目录
pcm:pulse code modulation,脉冲编码调制。将声音等模拟信号变成符号化的脉冲列,予以记录。是由[0]、[1]等符号构成的数字信号,未经过任何编码和压缩处理。pcm是没有压缩的编码方式。
wav:wav是一种无损音频文件格式,wav都有一个文件头,文件头包括音频流的【编码参数】,而对音频流的编码没有硬性规定,符合ACM规范的编码都行,所以wav格式通常只要在其他编码(pcm、MP3)下,加相应的decode(头文件)就可以转换
图片引用来源:
WAV和PCM的关系和区别
声道数即声音通道的数目。比如单声道就是左右声道播放是同一个声音,立体声可以使左右声道分工,使听起来有空间效果。
也可以称为采样值或取样值,或叫采样精度、位深度,就是将采样样本幅度量化。例如8bits就是把纵坐标分成2的8次方,即256份。可以衡量声音波动变化的一个参数(声卡的分辨率)
取样频率,每秒取得声音样本的次数。频率越高,声音的质量也就越好,还原也就越真实。
由于人耳的分辨率很有限,太高的频率并不能分辨出来。在16位声卡中有22KHz、44KHz等几级,其中,22KHz相当于普通FM广播的音质,44KHz已相当于CD音质了,目前的常用采样频率都不超过48KHz
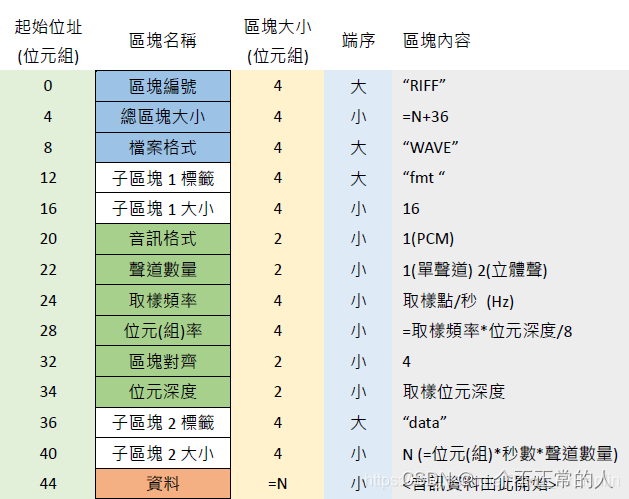
图片引用来源:PCM和WAV数据结构
pcm文件所占容量:储存量=(采样频率*采样位数*声道*时间)/ 8 | (8为单位,字节数)
import wave
import numpy as np
# pcm转wav格式,单声道,采样精度,采样率
def pcm2wav(pcm_file, wav_file, channels=1, bits=16, sample_rate=16000):
with open(pcm_file,'rb') as f:
pcmdata = f.read()
if bits % 8 != 0:
raise ValueError("bits % 8 must == 0. now bits:"+str(bits))
wavfile = wave.open(wav_file,'wb')
wavfile.setnchannels(channels)
wavfile.setsampwidth(bits // 8)
wavfile.setframerate(sample_rate)
wavfile.writeframes(pcmdata)
wavfile.close()
# wav转pcm格式
def wav2pcm(wav_file, pcm_file, data_type=np.int16):
with open(wav_file,'rb') as f:
f.seek(0)
f.read(44)
data = np.fromfile(f,dtype=data_type)
data.tofile(pcm_file)
#wav_file,pcm_file分别是两种格式文件的读取(存储)路径
————————————————————————
新学内容,外行,可能有误
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我需要读入一个包含数字列表的文件。此代码读取文件并将其放入二维数组中。现在我需要获取数组中所有数字的平均值,但我需要将数组的内容更改为int。有什么想法可以将to_i方法放在哪里吗?ClassTerraindefinitializefile_name@input=IO.readlines(file_name)#readinfile@size=@input[0].to_i@land=[@size]x=1whilex 最佳答案 只需将数组映射为整数:@land边注如果你想得到一条线的平均值,你可以这样做:values=@input[x]
这道题是thisquestion的逆题.给定一个散列,每个键都有一个数组,例如{[:a,:b,:c]=>1,[:a,:b,:d]=>2,[:a,:e]=>3,[:f]=>4,}将其转换为嵌套哈希的最佳方法是什么{:a=>{:b=>{:c=>1,:d=>2},:e=>3,},:f=>4,} 最佳答案 这是一个迭代的解决方案,递归的解决方案留给读者作为练习:defconvert(h={})ret={}h.eachdo|k,v|node=retk[0..-2].each{|x|node[x]||={};node=node[x]}node[
请帮助我理解范围运算符...和..之间的区别,作为Ruby中使用的“触发器”。这是PragmaticProgrammersguidetoRuby中的一个示例:a=(11..20).collect{|i|(i%4==0)..(i%3==0)?i:nil}返回:[nil,12,nil,nil,nil,16,17,18,nil,20]还有:a=(11..20).collect{|i|(i%4==0)...(i%3==0)?i:nil}返回:[nil,12,13,14,15,16,17,18,nil,20] 最佳答案 触发器(又名f/f)是
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
这个问题在这里已经有了答案:Railsformattingdate(4个答案)关闭4年前。我想格式化Time.Now函数以显示YYYY-MM-DDHH:MM:SS而不是:“2018-03-0909:47:19+0000”该函数需要放在时间中.现在功能。require‘roo’require‘roo-xls’require‘byebug’file_name=ARGV.first||“Template.xlsx”excel_file=Roo::Spreadsheet.open(“./#{file_name}“,extension::xlsx)xml=Nokogiri::XML::Build