
? 作者:韩信子@ShowMeAI
? 机器学习实战系列:https://www.showmeai.tech/tutorials/41
? 本文地址:https://www.showmeai.tech/article-detail/333
? 声明:版权所有,转载请联系平台与作者并注明出处
? 收藏ShowMeAI查看更多精彩内容

本篇内容 ShowMeAI 将带大家学习,从头开始构建机器学习管道,使用 Flask 框架构建 Web 应用程序,并部署到云服务器上的过程。具体包括:

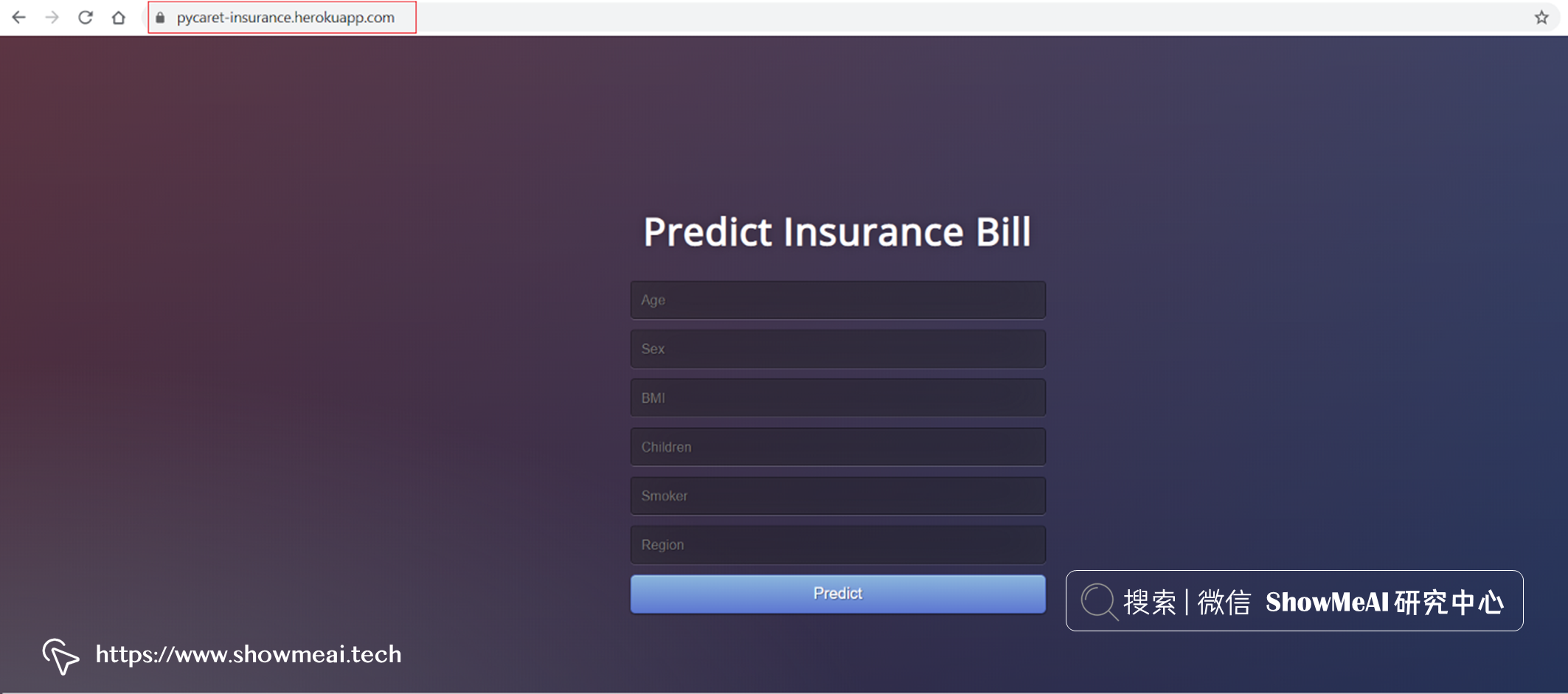
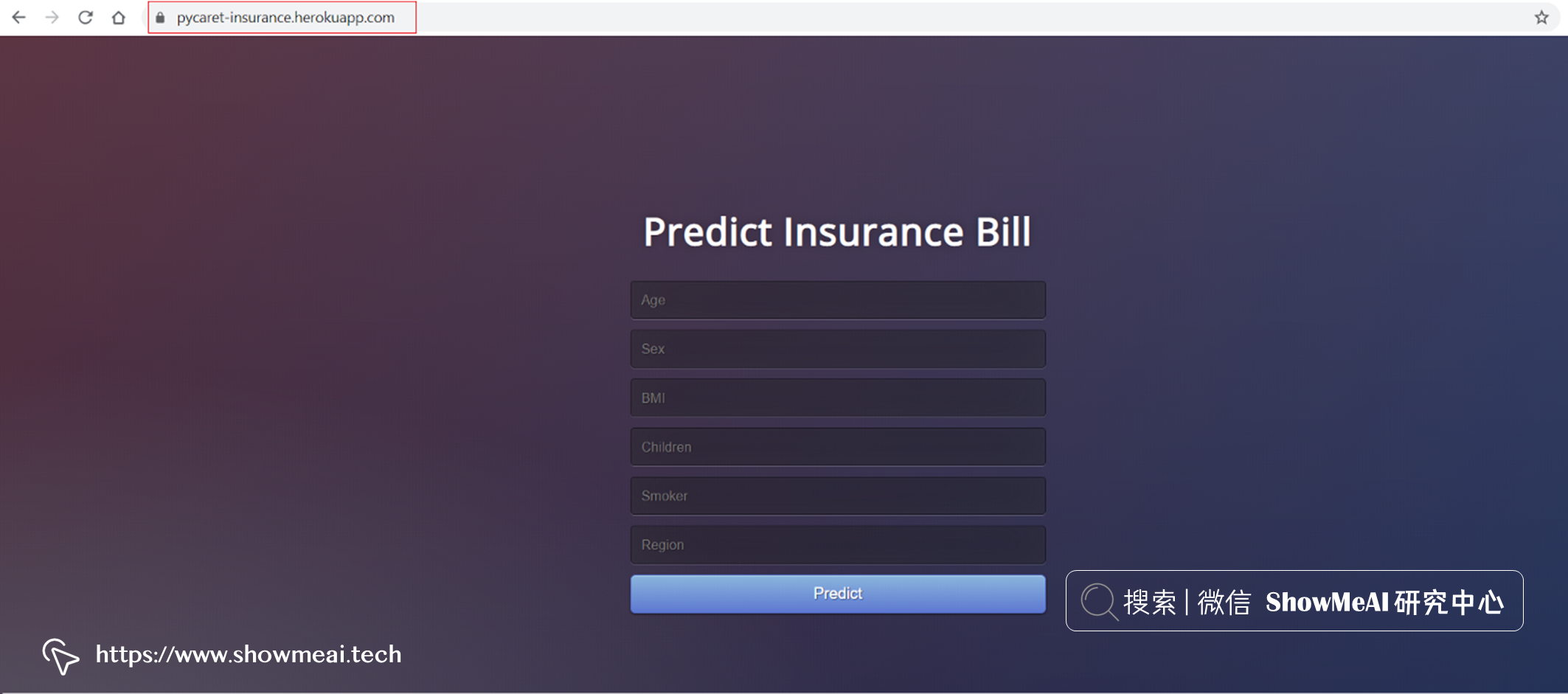
本示例中的应用为保险金额预估,部署好的云端服务页面如下图所示,可以点击 ?这里体验。

?PyCaret 是一个开源的低代码机器学习库,用于在生产中训练和部署机器学习管道/流水线和模型。我们可以通过pip安装 PyCaret。
# 安装pycaret
pip install pycaret

?Flask 是一个用于在 Python 中构建 Web 应用程序的轻量化框架。我们本次的应用需要部署成Web端可交互操作使用的形态,会用到这个工具库,我们同样可以通过pip安装它。
# 安装flask
pip install flask

? Heroku 是一个平台即服务(PaaS),它支持基于托管容器系统部署 Web 应用程序,具有集成的数据服务和强大的生态系统。我们将基于它将应用程序部署到云端,进而大家可以直接通过 URL 在浏览器端访问应用。
在企业的实际生产中,我们经常会把机器学习模型构建成服务形态,这样协作的开发同事可以通过接口(API)来访问模型服务,完成预估任务,这被称为部署机器学习应用过程。
更全一点说,生产中使用机器学习管道有两种广泛的方式:
将模型或管道存储在磁盘中,定期运行脚本,加载模型和数据,生成预测并将输出写入磁盘。这种情况下,多个预测会并行。它对于时效性要求不高。
需要实时预测,大家使用到的很多 app,其实都是输入信息,然后在单击提交按钮时,实时预估生成预测的。比如你在电商平台输入搜索词,点击查询,可以看到模型排序好的结果列表返回。
本教程中,我们讲解的是『在线预测』这种模式。我们将首先使用 PyCaret 在 Python 中构建机器学习管道,然后使用 Flask 构建 Web 应用程序,最后将所有这些部署在 Heroku 云上。
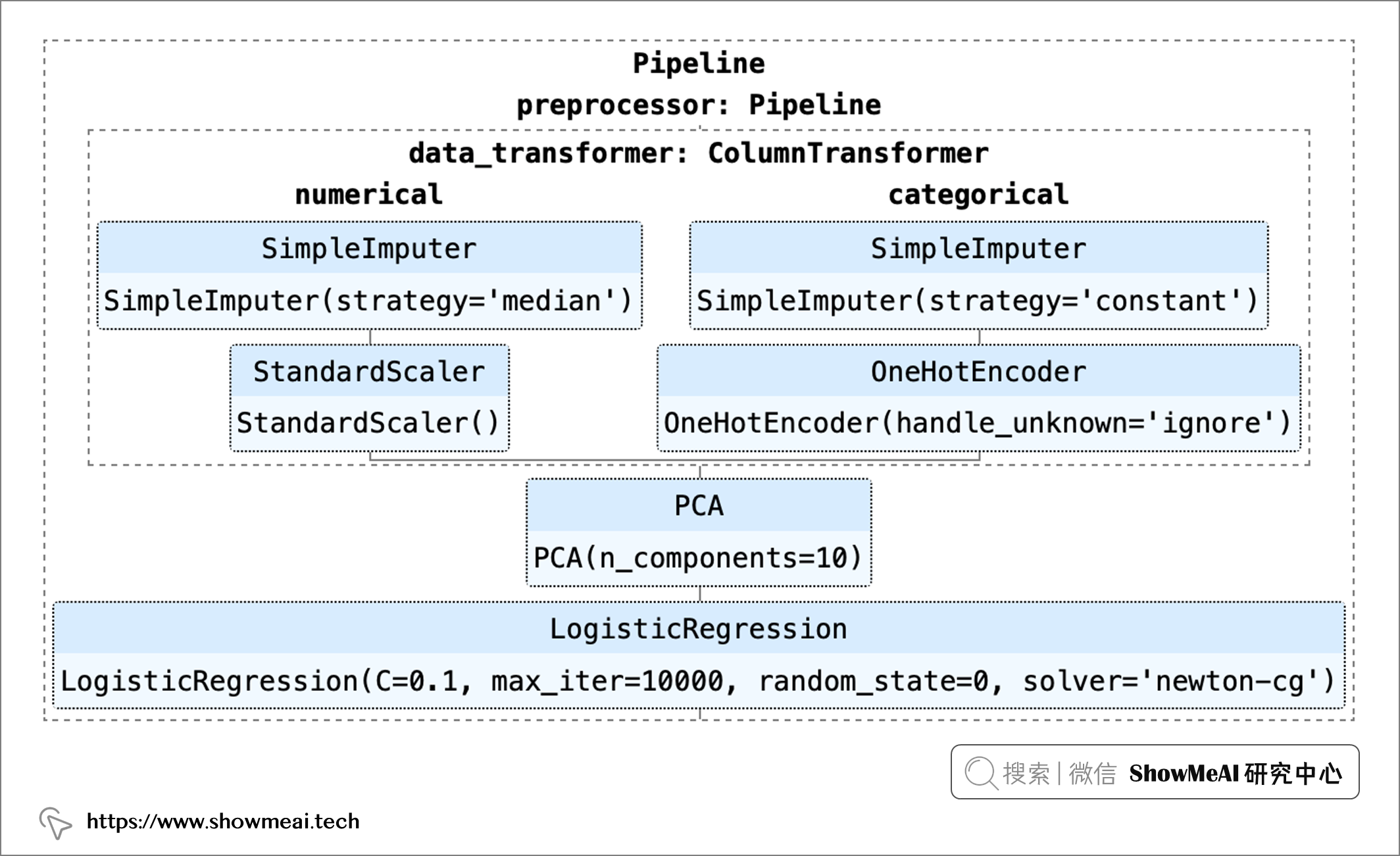
整个机器学习管道(pipeline)如下图所示:
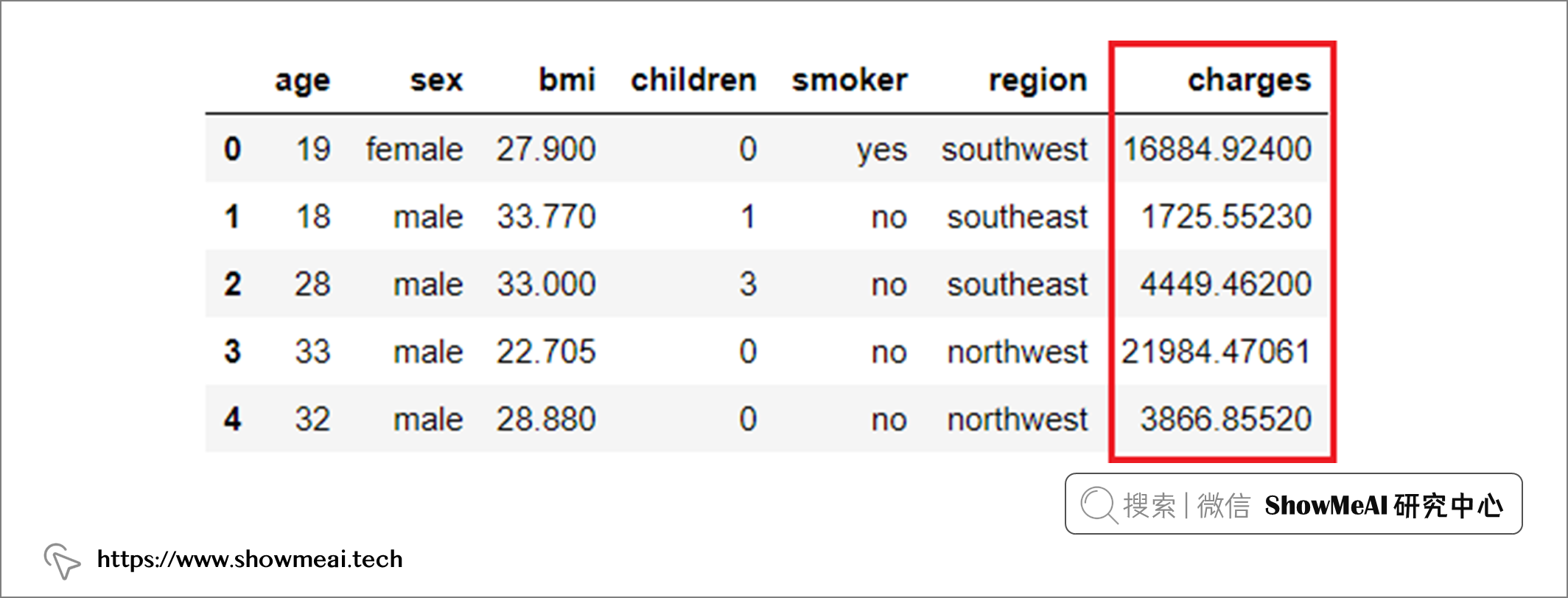
本案例中用作示例的数据来自保险场景,保险公司希望通过使用人口统计学信息和基本患者健康风险特征,更准确地预测患者保单费用,以优化其使用的现金流预测的准确性。数据是 PyCaret 自带的,数据的简单速览如下:
下面我们逐步完成机器学习管道构建与云端部署的过程。
我们把整个建模过程构建为一个流水线,这里我们使用 PyCaret,几乎可以自动化地完成这个过程。
# 加载数据
from pycaret.datasets import get_data
data = get_data('insurance')
# 初始化设置
from pycaret.regression import *
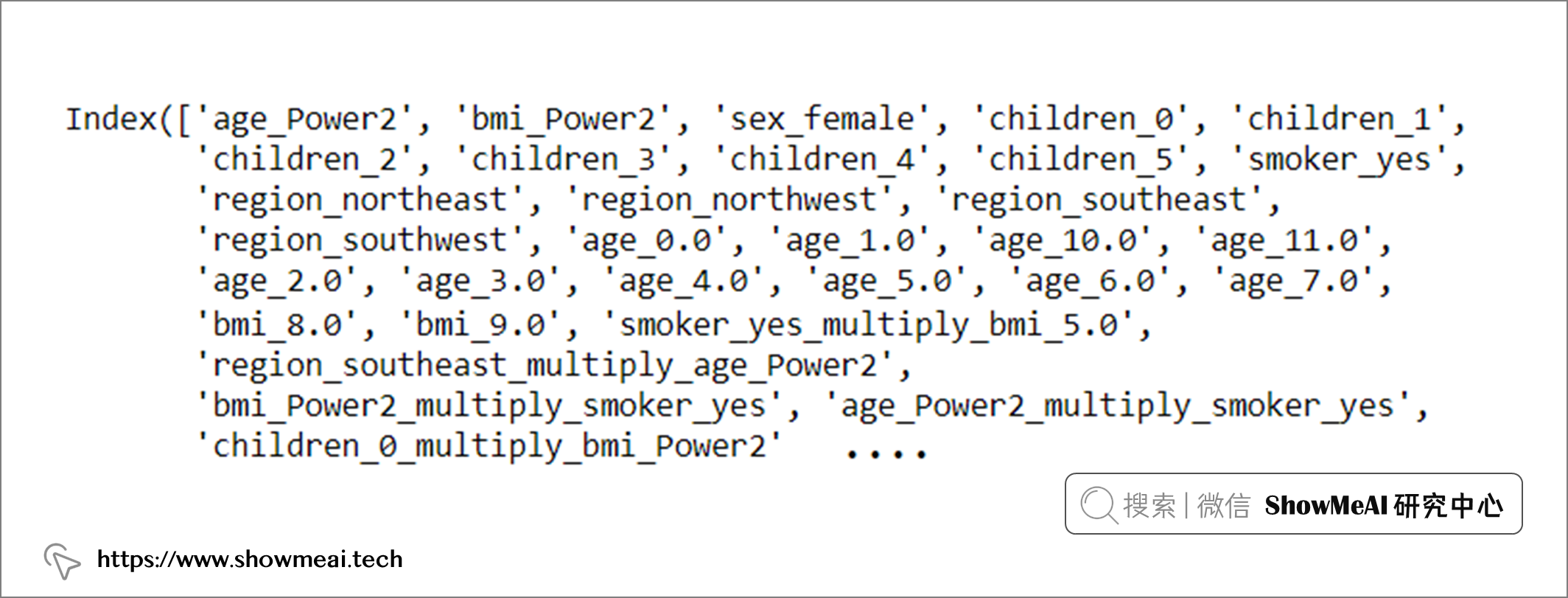
s = setup(data, target = 'charges', session_id = 123, normalize = True, polynomial_features = True, trigonometry_features = True, feature_interaction=True, bin_numeric_features= ['age', 'bmi'])

上述的代码会自动化完成数据转换,转换后的数据集有 62 个用于训练的特征,这些特征由原始数据集的 7 个特征变换而来。以下为对应的特征列表:
使用PyCaret进行建模和评估非常简单,下面示例代码中,我们选择逻辑回归模型,并进行10折交叉验证:
# 模型训练
lr = create_model('lr')
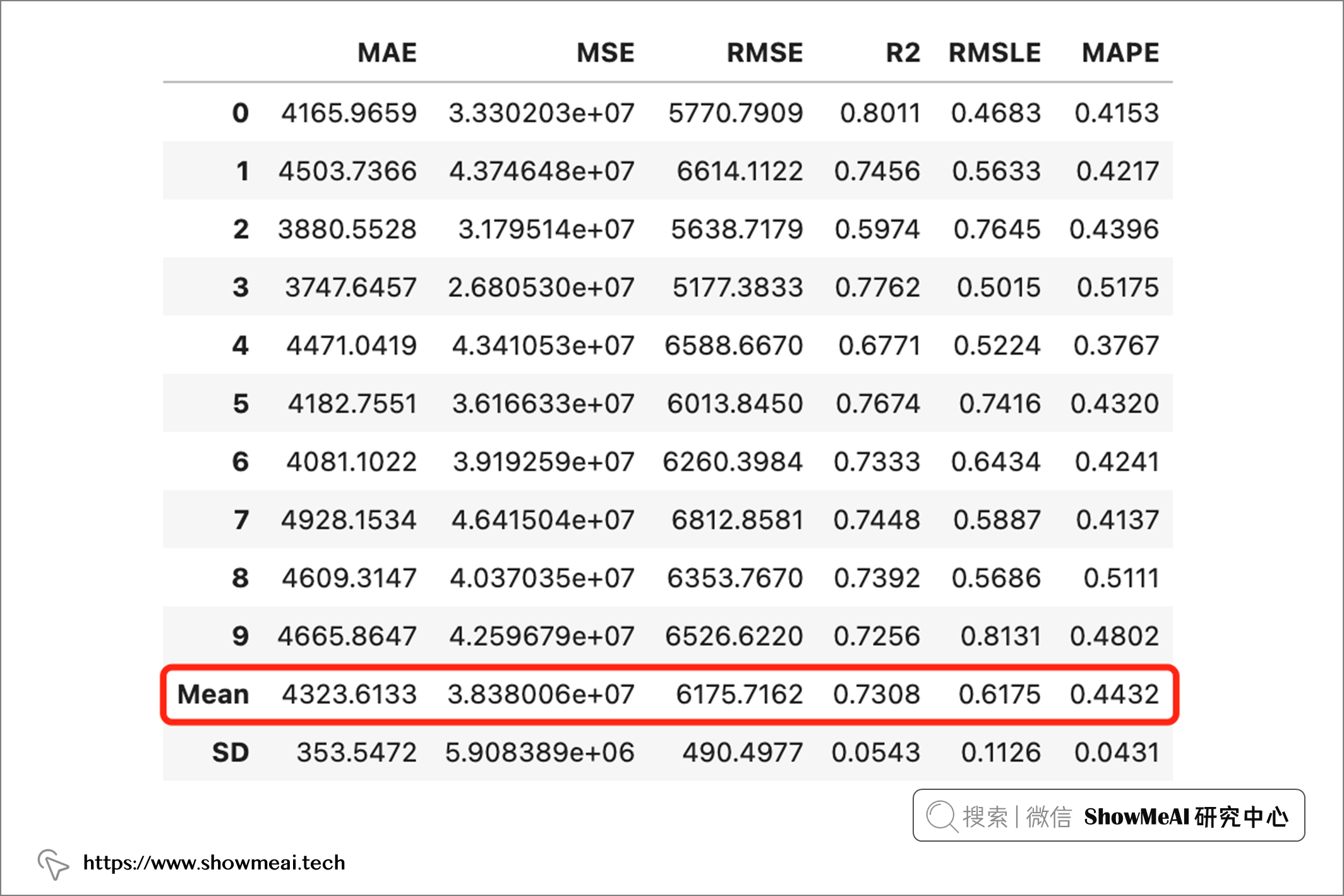
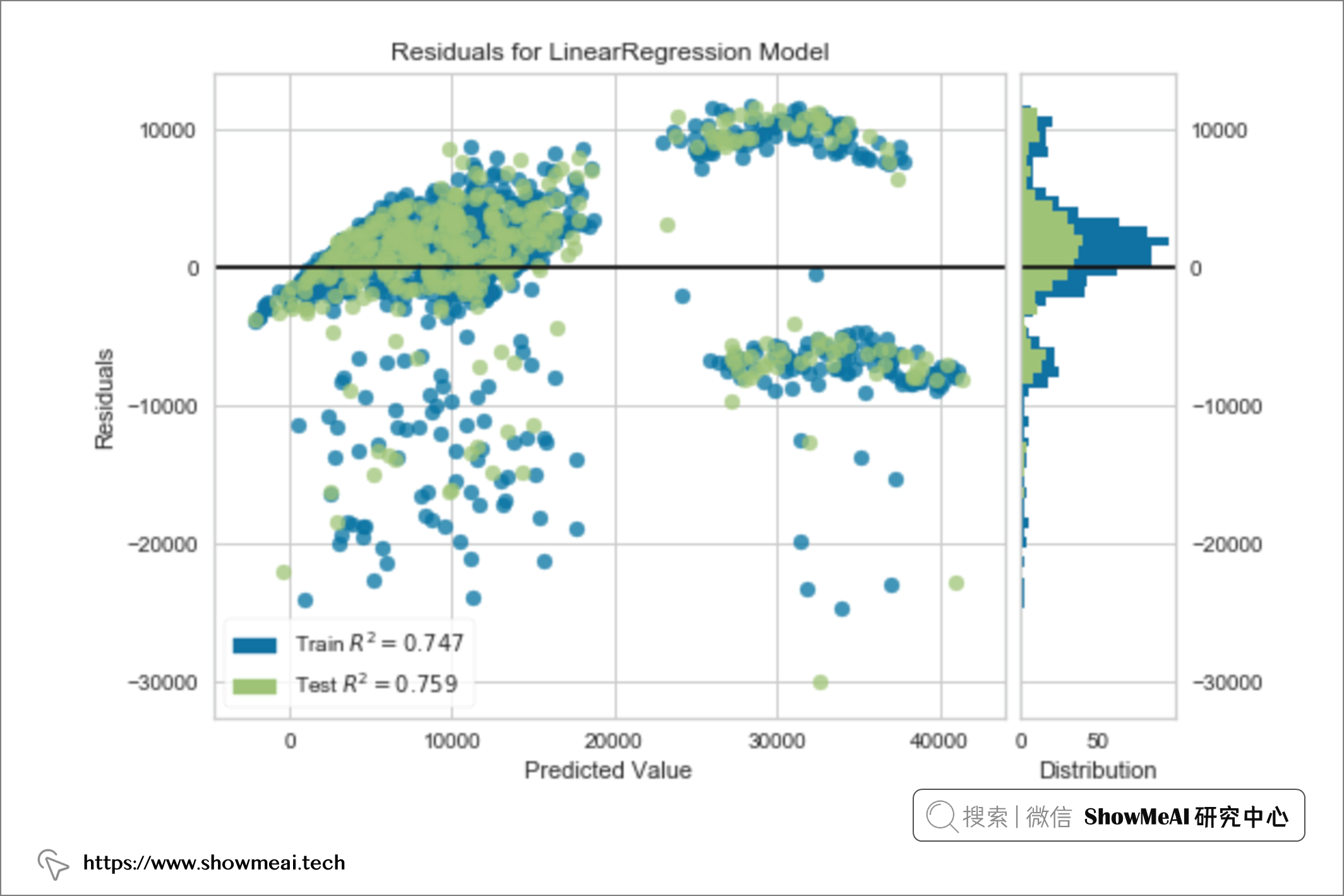
# 绘制训练模型的残差
plot_model(lr, plot='residuals')
上述流程之后,我们可以使用该save_model函数保存整个建模流水线。
# 保存转换流水线和模型
save_model(lr, model_name='/username/ins/deployment')
这样我们就快速完成了第 1 步,注意,实际业务场景下,大家会做更精细化的数据清洗、特征工程和模型调优,我们本次的目标是给大家演示从建模到部署的全流程方法,因此这个部分相对简略。
PyCaret 自动化建模的输出是一个流水线/pipeline,包含几个数据转换步骤(如特征工程、缩放、缺失值插补等)和机器学习模型。流水线保存为pkl格式的文件,我们在后续构建 Flask 应用程序会使用到它。
在完成我们的机器学习流水线和模型之后,我们要开始开发 Web 应用程序,它由两个部分组成:
很多 Web 应用程序的前端都是使用 HTML 构建的,我们在本篇内容中不会深入讲解前端相关的内容。为了构建一个输入表单(以接收用户实时预估时输入的字段取值),我们基于一个基本的 HTML 模板完成前端网页,然后包含一个 CSS 样式表。
◉ HTML 代码实现
以下是我们 Web 应用程序主页的 HTML 代码。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Predict Insurance Bill</title>
<link href='https://fonts.googleapis.com/css?family=Pacifico' rel='stylesheet' type='text/css'>
<link href='https://fonts.googleapis.com/css?family=Arimo' rel='stylesheet' type='text/css'>
<link href='https://fonts.googleapis.com/css?family=Hind:300' rel='stylesheet' type='text/css'>
<link href='https://fonts.googleapis.com/css?family=Open+Sans+Condensed:300' rel='stylesheet' type='text/css'>
<link type="text/css" rel="stylesheet" href="{{ url_for('static', filename='./style.css') }}">
</head>
<body>
<div class="login">
<h1>Predict Insurance Bill</h1>
<!-- Form to enter new data for predictions -->
<form action="{{ url_for('predict')}}"method="POST">
<input type="text" name="age" placeholder="Age" required="required" /><br>
<input type="text" name="sex" placeholder="Sex" required="required" /><br>
<input type="text" name="bmi" placeholder="BMI" required="required" /><br>
<input type="text" name="children" placeholder="Children" required="required" /><br>
<input type="text" name="smoker" placeholder="Smoker" required="required" /><br>
<input type="text" name="region" placeholder="Region" required="required" /><br>
<button type="submit" class="btn btn-primary btn-block btn-large">Predict</button>
</form>
<br>
<br>
</div>
{{pred}}
</body>
</html>
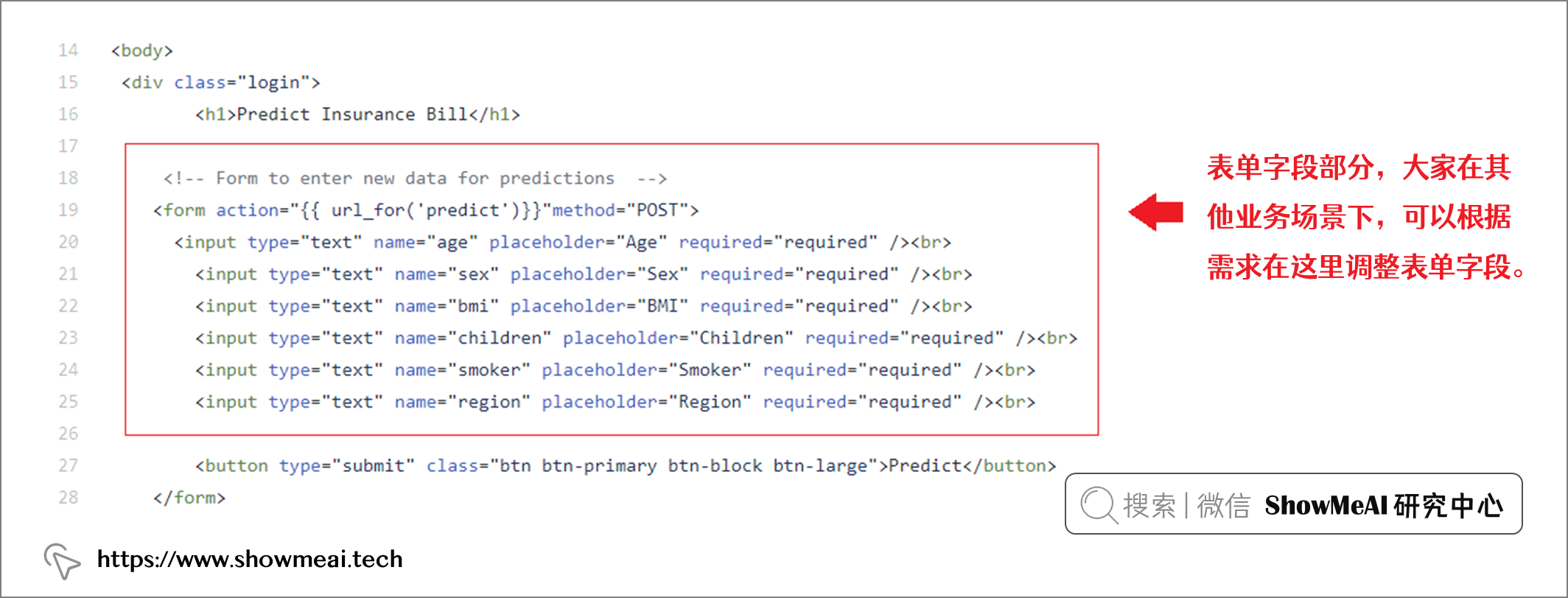
大家如果要构建简单的应用程序,不需要专门去学一遍 HTML 的高级知识。大家在互联网上可以找到大量 HTML 和 CSS 模板,甚至有些 ?在线平台 可以通过使用拖拽构建用户界面,并快速生成对应的 HTML 代码。
◉ CSS 样式表 CSS 负责描述 HTML 元素在屏幕上的呈现样式,借助 CSS 可以非常有效地控制应用程序的布局。存储在样式表中的信息包括边距、字体大小和颜色以及背景颜色。这些信息以 CSS 扩展名的文件格式存储在外部位置,主 HTML 文件包含对 CSS 文件的引用。
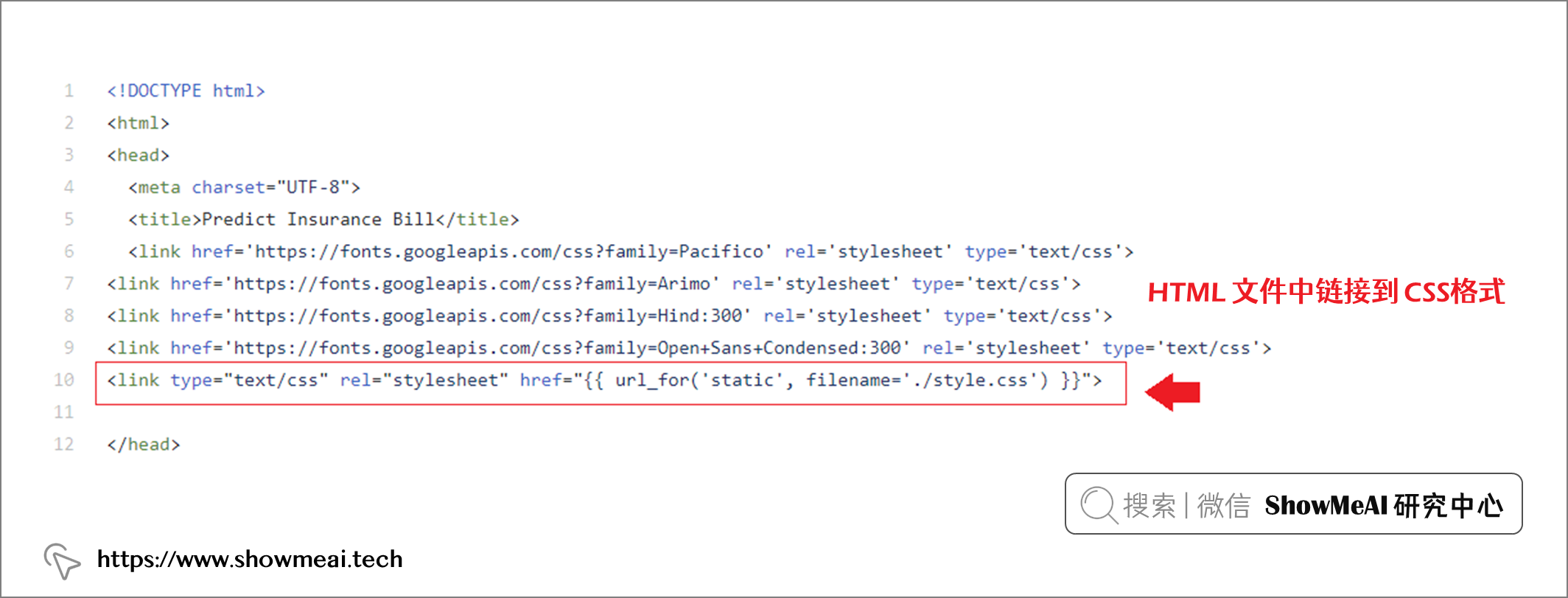
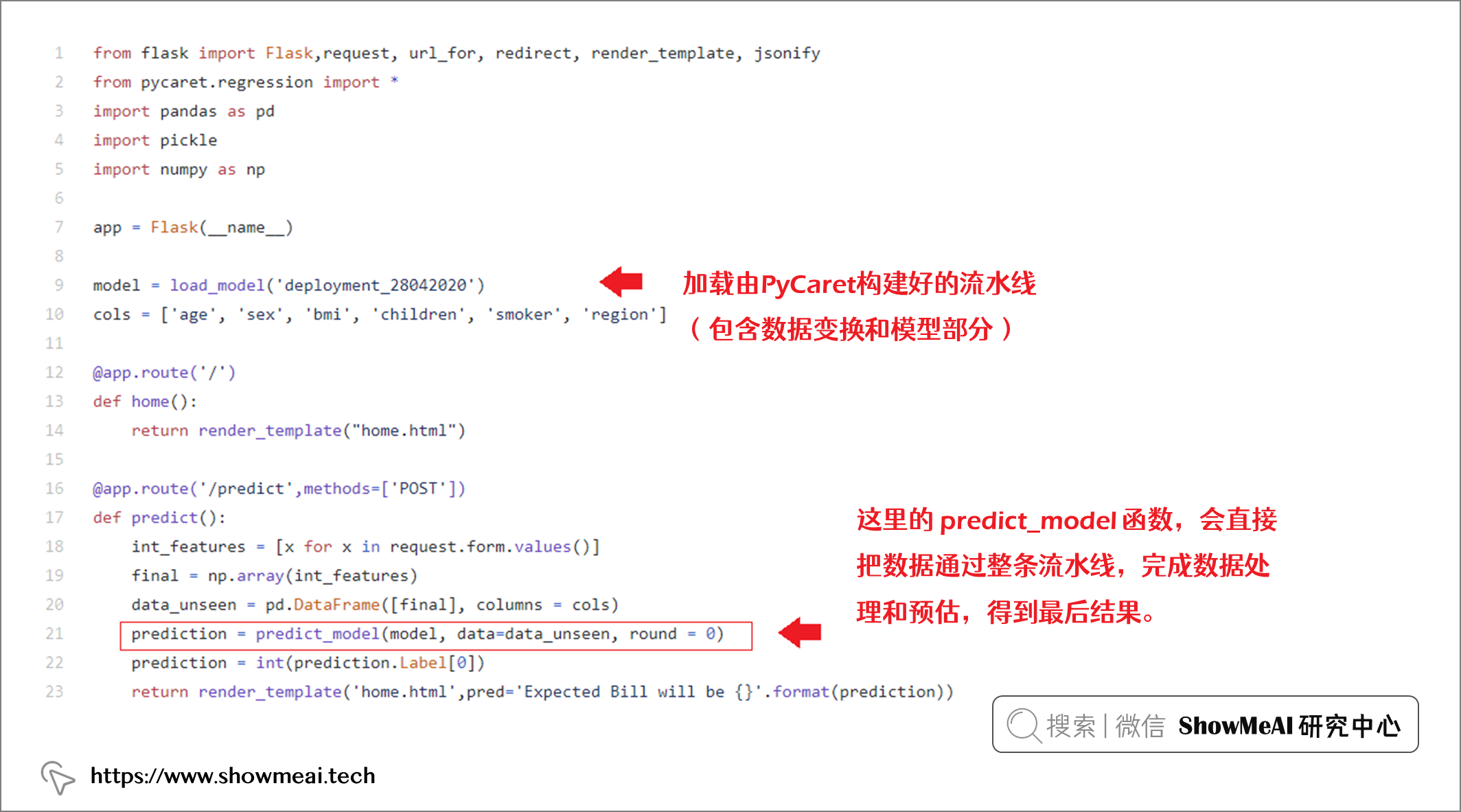
下面我们完成这个应用的后端,我们在 Python 中可以使用 Flask 工具库完成。关于 Flask 的详细知识大家可以参考 ?官方网站。我们的部分代码如下:
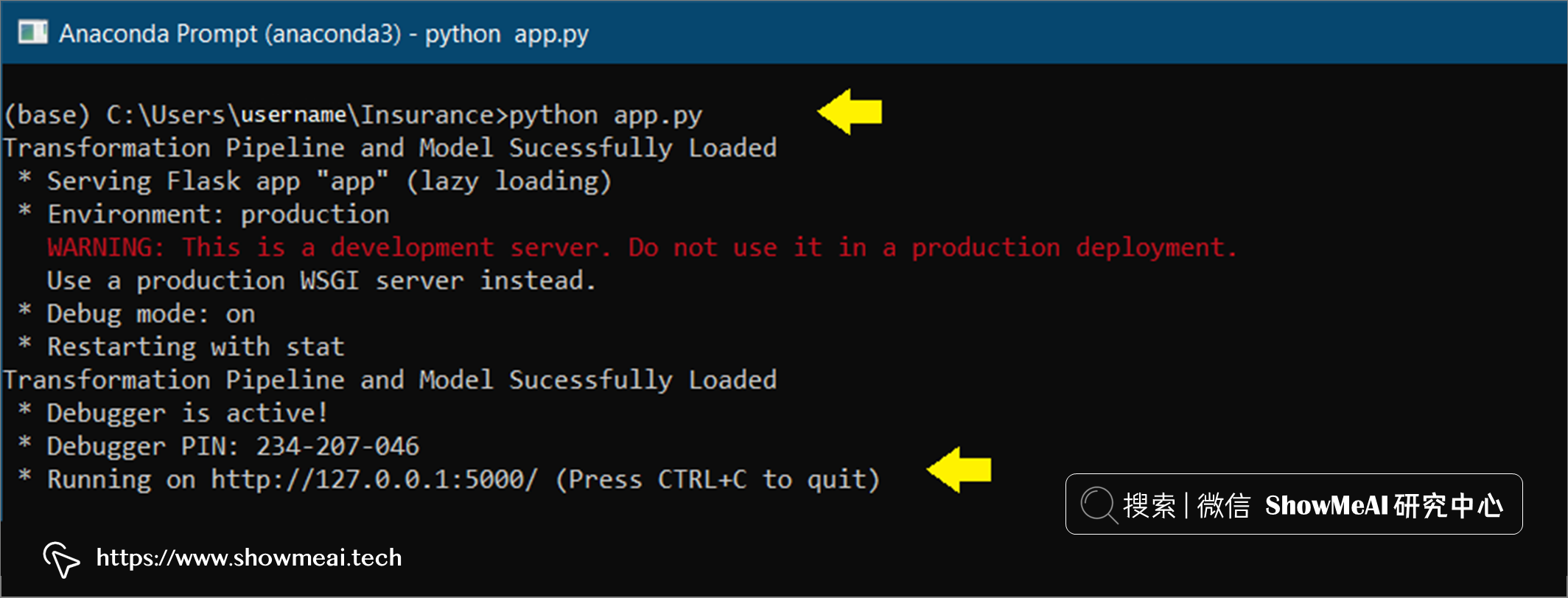
在云端部署之前,我们需要在本地测试应用是否正常工作。我们在命令行运行 python app.py:
python app.py
上图中大家可以在最后一行看到本地的测试 URL,我们把它粘贴到浏览器可以查看 Web 应用程序是否正常。我们还可以通过输入一些测试数据来检查预测功能是否正常运行。如下例中,我们输入信息:19 岁、吸烟、西南地区、没有孩子、女性,模型预测住院费用为 20900 美元。
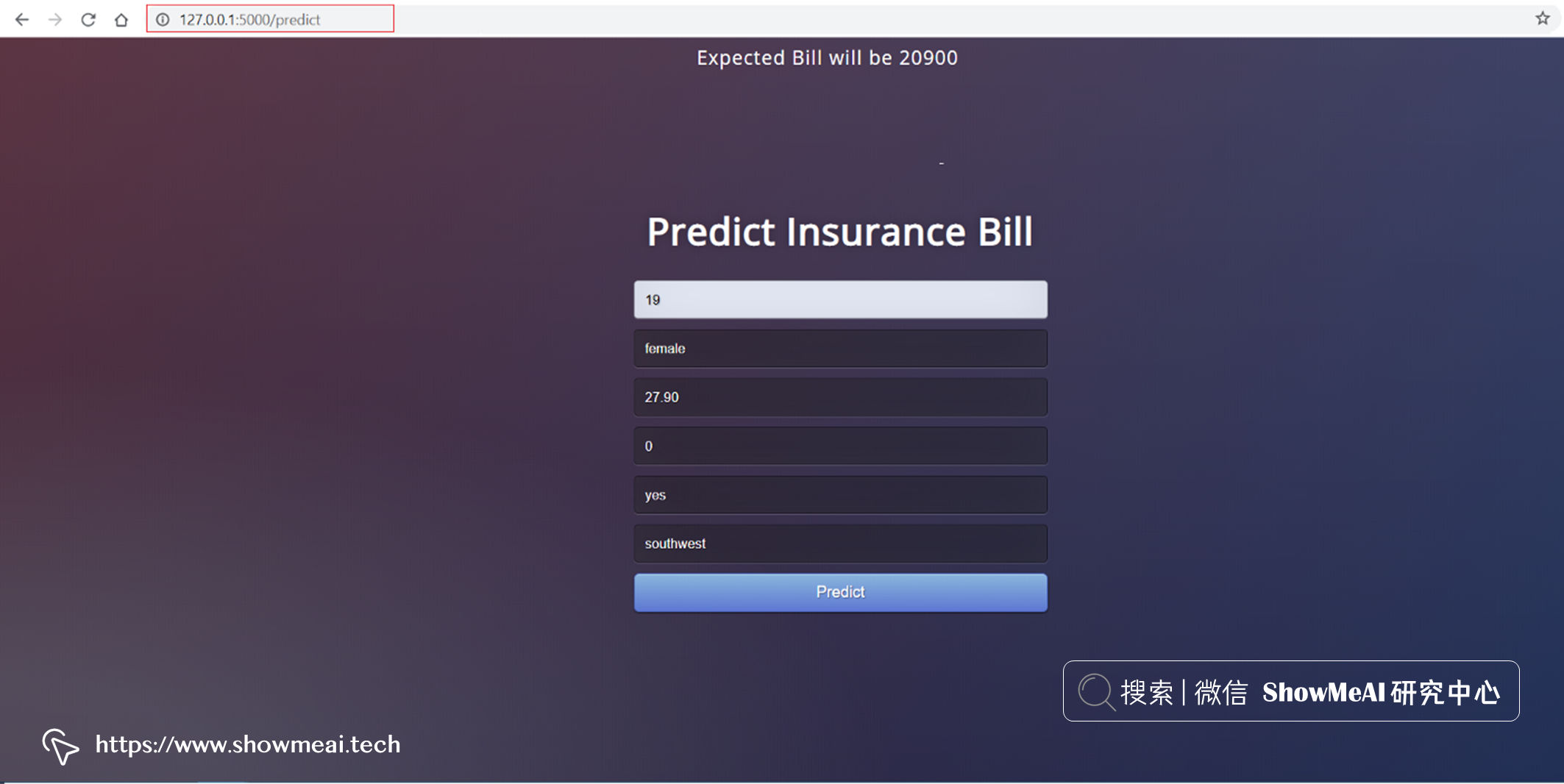
好啦,测试完毕,完全可以正常工作,我们在下一步把它部署到云端。
模型训练完成后,机器学习流水线已经准备好,且完成了本地测试,我们现在准备开始部署到 Heroku。有多种方法可以完成这个步骤,最简单的是将代码上传 GitHub ,并连接 Heroku 帐户完成部署。
下图是上传好的截图,大家可以在 ?https://www.github.com/pycaret/deployment-heroku 查看。
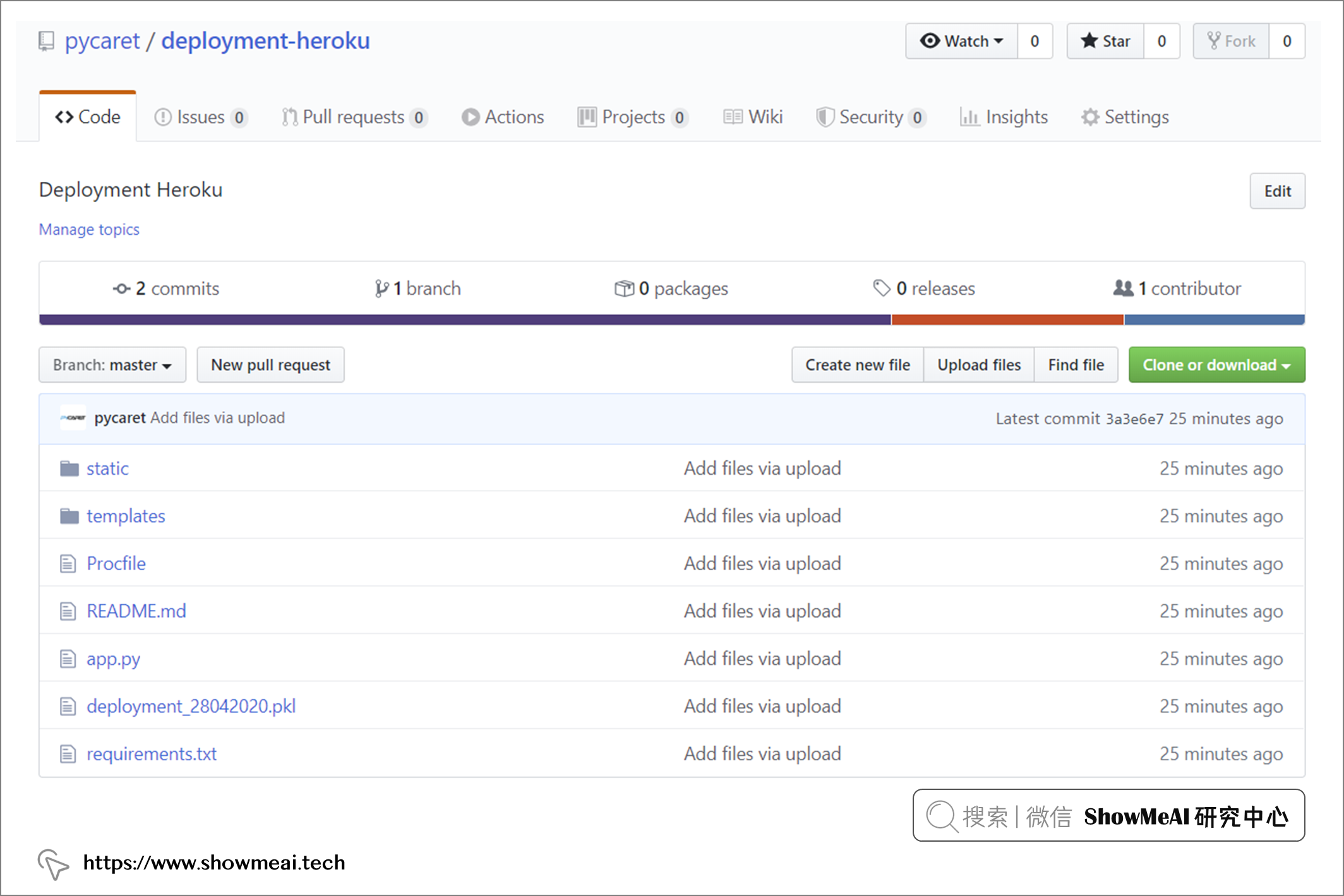
将所有文件上传到 GitHub 后,我们就可以开始在 Heroku 上进行部署了。如下为操作步骤:
在 ?heroku 上可以完成上述操作,如下图所示
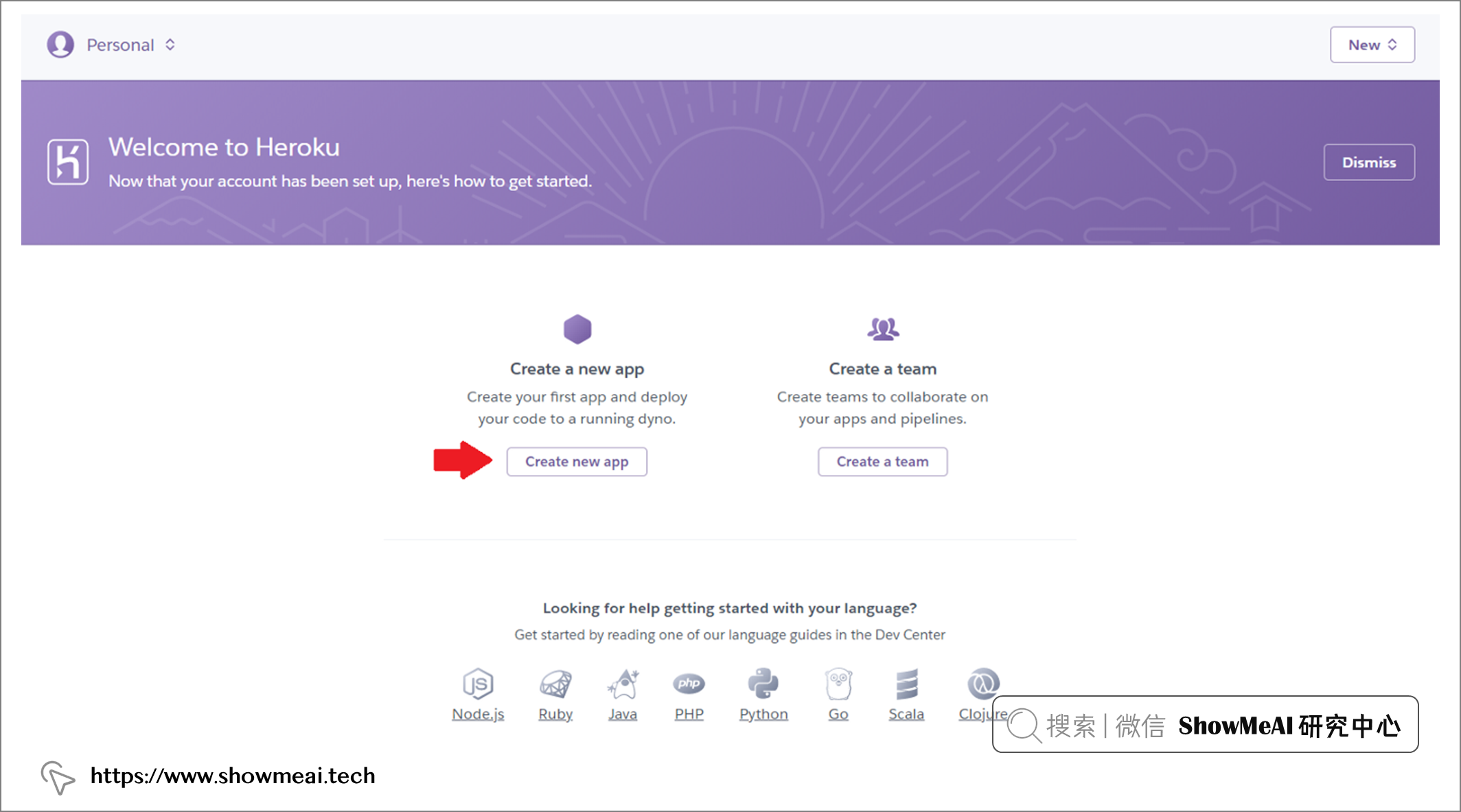
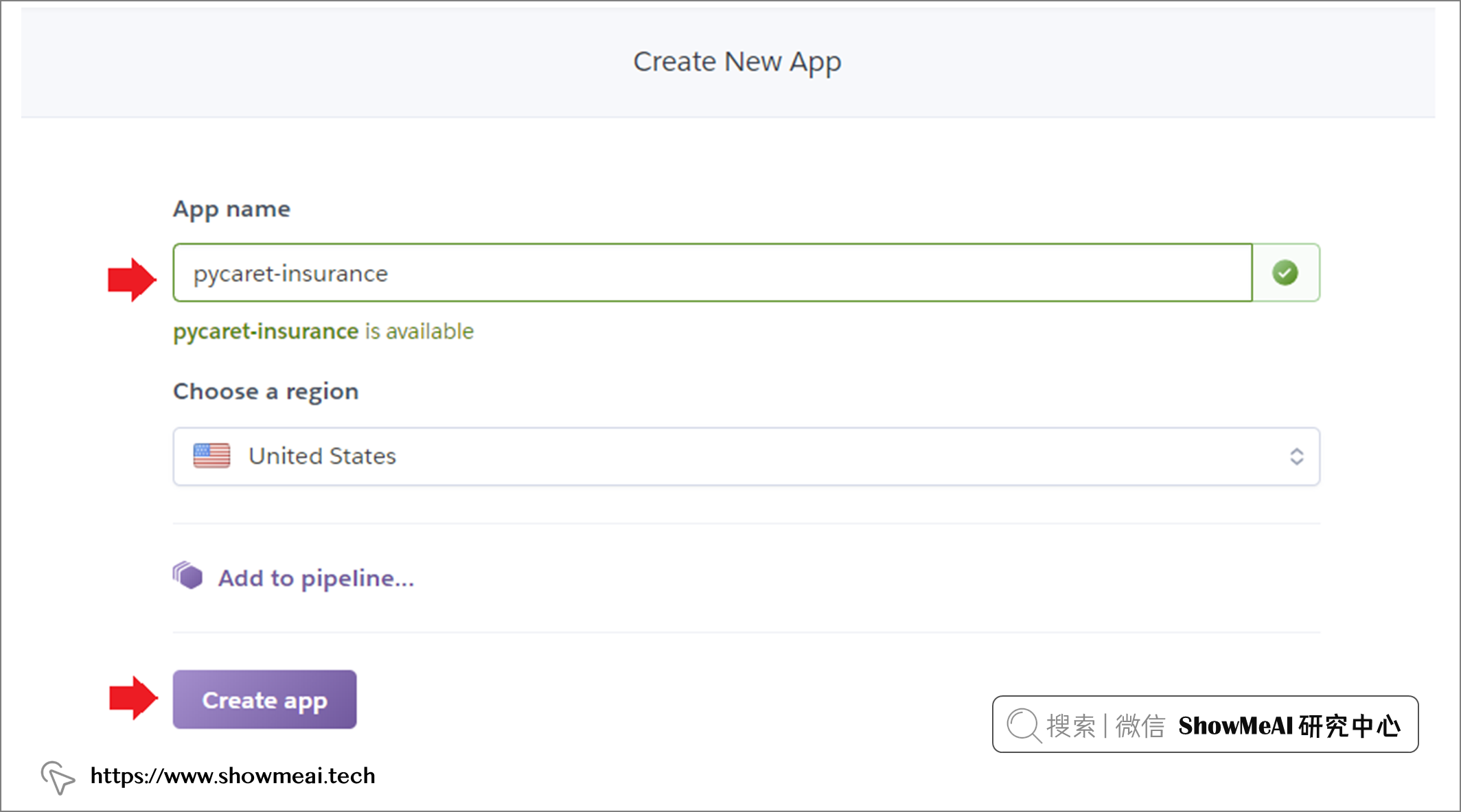
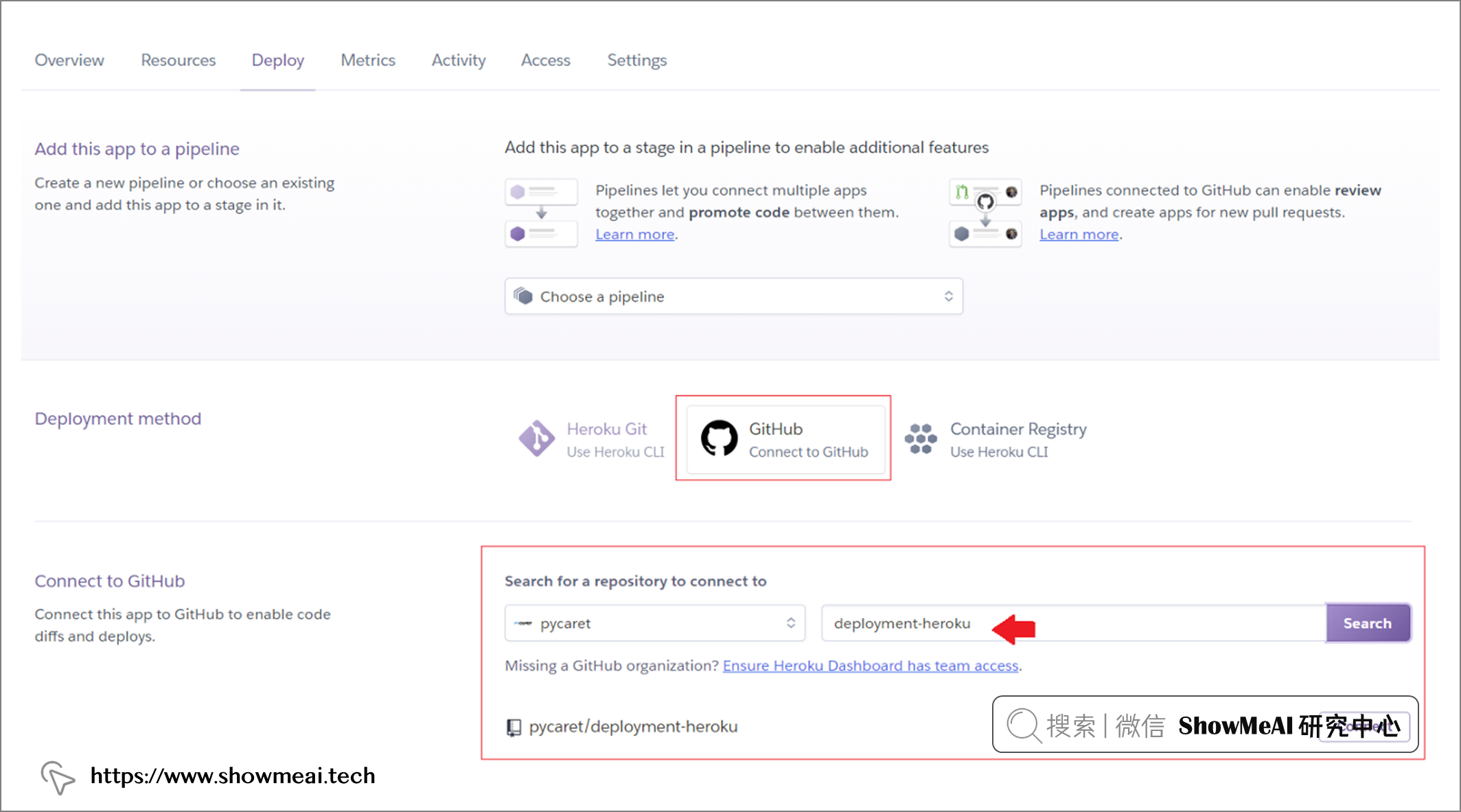
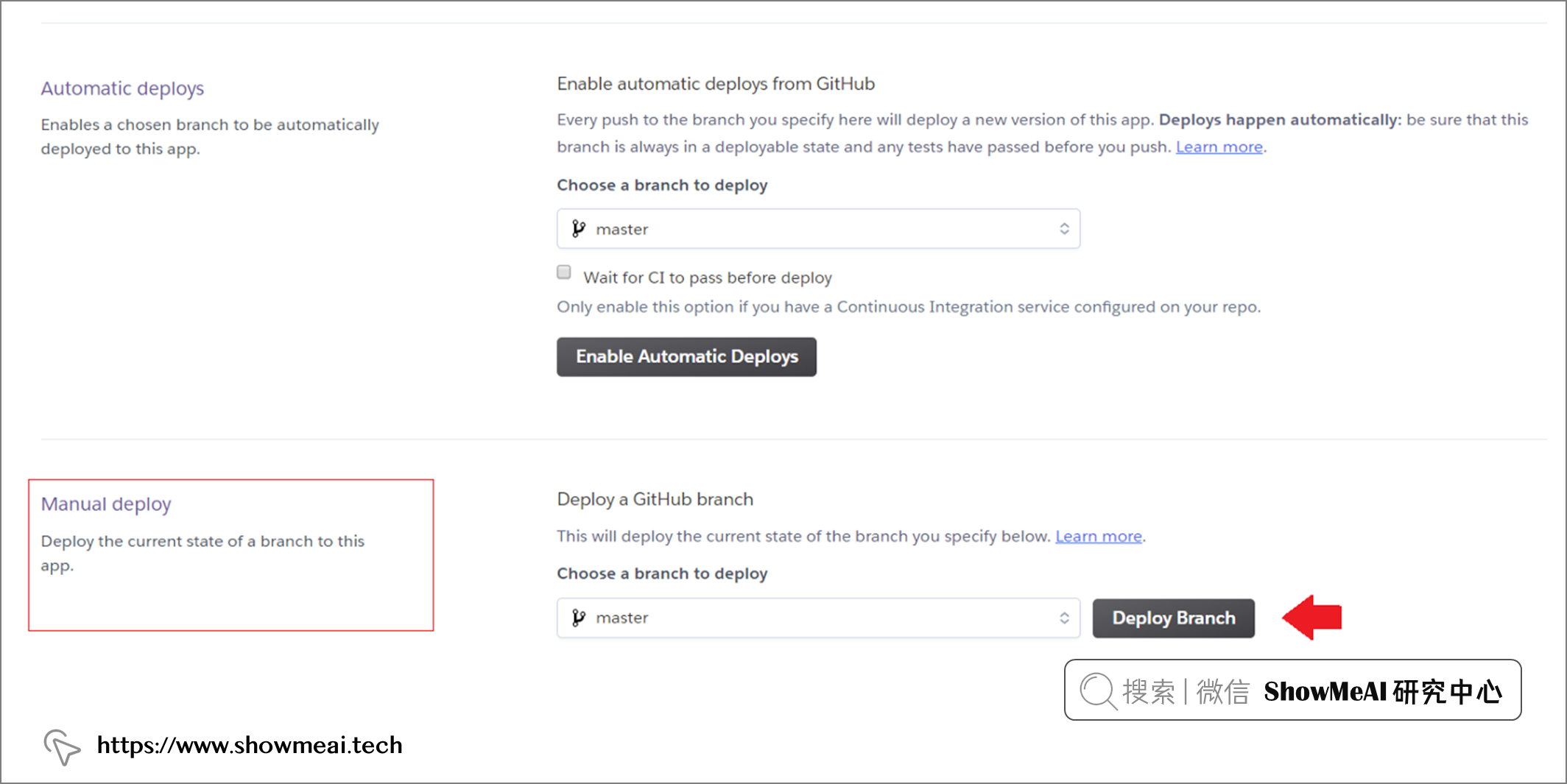
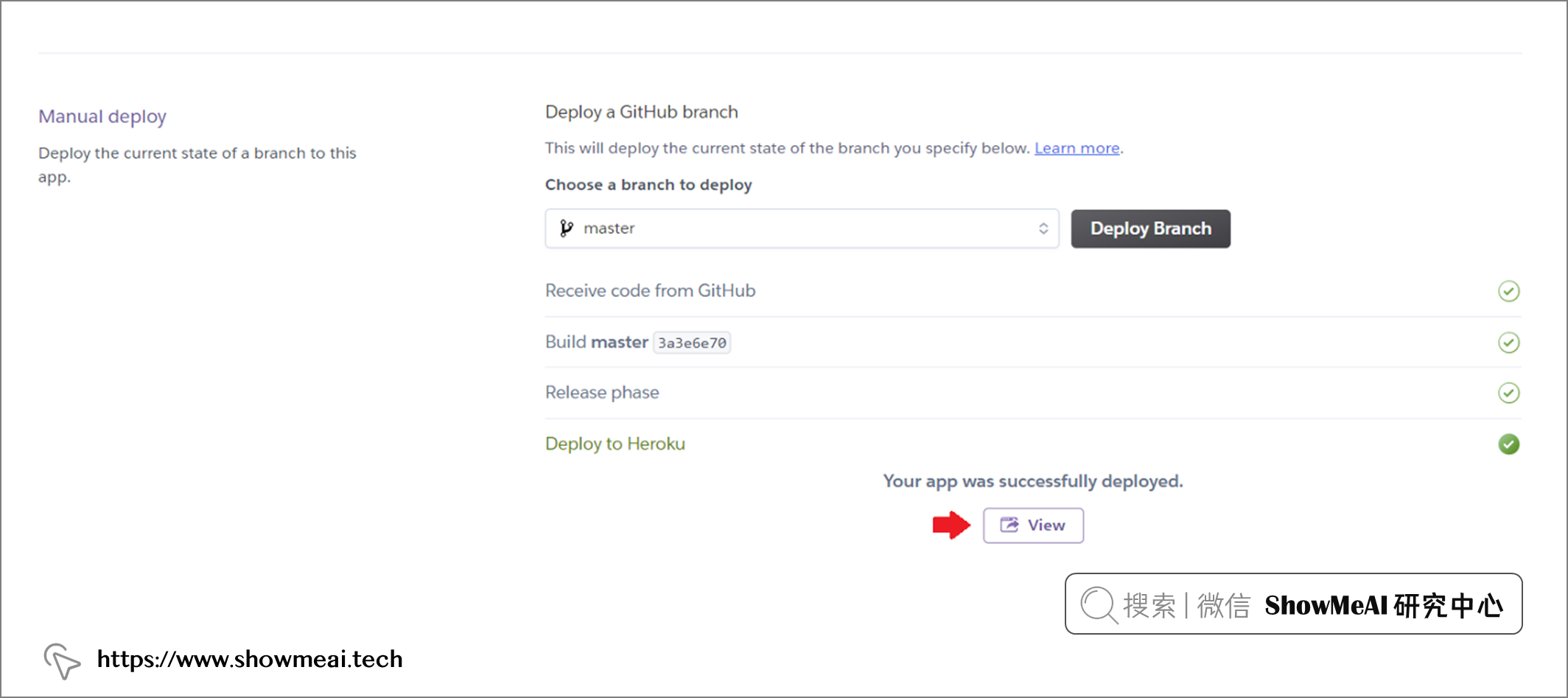
部署完成后,在有网络的情况下,就都可以访问对应的应用程序了 ?https ?/pycaret-insurance.herokuapp.com/。
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain