大家好,我是带我去滑雪!
本期使用R包 ElemStatLearn 的南非心脏病数据 SAheart 进行逻辑回归。其中,响应变量为chd(是否有冠心病,即coronary heart disease)。特征向量包括sbp(收缩压,systolic blood pressure)、tobacco(累计抽烟量)、ldl(低密度脂蛋白胆固醇,即low density lipoprotein cholesterol)、因子变量famhist(是否有家族心脏病史)、typea(A型行为,即type-A behavior)、alcohol(当前饮酒量)、age(发病时年龄),以及两个关于肥胖程度的数值型度量adiposity与obesity。该案例来自陈强编著的《机器学习及R运用》第5.1节课后习题。
需要完成的工作有如下:
(1)将响应变量 cha 设为因子变量,并计算样本中有冠心病的比例;
(2)使用set. seed (1),预留 100 个观测值作为测试集;
(3)使用训练集,将chd 对其余变量进行逻辑回归;
(4)计算此逻辑回归的准;
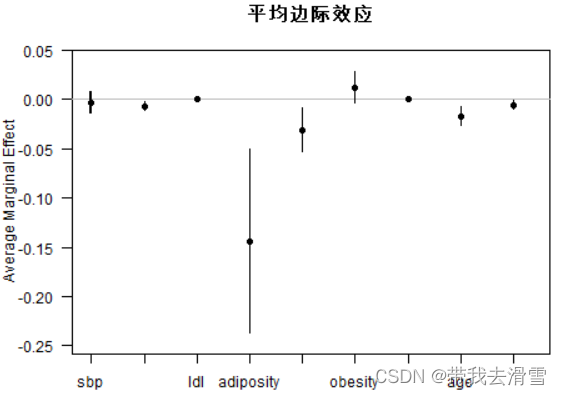
(5) 计算平均边际效应AME,并画图展示;
(6)在测试集中进行预测,计算准确率、错误率、灵敏度、特异度与召回率;
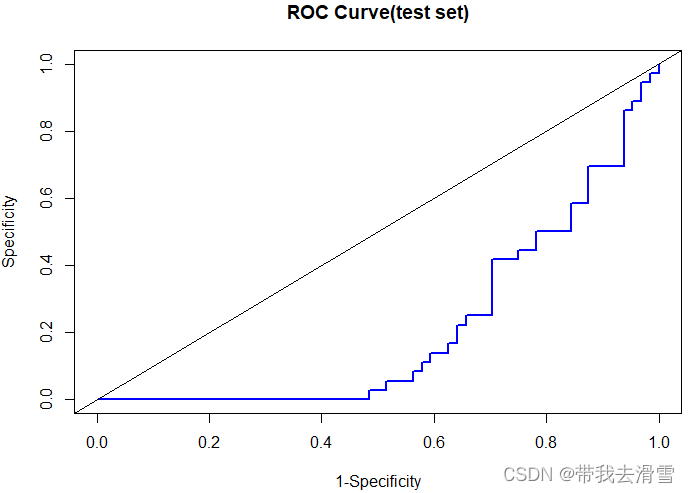
(7)画ROC 曲线;
(8)计算 AUC:
(9)计算 kappa 值。
首先尝试最常用的先安装包再加载数据集:
> install.packages(ElemStatLearn)
Error in install.packages : object 'ElemStatLearn' not found
结果显示:“Error in install.packages : object 'ElemStatLearn' not found”,所以采用这种方法安装ElemStatLearn包不行,正确的做法如下,使用“str()”查看数据结构:
>packageurl <- "https://cran.r-project.org/src/contrib/Archive/ElemStatLearn/ElemStatLearn_2015.6.26.tar.gz"
>install.packages(packageurl, repos=NULL, type="source")>library(ElemStatLearn)
>str(SAheart)'data.frame': 462 obs. of 10 variables:
$ sbp : int 160 144 118 170 134 132 142 114 114 132 ...
$ tobacco : num 12 0.01 0.08 7.5 13.6 6.2 4.05 4.08 0 0 ...
$ ldl : num 5.73 4.41 3.48 6.41 3.5 6.47 3.38 4.59 3.83 5.8 ...
$ adiposity : num 23.1 28.6 32.3 38 27.8 ...
$ famhist : Factor w/ 2 levels "Absent","Present": 2 1 2 2 2 2 1 2 2 2 ...
$ typea : int 49 55 52 51 60 62 59 62 49 69 ...
$ obesity : num 25.3 28.9 29.1 32 26 ...
$ alcohol : num 97.2 2.06 3.81 24.26 57.34 ...
$ age : int 52 63 46 58 49 45 38 58 29 53 ...
$ chd : int 1 1 0 1 1 0 0 1 0 1 ...
> SAheart$chd=factor(SAheart$chd,levels = c("1","0"),labels=c("Have","Don't have"))
> options(digits = 4)
> prop.table(table(SAheart$chd))
Have Don't have
0.3463 0.6536
结果显示,样本中有冠心病的比例为34.63%,没有冠心病的比例为65.36%,其中“options(digits = 4)”表示保留小数点后四位数字。
> set.seed(1)
> train_index=sample(462,362)
> train=SAheart[train_index,]
> test=SAheart[-train_index,]> str(train)
'data.frame': 362 obs. of 10 variables:
$ sbp : int 140 110 134 176 132 136 150 150 128 174 ...
$ tobacco : num 8.6 12.2 8.8 0 12 ...
$ ldl : num 3.9 4.99 7.41 3.14 4.51 7.84 6.4 5.04 2.43 6.57 ...
$ adiposity: num 32.2 28.6 26.8 31 21.9 ...
$ famhist : Factor w/ 2 levels "Absent","Present": 2 1 1 2 1 2 1 2 2 2 ...
$ typea : int 52 44 35 45 61 58 53 60 63 50 ...
$ obesity : num 28.5 27.1 29.4 30.2 26.1 ...
$ alcohol : num 11.11 21.6 29.52 4.63 64.8 ...
$ age : int 64 55 60 45 46 45 63 45 17 64 ...
$ chd : Factor w/ 2 levels "Have","Don't have": 1 1 1 2 1 1 2 2 2 1 ...
> options(digits=4)
> fit=glm(chd~.,data=train,family=binomial)
> summary(fit)Call:
glm(formula = chd ~ ., family = binomial, data = train)Deviance Residuals:
Min 1Q Median 3Q Max
-2.446 -0.871 0.456 0.786 1.887Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 4.801815 1.464569 3.28 0.00104 **
sbp -0.001488 0.006739 -0.22 0.82528
tobacco -0.101163 0.029964 -3.38 0.00073 ***
ldl -0.181278 0.068809 -2.63 0.00843 **
adiposity -0.019735 0.032331 -0.61 0.54159
famhistPresent -0.801410 0.259376 -3.09 0.00200 **
typea -0.033687 0.013850 -2.43 0.01501 *
obesity 0.072542 0.048936 1.48 0.13824
alcohol -0.000867 0.005118 -0.17 0.86540
age -0.041313 0.013358 -3.09 0.00198 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1(Dispersion parameter for binomial family taken to be 1)
Null deviance: 465.32 on 361 degrees of freedom
Residual deviance: 369.50 on 352 degrees of freedom
AIC: 389.5Number of Fisher Scoring iterations: 5
结果显示,经过5次“Fisher得分迭代”得到估计结果,其中,零偏离度(只有常数项模型的残差平方和)为465.32,而残差偏离度(完整模型的残差平方和)为369.50。
> (fit$null.deviance-fit$deviance)/fit$null.deviance
[1] 0.2059
>install.packages("margins")
> library(margins)
> effects=margins(fit)
> summary(effects)
factor AME SE z p lower upper
adiposity -0.0033 0.0055 -0.6116 0.5408 -0.0141 0.0074
age -0.0070 0.0022 -3.2198 0.0013 -0.0113 -0.0027
alcohol -0.0001 0.0009 -0.1695 0.8654 -0.0018 0.0016
famhistPresent -0.1436 0.0473 -3.0344 0.0024 -0.2363 -0.0508
ldl -0.0307 0.0113 -2.7307 0.0063 -0.0528 -0.0087
obesity 0.0123 0.0082 1.5007 0.1334 -0.0038 0.0284
sbp -0.0003 0.0011 -0.2208 0.8252 -0.0025 0.0020
tobacco -0.0171 0.0048 -3.5966 0.0003 -0.0265 -0.0078
typea -0.0057 0.0023 -2.4994 0.0124 -0.0102 -0.0012
> win.graph(width=5, height=4,pointsize=9)
> plot(effects,main="平均边际效应")
首先,使用逻辑模型的回归结果进行预测,并计算混淆矩阵,使用测试集进行预测:
> prob_test=predict(fit,type="response",newdata=test)
> prob_test=prob_test>0.5
> table=table(predicted=prob_test,Actual=test$chd)
> table
Actual
predicted Have Don't have
FALSE 18 10
TRUE 18 54
其中,函数predict ()的参数“type = "response"”,表示预测事件发生的条件概率,根据此概率是否大于0.5,预测结果变量的类别。
根据混淆矩阵,可计算衡量预测优良程度的相应指标,包括准确率、错误率、灵敏度、特异度与召回率:
> (Accuracy=(table[1,1]+table[2,2])/sum(table))
[1] 0.72
> (Error_rate=(table[2,1]+table[1,2])/sum(table))
[1] 0.28
> (Sensitivity=table[2,2]/(table[1,2]+table[2,2]))
[1] 0.8438
> (Specificity=table[1,1]/(table[1,1]+table[2,1]))
[1] 0.5
> (Recall=table[2,2]/(table[2,1]+table[2,2]))
[1] 0.75
> install.packages("ROCR")
> library(ROCR)
> pred_object=prediction(prob_test,test$chd)
> perf=performance(pred_object,measure="tpr",x.measure="fpr")
> plot(perf,main="ROC Curve(test set)",lwd=2,col="blue",xlab="1-Specificity",ylab="Specificity")
> abline(0,1)
>aut_test=performance(pred_object,measure="auc")
>auc_test@y.values
[1] 0.2122
结果显示,曲线下面积为0.2122。
> install.packages("vcd")
> library(vcd)> Kappa(table)
value ASE z Pr(>|z|)
Unweighted 0.361 0.0973 3.71 0.000205
Weighted 0.361 0.0973 3.71 0.000205
结果显示,在测试集中,kappa值为0.361,表明预测值与实际值之间具有中等一致性。
更多优质内容持续发布中,请移步主页查看。
点赞+关注,下次不迷路!
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
前言作为一名程序员,自己的本质工作就是做程序开发,那么程序开发的时候最直接的体现就是代码,检验一个程序员技术水平的一个核心环节就是开发时候的代码能力。众所周知,程序开发的水平提升是一个循序渐进的过程,每一位程序员都是从“菜鸟”变成“大神”的,所以程序员在程序开发过程中的代码能力也是根据平时开发中的业务实践来积累和提升的。提高代码能力核心要素程序员要想提高自身代码能力,尤其是新晋程序员的代码能力有很大的提升空间的时候,需要针对性的去提高自己的代码能力。提高代码能力其实有几个比较关键的点,只要把握住这些方面,就能很好的、快速的提高自己的一部分代码能力。1、多去阅读开源项目,如有机会可以亲自参与开源