我们平时开发中好像很少使用到BlockingQueue(阻塞队列),比如我们想要存储一组数据的时候会使用ArrayList,想要存储键值对数据会使用HashMap,在什么场景下需要用到BlockingQueue呢?
当我们处理完一批数据之后,需要把这批数据发给下游方法接着处理,但是下游方法的处理速率不受控制,可能时快时慢。如果下游方法的处理速率较慢,会拖慢当前方法的处理速率,这时候该怎么办呢?
你可能想到使用线程池,是个办法,不过需要创建很多线程,还要考虑下游方法支不支持并发,如果是CPU密集任务,可能多线程比单线程处理速度更慢,因为需要频繁上下文切换。
这时候就可以考虑使用BlockingQueue,BlockingQueue最典型的应用场景就是上面这种生产者-消费者模型。生产者往队列中放数据,消费者从队列中取数据,中间使用BlockingQueue做缓冲队列,也就解决了生产者和消费者速率不同步的问题。
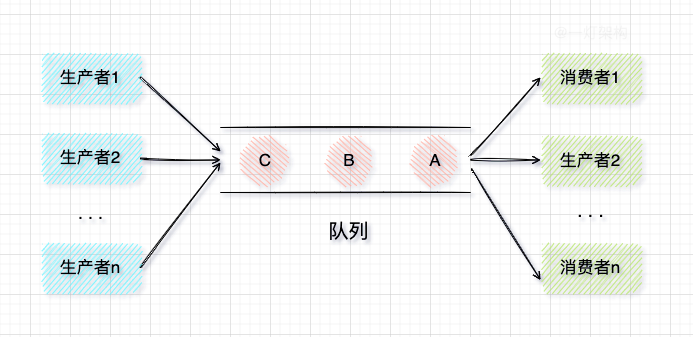
你可能联想到了消息队列(MessageQueue),消息队列相当于分布式阻塞队列,而BlockingQueue相当于本地阻塞队列,只作用于本机器。对应的是分布式缓存(比如:Redis、Memcache)和本地缓存(比如:Guava、Caffeine)。
另外很多框架中都有BlockingQueue的影子,比如线程池中就用到BlockingQueue做任务的缓冲。消息队列中发消息、拉取消息的方法也都借鉴了BlockingQueue,使用起来很相似。
今天就一块深入剖析一下Queue的底层源码。
BlockingQueue的用法非常简单,就是放数据和取数据。
/**
* @apiNote BlockingQueue示例
* @author 一灯架构
*/
public class Demo {
public static void main(String[] args) throws InterruptedException {
// 1. 创建队列,设置容量是10
BlockingQueue<Integer> queue = new ArrayBlockingQueue<>(10);
// 2. 往队列中放数据
queue.put(1);
// 3. 从队列中取数据
Integer result = queue.take();
}
}
为了满足不同的使用场景,BlockingQueue设计了很多的放数据和取数据的方法。
| 操作 | 抛出异常 | 返回特定值 | 阻塞 | 阻塞一段时间 |
|---|---|---|---|---|
| 放数据 | add |
offer |
put |
offer(e, time, unit) |
| 取数据 | remove |
poll |
take |
poll(time, unit) |
| 取数据(不删除) | element() |
peek() |
不支持 | 不支持 |
这几组方法的不同之处就是:
工作中使用最多的就是offer、poll阻塞指定时间的方法。
BlockingQueue常见的有下面5个实现类,主要是应用场景不同。
ArrayBlockingQueue
基于数组实现的阻塞队列,创建队列时需指定容量大小,是有界队列。
LinkedBlockingQueue
基于链表实现的阻塞队列,默认是无界队列,创建可以指定容量大小
SynchronousQueue
一种没有缓冲的阻塞队列,生产出的数据需要立刻被消费
PriorityBlockingQueue
实现了优先级的阻塞队列,基于数据显示,是无界队列
DelayQueue
实现了延迟功能的阻塞队列,基于PriorityQueue实现的,是无界队列
BlockingQueue的5种子类实现方式大同小异,这次就以最常用的ArrayBlockingQueue做源码解析。
先看一下ArrayBlockingQueue类里面有哪些属性:
// 用来存放数据的数组
final Object[] items;
// 下次取数据的数组下标位置
int takeIndex;
// 下次放数据的数组下标位置
int putIndex;
// 当前已有元素的个数
int count;
// 独占锁,用来保证存取数据安全
final ReentrantLock lock;
// 取数据的条件
private final Condition notEmpty;
// 放数据的条件
private final Condition notFull;
ArrayBlockingQueue中4组存取数据的方法实现也是大同小异,本次以put和take方法进行解析。
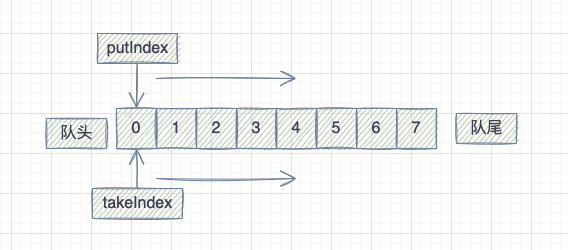
无论是放数据还是取数据都是从队头开始,逐渐往队尾移动。
// 放数据,如果队列已满,就一直阻塞,直到有其他线程从队列中取走数据
public void put(E e) throws InterruptedException {
// 校验元素不能为空
checkNotNull(e);
final ReentrantLock lock = this.lock;
// 加锁,加可中断的锁
lock.lockInterruptibly();
try {
// 如果队列已满,就一直阻塞,直到被唤醒
while (count == items.length)
notFull.await();
// 如果队列未满,就往队列添加元素
enqueue(e);
} finally {
// 结束后,别忘了释放锁
lock.unlock();
}
}
// 实际往队列添加数据的方法
private void enqueue(E x) {
// 获取数组
final Object[] items = this.items;
// putIndex 表示本次插入的位置
items[putIndex] = x;
// ++putIndex 计算下次插入的位置
// 如果本次插入的位置,正好是队尾,下次插入就从 0 开始
if (++putIndex == items.length)
putIndex = 0;
// 元素数量加一
count++;
// 唤醒因为队列空等待的线程
notEmpty.signal();
}
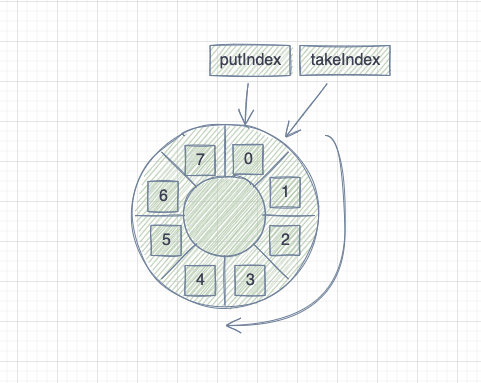
源码中有个有意思的设计,添加元素的时候如果已经到了队尾,下次就从队头开始添加,相当于做成了一个循环队列。
像下面这样:
// 取数据,如果队列为空,就一直阻塞,直到有其他线程往队列中放数据
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
// 加锁,加可中断的锁
lock.lockInterruptibly();
try {
// 如果队列为空,就一直阻塞,直到被唤醒
while (count == 0)
notEmpty.await();
// 如果队列不为空,就从队列取数据
return dequeue();
} finally {
// 结束后,别忘了释放锁
lock.unlock();
}
}
// 实际从队列取数据的方法
private E dequeue() {
// 获取数组
final Object[] items = this.items;
// takeIndex 表示本次取数据的位置,是上一次取数据时计算好的
E x = (E) items[takeIndex];
// 取完之后,就把队列该位置的元素删除
items[takeIndex] = null;
// ++takeIndex 计算下次取数据的位置
// 如果本次取数据的位置,正好是队尾,下次就从 0 开始取数据
if (++takeIndex == items.length)
takeIndex = 0;
// 元素数量减一
count--;
if (itrs != null)
itrs.elementDequeued();
// 唤醒被队列满所阻塞的线程
notFull.signal();
return x;
}
我是「一灯架构」,如果本文对你有帮助,欢迎各位小伙伴点赞、评论和关注,感谢各位老铁,我们下期见

我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
我正在处理旧代码的一部分。beforedoallow_any_instance_of(SportRateManager).toreceive(:create).and_return(true)endRubocop错误如下:Avoidstubbingusing'allow_any_instance_of'我读到了RuboCop::RSpec:AnyInstance我试着像下面那样改变它。由此beforedoallow_any_instance_of(SportRateManager).toreceive(:create).and_return(true)end对此:let(:sport_
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www