
大家好,我是莫觉。今年我将担任阿里巴巴 D2 终端技术大会「跨端技术」的出品人,借由此次机会,写下本文聊聊跨端技术的现状与未来,希望可以给大家带来一些新的启迪。
自 90 年代初开启 PC 时代以来,随着移动网络的快速普及,在 2010 年左右,进入移动时代、IOT 时代,各种移动互联设备不断涌现,除了最常见的 PC、Pad、智能手机外,它还可能是小小的一块智能手表,也可以是一个大屏终端。智能设备层出不穷,填满了人们生活的各个角落,设备的系统类型、屏幕大小等也是愈发碎片化。
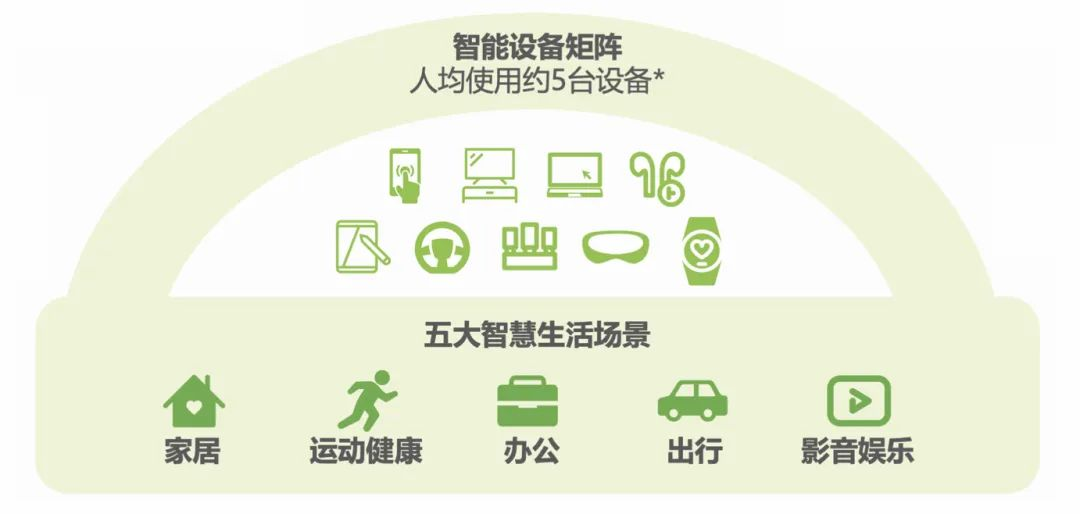
数据显示,当前用户平均拥有 5 台智能设备;预计到 2022 年底,中国物联连接量将会超过 100 亿设备。智能设备的增长势头迅猛,用户对于智能家居、智慧办公等跨设备互联需求愈发旺盛,意味着跨端开发的需求也将激增。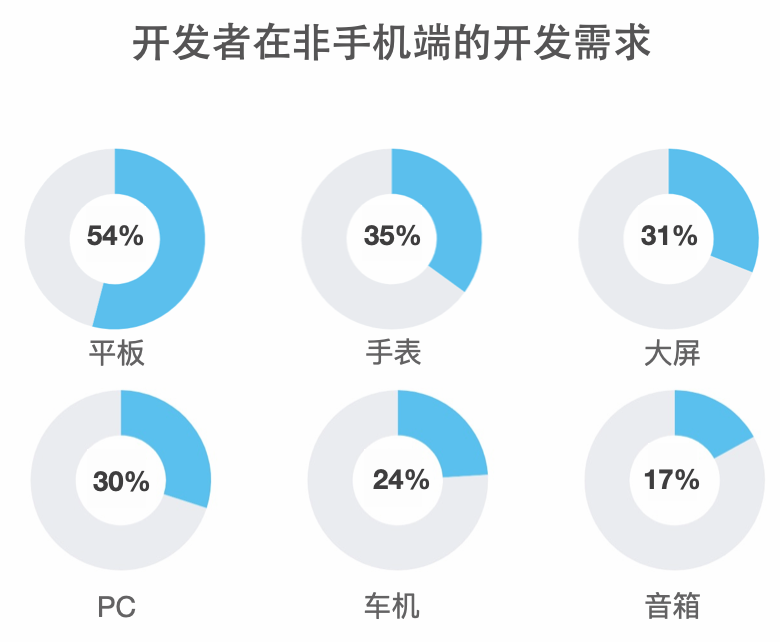
过去,不同类型的硬件开发是相互独立的,手机的归手机,电脑的归电脑。同一类型的硬件如果系统不同,开发也是相互独立的,iOS 的归 iOS,Android 的归 Android。这背后是大量的重复劳动,一次开发满足全场景使用是必然趋势。正因如此才有了层出不穷的跨端方案探索。
跨端技术的变与不变
跨端技术演进
浏览器和 WebView 本来就都是 W3C 规范下的标准化 Web 容器,因此 Web 页面天生就能轻松投放到任意浏览器、WebView 之中。从开发成本、标准统一、生态繁荣上来说,Web 方案基本是不二之选;不过 Web 本身也存在一些问题,例如页面加载慢、内存消耗大、交互体验差。尽管在 Web 基础上又衍生出了 Hybrid、PWA、PHA 等一系列 Web 能力增强的方案,让性能和体验得到了非常不错的提升,但相对于 Native 性能和体验的劣势却仍然存在。Web 的高效和动态性是 Native 开发难以企及的,Native 的性能和体验也是Web一直追求的,有没有一种俩全齐美的方式让我们在俩者之间找到一个平衡点?React Native 的出现给开发者带来了新的思路。
为了弥补 Web 容器方案性能和体验上的不足,同时也能拥有 Web 的研发效率;类 RN 容器尽可能的取长补短,保留了 JS 引擎,以便最大程度的对接前端生态,提升开发效率;出于性能和体验上的考虑在渲染上则复用了 Native 的渲染管线,使用原生渲染保障了性能和体验;通过类似的容器方案即可实现跨端,主流的 RN、Weex 都是采用这种方案。容器化 Native 方案看起来既能拥有 Native 的体验又能拥抱 Web 的繁荣生态非常完美,但它实际上还是存在问题:比如难以抹平的一致性、W3C标准支持不足、研发体验、周边生态缺失等。尽管如此容器化 Native 方案仍是成功的,它迅速拓展了前端的边界。
Web 容器存在性能问题,Native 容器化存在一致性问题;那么是否可以绕开 Native 渲染管线自建渲染引擎,解决跨端一致性问题呢?答案是必然的,Flutter 基于 Skia 实现了一套自绘引擎;因此 Flutter 的特点是一致性高,性能好;但它也有着自身的缺点由于设计上采用全新的思路,抛弃 JS 而使用 Dart 作为开发语言,所以不管对于 Native 研发还是前端研发都有一定的学习成本,不过站在开发者的角度来说学习成本并不是特别高,更大的问题是前端生态需要重建,工程相关的 CI、CD,生态相关的搭投、智能化都需要重新建设,成本巨大。正是这样的原因,让不少前端开发者望而却步;那么自然而然的就有各种各样的探索;上层让 Flutter 更好的对接前端生态,底层使用 Flutter 自绘渲染保证多端的渲染一致性,这里我们就不再展开了。
小程序帮助头部 App 建立起封闭流量体系和容器管控的同时,也因其双线程模型及自建 DSL 引入带来了新的跨端问题。随着各大厂商纷纷实现自己的小程序容器、快应用,跨端容器的碎片化愈演愈烈。其实现方案大致可分为两类:编译时与运行时。
编译时思路:在编译时将框架的业务代码转换为小程序原生 DSL;
此类框架非常多。小程序的一码多投实际是一种商业模式下的无奈与技术妥协。
演进中的变与不变
基于上述跨端技术演进的介绍,会发现无论跨端技术方案如何变化,跨端的目标始终不变,一直保持着对性能体验、交付效率和多端一致性追求,其方案本质无非是如何做平衡与取舍而已。跨端技术方案一直在变化,基于方案的终端能力要求、容器、Bridge 等在变,业务开发框架、基础设施也在变。如何在这些变化中寻找不变的存在,通过控制变量,让混沌变得有序,让跨端技术演进有迹可循?是否可以把每次方案迭代必然变化的「容器」作为唯一的变量,保持业务代码、基础设施、研发生态、底层能力等的不变?
换个新容器,业务代码无需改动依然能在新容器上稳定运行?
换个新容器,周边配套设施、研发生态是否可延续使用?
换个新容器,对端能力的要求是否能保持不变?
基于上述变与不变的思考,「统一跨端容器规范,实现容器标准化」必然是一条正确的大道。只要按照该标准实现的容器,就能随意进行切换,不影响上层业务、框架、基础设施,让跨端也能轻松“write once, run anywhere”。那么该如何进行容器标准化呢?
如何进行标准化
从 Web 的思路来进行思考,很容易找到答案,那么浏览器是怎么进行标准化的呢?我们先来看看浏览器架构,Web是依托浏览器内核完成渲染的,浏览器内核执行 HTML、CSS 、JS 并渲染成开发者预期的 UI 界面。内核主要由浏览器引擎和 JS 引擎组成;JS 引擎执行 JS,遵照的是 TC39(ECMAScript) 标准,浏览器引擎负责除执行JS外的其他工作例如 DOM、CSS,遵照的是 W3C 的标准,两者比较独立又有很强的配合,这些引擎在不同浏览器中的实现也是不一样的。
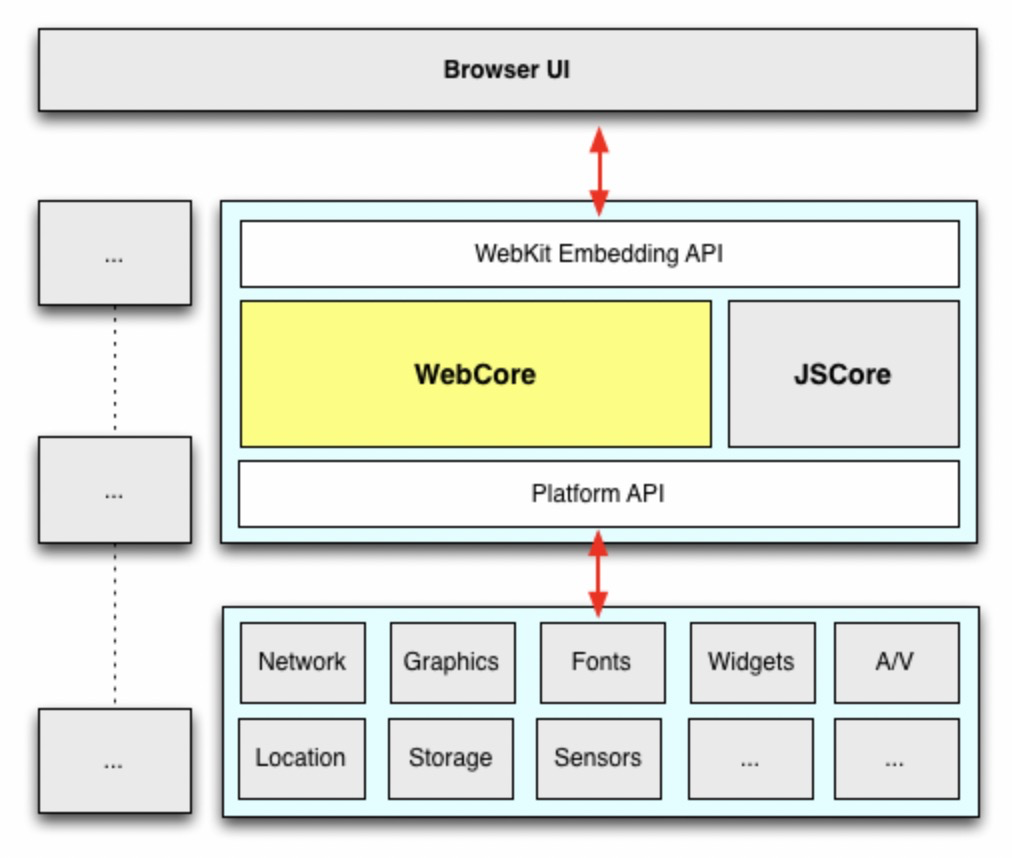
这种架构下最核心的部分是 WebCore,它是加载和渲染的基础能力;对于这部分各浏览器是共享的;其他的部分(图中灰色的部分)虽然遵循相同的标准,但实现存在差异,对于不同浏览器由于平台差异/第三方依赖不同/需求不同等多方面原因,允许其按照自己的方式来设计和实现。借鉴浏览器的思想,在跨端容器上我们也完全可以这样做,基于相同标准实现跨端容器能大大减轻我们的开发工作,基于 W3C 标准则能够让我们相对轻松的对接前端生态。在阿里内部也确实是这么做的。
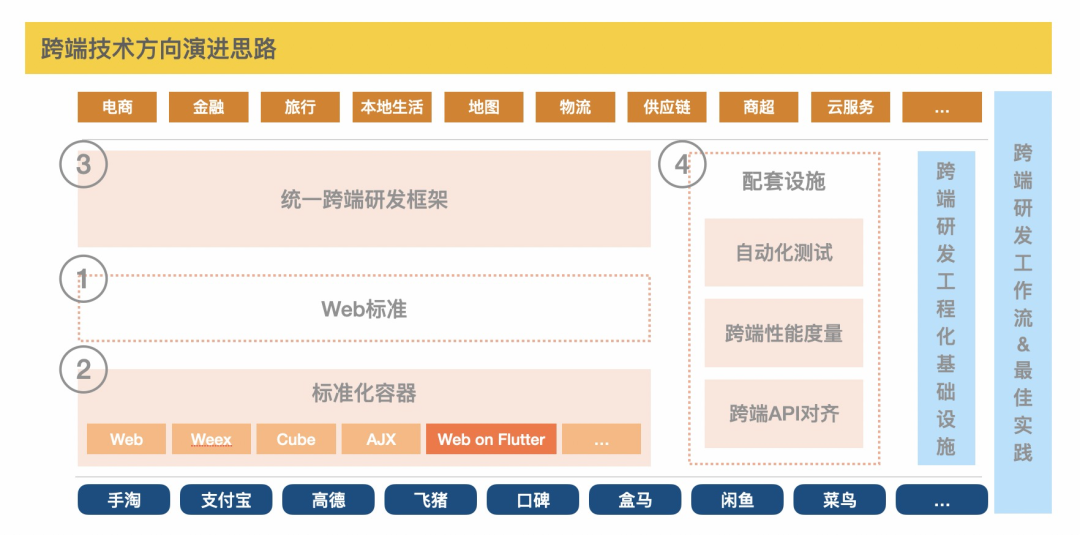
在阿里标准化实践上,我们拉通了集团涉及跨端容器的几大业务单元,并参考 W3C/WHATWG 标准和业务需要从 CSS/WebAPI/桥通道四个方面制定了标为什么会选择实现子集,而不是实现全集呢?主要是平衡了性能、效率后的考虑;如果实现规范全集研发效率、研发体验上无疑是最棒的;但对于跨端容器来说则会遇到各种各样的问题,例如圆角、阴影等;类似的案例还有很多,本质上是 Web 和 Native 最开始的设计思路就完全不同,强行适配会导致性能严重的下降;除此之外浏览器已经发展许多年了,相关的规范非常多,有大量的历史包袱存在,在移动、IoT 上性能仍然是一个非常有挑战的课题。

那么是否制定了 HTML、CSS、Web API 标准子集,就能对接前端生态了吗?我认为还不够,从现状上看不同的跨端容器对于标准的实现有着相当大的差异,也会导致跨端研发生态不能统一,很多情况下都需要自己造轮子;现有的前端生态,跨端生态很多都不能直接使用;例如我们常用的调试能力,由于容器实现 inspector 各不相同,现有的 Devtools 也很难直接使用,大多会开发自己的 Devtools;比如 WeexDevtools、AJXDevtools 虽然都是基于远程调试协议来通信的,但实现都是独立的。再比如 List 组件,几乎每个跨端容器都需要 List 组件解决列表渲染的问题,但又都是独立实现的自定义 List 组件。在这些方面我们花费了大量的精力,如果核心能力上我们也能和 WebCore 一样,共享 WebCore 的能力,那么我们就能建设一个更好的跨端内核,也能把精力集中在优化业务领域上,构建更好的、更适合自己的业务容器。
跨端的核心诉求是一次开发全场景使用,我们通过跨端方案解决了多端开发问题,通过 Native 跨端容器解决了性能、体验问题,通过自绘容器解决了双端不一致问题;那么该如何对接前端生态,提升研发效率,在生产环境中发挥他应有的价值则是我们要不断思考的。标准化是趋势,千里之行,始于足下;九层之台,起于累土;API 的标准化已经走出了第一步,让我们继续建立容器标准,建立跨端研发标准;通过标准化更好的对接前端框架、前端生态,帮助企业实现降本增效,帮助业务实现快速增长。
作者 | 莫觉
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只