图示:
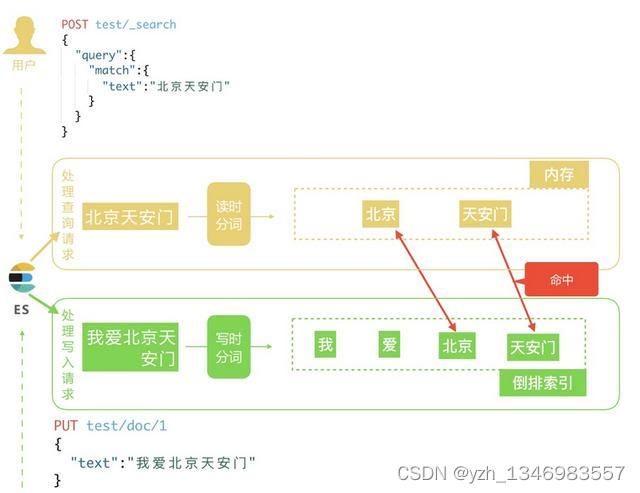
默认结合standard analyzer(标准解析器)对文本进行分词、倒排索引。
不支持聚合,排序操作。
模糊匹配,支持 term、match 查询。
不分词,直接将完整的文本保存到倒排索引中。
支持聚合、排序操作。
支持的最大长度为32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配数据。
精确匹配,支持 term、match 查询。
DELETE /yzh
PUT /yzh
{
"mappings": {
"properties": {
"code":{
"type": "keyword"
},
"desc":{
"type": "text"
}
}
}
}
POST /yzh/_doc
{
"code":"我的code1",
"desc":"我的第一个code啊"
}
POST /yzh/_doc
{
"code":"我的code2",
"desc":"我的第二个code啊"
}analyze(分析)数据:
POST /yzh/_analyze
{
"field":"code",
"text":"我的code1"
}
POST /yzh/_analyze
{
"field":"name",
"text":"我的第二个code啊"
}对比下方分析的结果,可发现 keyword 类型的字段不会分词直接整个文本存储到倒排索引中了,text 类型的字段分词后才进行倒排索引:
{
"tokens" : [
{
"token" : "我的code1",
"start_offset" : 0,
"end_offset" : 7,
"type" : "word",
"position" : 0
}
]
}{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "的",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "第",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "二",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "个",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "code",
"start_offset" : 5,
"end_offset" : 9,
"type" : "<ALPHANUM>",
"position" : 5
},
{
"token" : "啊",
"start_offset" : 9,
"end_offset" : 10,
"type" : "<IDEOGRAPHIC>",
"position" : 6
}
]
}索引 yzh 添加索引字段 name :name使用text类型,分词了,但name下添加字段keyword使用keyword类型,没有分词。
PUT /yzh/_mapping
{
"properties": {
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}GET /yzh/_mapping
结果:
{
"yzh" : {
"mappings" : {
"properties" : {
"code" : {
"type" : "keyword"
},
"desc" : {
"type" : "text"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}POST /yzh/_doc
{
"code":"我的code3",
"desc":"我的第三个code啊",
"name":"我看看咋结合的"
}
POST /yzh/_doc
{
"code":"我的code4",
"desc":"我的第四个code啊",
"name":"我看看咋结合的2"
}
POST /yzh/_analyze
{
"field":"name.keyword",
"text":"我看看咋结合的"
}
结果:
{
"tokens" : [
{
"token" : "我看看咋结合的",
"start_offset" : 0,
"end_offset" : 7,
"type" : "word",
"position" : 0
}
]
}POST /yzh/_analyze
{
"field":"name",
"text":"我看看咋结合的"
}
结果:
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "看",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "看",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "咋",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "结",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "合",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "的",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 6
}
]
}term精确查询:name(name为text类型,分词了)
GET /yzh/_search
{
"query": {
"term": {
"name": "我看看咋结合的"
}
}
}
结果为空term精确查询:name.keyword(name.keyword为keyword类型,没有分词)
GET /yzh/_search
{
"query": {
"term": {
"name.keyword": "我看看咋结合的"
}
}
}
结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.6931472,
"hits" : [
{
"_index" : "yzh",
"_type" : "_doc",
"_id" : "HQzrwYABJSFE9aEtrO9q",
"_score" : 0.6931472,
"_source" : {
"code" : "我的code3",
"desc" : "我的第三个code啊",
"name" : "我看看咋结合的"
}
}
]
}
}match模糊匹配:name(name为text类型,分词了)
GET /yzh/_search
{
"query": {
"match": {
"name": "我"
}
}
}
结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.4481319,
"hits" : [
{
"_index" : "yzh",
"_type" : "_doc",
"_id" : "HQzrwYABJSFE9aEtrO9q",
"_score" : 1.4481319,
"_source" : {
"code" : "我的code3",
"desc" : "我的第三个code啊",
"name" : "我看看咋结合的"
}
},
{
"_index" : "yzh",
"_type" : "_doc",
"_id" : "7QwDwoABJSFE9aEtae_F",
"_score" : 1.3795623,
"_source" : {
"code" : "我的code4",
"desc" : "我的第四个code啊",
"name" : "我看看咋结合的2"
}
}
]
}
}精确查询,搜索前不会再对搜索词进行分词拆解。
GET /yzh/_search
{
"query": {
"term": {
"code": "我的code1"
}
}
}
GET /yzh/_search
{
"query": {
"term": {
"desc": "我"
}
}
}term属于精确匹配,只能查单个词。精确匹配多个词使用terms。
GET /yzh/_search
{
"query": {
"terms": {
"desc": ["我","二"]
}
}
}terms里的 [ ] 是 或 的关系,只要匹配到其中一个词就会返回。想要多个词同时匹配,就得使用bool的must来做,如下:
GET /yzh/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"desc": "我"
}
},
{
"term": {
"desc": "二"
}
}
]
}
}
}先进行分词拆分,拆完词再匹配查询。
GET /yzh/_search
{
"query": {
"match": {
"code": "我的code1"
}
}
}
GET /yzh/_search
{
"query": {
"match": {
"desc": "我1"
}
}
}match拆词后,只要匹配到其中一个词就会返回。想要多个词同时匹配,就得使用match的and模式。
GET /yzh/_search
{
"query": {
"match": {
"desc": {
"query": "我一",
"operator": "and"
}
}
}
}要求所有的分词必须同时出现在文档中,同时位置必须紧邻一致,就得使用match_phrase。
GET /yzh/_search
{
"query": {
"match_phrase": {
"desc": "我的第二个"
}
}
}
GET /yzh/_search
{
"query": {
"match_phrase": {
"desc": "我第"
}
}
}其中一个字段包含分词就被文档就被搜索到时,可以用multi_match。
GET /yzh/_search
{
"query": {
"multi_match": {
"query": "我q",
"fields": [
"code",
"desc"
]
}
}
}我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
所以我在关注Railscast,我注意到在html.erb文件中,ruby代码有一个微弱的背景高亮效果,以区别于其他代码HTML文档。我知道Ryan使用TextMate。我正在使用SublimeText3。我怎样才能达到同样的效果?谢谢! 最佳答案 为SublimeText安装ERB包。假设您安装了SublimeText包管理器*,只需点击cmd+shift+P即可获得命令菜单,然后键入installpackage并选择PackageControl:InstallPackage获取包管理器菜单。在该菜单中,键入ERB并在看到包时选择
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
-if!request.path_info.include?'A'%{:id=>'A'}"Text"-else"Text"“文本”写了两次。我怎样才能只写一次并同时检查path_info是否包含“A”? 最佳答案 有两种方法可以做到这一点。使用部分,或使用content_forblock:如果“文本”较长,或者是一个重要的子树,您可以将其提取到一个部分。这会使您的代码变干一点。在给出的示例中,这似乎有点矫枉过正。在这种情况下更好的方法是使用content_forblock,如下所示:-if!request.path_info.inc
我在尝试使用Nokogiri构建XML文档时遇到了一个小问题。我想将我的元素之一称为“文本”(请参阅下面粘贴代码的最底部)。通常,要创建一个新元素,我会执行类似以下的操作xml.text--但它似乎是.text是Nokogiri已经用来做其他事情的方法。因此,当我写这行时xml.textNokogiri没有创建名为的新元素但只是写了意味着成为元素内容的文本。我怎样才能让Nokogiri实际制作一个名为的元素??builder=Nokogiri::XML::Builder.newdo|xml|xml.TEI("xmlns"=>"http://www.tei-c.org/ns/1.0"
所以...SublimeText具有折叠方法的内置功能,但是一旦方法声明跨越多行,它就会失去这种能力。有谁知道插件或使它工作的方法吗?具体来说,我在使用ruby时遇到了这个问题(我的团队遵守关于行长度的严格风格指南),但语言应该无关紧要。 最佳答案 无需单击出现在函数定义第一行旁边的装订线中的向下箭头,您需要做的就是将光标放在函数的一个缩进行上(不是缩进的函数参数,而是在函数定义本身)并使用CtrlShift[键绑定(bind)(在OSX上使用⌘Alt[)折叠函数及其参数。使用CtrlShift](⌘Alt]在OSX上)展开,或
我是程序员的新手,请原谅我的新手。所以我正在使用Nokogiri来抓取警方的犯罪记录。这是下面的代码:require'rubygems'require'nokogiri'require'open-uri'url="http://www.sfsu.edu/~upd/crimelog/index.html"doc=Nokogiri::HTML(open(url))putsdoc.at_css("title").textdoc.css(".brief").eachdo|brief|putsbrief.at_css("h3").textend我使用选择器小工具书签来查找日志(.brief)的C
我的ruby脚本从命令行参数获取某些输入。它检查是否缺少任何命令行参数,然后提示用户输入。但是我无法使用gets从用户那里获得输入。示例代码:test.rbname=""ARGV.eachdo|a|ifa.include?('-n')name=aputs"Argument:#{a}"endendifname==""puts"entername:"name=getsputsnameend运行脚本:rubytest.rbraghav-k错误结果:test.rb:6:in`gets':Nosuchfileordirectory-raghav-k(Errno::ENOENT)fromtes
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a