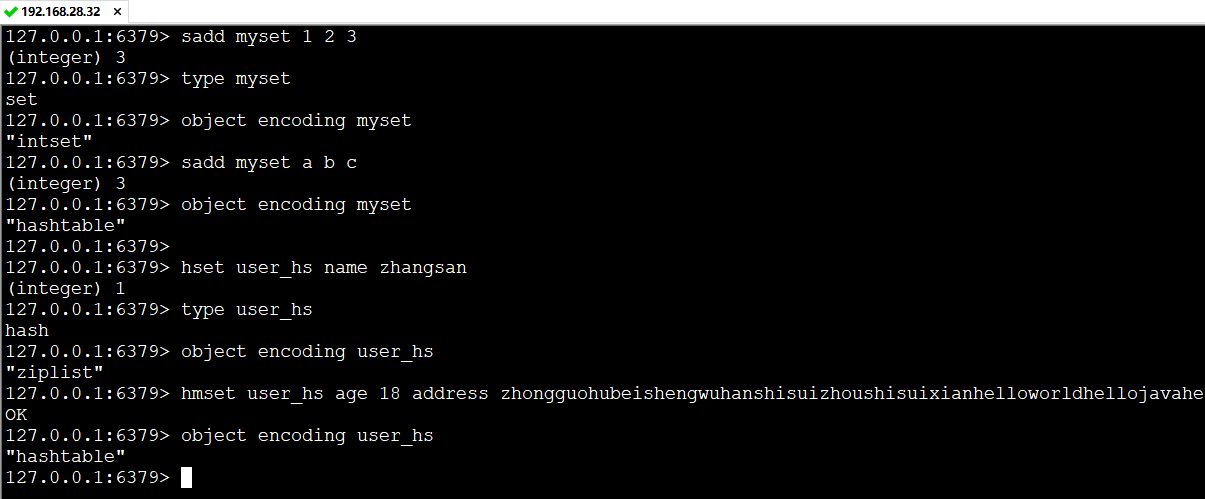
不同的数据类型的实现方式是不一样的,可以通过object encoding命令查看底层真正的数据存储结构
同一种类型在不同的条件下所采用的数据结构也不一样,例如:
Redis是键值对形式的数据库,key可以是任意值(PS:最终都会转成string),value有多种数据类型
详见:https://redis.io/docs/manual/data-types/data-types-tutorial/
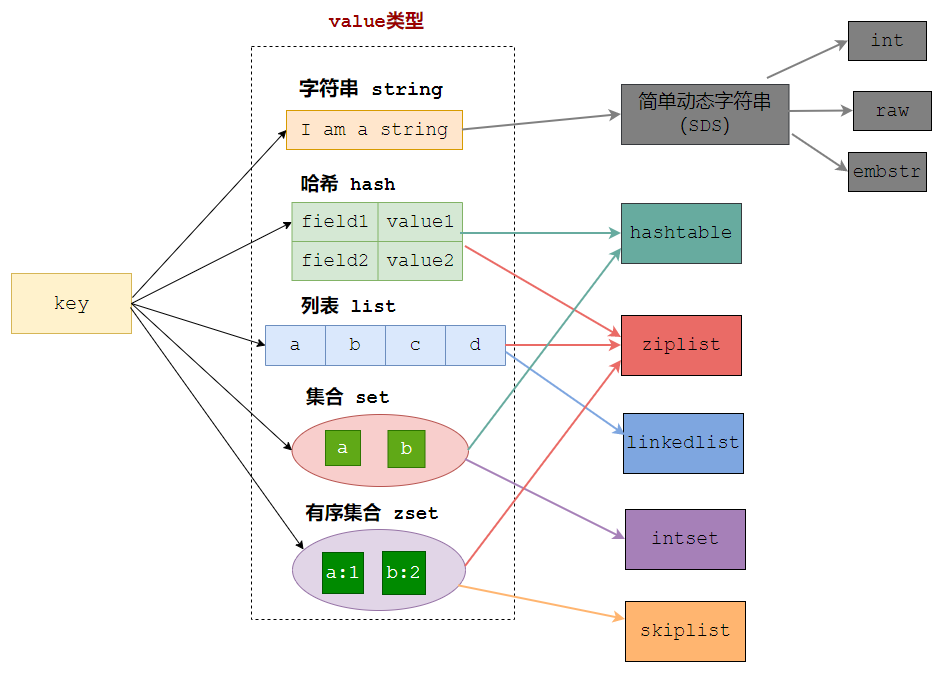
至此,已经很清楚,hash底层的结构是 ziplist 和 hashtable
那么,什么时候会从ziplist转成hashtable呢?这个在redis.conf中有相关的配置,如下:

默认情况下:
2. hashtable
在Redis中hashtable就是字典dict
通过源码,可以看到dict是这样定义的:

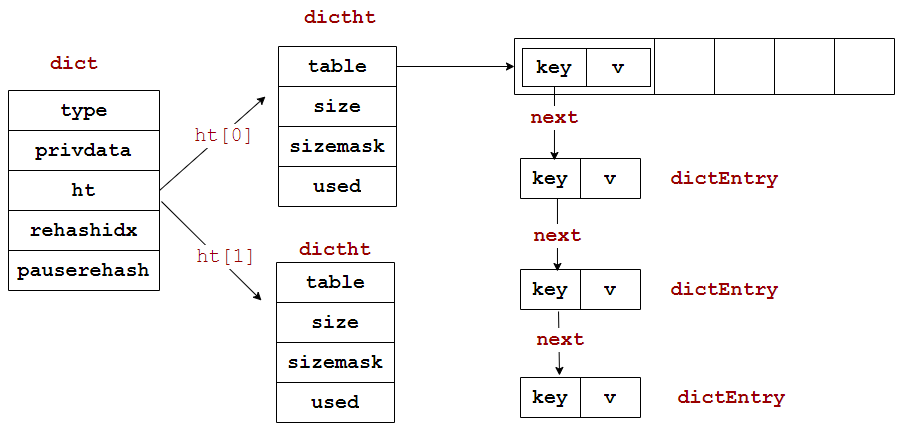
3. redisDb 与 redisObject
通过源码得知,redisDb代表redis数据库,redisObject代表存到数据库中的数据
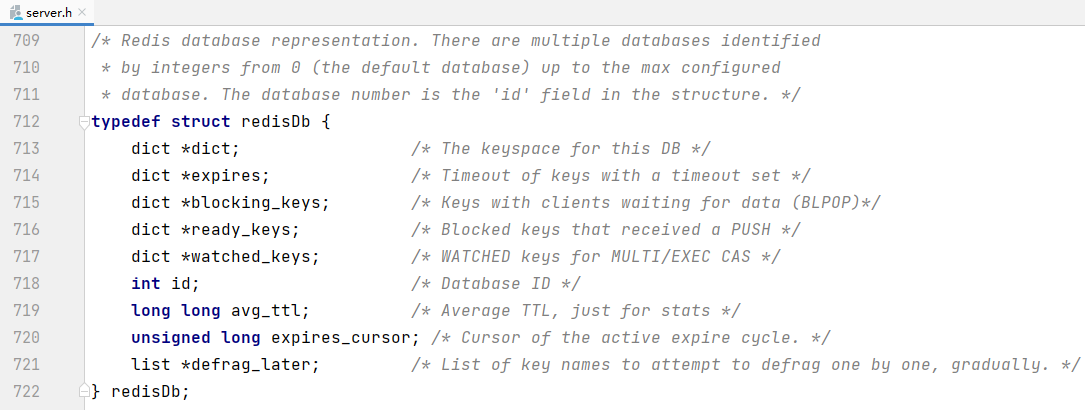
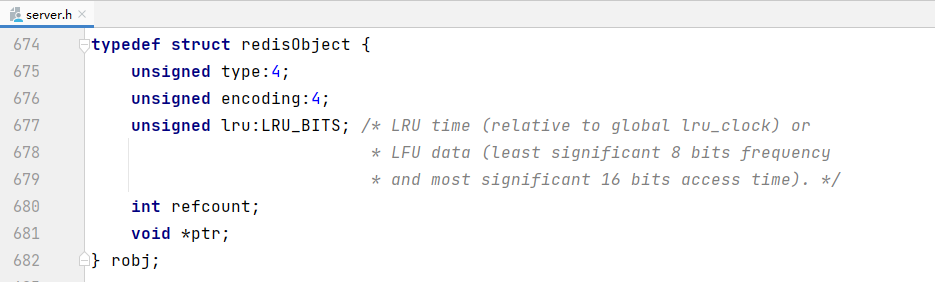
字典dict的结构前面已经看过了,于是整个数据库的结构大概就是下面这个样子:
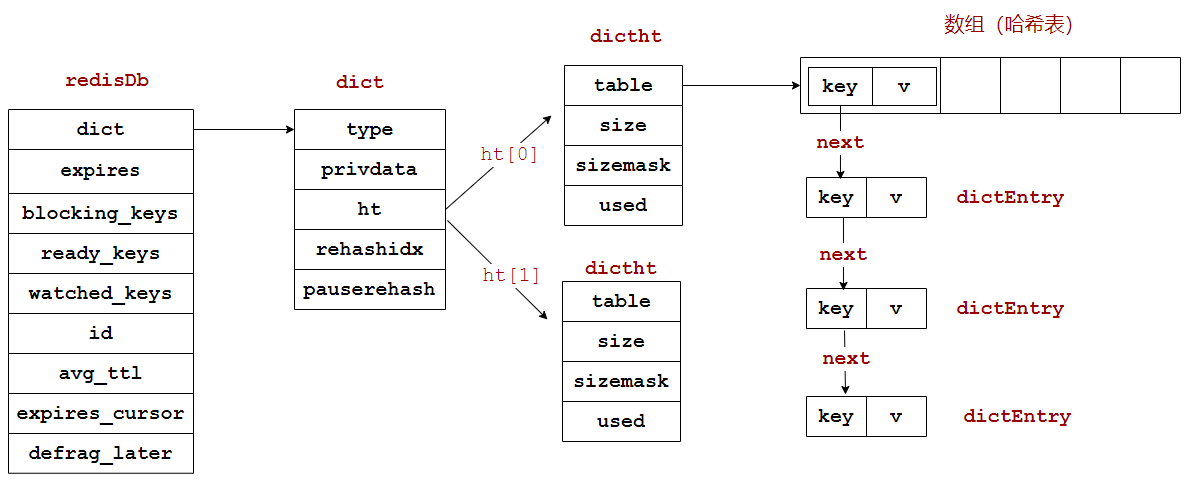
4. ziplist
ziplist是一种特殊编码的双链表,被设计成非常节省内存。它存储字符串和整型值,其中整数被编码为实际整数,而不是一系列字符。它允许在O(1)时间内在列表的任意一边进行push和pop操作。但是,由于每个操作都需要重新分配ziplist所使用的内存,因此实际的复杂性与ziplist所使用的内存量有关。
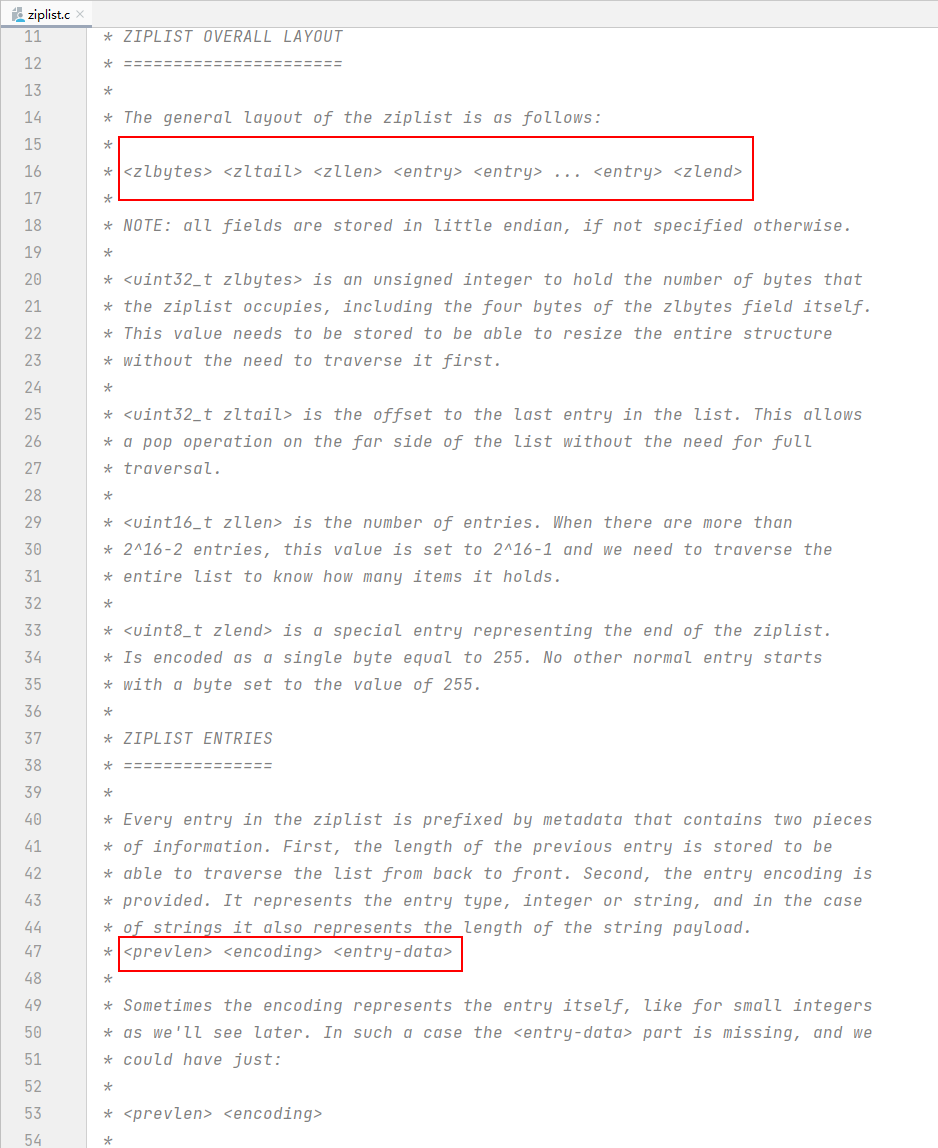
ziplist的大体布局如下:
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
<uint32_t zlbytes>: 一个无符号整数,用于保存ziplist占用的字节数,包括zlbytes字段本身的四个字节。需要存储这个值,以便能够调整整个结构的大小,而不需要首先遍历它。
<uint32_t zltail> : 列表中最后一个条目的偏移量。
<uint16_t zllen> : 条目的数量。当有超过2^16-2个条目时,这个值被设置为2^16-1,我们需要遍历整个列表来知道它包含多少项。
<uint8_t zlend> : 一个特殊的条目,表示 ziplist 的结尾

5. linkedlist

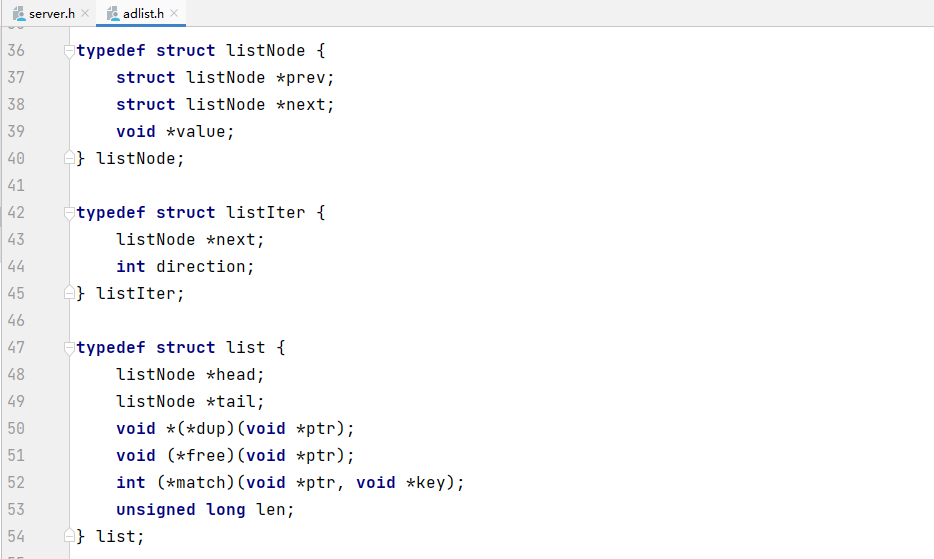
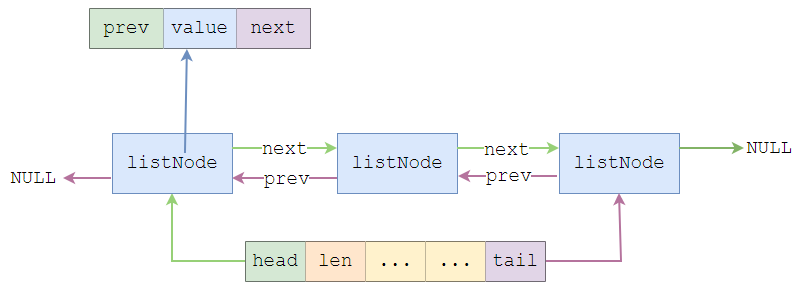
linkedlist是一个双向链表
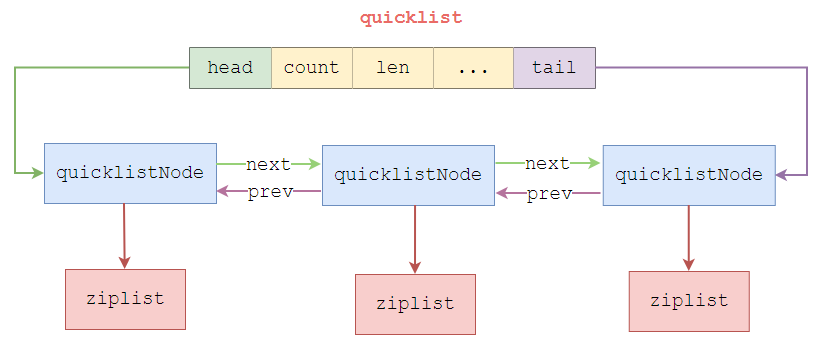
6. quicklist

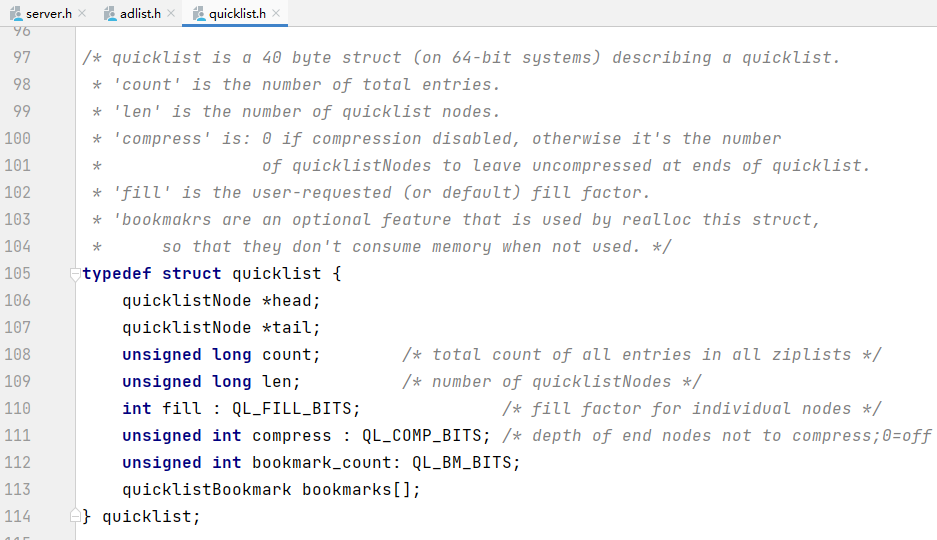
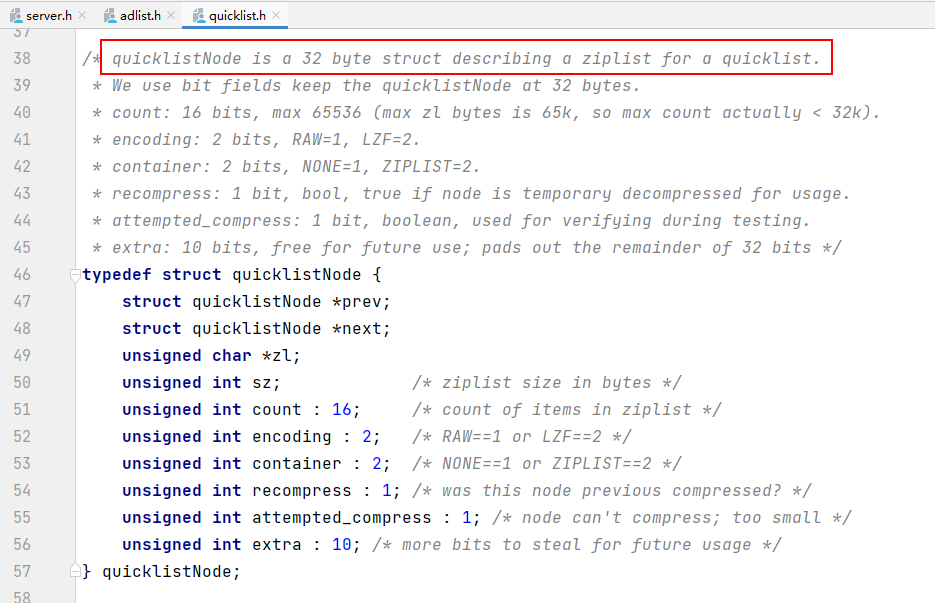
quicklistNode是一个32字节的结构体,描述快表的ziplist。
quicklist = linkedlist + ziplist
7. 参考
http://redisbook.com/index.html
http://blog.itpub.net/70000430/viewspace-2787985/
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最