目录
今天亲手体验了一下meta公司发布的Segment Anything,我们认为是cv界的chatgpt,这个模型太厉害了,厉害到可以对任意一张图进行分割,他们的网站上的例子也是挺复杂的,能够说明其强大的能力—demo链接,人工智能的技术迭代真是太快了。在模型的介绍中,有句话着实惊人——号称:“SAM已经学会了物体是什么的一般概念”:

通常人们认为,人工智能大致可以分为三个阶段:
弱人工智能(Weak AI)简称弱智,指特定场景解决特定领域的问题。比如前段时间出现的AlphaGo,实现了围棋领域的的人工智能。
强人工智能更贴切的翻译是通用人工智能,就是以ChatGPT为代表的完全人工智能,能够适应人类大部分甚至是所有工作领域的一类人工智能。可以说我们如今,正在处于通用人工智能技术突破的时间转折点上。
顾名思意,这个时候,人工智能在人类定义的”智能“领域已经全面超过了人类,随着量子计算等技术发展,相信实现是时间问题。真希望这个时代晚点到来,或者那时候,人类或许已经和超人工智能实现了融合,成为了新一代的超人。也希望那个时代,人类的道德境界也实现了满格。
笔者上传了自己的一个棋盘图片,利用Segment Anything提供的模型工具进行了测试,测试结果发现,能够很好地抠出棋盘中的棋子。
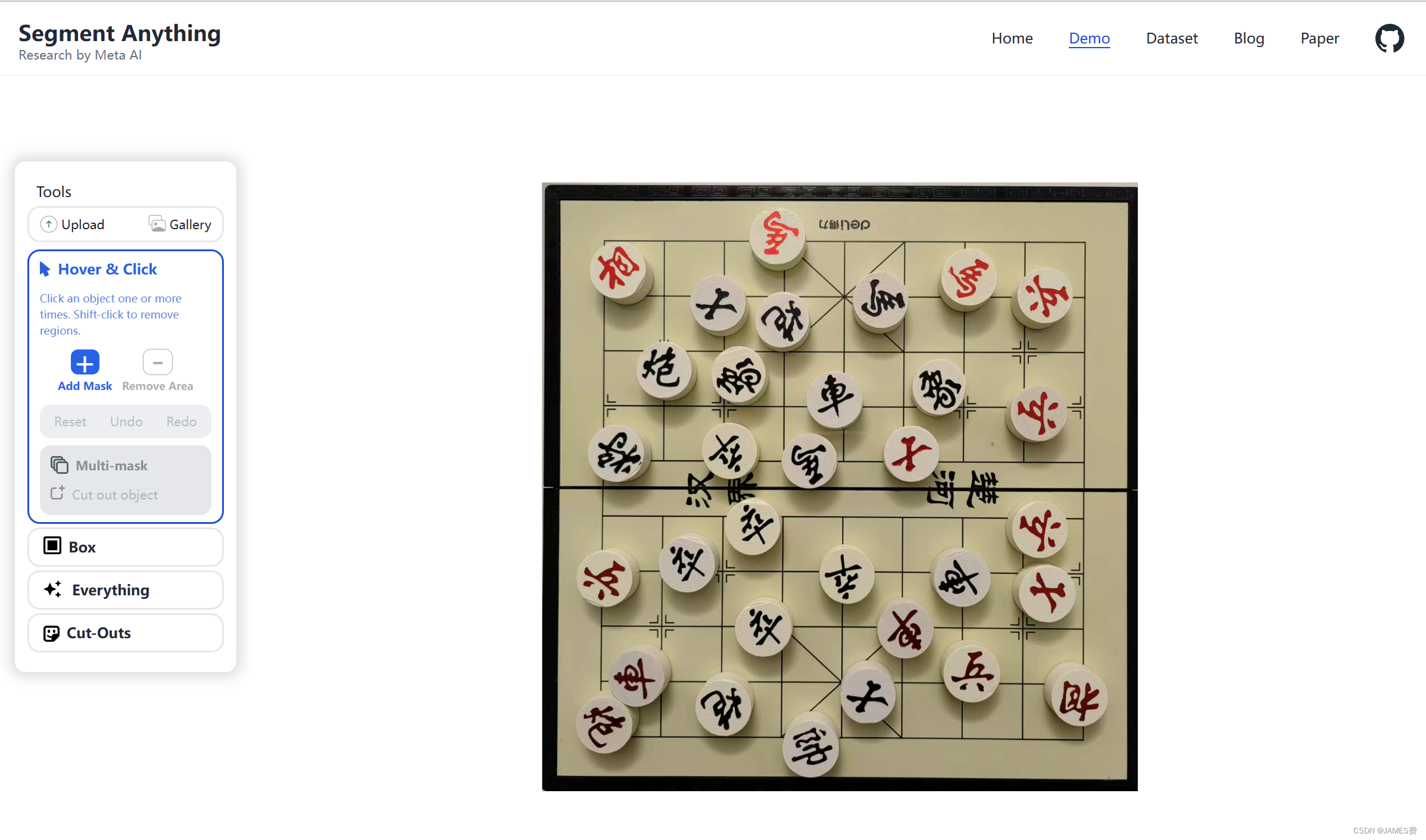
上传后,通过一点时间的识别后,把鼠标放到图片上面,就可以对上面的棋子做出响应,显然自动分离出了棋子棋盘。有一点厉害的是,它把棋子的厚度也给识别出来,认为也是棋子的一部分。

Segment Anything提供了手动框选分割功能,此外还有一个牛逼的功能是,自动对图像进行分割:
点击自动分割后,可以准确的识别出棋子:

识别完后,它会自动切出分离的物体如下32个棋子一个不少:

输入一张随机的羽毛球图片:

识别结果如下:

好吧,我承认,我用opecv远远还不能达到以上的效果。
以上的象棋、羽毛球图片其实场景并不复杂,比它网站上面的图片要简单的多,但是足够可以说明一件事,该模型可以胜任多个领域的机器视觉任务,或者是给各领域的cv工作者提供了底层解决方案或者思路。
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
我正在尝试在配备ARMv7处理器的SynologyDS215j上安装ruby2.2.4或2.3.0。我用了optware-ng安装gcc、make、openssl、openssl-dev和zlib。我根据README中的说明安装了rbenv(版本1.0.0-19-g29b4da7)和ruby-build插件。.这些是随optware-ng安装的软件包及其版本binutils-2.25.1-1gcc-5.3.0-6gconv-modules-2.21-3glibc-opt-2.21-4libc-dev-2.21-1libgmp-6.0.0a-1libmpc-1.0.2-1libm
下面的代码工作正常:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson)do|key,oldv,newv|ifkey==:aoldvelsifkey==:bnewvelsekeyendendputskerson.inspect但是如果我在“ifblock”中添加return,我会得到一个错误:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson
我正在使用macos,我想使用ruby驱动程序连接到sqlserver。我想使用tiny_tds,但它给出了缺少free_tds的错误,但它已经安装了。怎么能过这个?~brewinstallfreetdsWarning:freetds-0.91.112alreadyinstalled~sudogeminstalltiny_tdsBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtiny_tds:ERROR:Failedtobuildgemnativeextension.完整日志如下:/System
我有以下haml:9%strongAskedby:10=link_to@user.full_name,user_path(@user)11.small="(#{@question.created_at.strftime("%B%d,%Y")})"这当前将链接和日期放在不同的行上,当它看起来像“链接(日期)”并且日期的类跨度为小...... 最佳答案 您的代码将生成类似这样的html:Askedby:UsernameApril26,2011当您使用类似.small的东西(即使用点而不指定元素类型)时,haml会创建一个implicit
下面有没有更优雅的方法来实现这个:输入:array=[1,1,1,0,0,1,1,1,1,0]输出:4我的算法:streak=0max_streak=0arr.eachdo|n|ifn==1streak+=1elsemax_streak=streakifstreak>max_streakstreak=0endendputsmax_streak 最佳答案 类似于w0lf'sanswer,但通过从chunk返回nil来跳过元素:array.chunk{|x|x==1||nil}.map{|_,x|x.size}.max
2022年底,OpenAI的预训练模型ChatGPT给人工智能领域的爱好者和研究人员留下了深刻的印象和启发,他展现的惊人能力将人工智能的研究和应用热度推向高潮,网上也充斥着和ChatGPT的各种聊天,他可以作诗、写小说、写代码、讨论疫情问题等。下面就是一些他的神回复:人命关天的坑: 写歌,留给词作者的机会不多了。。。 回答人类怎么样面对人工智能: 什么是ChatGPT?借用网上的一段介绍,ChatGPT是由人工智能研究实验室OpenAI在2022年11月30日发布的全新聊天机器人模型,一款人工智能技术驱动的自然语言处理工具。它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动
目录ChatGPT简介技术原理应用未来发展ChatGPT的10 种用法ChatGPT简介ChatGPT是一种基于深度学习的大型语言模型,由OpenAI公司开发。技术原理GPT是GenerativePre-trainedTransformer的缩写,意为生成式预训练变压器。它的技术原理是使用了一个基于注意力机制的变压器(Trans
有没有一种有效的方法来做到这一点。我有一个数组a=[1,2,2,3,1,2]我想按升序输出出现的频率。示例[[3,1],[1,2],[2,3]]这是我的ruby代码。b=a.group_by{|x|x}out={}b.eachdo|k,v|out[k]=v.sizeendout.sort_by{|k,v|v} 最佳答案 a=[1,2,2,3,1,2]a.each_with_object(Hash.new(0)){|m,h|h[m]+=1}.sort_by{|k,v|v}#=>[[3,1],[1,2],[2,3]]
我认为我对线程在ruby中的工作原理存在根本性的误解,我希望获得一些见解。我想要一个简单的生产者和消费者。首先,生产者线程从文件中提取行并将它们粘贴到SizedQueue中;当那些用完时,在末端贴上一些token,让消费者知道事情已经完成。require'thread'numthreads=2filename='edition-2009-09-11.txt'bq=SizedQueue.new(4)producerthread=Thread.new(bq)do|queue|File.open(filename)do|f|f.eachdo|r|queue现在有几个消费者。为简单起见,让