需要学习基础的可参照这两文章
Elasticsearch 学习+SpringBoot实战教程(一)
Elasticsearch 学习+SpringBoot实战教程(一)_桂亭亭的博客-CSDN博客
Elasticsearch 学习+SpringBoot实战教程(二)
前言: 经过了前面2课的学习我们已经大致明白了ES怎么使用,包括原生语句,javaapi等等,现在我们要在业务中使用了,
所以我们选择spring-data作为我们的ORM框架,快速开发代码。
同时需要给规范化操作
目录
1 使用ElasticsearchOperations的方式
注意你的ES版本号
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.20</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.10.1</version>
<exclusions>
<exclusion>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.10.1</version>
</dependency>




spring:
elasticsearch:
uris: localhost:9200
connection-timeout: 3000
socket-timeout: 5000
package com.example.eslearn.entity;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.io.Serializable;
/**
* Document: 将这个类对象转为 es 中一条文档进行录入
* indexName: 用来指定文档的索引名称
* createIndex: 用来指定是否创建索引,默认为false
*/
@Document(indexName = "user", createIndex = true)
public class UserDocument implements Serializable {
@Id // 用来将放入对象id值作为文档_id进行映射
private String id;
@Field(type = FieldType.Keyword) // 字段映射类型
private String name;
private String sex;
private Integer age;
@Field(type = FieldType.Text) // 字段映射类型
private String city;
优点:更想我们的springdata的使用风格,简单,快捷,个人使用
private final ElasticsearchOperations ESO;
// set方法注入
@Autowired
public CRUDService2(ElasticsearchOperations elasticsearchOperations) {
this.ESO = elasticsearchOperations;
}
// 新增文档
public String save() {
UserDocument user = new UserDocument();
user.setName("说不定看见的");
user.setCity("北京 上海 西安");
user.setAge(22);
user.setSex("男");
UserDocument save = ESO.save(user);
System.out.println(save);
return JSON.toJSONString(save);
}
使用可视化软件查询,得到下面的结果


// 更新文档
public String update() {
UserDocument user = new UserDocument();
user.setId("W7w2HYcB32f1ZLmxRwzw");
user.setName("说快来打见的");
user.setCity("北京 上海 西安");
user.setAge(21);
user.setSex("女");
UserDocument save = ESO.save(user);
System.out.println(save);
return JSON.toJSONString(save);
}

// 删除
public String delete(){
UserDocument userDocument = new UserDocument();
userDocument.setId("8966e506-1763-4d4b-bf1c-4f5d9bd9b052");
return ESO.delete(userDocument);
}
// 查询所有
public String findAll(){
//查询所有
SearchHits<UserDocument> search = ESO.search(Query.findAll(), UserDocument.class);
for (SearchHit<UserDocument> uc : search) {
System.out.println(uc.getContent());
}
return JSON.toJSONString(search);
}
// 根据id查询文档
public String getById(){
UserDocument userDocument = ESO.get("W7w2HYcB32f1ZLmxRwzw", UserDocument.class);
return JSON.toJSONString(userDocument);
}
服务层
//大杂烩,一次学会
public String findSource(){
//查询条件构建
MatchQueryBuilder mp=new MatchQueryBuilder("name","妲己");
//排序构建
FieldSortBuilder f = new FieldSortBuilder("age");
//分页构建
Pageable page= PageRequest.of(0,5);
// 高亮构建
HighlightBuilder highlightBuilder = new HighlightBuilder()
.preTags("<span style='color:yellow'>")
.postTags("</span>")
.field("name");
//结果过滤构建,相当于返回那些字段
FetchSourceFilter filter = new FetchSourceFilter(new String[]{"name", "city"}, null);
//查询语句构建
NativeSearchQueryBuilder query = new NativeSearchQueryBuilder()
.withQuery(mp)
.withSorts(f)
.withPageable(page)
.withHighlightBuilder(highlightBuilder)
.withSourceFilter(filter);
//执行查询
SearchHits<UserDocument> search = ESO.search(query.build(), UserDocument.class);
return JSON.toJSONString(search);
}
控制器
@GetMapping("/findSource")
private String findSource(){
return sv.findSource();
}

优点:安全,企业级常用
对应的原生查询语句
注意这里的term就是精准查询到 关键字
GET user/_search
{
"query": {
"term": {
"city": "上海"
}
}
}服务层
// 文档搜索
public String searchDocument(String indexName,String city){
//2 构建搜索请求
SearchRequest searchRequest = new SearchRequest().indices(indexName);
//3 构建搜索内容
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("city", city);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(termQueryBuilder);
//4 填充搜索内容
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = null;
try {
//5 执行搜索操作
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
//6 返回值
return JSON.toJSONString(searchResponse.getHits().getHits());
}控制器
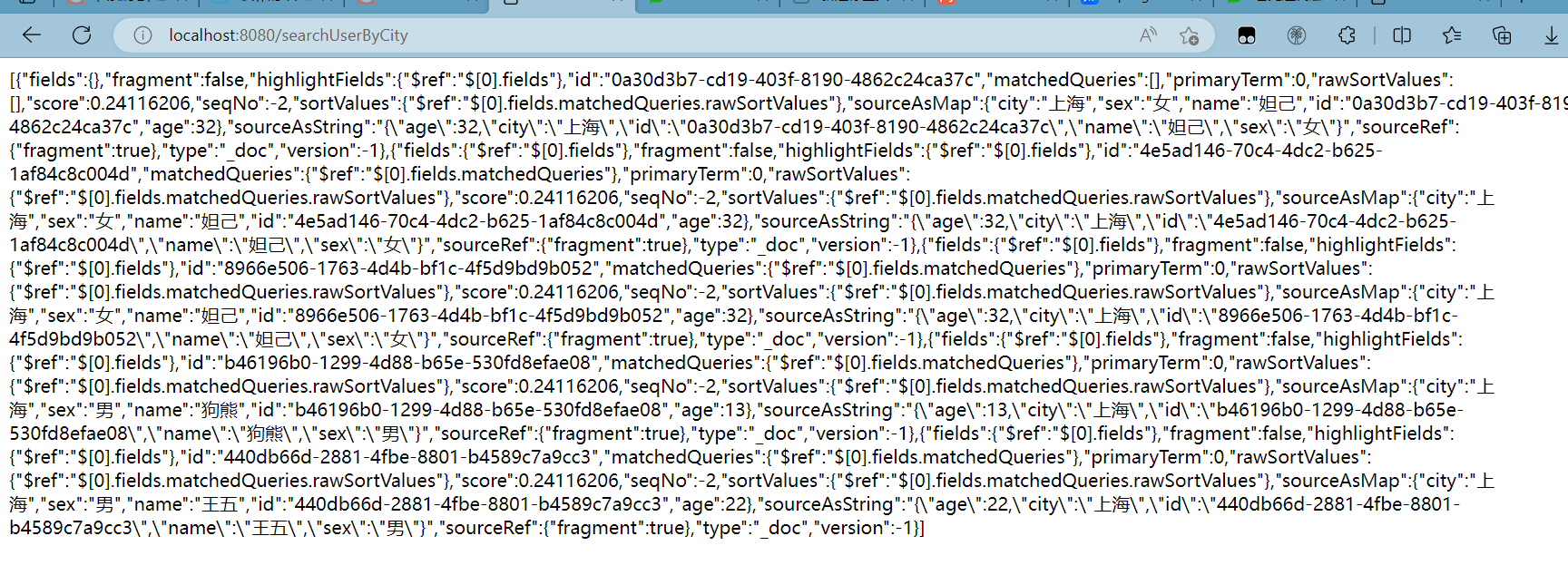
@GetMapping("/searchUserByCity")
public String searchUserByCity() throws IOException {
return service.searchDocument("user","上海");
}
访问链接localhost:8080/searchUserByCity
GET user/_search
{
"query": {
"term": {
"city": "上海"
}
},
"from":0,
"size":5
}服务层
// 文档搜索--分页查询
public String searchDocument2(String indexName,String city){
//2 构建搜索请求
SearchRequest searchRequest = new SearchRequest().indices(indexName);
//3 构建搜索内容
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//拿到前5条数据
searchSourceBuilder
.query(QueryBuilders.termQuery("city", city))
.from(0)
.size(5);
//4 填充搜索内容
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = null;
try {
//5 执行搜索操作
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
//6 返回值
return JSON.toJSONString(searchResponse.getHits().getHits());
}控制层
@GetMapping("/searchUserByCity2")
public String searchUserByCity2() throws IOException {
return service.searchDocument2("user","上海");
}访问localhost:8080/searchUserByCity2
term 与matchphrase的比较 term用于精确查找有点像 mysql里面的"=" match是先将查询关键字分词然后再进行查找。term一般用在keywokrd类型的字段上进行精确查找。
注意这里的bool,表示使用布尔查询,其中的must是相当于SQL语句中的and的意思。
所以就是查找name中包含“妲己”并且年龄为22岁的信息,请注意不能写成"妲",因为我们在新建文档的时候是这样新建的“妲己”,那么我们如果匹配“妲”就会匹配不到,加入这样写就可以匹配到了“妲 己”,请注意空格,这是分词的依据之一
ES查询语句。
GET user/_search
{
"query": {
"bool":{
"must": [
{
"match_phrase": {
"name": "妲己"
}
},
{
"term": {
"age": "32"
}
}
]
}
},
"from":0,
"size":10
}
服务层
// 文档分词搜索+精确查询
public String searchDocument3(String indexName,String name,Integer age){
//2 构建搜索请求
SearchRequest searchRequest = new SearchRequest().indices(indexName);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//3 构建复杂的查询语句
BoolQueryBuilder bq=QueryBuilders
.boolQuery()
//分词匹配
.must(QueryBuilders.matchPhraseQuery("name",name))
//精确匹配
.must(QueryBuilders.matchQuery("age",age));
//4 填充搜索语句
searchSourceBuilder
.query(bq)
.from(0)
.size(5);
//4 填充搜索内容
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = null;
try {
//5 执行搜索操作
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
//6 返回值
return JSON.toJSONString(searchResponse.getHits());
}控制层
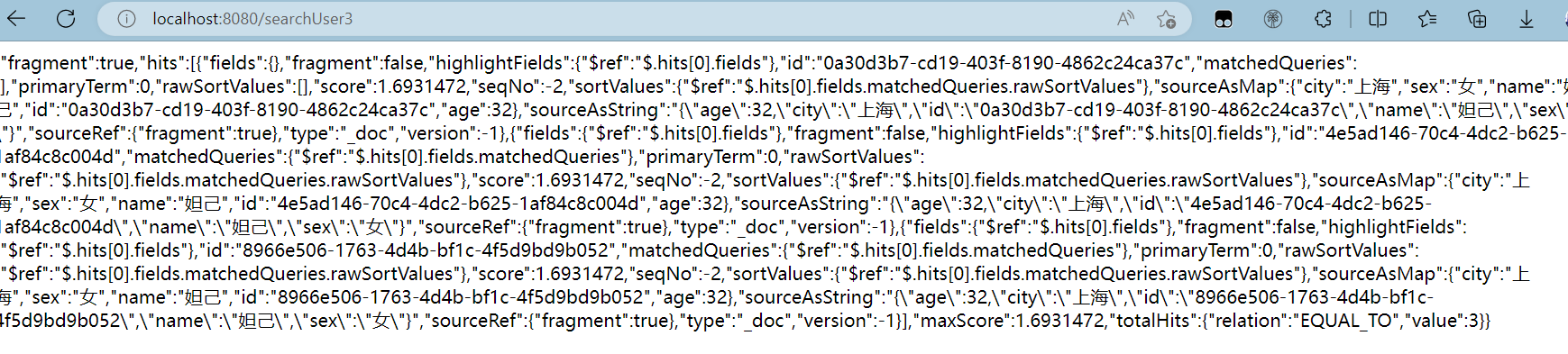
@GetMapping("/searchUser3")
public String searchUser3() throws IOException {
return service.searchDocument3("user","妲己",32);
}
 字符匹配OR精准查询
字符匹配OR精准查询原始查询语句
GET user/_search
{
"query": {
"bool":{
"should": [
{
"match_phrase": {
"name": "妲己"
}
},
{
"term": {
"age": "32"
}
}
]
}
},
"from":0,
"size":10
}服务层
// 文档分词搜索OR精确查询
public String searchDocument4(String indexName,String name,Integer age){
//2 构建搜索请求
SearchRequest searchRequest = new SearchRequest().indices(indexName);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//3 构建复杂的查询语句
BoolQueryBuilder bq=QueryBuilders
.boolQuery()
//分词匹配
.should(QueryBuilders.matchPhraseQuery("name",name))
//精确匹配
.should(QueryBuilders.matchQuery("age",age));
//4 填充搜索语句
searchSourceBuilder
.query(bq)
.from(0)
.size(5);
//4 填充搜索内容
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = null;
try {
//5 执行搜索操作
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
//6 返回值
return JSON.toJSONString(searchResponse.getHits());
}控制层
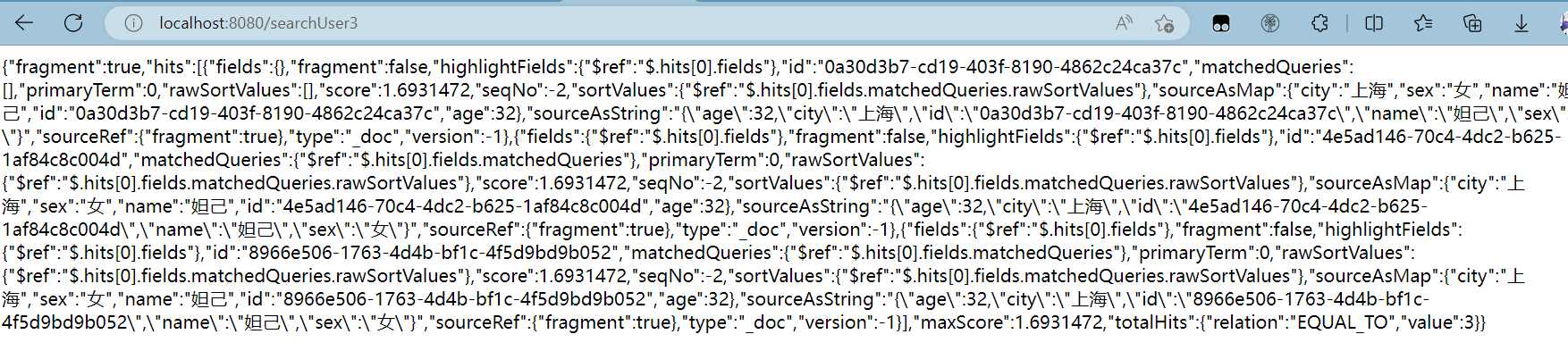
@GetMapping("/searchUser4")
public String searchUser4() throws IOException {
return service.searchDocument4("user","妲己",22);
}结果

原始语句
GET user/_search
{
"query": {
"wildcard": {
"city": {
"value": "上*"
}
}
}
} // 文档模糊查询
public String searchDocument5(String indexName,String city){
//2 构建搜索请求
SearchRequest searchRequest = new SearchRequest().indices(indexName);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//3 构建模糊查询的语句
WildcardQueryBuilder bq=QueryBuilders
.wildcardQuery("city",city);
//4 填充搜索语句
searchSourceBuilder
.query(bq);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = null;
try {
//5 执行搜索操作
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
//6 返回值
return JSON.toJSONString(searchResponse.getHits());
} @GetMapping("/searchUser5")
public String searchUser5() throws IOException {
return service.searchDocument5("user","上*");
}结果

1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
我是Ruby新手,并被要求在我们的新项目中使用它。我们还被要求使用Padrino(Sinatra)作为后端/框架。我们被要求使用Rspec进行测试。我一直在寻找可以指导在Padrino上使用RspecforRuby的教程。我得到的主要是引用RoR。但是,我需要RubyonPadrino。请在任何入门/指南/引用/讨论等方面指导我。如有不妥之处请指正。可能是我没有针对我的问题搜索正确的词/短语组合。我正在使用Ruby1.9.3和Padrinov.0.10.6。注意:我还提到了SOquestion,但它没有帮助。 最佳答案 我没用过Pa