路由懒加载指的是打包部署时将资源按照对应的页面进行划分,需要的时候加载对应的页面资源,而不是把所有的页面资源打包部署到一块。避免不必要资源加载。(参考vue项目实现路由按需加载(路由懒加载)的3种方式_小胖梅的博客-CSDN博客_vue懒加载 )
// 非懒加载
import Home from '@/components/Home'
const routes = [
{
path: '/home',
name: 'home',
component: Home
}
]这里有三种方式可以实现vue项目路由跳转时资源的按需加载。
1. vue异步组件
vue-router配置路由,使用vue的异步组件技术,可以实现按需加载。
但是,这种情况下每一个组件就会生成一个js文件,不能分类指定chunkName
// vue异步组件
{
path: '/home',
name: 'home',
component: resolve => require(['@/components/home'], resolve)
}2. 使用import
// const 组件名 = () => import('组件路径');
// 下面2行代码,没有指定webpackChunkName,每个组件打包成一个js文件。
const Home = () => import('@/componnets/home');
const Index = () => import('@/components/index');
// 下面2行代码,指定了相同的webpackChunkName,会合并打包成一个js文件
// 把组件按组分块
const Home = () => import(/* webpackChunkName: 'ImportFuncDemo' */ '@/components/home');
const Index = () => import(/* webpackChunkName: 'ImportFuncDemo' */ '@/components/index')
{
path: '/home',
name: 'home',
component: Home
}, {
path: '/index',
name: 'index',
component: Index
}
3. webpack提供的require.ensure()
该方法也可指定相同的chunkName,合并打包成一个js文件。
{
path: '/home',
name: 'home',
component: r => require.ensure([], () => r(require('@/components/home')), 'demo')
}, {
path: '/index',
name: 'index',
component: r => require.ensure([], () => r(require('@/components/index')), 'demo')
}, {
path: '/about',
name: 'about',
// 传入空字符串 则每个component会单独生成一个js文件
component: r => require.ensure([], () => r(require('@/components/index')), '')
}公司后台项目路由懒加载模式修改(新后台vue2.0)
项目背景:老后台(angular1.x版本)正在迁移新后台(vue2.0)
未修改之前:
打完包之后有156个js文件,这是按照每个路由对应的component生成一个js文件,这就意味着到时候老后台全部迁移到新后台之后,目前大概有800个路由,那就会生成800多个js文件,这种模式的路由懒加载对于后台管理系统其实是没有必要的,所以考虑通过webpackChunkName将各个模块分类,一个一级分类指定一个chunkName。
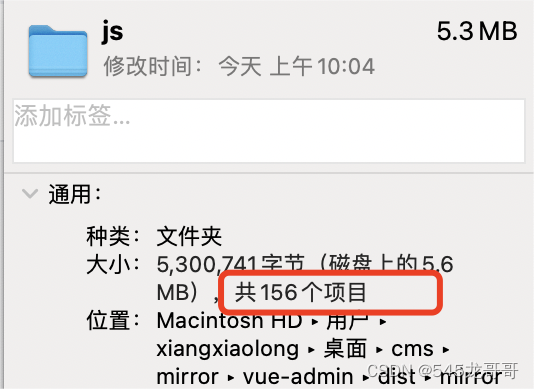
修改之后:
打完包只有25个js文件,看起来就舒服多了。

各个大模块路由懒加载修改的格式如下:
在一个大的路由模块下,指定相同的webpackChunkName。
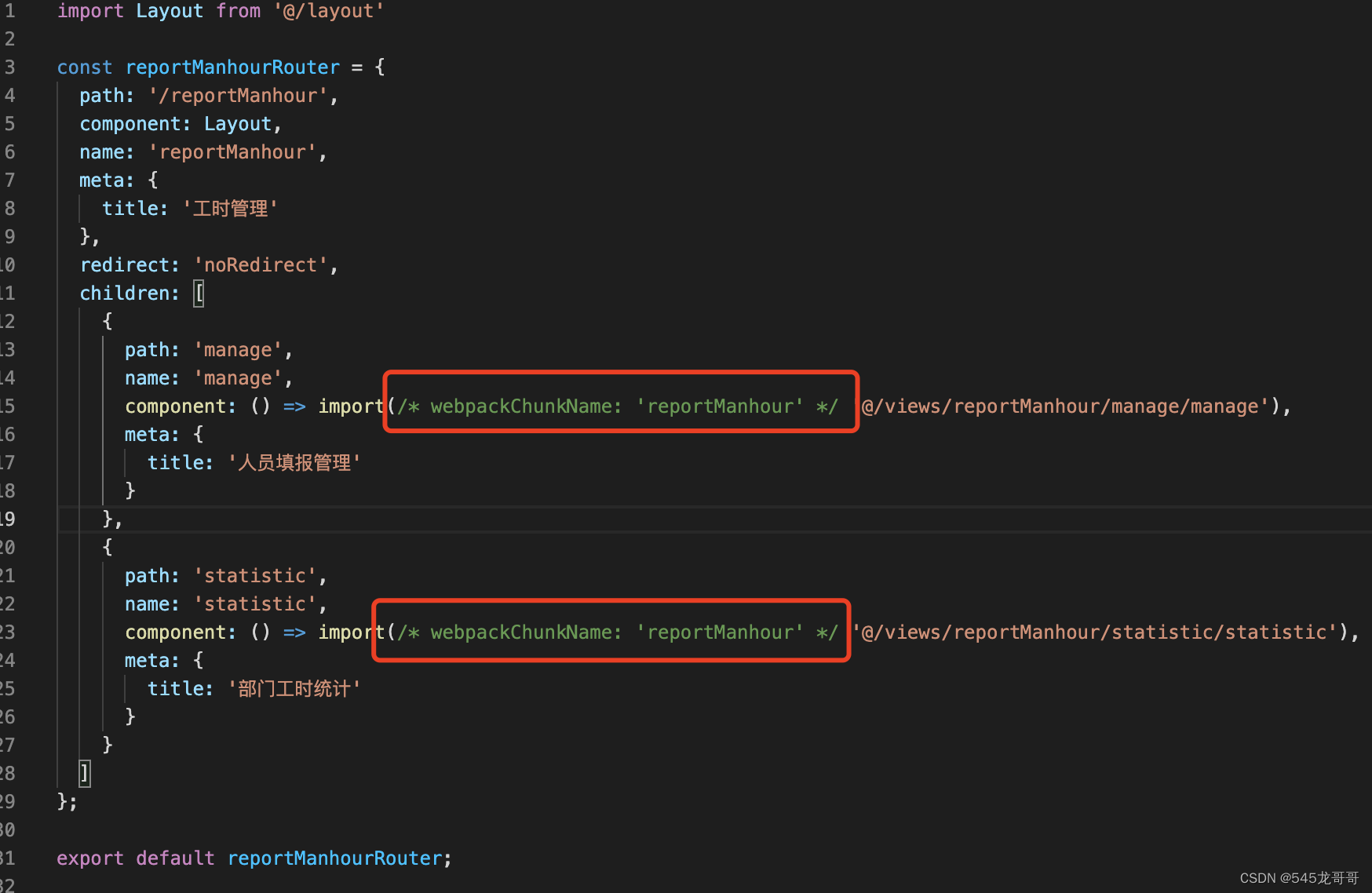
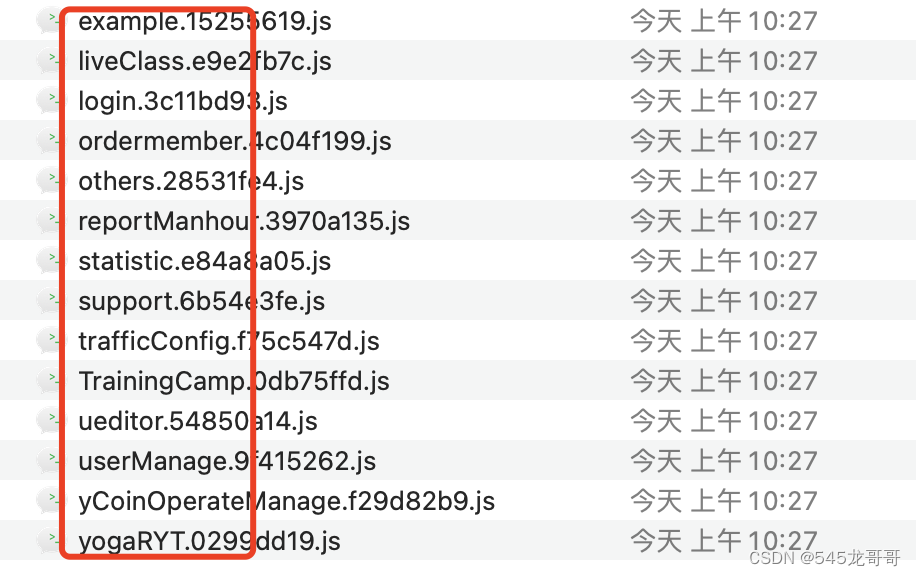
修改之后打包生成的文件名格式如下:
hash值之前为自己设置的webpackChunkName名称。
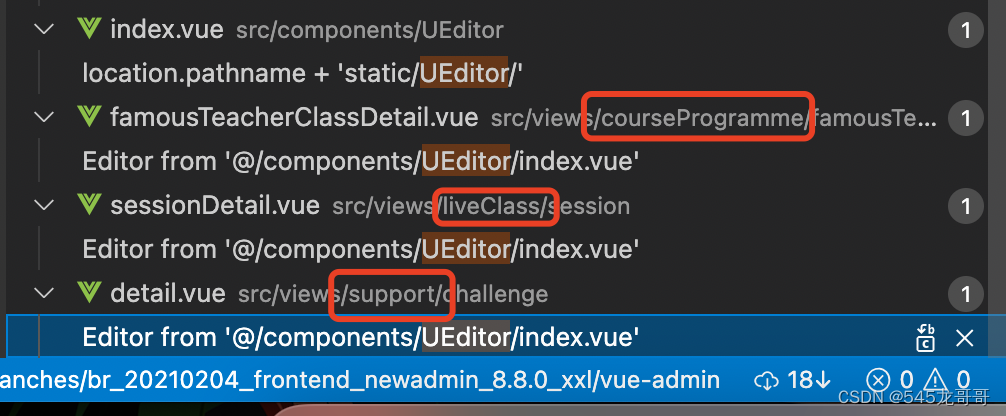
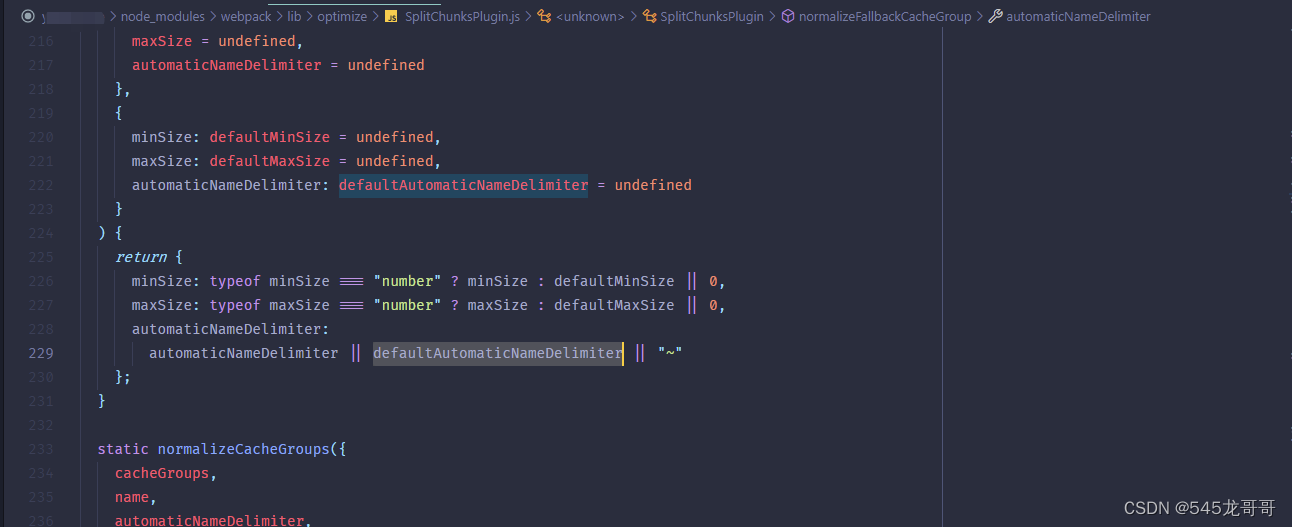
这里当时遇到的一个问题如下图所示:

如左边红框所示,生成的文件里面多了一个用 '~' 拼接起来的js文件。
这个后来翻到了webpack的splitChunks.automaticNameDelimiter。因为项目中在这三个模块下,都引入了同一个文件(UEditor),并且项目中也并没有指定对应的webpackChunkName,所以webpack内部自动处理,将这个文件单独提取出来,并自动命名,命名规则见webpack官方文档,连接符 '~' 是可配置的。
出现 '~' 连接符的组件引入方式如下:
修改之后的引入方式如下:
指定了webpackChunkName,以后其他模块引入富文本UEditor时也请按照此方式引入,命名保持相同。

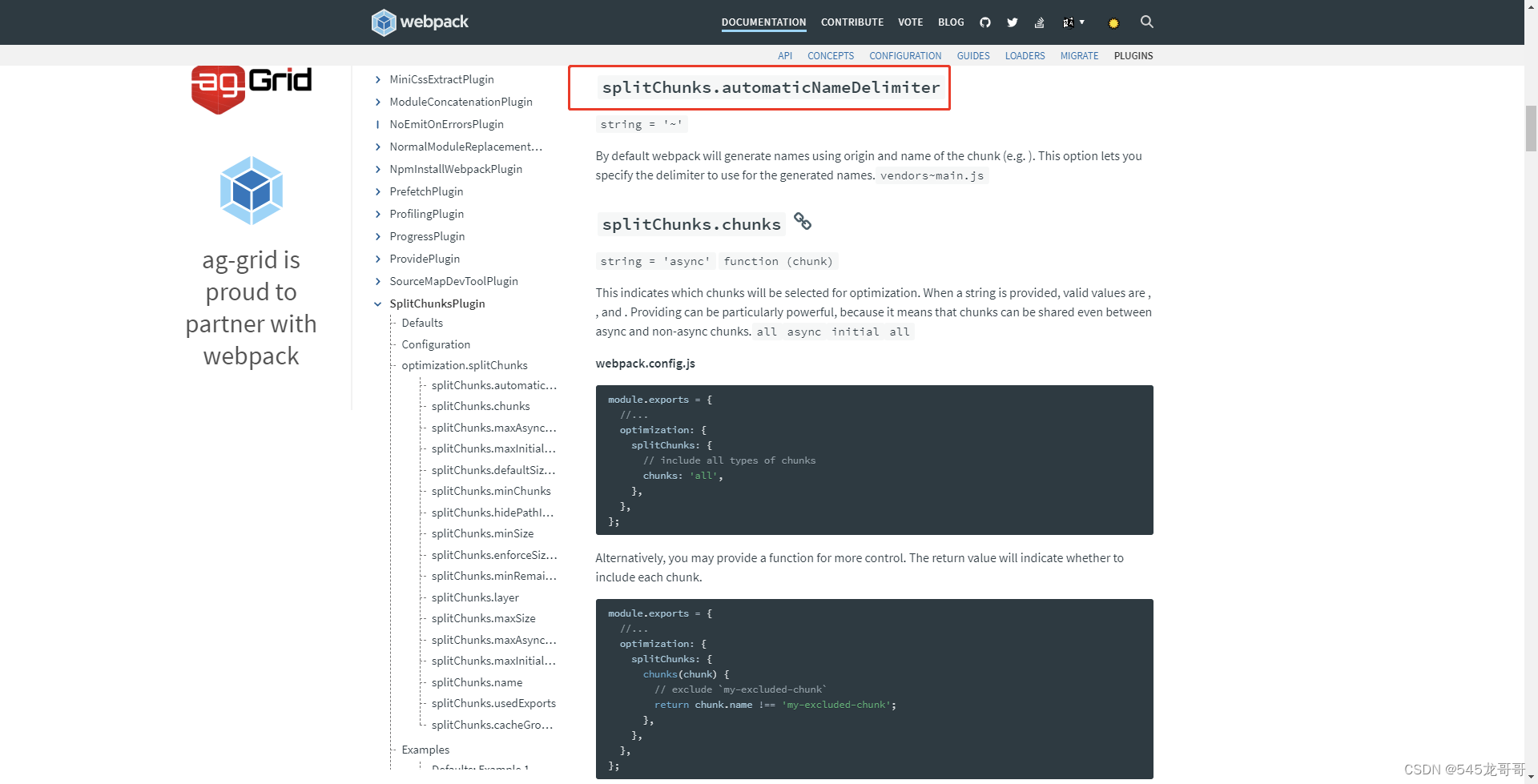
以下是webpack官方文档对automaticNameDelimiter配置的解释。
vue-router核心原理解析:(参考【第2194期】SPA 路由三部曲之核心原理 )
路由描述了URL和UI之间的映射关系,这种映射是单向的,即URL变化引起UI更新(无需刷新页面)。前端路由最主要的展示方式有2种:
在vue-router中,这两种展示形式,被定义成两种模式,即Hash模式与History模式。前端路由实现原理很简单,本质上就是检测URL的变化,截获URL地址,通过解析、匹配路由规则实现UI更新。
① Hash模式
一个完整的URL包括:协议、域名、端口、虚拟目录、文件名、参数、锚。

Hash值指的是URL地址中的锚部分,也就是# 后面的部分。hash也称作锚点,是用来做页面定位的,与hash值对应的DOM id显示在可视区域内。在HTML5的history新特性出现前,基本都是使用监听hash值来实现前端路由的。hash值更新有一下几个特点:
而改变hash值的方式有3种:
综上所述,这3种改变hash值的方式,并不会导致浏览器向服务器发送请求,浏览器不发出请求,也就不会刷新页面。hash值改变,触发全局的window对象上的hashchange事件。所以hash模式路由就是利用hashchange事件监听URL的变化,从而进行DOM操作来模拟页面跳转。
② History模式
主要应用了History API新增的两个方法:pushState()、replaceState(),均具有操纵浏览器历史记录的能力。
history.pushState(state, title, URL),该方法共接收3个参数:
pushState函数会向浏览器的历史记录中国添加一条,history.length的值会+1,当前浏览器的URL变成了新的URL。需要注意的是:仅仅将浏览器的URL变成了新的URL,页面不会加载、刷新。
history.replaceState(state, title, URL)
replaceState的使用与pushState非常相似,都是改变当前的URL,页面不刷新。区别在于replaceState是修改了当前的历史记录项而不是新建一个,history.length的值保持不变。
window.onpopstate()
为了配合history.pushState()或者history.replaceState(),HTML5还新增了一个事件,用于监听URL历史记录改变:window.onpopstate。
官方对于window.onpopstate()事件的描述是这样的:
每当处于激活状态的历史记录条目发生变化时,popstate事件就会在对应的window对象上触发。如果当前处于激活状态的历史记录条目是由history.pushState()方法创建,或者由history.replaceState()方法修改过的,则popstate事件对象的state属性包含了这个历史记录条目的state对象的一个拷贝。调用history.pushState()或者history.replaceState()不会触发popstate事件。popstate事件只会在浏览器某些行为下触发,比如点击后退、前进按钮(或者在Javascript中调用 history.back()、history.foward()、history.go()方法),此外,a标签的锚点也会触发该事件。
结合上述,在浏览器支持 pushState 的情况下,hash 模式路由也可以使用 pushState 、replaceState 和 popstate 实现。pushstate 改变 hash 值,进行跳转,popstate 监听 hash 值的变化。小小的剧透,vue-router 中不管是 hash 模式,还是 history 模式,只要浏览器支持 history 的新特性,使用的都是 history 的新特性进行跳转。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我一直致力于让我们的Rails2.3.8应用程序在JRuby下正确运行。一切正常,直到我启用config.threadsafe!以实现JRuby提供的并发性。这导致lib/中的模块和类不再自动加载。使用config.threadsafe!启用:$rubyscript/runner-eproduction'pSim::Sim200Provisioner'/Users/amchale/.rvm/gems/jruby-1.5.1@web-services/gems/activesupport-2.3.8/lib/active_support/dependencies.rb:105:in`co
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use
我真的为这个而疯狂。我一直在搜索答案并尝试我找到的所有内容,包括相关问题和stackoverflow上的答案,但仍然无法正常工作。我正在使用嵌套资源,但无法使表单正常工作。我总是遇到错误,例如没有路线匹配[PUT]"/galleries/1/photos"表格在这里:/galleries/1/photos/1/edit路线.rbresources:galleriesdoresources:photosendresources:galleriesresources:photos照片Controller.rbdefnew@gallery=Gallery.find(params[:galle
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
Rails中有没有一种方法可以提取与路由关联的HTTP动词?例如,给定这样的路线:将“users”匹配到:“users#show”,通过:[:get,:post]我能实现这样的目标吗?users_path.respond_to?(:get)(显然#respond_to不是正确的方法)我最接近的是通过执行以下操作,但它似乎并不令人满意。Rails.application.routes.routes.named_routes["users"].constraints[:request_method]#=>/^GET$/对于上下文,我有一个设置cookie然后执行redirect_to:ba
路由有如下代码:resources:orders,only:[:create],defaults:{format:'json'}resources:users,only:[:create,:update],defaults:{format:'json'}resources:delivery_types,only:[:index],defaults:{format:'json'}resources:time_corrections,only:[:index],defaults:{format:'json'}是否可以使用1个字符串为所有资源设置默认格式,每行不带“默认值”散列?谢谢。