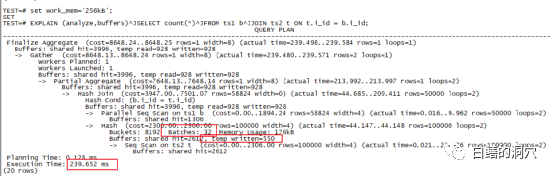
 可能有朋友要说了,反正都是HASH JOIN,执行计划都差不多,有啥可看的。那么我们来看看上面的执行计划里的红框里的内容吧,Batches :32,这个是啥意思?如果你以前是Oracle DBA,那么优化排序、one-pass 排序,multi-pass排序的概念应该还有印象吧。当需要做排序或者HASH TABLE的数据量太大,超出了SORT AREA SIZE的限制,那么这次排序/HASH join就无法一次完成,必须切分为多个分区,一个个的完成。在PG的HASH JOIN里,就是把HASH JOIN切分为多个BATCHES。因为某个BATCH完成后需要暂存在临时文件中,因此遇到这种情况我们一般都可以看到temp written这个内容,这部分内容我也用红框标注出来了。
可能有朋友要说了,反正都是HASH JOIN,执行计划都差不多,有啥可看的。那么我们来看看上面的执行计划里的红框里的内容吧,Batches :32,这个是啥意思?如果你以前是Oracle DBA,那么优化排序、one-pass 排序,multi-pass排序的概念应该还有印象吧。当需要做排序或者HASH TABLE的数据量太大,超出了SORT AREA SIZE的限制,那么这次排序/HASH join就无法一次完成,必须切分为多个分区,一个个的完成。在PG的HASH JOIN里,就是把HASH JOIN切分为多个BATCHES。因为某个BATCH完成后需要暂存在临时文件中,因此遇到这种情况我们一般都可以看到temp written这个内容,这部分内容我也用红框标注出来了。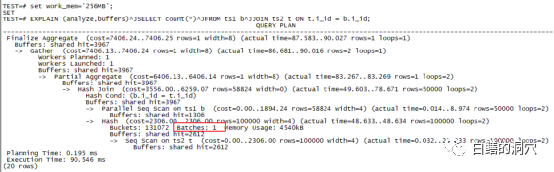 这种排序区不足导致的问题会带来什么样的性能问题呢?我们来看这个例子,BATCHES:1,也就是无需通过分区完成,此时使用了4540KB的WORK_MEM。实际上我给大家演示这个案例的时候,第一个例子用了256KB的work_mem设置,当然无法满足4M多的内存需求了。而第二个例子我使用了一个极大的work_mem(256MB),当然实际上的内存使用以执行计划中的为准。一次性在内存中完成HASH JOIN的好处是什么呢?当然是执行效率,我们可以看出第二个执行只用了90毫秒,而分裂为32个BATCH的执行花了239毫秒。看到这里可能有朋友要说了,既然效果那么好,那么我们把WORK_MEM参数设的足够大不就行了。实际上设置过大的WORK_MEM也是存在隐患的。如果我们的物理内存不是很大,那么设置过大的WORK_MEM可能导致极端情况下,物理内存过度消耗而导致更严重的问题。WORK_MEM参数是可会话级动态设置的,如果我们的某些要做大型排序或者HASH JOIN的SQL能够在应用层面做设置,执行大型SQL的时候设置一个较大的值,SQL执行完毕RESET一下参数,这样WORK_MEM的使用效率是最高的。否则我们为了满足大型SQL的需求,就需要设置一个做大值。当然虽然我们设置了WORK_MEM并不一定就会消耗那么多的内存,不过活跃会话数*WORK_MEM这个数字还是需要关注的,确保我们的物理内存有那么多的空闲可用(参考可用内存,而不是FREE内存)是十分必要的。如果我们不确定系统最大的内存使用量,并且物理内存比较紧张,那么设置大一点的SWAP是十分必要的,在极端情况下可以确保系统不会因为OOM而出大问题。
这种排序区不足导致的问题会带来什么样的性能问题呢?我们来看这个例子,BATCHES:1,也就是无需通过分区完成,此时使用了4540KB的WORK_MEM。实际上我给大家演示这个案例的时候,第一个例子用了256KB的work_mem设置,当然无法满足4M多的内存需求了。而第二个例子我使用了一个极大的work_mem(256MB),当然实际上的内存使用以执行计划中的为准。一次性在内存中完成HASH JOIN的好处是什么呢?当然是执行效率,我们可以看出第二个执行只用了90毫秒,而分裂为32个BATCH的执行花了239毫秒。看到这里可能有朋友要说了,既然效果那么好,那么我们把WORK_MEM参数设的足够大不就行了。实际上设置过大的WORK_MEM也是存在隐患的。如果我们的物理内存不是很大,那么设置过大的WORK_MEM可能导致极端情况下,物理内存过度消耗而导致更严重的问题。WORK_MEM参数是可会话级动态设置的,如果我们的某些要做大型排序或者HASH JOIN的SQL能够在应用层面做设置,执行大型SQL的时候设置一个较大的值,SQL执行完毕RESET一下参数,这样WORK_MEM的使用效率是最高的。否则我们为了满足大型SQL的需求,就需要设置一个做大值。当然虽然我们设置了WORK_MEM并不一定就会消耗那么多的内存,不过活跃会话数*WORK_MEM这个数字还是需要关注的,确保我们的物理内存有那么多的空闲可用(参考可用内存,而不是FREE内存)是十分必要的。如果我们不确定系统最大的内存使用量,并且物理内存比较紧张,那么设置大一点的SWAP是十分必要的,在极端情况下可以确保系统不会因为OOM而出大问题。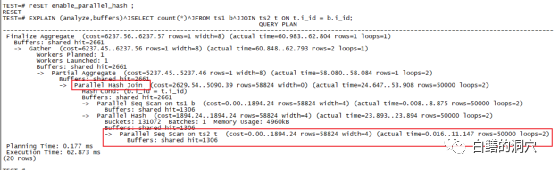 上面的这个执行计划也是我们经常看到的,PG数据库支持并行HASH JOIN,并且默认是打开的。如果我们的系统中的CPU资源是充足的,那么enable_parallel_hash参数确保打开状态就行了。并行HASH JOIN可以通过过parallel seq scan和parallel hash join两种机制来进一步提高HASH JOIN的性能。我们可以看到,通过并发,这个SQL的执行效率进一步的提升了。不过任何事情都是有利有弊,如果你的服务器的CPU资源十分紧张,那么过多的并行HASH JOIN可能会导致你的CPU资源经常出现不足,引发其他问题。如果存在这种情况,那么关闭并行HASH JOIN,让每个HASH JOIN变得略微慢一点,但是确保CPU资源不过载,也是一种策略。
上面的这个执行计划也是我们经常看到的,PG数据库支持并行HASH JOIN,并且默认是打开的。如果我们的系统中的CPU资源是充足的,那么enable_parallel_hash参数确保打开状态就行了。并行HASH JOIN可以通过过parallel seq scan和parallel hash join两种机制来进一步提高HASH JOIN的性能。我们可以看到,通过并发,这个SQL的执行效率进一步的提升了。不过任何事情都是有利有弊,如果你的服务器的CPU资源十分紧张,那么过多的并行HASH JOIN可能会导致你的CPU资源经常出现不足,引发其他问题。如果存在这种情况,那么关闭并行HASH JOIN,让每个HASH JOIN变得略微慢一点,但是确保CPU资源不过载,也是一种策略。 我在使用omniauth/openid时遇到了一些麻烦。在尝试进行身份验证时,我在日志中发现了这一点:OpenID::FetchingError:Errorfetchinghttps://www.google.com/accounts/o8/.well-known/host-meta?hd=profiles.google.com%2Fmy_username:undefinedmethod`io'fornil:NilClass重要的是undefinedmethodio'fornil:NilClass来自openid/fetchers.rb,在下面的代码片段中:moduleNetclass
我遵循了教程http://gettingstartedwithchef.com/,第1章。我的运行list是"run_list":["recipe[apt]","recipe[phpap]"]我的phpapRecipe默认Recipeinclude_recipe"apache2"include_recipe"build-essential"include_recipe"openssl"include_recipe"mysql::client"include_recipe"mysql::server"include_recipe"php"include_recipe"php::modul
我在用Ruby执行简单任务时遇到了一件奇怪的事情。我只想用每个方法迭代字母表,但迭代在执行中先进行:alfawit=("a".."z")puts"That'sanalphabet:\n\n#{alfawit.each{|litera|putslitera}}"这段代码的结果是:(缩写)abc⋮xyzThat'sanalphabet:a..z知道为什么它会这样工作或者我做错了什么吗?提前致谢。 最佳答案 因为您的each调用被插入到在固定字符串之前执行的字符串文字中。此外,each返回一个Enumerable,实际上您甚至打印它。试试
如何检查Ruby文件是否是通过“require”或“load”导入的,而不是简单地从命令行执行的?例如:foo.rb的内容:puts"Hello"bar.rb的内容require'foo'输出:$./foo.rbHello$./bar.rbHello基本上,我想调用bar.rb以不执行puts调用。 最佳答案 将foo.rb改为:if__FILE__==$0puts"Hello"end检查__FILE__-当前ruby文件的名称-与$0-正在运行的脚本的名称。 关于ruby-检查是否
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
我从Ubuntu服务器上的RVM转移到rbenv。当我使用RVM时,使用bundle没有问题。转移到rbenv后,我在Jenkins的执行shell中收到“找不到命令”错误。我内爆并删除了RVM,并从~/.bashrc'中删除了所有与RVM相关的行。使用后我仍然收到此错误:rvmimploderm~/.rvm-rfrm~/.rvmrcgeminstallbundlerecho'exportPATH="$HOME/.rbenv/bin:$PATH"'>>~/.bashrcecho'eval"$(rbenvinit-)"'>>~/.bashrc.~/.bashrcrbenvversions
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里
如果names为nil,则以下中断。我怎样才能让这个map只有在它不是nil时才执行?self.topics=names.split(",").mapdo|n|Topic.where(name:n.strip).first_or_create!end 最佳答案 其他几个选项:选项1(在其上执行map时检查split的结果):names_list=names.try(:split,",")self.topics=names_list.mapdo|n|Topic.where(name:n.strip).first_or_create!e
关于SSHkit-Github它说:Allbackendssupporttheexecute(*args),test(*args)&capture(*args)来自SSHkit-Rubydoc,我明白execute实际上是test的别名?test之间有什么区别?,execute,capture在Capistrano/SSHKit中我应该什么时候使用? 最佳答案 执行只是执行命令。使用非0退出引发错误。测试方法的行为与execute完全相同,但是它返回bool值(true如果命令以0退出,而false否则)。它通常用于控制任务中的流程