⭐️前面的话⭐️
本篇文章将介绍Spring项目的创建,IDEA国内源的配置以及Bean的存储与读取,所谓的Bean其实就是对象的意思,更详细地说Spring Bean是被实例的,组装的及被Spring 容器管理的Java对象。
小贴士:本专栏所有题目来自牛客->面试刷题必用工具
📒博客主页:未见花闻的博客主页
🎉欢迎关注🔎点赞👍收藏⭐️留言📝
📌本文由未见花闻原创,CSDN首发!
📆首发时间:🌴2022年7月24日🌴
✉️坚持和努力一定能换来诗与远方!
💭推荐书籍:📚《Spring实战》
💬参考在线编程网站:🌐牛客网🌐力扣
博主的码云gitee,平常博主写的程序代码都在里面。
博主的github,平常博主写的程序代码都在里面。
🍭作者水平很有限,如果发现错误,一定要及时告知作者哦!感谢感谢!
📌导航小助手📌
注意事项:博主安利一款刷题面试的神器,如果有小伙伴还没有注册牛客,可以点击下方链接进行注册,注册完就能立即刷题了。不仅是刷题,上面还有很多有关就业的面经,面试题库,以及名企的模拟面试,我非常推荐它,博主自己用的也很多,也刷了不少题了!下图可以作证:
注册地址:牛客网
有关任何问题都可以与博主交流,你可以在评论区留言,也可以私信我,更可以加上博主的vx与博主一对一交流(文章最下方有)。

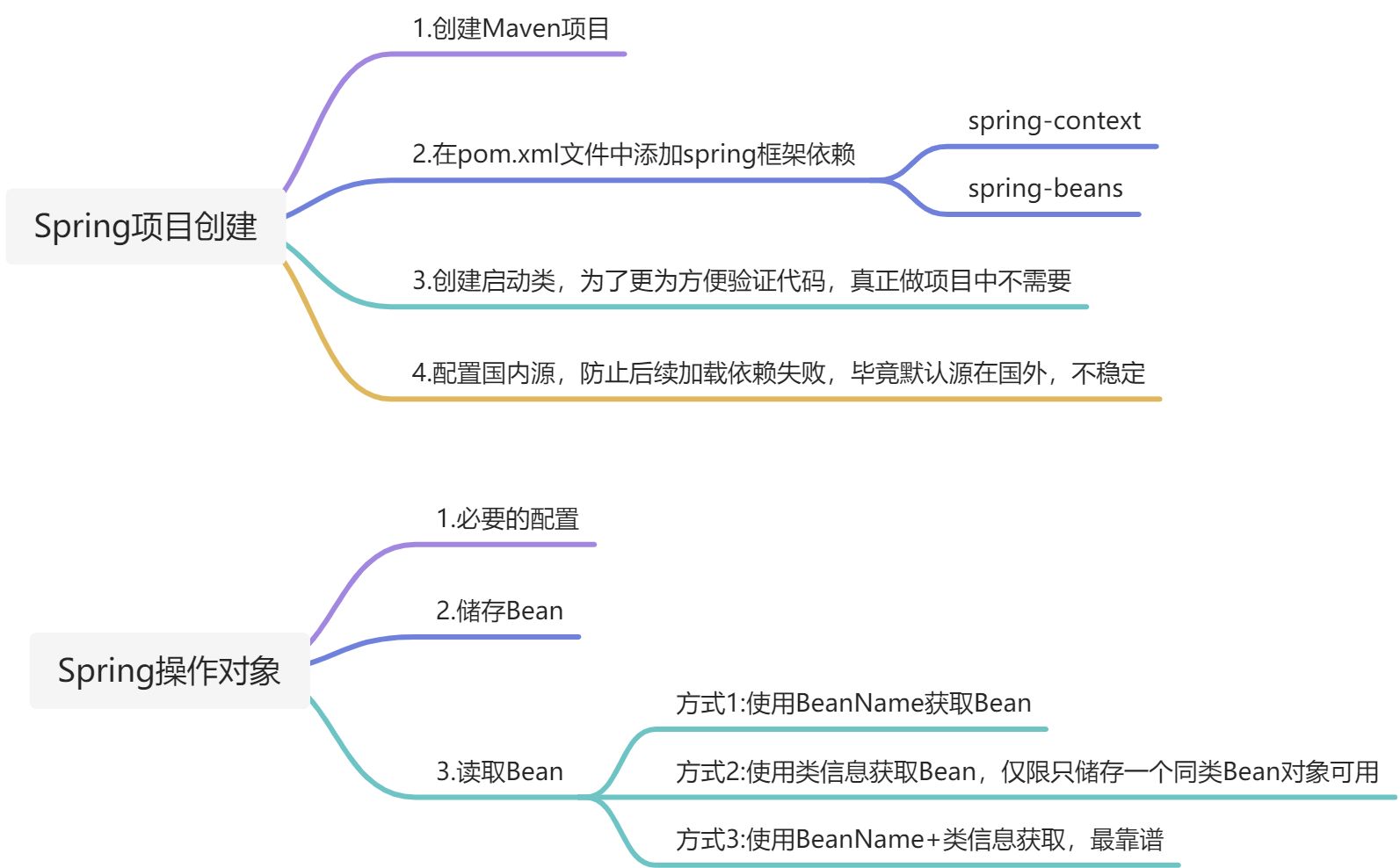
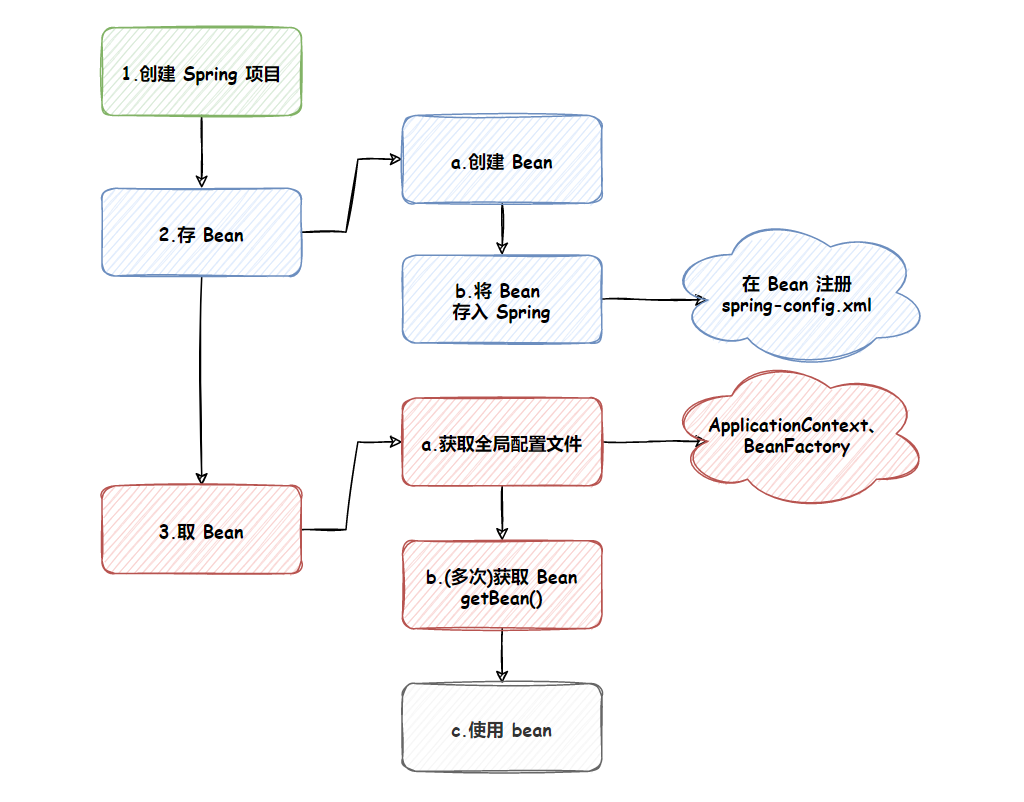
本文思维导图:
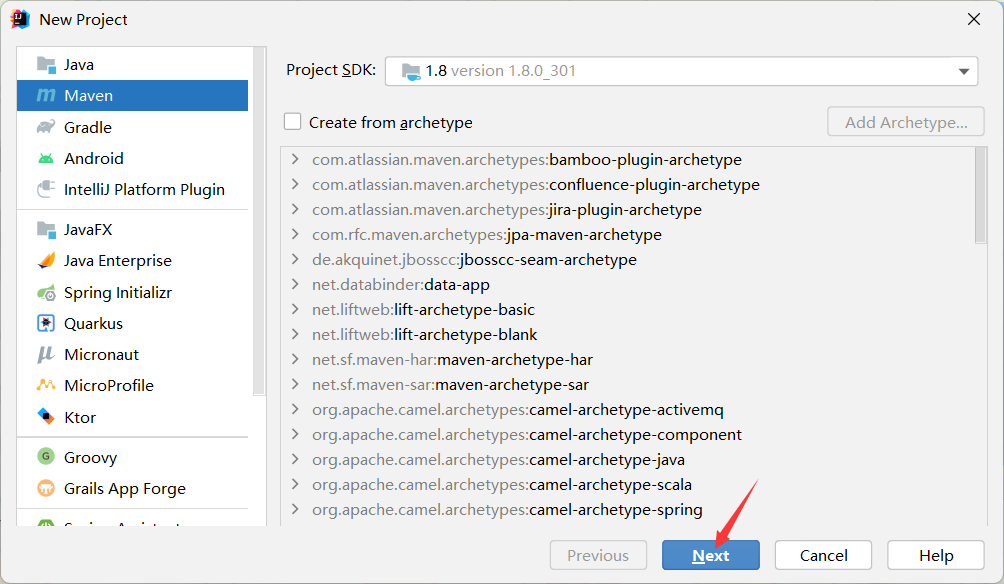
第一步,创建Maven项目,Spring也是基于Maven的。
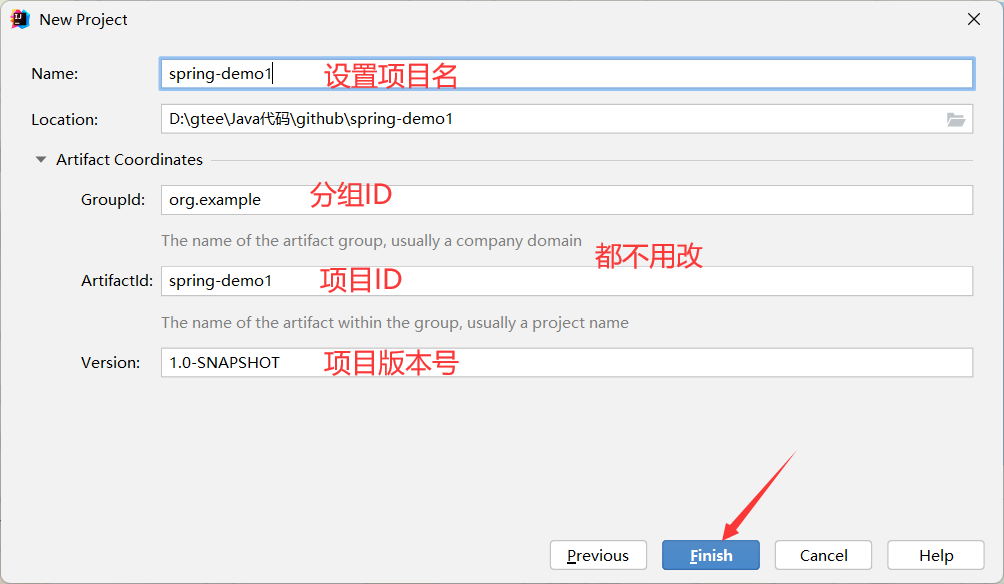
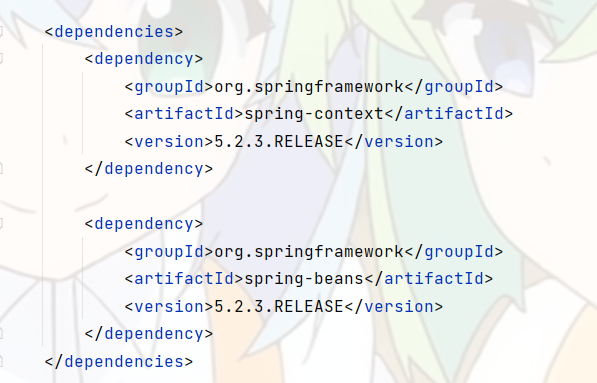
第二步,在Maven项目中添加Spring的支持(spring-context, spring-beans)
在pom.xml文件添加依赖项。
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.2.3.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>5.2.3.RELEASE</version>
</dependency>
</dependencies>
刷新等待加载完成。
第三步,创建启动类与main,用来做简单的测试
在java目录创建类,写代码即可,因为这里只演示怎么创建Spring项目和介绍Spring的简单使用,就不依赖那些Tomcat什么的了,直接写一个Main类更直观。
由于国外源不稳定,可能第二步引入spring依赖会失败,所以下面介绍如何配置国内镜像源。
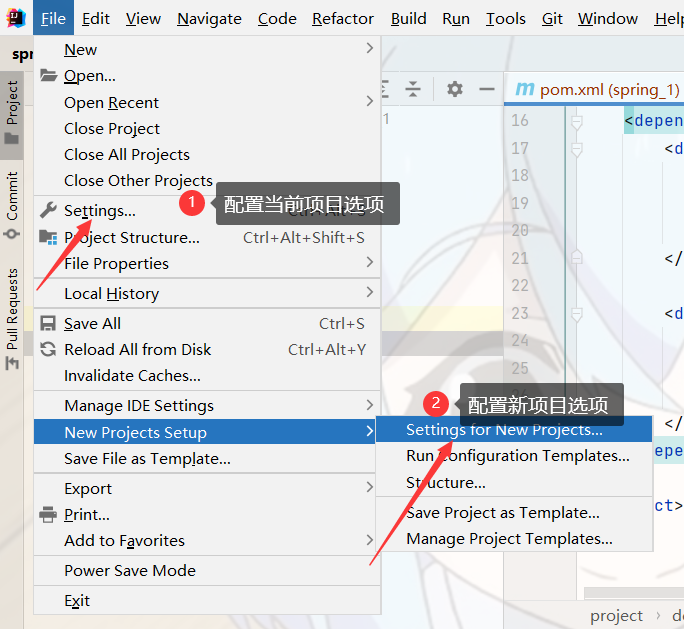
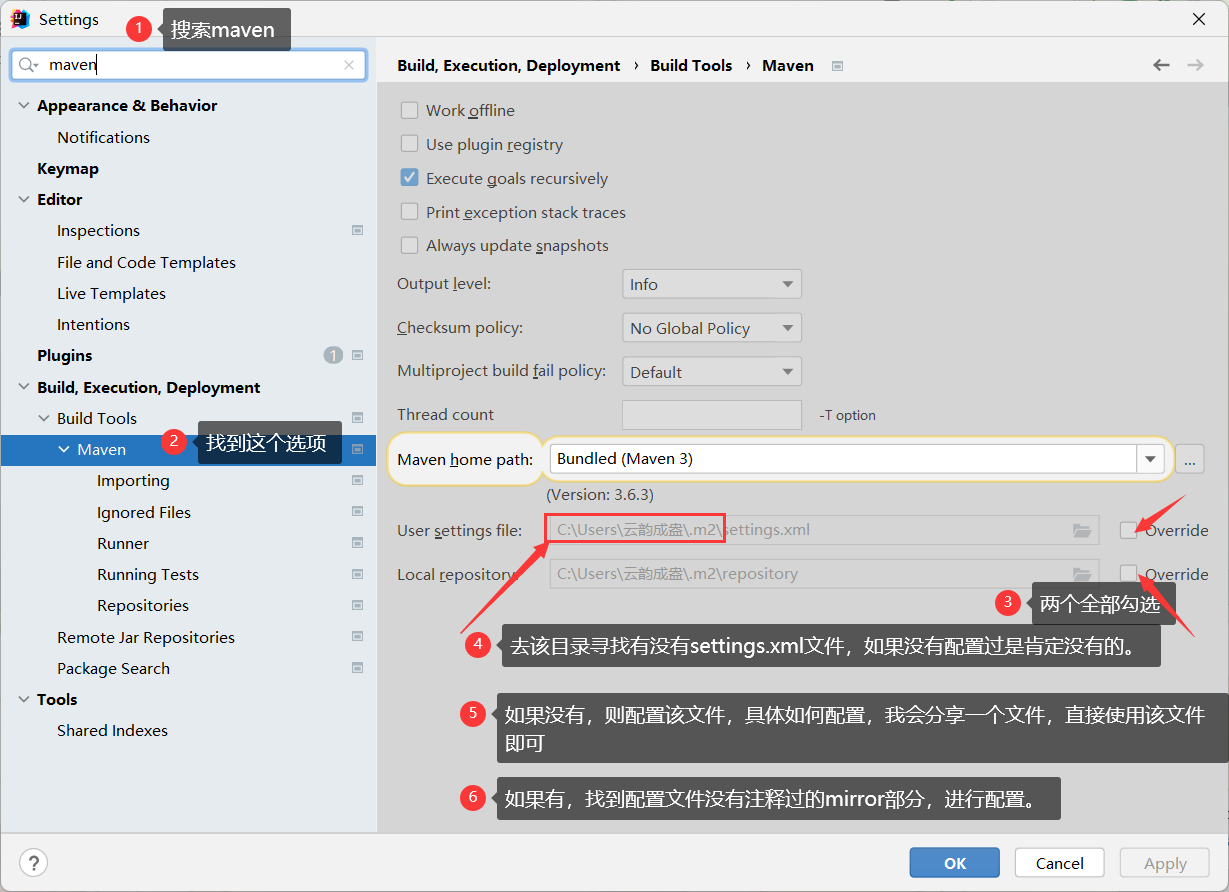
现成的settings.xml文件链接:
地址1:github
地址2:语雀
如果你已经有了settings文件,但没有配置mirror,配置内容如下:
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
添加spring配置文件(首次才需要,非首次可忽略此步骤)
右键resources目录,新建一个.xml配置文件,文件名推荐spring.xml或者spring-config.xml。
创建一个spring.xml配置文件,配置内容:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
</beans>
第一步,创建Bean对象。
比如我们要注入一个User对象,就先的创建一个User类。
package com.bean;
public class User {
public void sayHi(String name) {
System.out.println("你好!" + name);
}
}
将Bean通过配置文件,注入到spring中,即在spring配置文件中通过以下语句注入。
<bean id="user" class="com.bean.User"></bean>
spring中对象的储存是通过键值对来存储的,其中key为id,value为class。
命名规范:id使用小驼峰命名,如userid,class使用大驼峰命名,如userId。
想要从spring中将Bean对象读取出来,先要得到spring上下文对象,相当于得到了spring。再通过spring上下文对象提供的方法获取需要使用的Bean对象。最后就能使用Bean对象了。
import com.bean.User;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Main {
public static void main(String[] args) {
//1.得到上下文对象
ApplicationContext context = new ClassPathXmlApplicationContext("spring.xml");
//2.获取bean对象,此处是根据id获取
User user = (User) context.getBean("user");
//3.使用bean
user.sayHi("zhangsan");
}
}
运行结果:
你好!zhangsan
Process finished with exit code 0
还可以使用Bean工厂(旧)来获取Bean。
import com.bean.User;
import org.springframework.beans.factory.BeanFactory;
import org.springframework.beans.factory.xml.XmlBeanFactory;
import org.springframework.core.io.ClassPathResource;
public class Main2 {
public static void main(String[] args) {
//1.得到Bean工厂
BeanFactory factory = new XmlBeanFactory(new ClassPathResource("spring.xml"));
//2.获取Bean
User user = (User) factory.getBean("user");
//3.使用
user.sayHi("李四");
}
}
虽然Bean工厂XmlBeanFactory类现在已经废弃了,但是目还能使用的,当然创建Bean工厂有新的方式,但老的方式比较直观,因此演示采用老的方式创建。
运行结果:
你好!李四
Process finished with exit code 0
发现ApplicationContext与BeanFactory都可以从容器中获取Bean,都提供了getBean方法,那问题来了,ApplicationContext与BeanFactory有什么区别?
相同点:都可以从容器中获取Bean,都提供了getBean方法。
不同点:
BeanFactory是ApplicationContext的父类, BeanFactory只提供了基础访问Bean对象的功能,而ApplicationContext除了拥有 BeanFactory的全部功能,还有其他额外功能的实现,如国际化,资源访问等功能实现。 BeanFactory按需加载Bean,属于懒汉方式,ApplicationContext是饿汉方式,在创建时会将所有的Bean都加载,以备使用。证明:
我们在bean目录下添加一个Blog类,并完善Blog与User类的构造方法,当类被构造时会发出一些信号,在获取上下文或工厂时根据这些信号让我们感知到它是否会被构造。

import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Main3 {
public static void main(String[] args) {
//1.得到上下文对象
ApplicationContext context = new ClassPathXmlApplicationContext("spring.xml");
}
}
运行结果:
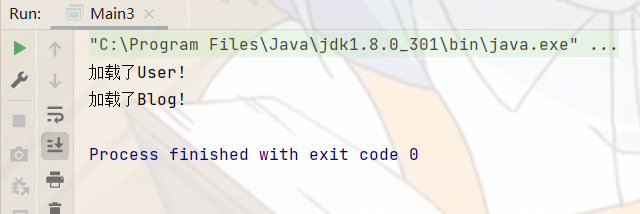
ApplicationContext创建时,会将所有的对象都构造,饿汉的方式。
import org.springframework.beans.factory.BeanFactory;
import org.springframework.beans.factory.xml.XmlBeanFactory;
import org.springframework.core.io.ClassPathResource;
public class Main4 {
public static void main(String[] args) {
//1.得到Bean工厂
BeanFactory factory = new XmlBeanFactory(new ClassPathResource("spring.xml"));
}
}
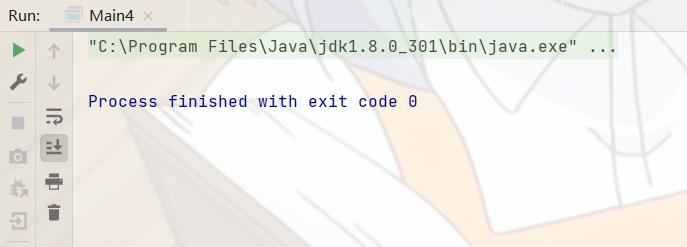
BeanFactory创建时,什么都没有,说明是懒汉的方式。
ApplicationContext中的多种getBean方法:
方法1:根据 bean name获取bean。
User user = (User) context.getBean("user");
方法2:根据bean type获取bean。
User user = (User) context.getBean(User.class);
只有beans中只有一个类的实例没有问题,但是个有多个同类的实例,会有问题,即在spring中注入多个同一个类的对象,就会报错。
我们来试一试,首先在Spring配置文件,注入多个User对象:
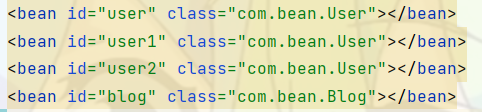
然后我们再通过这种方式来获取对象,我们发现报错了,报错信息如下:
Exception in thread "main" org.springframework.beans.factory.NoUniqueBeanDefinitionException: No qualifying bean of type 'com.bean.User' available: expected single matching bean but found 3: user,user1,user2
抛出了一个NoUniqueBeanDefinitionException异常,表示注入的对象不是唯一的。
方法3:综合上述两种,可以根据bean name与bean type来获取bean
相比方法1,更加健壮。
User user = context.getBean("user", User.class);
小结:
到文章最后,再来安利一下吧,博主也是经常使用,并且也经常在牛客上刷题,题库也非常丰富:学习,刷题,面试,内推都有。也欢迎与博主交流有关刷题,技术方面,以及与博主聊聊天,交个朋友也好啊,毕竟有朋自远方来!

很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我对最新版本的Rails有疑问。我创建了一个新应用程序(railsnewMyProject),但我没有脚本/生成,只有脚本/rails,当我输入ruby./script/railsgeneratepluginmy_plugin"Couldnotfindgeneratorplugin.".你知道如何生成插件模板吗?没有这个命令可以创建插件吗?PS:我正在使用Rails3.2.1和ruby1.8.7[universal-darwin11.0] 最佳答案 随着Rails3.2.0的发布,插件生成器已经被移除。查看变更日志here.现在