MySQL优化器在基于成本的计算和基于规则的SQL优化会生成一个所谓的执行计划,我们就可以使用执行计划查看MySQL对该语句具体的执行方式。
介绍这个好啰嗦就是了,我们可以通过这个优化器展示的执行计划,查看优化器对我们的SQL进行优化的步骤,连接转换成单表访问时的优化。以及对于之前知识的复习了属于是,比如访问方式,索引的选择,半连接等SQL语句优化。
mysql> explain select * from mall.ums_admin;
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | ums_admin | NULL | ALL | NULL | NULL | NULL | NULL | 5 | 100.00 | NULL |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
上述是我们使用explain使用的简单小例子。下面是每列的简单描述。

我们接下来就是对于Explain中展示的列进行介绍,回涉及到之前的SQL成本和语句优化。
对于每个SQL语句来说,不管是不是使用连接的多表查询,我们最后都会变成执行多个单表查询的语句。所以table列就指明了当前执行某个计划的表是哪一个。就比如上面例子的单表查询的SQL。
会有以下几种情况
单表查询,此时的ID列就为1。
连接查询,此时对于两个表的连接查询ID列都为1,MySQL视在前面的表就是作为驱动表,在后面的表就是作为被驱动表。

子查询,有多种情况


UNION连表,就是出现一个select就再分配一个ID值。稍微有点特殊对于UNION ALL。

首先呢是因为UNION关键字会对合并的结果集进行去重,进行去重就得创建一个临时表来进行去重,第三行是一个临时表。但是呢UNION ALL不去重就不会出现第三行记录。


就是简单的单表查询或者连接查询。
就是UNION或UNION ALL或子查询的情况下,最左边的select就是PRIMARY类型的。

就是UNION的时候除了最左边的SELECT是PRIMARY类型,其他的SELECT都是UNION。
UNION的结果就会创建一个临时表进行去重,临时表就是这个select_type。
以上三个条件成立,此时子查询的第一个select部分的select_type就是SUBQUERY。如果物化的话,子查询只会执行一次,应该不用多说了。
以上条件成立,此时子查询的第一个select部分的select_type就是DEPENDENT SUBQUERY。相关外层查询会不断传参然后一直进行子查询。
UNION中除了最左边的select部分,被union连接的小查询的select_type 都是DEPENDENT UNION。
采用物化的方式执行的派生表,其中的子查询的select_type就是DERIVED。

当子查询是物化后转连接的方式,就是首先子查询是不相关子查询,然后子查询执行物化,优化成连接的方式和外层查询。此时子查询的select_type就是MATERIALIZED。

一般情况下都为null。
就是介绍访问当前行的表的访问方式。
我们之前学习的有
新的
possible_key就是SQL可以用到的索引。
key就是优化器计算成本后决定使用的索引列。
就是使用的索引的索引记录的长度。有三部分相加而成。
对于上面三部分,前面已经讲得很清楚了。
如果是varchar(100)可以为null的列,就需要300字节数据最大长度+1字节的非null+2字节记录长度,总长度就是303字节。
对于联合索引来说,用几个索引这个值就根据索引进行叠加上去,606就是俩varchar(100)可以为null的字段的联合索引。
就是当我们使用索引进行匹配的时候,索引列具体等值匹配的是什么东西,常数值还是一个列等等。

代表优化器经过预测具体要扫描表或者索引多少行。
代表驱动表的扇出比例,比如驱动表经过自身查询条件后预计会有多少记录数符合条件,输出出来。
对于单表来说这个字段没有意义,但是对于连接查询来说,可以预计被驱动表会执行多少次,即驱动表的扇出值。
就是优化器为我们提供额外信息,来帮助我们分析语句。
No tables used
Impossible where
No matching min/max row
Using index
Using index condition
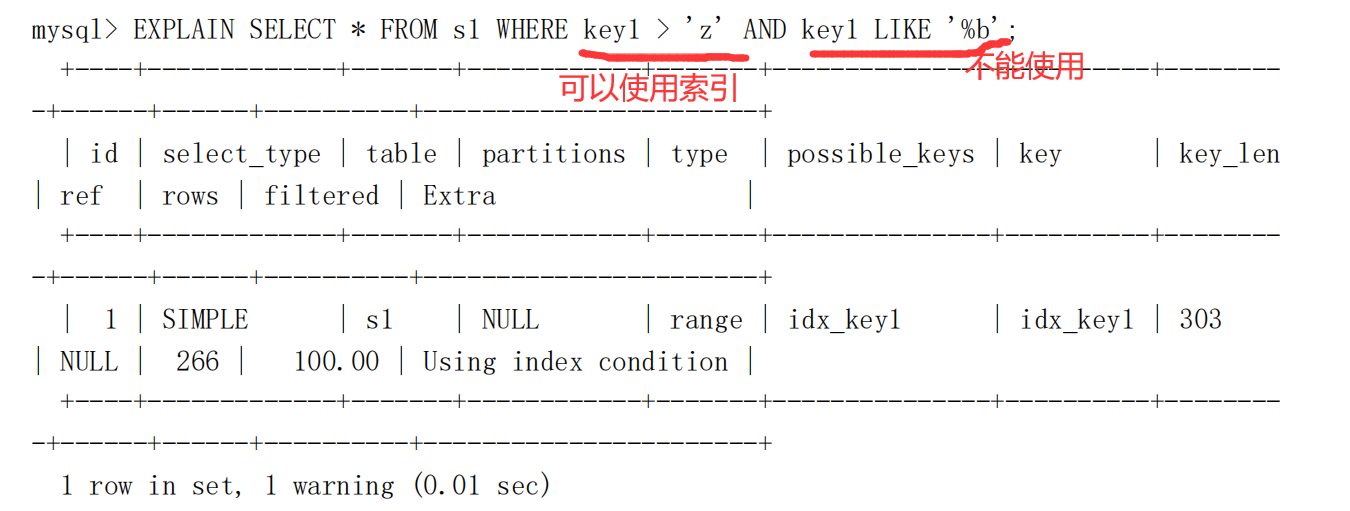
Using where
Using join buffer
Not exists
Using intersect(...) ,Using union(...),Using sort_union(...)
Zero limit
Using filesort
Using temporary
Start temporary , End temporary
LooseScan
FirstMatch
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记
我正在尝试绕过rails配置这个极其复杂的迷宫。到目前为止,我设法在ubuntu上设置了rvm(出于某种原因,ruby在ubuntu存储库中已经过时了)。我设法建立了一个Rails项目。我希望我的测试项目使用mysql而不是mysqlite。当我尝试“rakedb:migrate”时,出现错误:“!!!缺少mysql2gem。将其添加到您的Gemfile:gem'mysql2'”当我尝试“geminstallmysql”时,出现错误,告诉我需要为安装命令提供参数。但是,参数列表很大,我不知道该选择哪些。如何通过在ubuntu上运行的rvm和mysql获取rails3?谢谢。
目录1、yum安装mysql修改密码(1)在mysql里面修改(2)第二种方式,利用mysqladmin修改密码2、没有密码,登录mysql修改密码3、mysql的安全设置1、yum安装mysql在CentOS中默认安装有MariaDB(MySQL的一个分支),安装完成之后可以直接覆盖MariaDB。rpm-qa|grepmariadb查询是否安装了mariadbrpm-e--nodepsmariadb-libs-5.5.60-1.el7_5.x86_64卸载mariadwgethttp://dev.mysql.com/get/mysql57-community-release-el7-11.
我是Ruby的新手。我安装了DataMapper并且正在尝试安装dm-mysql-adapter-1.0.2gem。但是当我尝试安装时,出现以下错误。我正在使用ubuntu操作系统。vinoth@vinoth-laptop:~/Downloads$geminstalldm-mysql-adapter-1.0.2----with-mysql-lib=/usr/lib/mysql----with-mysql-conf=/usr/bin/mysqlWARNING:Installingto~/.gemsince/home/vinoth/gemsand/home/vinoth/gems/bina
我目前正在构建一个需要mysql2gem的RoR项目。我成功安装了gem。因为它出现在我的gem列表中。[root@vc2cmmka035538nsimple_cms]#gemlist***LOCALGEMS***actionmailer(3.2.3)actionpack(3.2.3)activemodel(3.2.3)activerecord(3.2.3)activeresource(3.2.3)activesupport(3.2.14,3.2.3)arel(3.0.2)bigdecimal(1.1.0)builder(3.2.2,3.0.0)bundler(1.1.5)c2c_li
我想使用托管在我自己服务器上的mysql数据库。我已经更改了DATABASE_URL和SHARED_DATABASE_URL配置变量以指向我的服务器,但它仍在尝试连接到heroku的amazonaws服务器。我该如何解决? 最佳答案 根据Herokudocumentation,更改DATABASE_URL是正确的方法。Ifyouwouldliketohaveyourrailsapplicationconnecttoanon-Herokuprovideddatabase,youcantakeadvantageofthissamemec