目录
SQL Server数据库是Microsoft开发设计的一个关系数据库智能管理系统(RDBMS),现在是全世界主流数据库之一;
SQL Server数据库具备方便使用、可伸缩性好、相关软件集成程度高等优势,能够从单一的笔记本上运行或以高倍云服务器集群为基础,或在这两者之间任何东西上运行。尽管说成“任何东西”,可是依然要考虑有关的软件和硬件配置;
--判断数据库文件是否存在,如果存在就删除 exits是判断()语句是否返回值,如果有就返回true,否则就是false
IF EXISTS(SELECT * FROM sysdatabases WHERE name='StudentDB ')
--删除数据库
DROP DATABASE StudentDB
GO
CREATE DATABASE StudentDB --创建数据库
ON PRIMARY --定义在主文件组上的文件
(
NAME=stu_date, --逻辑名称
FILENAME='C:\sql\StudentDB.mdf', --物理名称
SIZE=10, --初始大小为10mb
MAXSIZE=unlimited, --最大限制为无限大
FILEGROWTH=10%) --主数据文件增长幅度为10%
LOG ON --定义事务日志文件
(
NAME=stu_log, --逻辑名称
FILENAME='C:\sql\StudentDB.ldf', --物理名称
SIZE=1, --初始大小为1mb
MAXSIZE=5, --最大限制为5mb
FILEGROWTH=1--事务日志增长幅度为1mb`
)
ALTER DATABASE database_name
{ ADD FILE <filespec>[,…n][ TO FILEGROUP filegroup_name ] /*在文件组中增加数据文件*/
| ADD LOG FILE <filespec>[,…n] /*增加日志文件*/
| REMOVE FILE logical_file_name /*删除数据文件*/
| ADD FILEGROUP filegroup_name /*增加文件组*/
| REMOVE FILEGROUP filegroup_name /*删除文件组*/
| MODIFY FILE <filespec> /*更改文件属性*/
| MODIFY NAME = new_dbname /*数据库更名*/
| MODIFY FILEGROUP filegroup_name {filegroup_property | NAME = new_filegroup_name }
| SET <optionspec> [ ,...n ] [ WITH <termination> ] /*设置数据库属性*/
| COLLATE < collation_name > /*指定数据库排序规则*/
}
GO
删除 StudentDB 数据库
DROP DATABASE StudentDB
GO
以上是建好数据库对数据库的操作,下面就是在数据库中添加表,对表进行操作。
Student(学生表)的表结构:
| 列 名 | 数 据 类 型 | 长度 | 可空 | 默认值 | 说 明 |
|---|---|---|---|---|---|
| 学号 | int | × | 无 | 主键,自增为1 | |
| 姓名 | nvarchar | 50 | × | 无 | |
| 性别 | nvarchar | 50 | √ | 1 | 1:男;0:女 |
| 出生时间 | 日期型(datetime) | 系统默认 | √ | 无 |
|
| 数学 | varchar | 50 | √ | 无 |
|
| 英语 | varchar | 50 | √ | 无 |
|
| 语文 | varchar | 50 | √ | 无 |
|
| 班级 | nvarchar | 50 | √ | 无 |
实例:
本代码演示如何创建“Student”的表和表中的结构。
该表包含8个列,列名分别是:“StuNo”、“StuName”、“StuSex”、“StuBir”、Math 、English 、Chinese 以及Classes ;
CREATE TABLE Student(
StuNo int NOT NULL identity(1,1) not null PRIMARY key ,
StuName char(8) NOT NULL ,
StuSex bit NULL DEFAULT (1) ,
StuBir datetime NULL ,
Math varchar(50),
English varchar(50),
Chinese varchar(50),
Classes nvarchar(50)
)
GO
这就是创建表的sql命令,成功后即可添加数据。
语法格式:
insert into 表名(字段名,...) values(值,...);
我们也可以指定所要插入数据的列:
INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....);
实例:
本例演示 “Student” 表插入记录的两种方式:
1、插入新的行
insert into Student values('张三','男','1999/01/02','80','75','90','2001班')
2、在指定的列中插入数据
INSERT INTO Student (StuName, StuSex) VALUES ('李四', '女');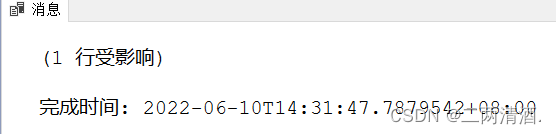
当下面的消息提示栏这出现上面这样的就是插入成功了。

数据表里就会出现你刚才插入的数据。下面就是查询出来结果。
温馨提示:当第一列是主键自增列的时候,不用插入,但第一列不是主键和自增列时,必须插入,否则会提示列数目不匹配的错误。
SELECT 语句用于从表中选取数据,结果被存储在一个结果表中(称为结果集)。
语法:
SELECT * FROM 表名称;
我们也可以指定所要查询数据的列:
SELECT 列名称 FROM 表名称;
温馨提示:SQL 语句不区分大小写,SELECT 等效于 select。
实例:
SQL SELECT * 实例:
SELECT * FROM Student;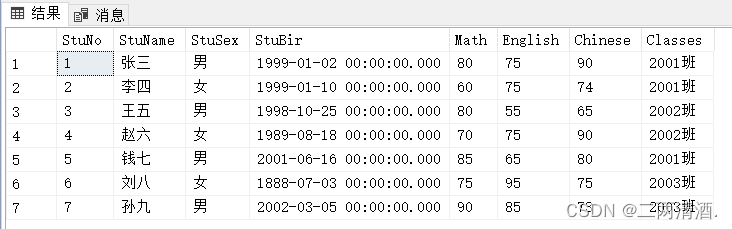 就会查询出表中所有的数据。
就会查询出表中所有的数据。
温馨提示:星号(*)是选取所有列的方法。
如需获取表中的其中某列的数据,请使用类似这样的 SELECT 语句:
SELECT StuNo,StuName FROM Student;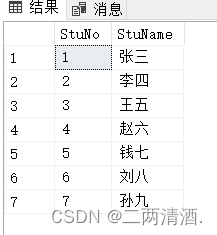
这样查询出来的结果就是查询你指定的字段。
如果一张表中有多行重复数据,如何去重显示呢?可以了解下 DISTINCT 。
语法:
SELECT DISTINCT 列名称 FROM 表名称;
实例:
如果要从 “StuName” 列中选取所有的值,我们需要使用 SELECT 语句:
SELECT DISTINCT StuName FROM Student;
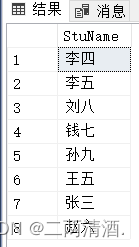
就会发现,重名的都没显示,只显示唯一的名字。
WHERE 子句是从表中查询出需要特定条件的语法。
语法:
SELECT 列名称 FROM 表名称 WHERE 列 运算符 值;下面的运算符可在 WHERE 子句中使用:
| 操作符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内(包含) |
| LIKE | 搜索某种模式(模糊查询) |
温馨提示:在某些版本的 SQL 中,操作符 <> 可以写为 !=。
实例:
查询Student中性别为男的学生
SELECT * FROM Student WHERE StuSex='男';
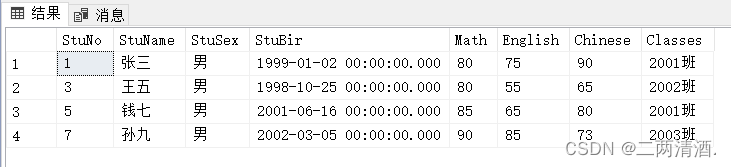
查询出来的结果就都是男生。
温馨提示: SQL 使用单引号来环绕文本值。如果是数值,请不要使用引号。
AND 和 OR 可在 WHERE 子语句中把两个或多个条件结合起来。
语法:
AND 运算符实例:
SELECT * FROM 表名称 WHERE 列 运算符 值 AND 列 运算符 值;
OR 运算符实例:
SELECT * FROM 表名称 WHERE 列 运算符 值 OR 列 运算符 值;
实例:
AND 运算符实例:
使用 AND 来显示所有姓名为 “张三” 并且性别是 “男“ 的人:
SELECT * FROM Student WHERE StuName='张三' AND StuSex='男';
OR 运算符实例:
使用 OR 来显示所有姓名为 “张三” 并且性别是 “男“ 的人:
SELECT * FROM Student WHERE StuName='张三' OR StuSex='男';结合 AND 和 OR 运算符:
我们也可以把 AND 和 OR 结合起来(使用圆括号来组成复杂的表达式):
SELECT * FROM Student WHERE (StuName='张三' OR StuName='李四') AND StuSex='男';ORDER BY 语句用于根据指定的列对结果集进行排序,默认按照升序对记录进行排序,可以使用 DESC 关键字进行降序排序。
语法:
SELECT * FROM 表名称 ORDER BY 列1,列2 DESC;
默认排序为 ASC 升序,DESC 代表降序。
实例:
以字母顺序显示 StuName名称:
SELECT * FROM Student ORDER BY StuName asc|desc;
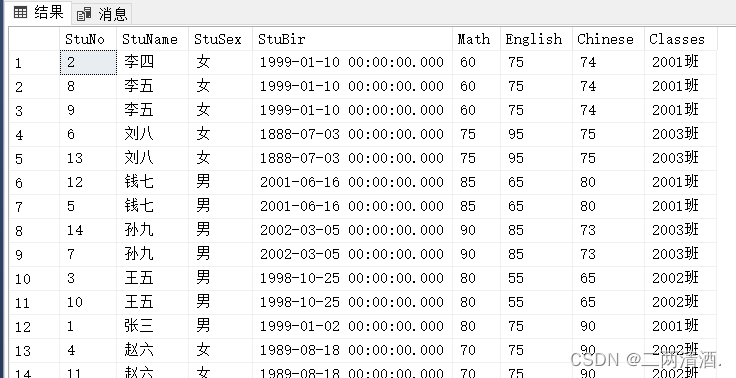 空值(NULL)默认排序在有值行之后。
空值(NULL)默认排序在有值行之后。
温馨提示: 在第一列中有相同的值时,第二列是以升序排列的。如果第一列中有些值为 null 时,情况也是这样的。
group by可以根据某一列进行分组查询。
语法:
select 【*/字段名,...】 from 【表名/查询结果集】
【where 查询条件】
group by 分组条件;
实例:
按照Student中的班级进行查询。
select Classes from Student group by Classes;
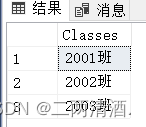
语法:
select 【*/字段名,...】 from 【表名/查询结果集】
【where 查询条件】
group by 分组条件
having 过滤条件;
实例:
根据数学成绩大于75分进行查询,查询出每位同学的学号,姓名,数学成绩。
select StuNo,StuName,Math from Student
group by Math,StuNo,StuName
having Math > 75;
温馨提示:having必须跟在group by的后面,不能单独使用。group by后面必须跟的是非聚合函数。
UPDATE用于修改表中的数据
语法:
UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值;
实例:
更新某一行中的一个列:
更新Student表中张三的数学成绩
UPDATE Studnet SET Math= '80' WHERE StuName= '张三';
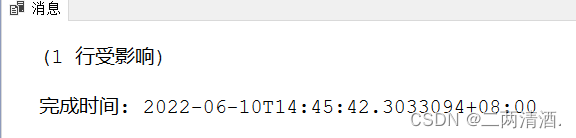
出现(一行受影响)代表更新成功。
温馨提示:SET后边是要更新的内容,WHERE后边是条件。
DELETE 语句用于删除表中的行。
语法:
DELETE FROM 表名称 WHERE 列名称 = 值;
实例:
删除某行:
删除 Student表中 StuName为 “张三” 的行:
DELETE FROM Studnet WHERE StuName= '张三';
出现(一行受影响)代表删除成功。
删除所有行:
可以在不删除表的情况下删除所有的行:
DELETE FROM Student;
温馨提示:删除的时候一定要有条件,不然的话表里的数据就都没有了。
TRUNCATE TABLE命令是只删除表中的所有数据,对表的结构不影响。
语法:
TRUNCATE TABLE 表名称;
实例:
如何删除名为 “Student” 表中的数据。
TRUNCATE TABLE Student;
最后要是不想要这张表的话,直接把整个表删除即可。
语法:
DROP TABLE 表名称;
实例:
删除名为 "Student" 的表。
drop table persons;
以上是Sql Server的一些基本命令,大家掌握的怎么样呢。让我们来一起学习Sql Server数据库。

1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我是Ruby新手,并被要求在我们的新项目中使用它。我们还被要求使用Padrino(Sinatra)作为后端/框架。我们被要求使用Rspec进行测试。我一直在寻找可以指导在Padrino上使用RspecforRuby的教程。我得到的主要是引用RoR。但是,我需要RubyonPadrino。请在任何入门/指南/引用/讨论等方面指导我。如有不妥之处请指正。可能是我没有针对我的问题搜索正确的词/短语组合。我正在使用Ruby1.9.3和Padrinov.0.10.6。注意:我还提到了SOquestion,但它没有帮助。 最佳答案 我没用过Pa
(本文是网络的宏观的概念铺垫)目录计算机网络背景网络发展认识"协议"网络协议初识协议分层OSI七层模型TCP/IP五层(或四层)模型报头以太网碰撞路由器IP地址和MAC地址IP地址与MAC地址总结IP地址MAC地址计算机网络背景网络发展 是最开始先有的计算机,计算机后来因为多项技术的水平升高,逐渐的计算机变的小型化、高效化。后来因为计算机其本身的计算能力比较的快速:独立模式:计算机之间相互独立。 如:有三个人,每个人做的不同的事物,但是是需要协作的完成。 而这三个人所做的事是需要进行协作的,然而刚开始因为每一台计算机之间都是互相独立的。所以前面的人处理完了就需要将数据