堆是一种非线性结构,可以把堆看作一棵二叉树,也可以看作一个数组,即:堆就是利用完全二叉树的结构来维护的一维数组。
堆可以分为大顶堆和小顶堆:
大顶堆:每个结点的值都大于或等于其左右孩子结点的值。
小顶堆:每个结点的值都小于或等于其左右孩子结点的值。
用简单的公式来描述一下堆的定义就是:
大顶堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]
小顶堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]
如果是排序,求升序用大顶堆,求降序用小顶堆。一般我们说 topK 问题,就可以用大顶堆或小顶堆来实现,即最大的 K 个:小顶堆/最小的 K 个:大顶堆。
大顶堆的构建过程就是从最后一个非叶子结点开始从下往上调整。
最后一个非叶子节点怎么找?这里我们用数组表示待排序序列,则最后一个非叶子结点的位置是:数组长度/2-1。假如数组长度为9,则最后一个非叶子结点位置是 9/2-1=3。
画个图理解下,以 [3, 7, 16, 10, 21, 23] 为例:
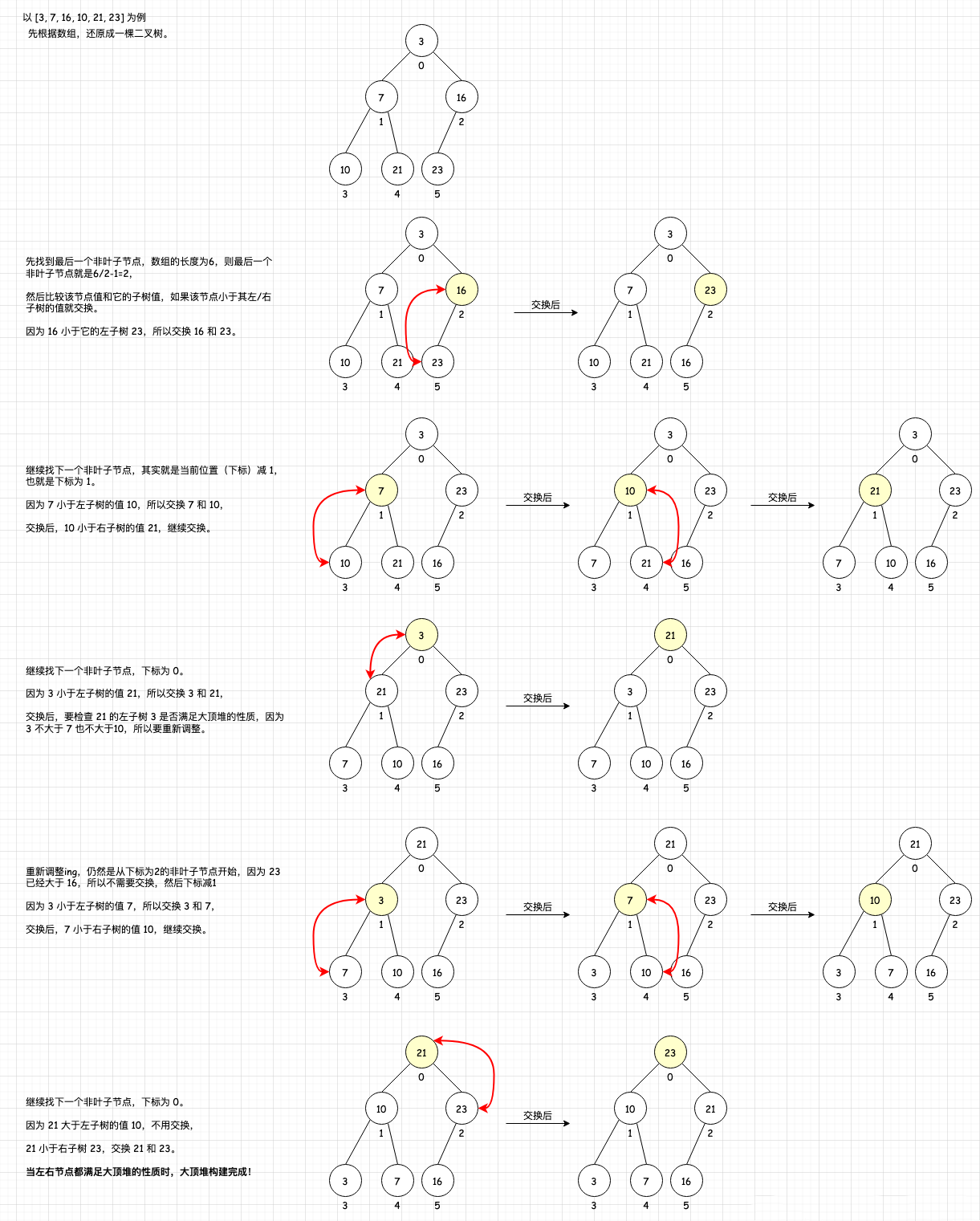
将待排序序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值,如此反复执行,便能得到一个有序序列了。
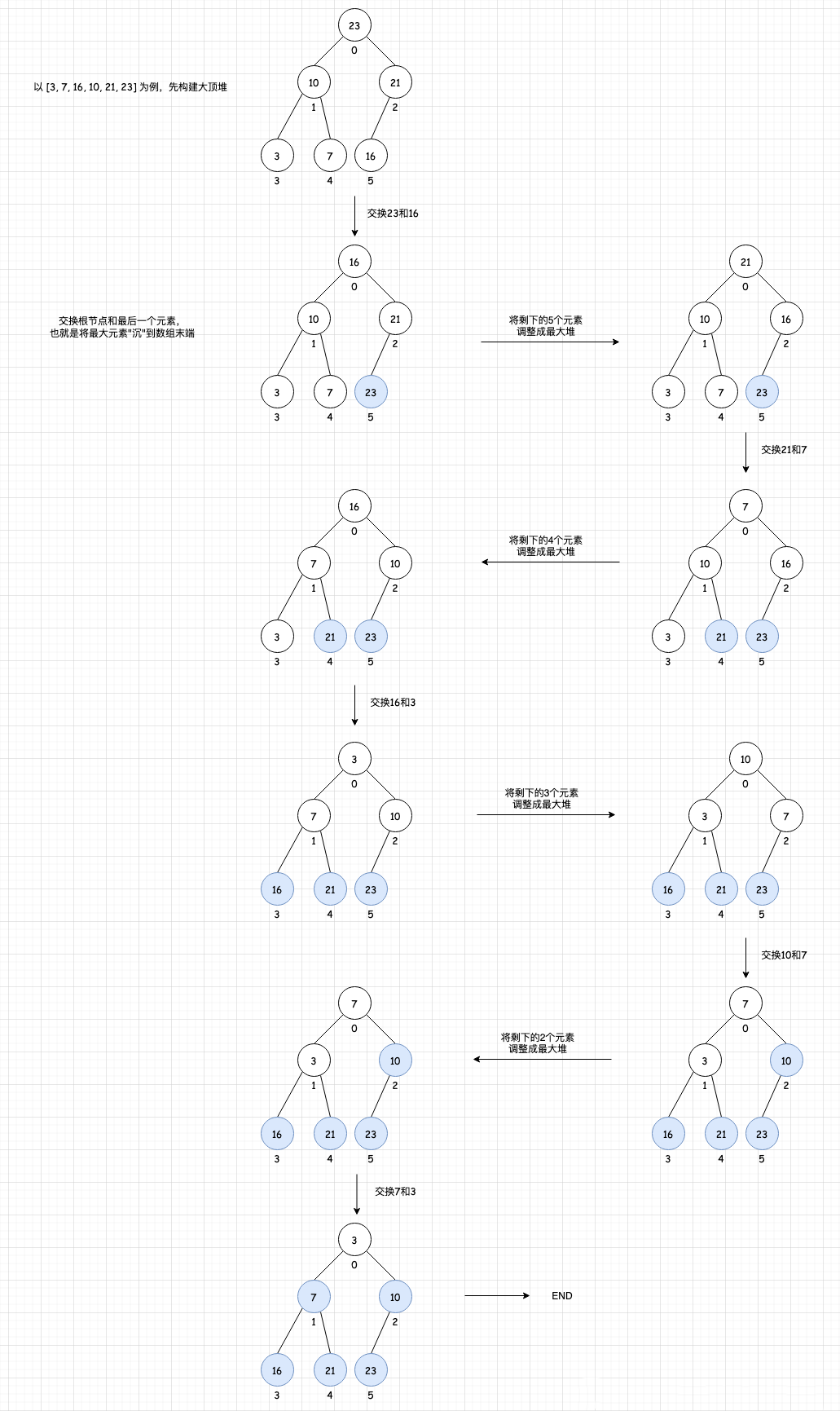
该排序过程可以用下面 4 步概括:
第 1 步:先 n 个元素的无序序列,构建成大顶堆;
第 2 步:将根节点与最后一个元素交换位置,(将最大元素"沉"到数组末端);
第 3 步:交换过后可能不再满足大顶堆的条件,所以需要将剩下的 n-1 个元素重新构建成大顶堆;
第 4 步:重复第 2 步、第 3 步直到整个数组排序完成。
同样以 [3, 7, 16, 10, 21, 23] 为例:
#include <stdio.h>
void g1(int *a, int n, int i){
while (2 * i <= n){
int j = 2 * i;
int v = a[j - 1];
if (j < n && v < a[j]){
v = a[j];
j += 1;
}
if (a[i - 1] < v){
int tmp = a[i - 1];
a[i - 1] = v;
a[j - 1] = tmp;
i = j;
} else{
break;
}
}
}
int g2(int *a, int n, int m){
int i;
for (i = n / 2; i > 0; --i)
g1(a, n, i);
for (i = 0; i < n && a[i] != m; ++i);
int j = 0;
for (++i; i > 0; i /= 2)
++j;
return j;
}
int main(int argc, char* argv[]){
int a[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};
int n = sizeof(a) / sizeof(a[0]);
printf("%d", g2(a, n, 8));
return 0;
}
g1 函数的作用即为构建大顶堆,代码第29行:当 i = 7 时,a[i] = 8,退出循环,程序执行后控制台输出 j 的值为:4。
为什么像nil、true或false这样的系统对象在Ruby中有一个固定的对象ID。我还尝试打印出数字的对象ID,它们是相同的并且遵循奇数序列模式。对此有什么解释吗?[nil,true,false].each{|o|printo.object_id,''}420=>[nil,true,false]>>(0..50).each{|i|printi.object_id,''}13579111315171921232527293133353739414345474951535557596163656769717375777981838587899193959799101=>0..50
我有一个Windows控制台应用程序,它应该可以运行数天和数月而无需重新启动。该应用程序从MSMQ检索“工作”并对其进行处理。有30个线程同时处理一个工作block。来自MSMQ的每个工作block大约为200kb,其中大部分分配在单个String对象中。我注意到,在处理了大约3-4千个这些工作block之后,应用程序的内存消耗高得离谱,消耗了1-1.5GB的内存。我通过探查器运行该应用程序,并注意到大部分内存(可能是gig左右)在大型对象堆中未使用,但结构是碎片化的。我发现这些未使用(垃圾收集)字节中有90%是以前分配的String。然后我开始怀疑来自MSMQ的字符串被分配、使用然后
从这里http://blogs.msdn.com/b/visualstudioalm/archive/2014/04/02/diagnosing-memory-issues-with-the-new-memory-usage-tool-in-visual-studio.aspx托管:对于托管应用程序,分析器默认仅收集托管堆信息。托管堆分析是通过在分析器中捕获一组CLRETW事件来完成的。native:对于native应用程序,分析器仅收集native堆信息。为了收集native堆信息,我们启用了堆栈跟踪和堆跟踪收集(ETW),这些非常冗长并且会创建大型诊断session文件。我的问题是
我正在使用JVMsunjava-1.6.0_21运行服务器应用程序。我的应用程序数据量大,充当缓存服务器。所以它存储了很多我们不希望在整个应用程序运行过程中获得GC的长期生存数据。我正在设置以下JVM参数-Xmx16384M和-Xms16384M。加载所需数据后,应用程序的内存使用情况如下总堆空间为:13969522688最大堆空间为:15271002112可用堆空间为:3031718040长期(老一代)堆存储:Used=10426MBMax=10922MB已用/最大=95%老一代使用-我已经确认这是由于实际数据,预计不会免费。我的问题是,默认情况下JVM堆空间的大小(它分配10922
我试图以编程方式找出调用我程序的JVM的最大permgen和最大堆大小,而不是它们当前可用的大小。有办法吗?我熟悉JavaRuntime对象中的方法,但不清楚它们真正传递的是什么。或者,有没有办法询问Eclipse为这两个分配了多少? 最佳答案 为最大permgen尝试这样的事情:publicstaticlonggetPermGenMax(){for(MemoryPoolMXBeanmx:ManagementFactory.getMemoryPoolMXBeans()){if("PermGen".equals(mx.getName(
我看到一个奇怪的情况,Java8u45和java.util.Deflater.deflate(byte[]b,intoff,intlen,intflush)的输出缓冲区很小与小输出缓冲区一起使用时的方法。(我正在编写一些与WebSocket即将推出的permessage-deflate扩展相关的低级网络代码,因此小缓冲区对我来说是现实)示例代码:packagedeflate;importjava.nio.charset.StandardCharsets;importjava.util.zip.Deflater;publicclassDeflaterSmallBufferBug{publ
我可以理解,使用压缩的oops,我们只能使用32GB的RAM。有没有办法我可以通过分配2个堆或其他东西来使用更多?谢谢葡萄藤 最佳答案 您不能有多个堆(尽管您可以有多个JVM,这称为向外扩展而不是向上扩展)。JVM在32GiB内存以下自动使用压缩对象指针。如果您了解它的工作原理(从每个地址中删除最年轻的三位,因为由于内存对齐,它们始终为0),您就会明白您不能再进一步了。有一个有趣的事实:一旦超过这个32GiB边界,JVM将停止使用压缩对象指针,从而有效减少可用内存。这意味着您必须将JVM堆增加到32GiB以上。据大Everythin
请推荐一些非常详细地处理这些主题的网站或书籍。我需要更好地理解这些概念(引用C++):堆栈和堆符号表实现范围规则函数调用的实现 最佳答案 您可以阅读DragonBook,但我想这可能太多了。 关于c++-阅读堆栈/堆和符号表概念的好资源是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/2064553/
int*ip=newint[10];for(inti=0;i上面的代码是我试图用来了解堆栈和堆的测试函数的一小段。我不完全确定正确的顺序是什么。这是我目前所拥有的:当创建指针ip时,它指向由于"new"声明而在堆上创建的大小为10的新int数组。0-9从0-9加入到数组中。指针现在传递给myfun,这意味着myfun有一个指向堆上相同内存空间的指针。delete[]ip;删除堆上分配给ip指针的内存。传递给myFun的指针现在指向任何内容。一旦函数完成,ip变量将被删除,因为它只是函数的本地变量。是否有人能够澄清我是否正确并纠正我哪里出错了?此外,如果我在那之后尝试继续使用ip,它会不
我正在检查C++中两个二维数组的行为,一个从堆栈分配,一个从堆分配。我创建了两个相同形状的二维数组,并用一些数据填充这些数组。然后我尝试用两种不同的方法读取数组,第一种是使用简单的数组索引格式“Arr[ROW][COLUMN]”。然后我使用指针取消引用读取数组,我得到了堆分配数组的两个不同结果,但堆栈分配数组的结果相同。我试图理解为什么结果不同。如果有人可以提供任何说明,我将不胜感激。提前致谢。我正在运行的代码如下:#includeusingnamespacestd;intmain(){introws=6;intcolumns=3;//allocatefromthestack.doub