
? 作者:韩信子@ShowMeAI
? 深度学习实战系列:https://www.showmeai.tech/tutorials/42
? 本文地址:https://www.showmeai.tech/article-detail/317
? 声明:版权所有,转载请联系平台与作者并注明出处
? 收藏ShowMeAI查看更多精彩内容

神经网络是一种由神经元、层、权重和偏差组合而成的特殊机器学习模型,随着近些年深度学习的高速发展,神经网络已被广泛用于进行预测和商业决策并大放异彩。
神经网络之所以广受追捧,是因为它们能够在学习能力和性能方面远远超过任何传统的机器学习算法。 现代包含大量层和数十亿参数的网络可以轻松学习掌握互联网海量数据下的模式和规律,并精准预测。

随着AI生态和各种神经网络工具库(Keras、Tensorflow 和 Pytorch 等)的发展,搭建神经网络拟合数据变得非常容易。但很多时候,在用于学习的训练数据上表现良好的模型,在新的数据上却效果不佳,这是模型陷入了『过拟合』的问题中了,在本篇内容中,ShowMeAI将给大家梳理帮助深度神经网络缓解过拟合提高泛化能力的方法。

缓解过拟合最直接的方法是增加数据量,在数据量有限的情况下可以采用数据增强技术。 数据增强是从现有训练样本中构建新样本的过程,例如在计算机视觉中,我们会为卷积神经网络扩增训练图像。
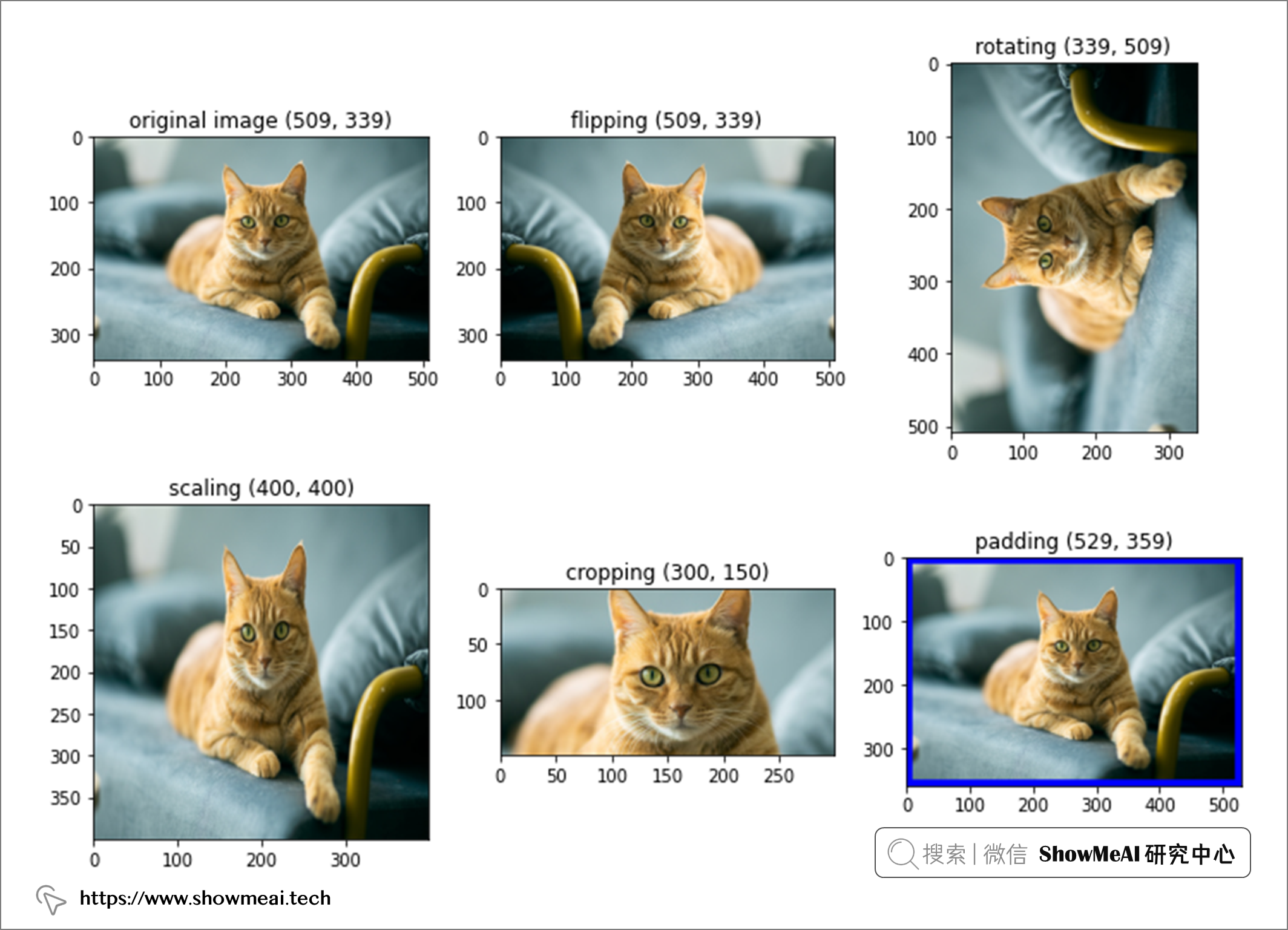
具体体现在计算机视觉中,我们可以对图像进行变换处理得到新突破,例如位置和颜色调整是常见的转换技术,常见的图像处理还包括——缩放、裁剪、翻转、填充、旋转和平移。
我们可以基于PIL库手动对图像处理得到新图像以扩增样本量
from PIL import Image
import matplotlib.pyplot as plt
img = Image.open("/content/drive/MyDrive/cat.jpg")
flipped_img = img.transpose(Image.FLIP_LEFT_RIGHT) ### 翻转
roated_img = img.transpose(Image.ROTATE_90) ## 旋转
scaled_img = img.resize((400, 400)) ### 图像缩放
cropped_img = img.crop((100,50,400,200)) # 裁剪
# 颜色变换
width, height = img.size
pad_pixel = 20
canvas = Image.new(img.mode, (width+pad_pixel, height+pad_pixel), 'blue')
canvas.paste(img, (pad_pixel//2,pad_pixel//2))
颜色增强处理通过改变图像的像素值来改变图像的颜色属性。更细一点讲,可以通过改变亮度、对比度、饱和度、色调、灰度、膨胀等来处理。
from PIL import Image, ImageEnhance
import matplotlib.pyplot as plt
img = Image.open("/content/drive/MyDrive/cat.jpg")
enhancer = ImageEnhance.Brightness(img)
img2 = enhancer.enhance(1.5) ## 更亮
img3 = enhancer.enhance(0.5) ## 更暗
imageenhancer = ImageEnhance.Contrast(img)
img4 = enhancer.enhance(1.5) ## 提升对比度
img5 = enhancer.enhance(0.5) ## 降低对比度
enhancer = ImageEnhance.Sharpness(img)
img6 = enhancer.enhance(5) ## 锐化

虽然可以通过使用像 pillow 和 OpenCV 这样的图像处理库来手动执行图像增强,但更简单且耗时更少的方法是使用 ?Keras API 来完成。
关于keras的核心知识,ShowMeAI为其制作了速查手册,欢迎大家通过如下文章快查快用:
Keras 是一个用 Python 编写的深度学习 API,可以运行在机器学习平台 Tensorflow 之上。 Keras 有许多可提高实验速度的内置方法和类。 在 Keras 中,我们有一个 ?ImageDataGenerator类,它为图像增强提供了多个选项。
keras.preprocessing.image.ImageDataGenerator()
?参数:
(-width_shift_range, +width_shift_range) 之间的整数个像素。width_shift_range=2 时,可能值是整数 [-1, 0, +1],与 width_shift_range=[-1, 0, +1] 相同;而 width_shift_range=1.0 时,可能值是 [-1.0, +1.0) 之间的浮点数。(-height_shift_range, +height_shift_range) 之间的整数个像素。height_shift_range=2 时,可能值是整数 [-1, 0, +1],与 height_shift_range=[-1, 0, +1] 相同;而 height_shift_range=1.0 时,可能值是 [-1.0, +1.0) 之间的浮点数。[lower, upper]。随机缩放范围。如果是浮点数,[lower, upper] = [1-zoom_range, 1+zoom_range]。fill_mode = "constant" 时。(samples, height, width, channels),"channels_first" 模式表示输入尺寸应该为 (samples, channels, height, width)。默认为 在 Keras 配置文件 ~/.keras/keras.json 中的 image_data_format 值。如果你从未设置它,那它就是 "channels_last"。如果要基于 TensorFlow 实现数据增强,示例代码如下:
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
brightness_range= [0.5, 1.5],
rescale=1./255,
shear_range=0.2,
zoom_range=0.4,
horizontal_flip=True,
fill_mode='nearest',
zca_epsilon=True)
path = '/content/drive/MyDrive/cat.jpg' ## Image Path
img = load_img(f"{path}")
x = img_to_array(img)
x = x.reshape((1,) + x.shape)
i = 0
### 基于数据增强构建25张图片并存入aug_img文件夹
for batch in datagen.flow(x, batch_size=1, save_to_dir="/content/drive/MyDrive/aug_imgs", save_prefix='img', save_format='jpeg'):
i += 1
if i > 25:
break

关于随机失活的详细原理知识,大家可以查看ShowMeAI制作的深度学习系列教程和对应文章
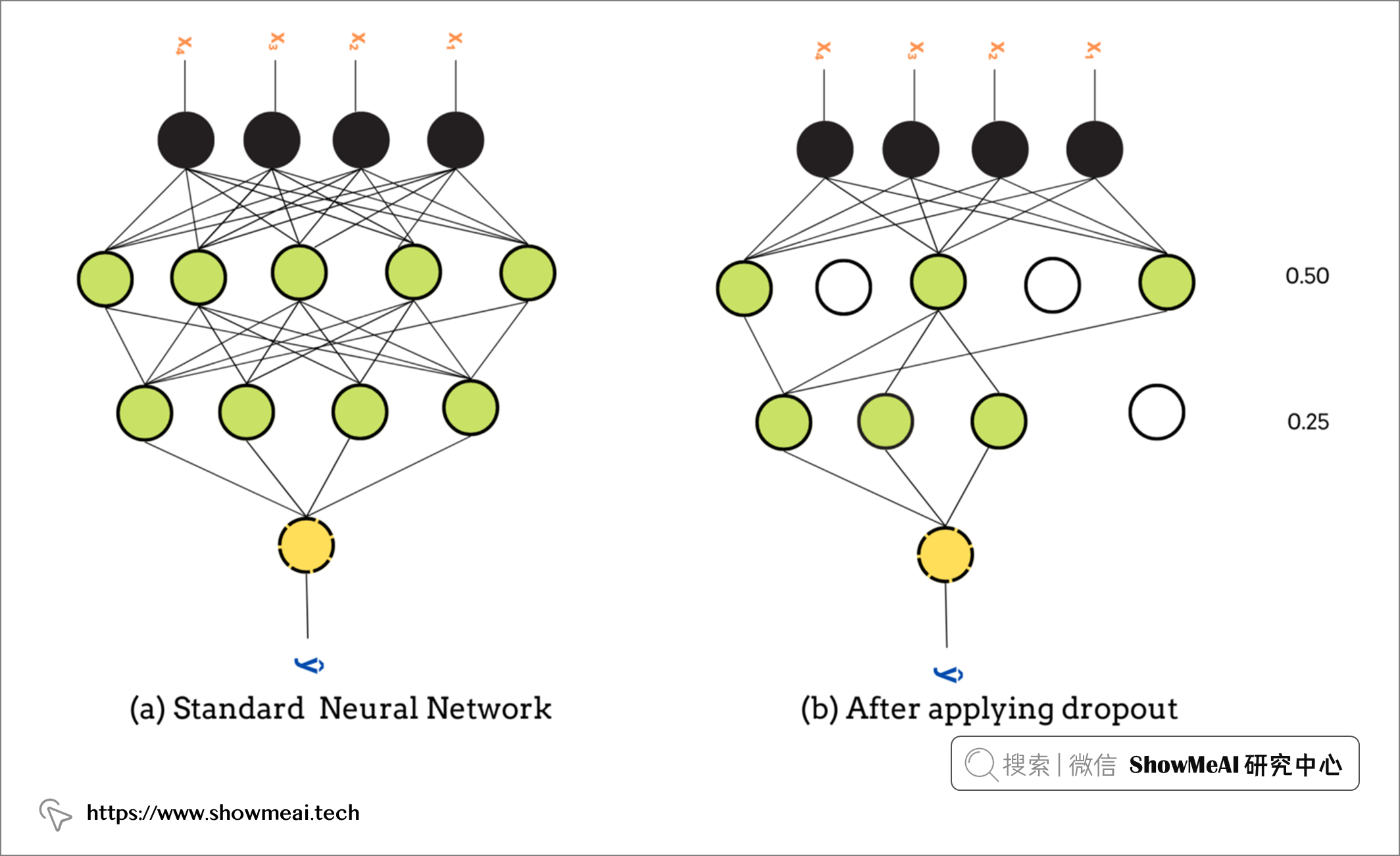
Dropout 层是解决深度神经网络中过度拟合的最常用方法。 它通过动态调整网络来减少过拟合的概率。
Dropout 层 随机 在训练阶段以概率rate随机将输入单元丢弃(可以认为是对输入置0),未置0的输入按 1/(1 - rate) 放大,以使所有输入的总和保持不变。
丢弃率rate 是主要参数,范围从 0 到 1。0.5 的rate取值意味着 50% 的神经元在训练阶段从网络中随机丢弃。
TensorFlow中的dropout使用方式如下
tf.keras.layers.Dropout(rate, noise_shape=None, seed=None)
?参数
rate: 在 0 和 1 之间浮动,丢弃概率。noise_shape:1D 整数张量,表示将与输入相乘的二进制 dropout 掩码的形状。seed: 随机种子。import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Reshape
from tensorflow.keras.layers import Dropout
def create_model():
model = Sequential()
model.add(Dense(60, input_shape=(60,), activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(30, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
return model
adam = tf.keras.optimizers.Adam()
model.compile(loss='binary_crossentropy', optimizer=adam, metrics=['accuracy'])
model = create_model()
model.summary()
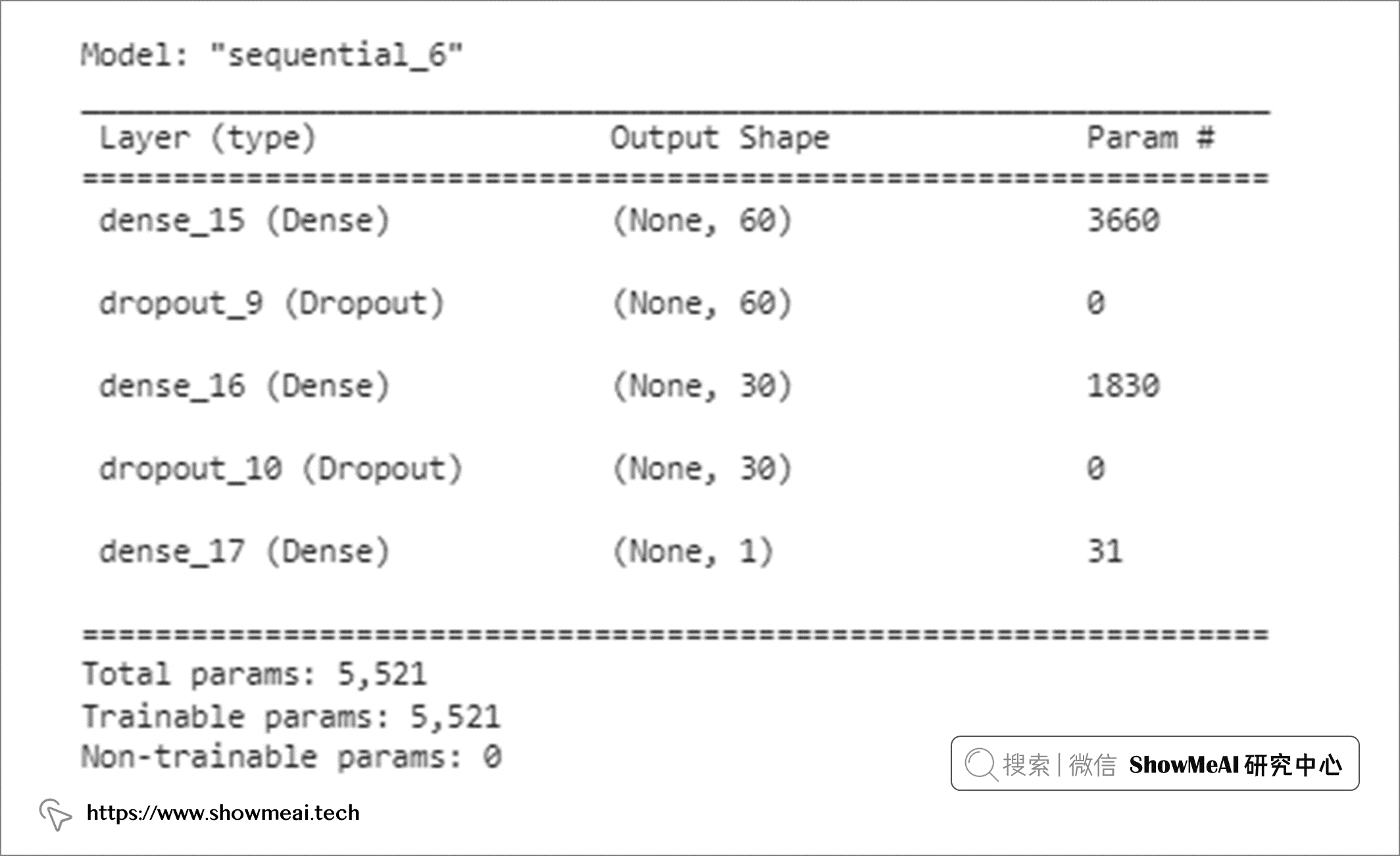
在向神经网络添加 dropout 层时,有一些技巧大家可以了解一下:
关于正则化的详细原理知识,大家可以查看ShowMeAI制作的深度学习系列教程和对应文章
正则化是一种通过惩罚损失函数来降低网络复杂性的技术。 它为损失函数添加了一个额外的权重约束部分,它在模型过于复杂的时候会进行惩罚(高loss),简单地说,正则化限制权重幅度过大。
L1 正则化的公式如下:

L2 正则化公式如下:

在TensorFlow搭建神经网络时,我们可以直接在添加对应的层次时,通过参数设置添加正则化项。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Reshape
from tensorflow.keras.layers import Dropout
def create_model():
# 构建模型
model = Sequential()
# 添加正则化
model.add(Dense(60, input_shape=(60,), activation='relu', kernel_regularizer=keras.regularizers.l1(0.01)))
model.add(Dropout(0.2))
# 添加正则化
model.add(Dense(30, activation='relu', kernel_regularizer=keras.regularizers.l2(0.001)))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
return model
adam = tf.keras.optimizers.Adam()
model.compile(loss='binary_crossentropy', optimizer=adam, metrics=['accuracy'])
model = create_model()
model.summary()
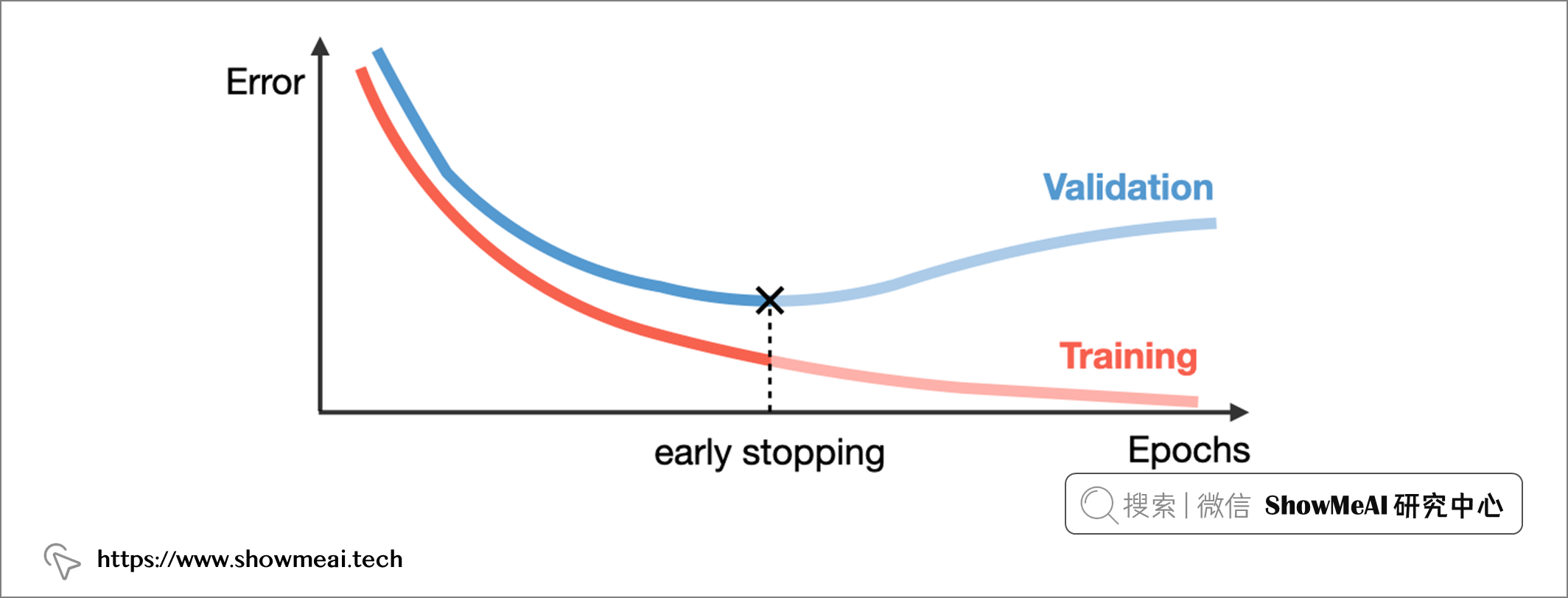
在深度学习中,一个 epoch指的是完整训练数据进行一轮的训练。迭代轮次epoch的多少对于模型的状态影响很大:如果我们的 epoch 设置太大,训练时间越长,也更可能导致模型过拟合;但过少的epoch可能会导致模型欠拟合。
Early stopping早停止是一种判断迭代轮次的技术,它会观察验证集上的模型效果,一旦模型性能在验证集上停止改进,就会停止训练过程,它也经常被使用来缓解模型过拟合。
Keras 有一个回调函数,可以直接完成early stopping。
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0,
patience=0,
verbose=0,
mode='auto',
baseline=None,
restore_best_weights=False
)
?参数
min 模式中, 当被监测的数据停止下降,训练就会停止;在 max 模式中,当被监测的数据停止上升,训练就会停止;在 auto 模式中,方向会自动从被监测的数据的名字中判断出来。from tensorflow.keras.callbacks import EarlyStoppingearly_stopping = EarlyStopping(monitor='loss', patience=2)history = model.fit(
X_train,
y_train,
epochs= 100,
validation_split= 0.20,
batch_size= 50,
verbose= "auto",
callbacks= [early_stopping]
)
ShowMeAI在本篇内容中,对缓解过拟合的技术做了介绍和应用讲解,大家可以在实践中选择和使用。『数据增强』技术将通过构建和扩增样本集来缓解模型过拟合,dropout 层通过随机丢弃一些神经元来降低网络复杂性,正则化技术将惩罚网络训练得到的大幅度的权重,early stopping 会防止网络过度训练和学习。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的