目录
所有AVI文件以"RIFF"表示符后跟的标识码‘AVI’开始。
| R | I | F | F | 文件大小 | 文件类型(AVI) | 数据......
|

RIFF块各字段描述:
| 十六进制数 | 描述 |
| 52 49 46 46 | 表示“RIFF”字符串 |
| 98 82 86 01 | 文件大小01 86 82 98=25,592,472字节,RIFF文件大小不包括“RIFF”域和“文件大小”域本身的大小(共8个字节),实际在Windows系统下看到的文件大小为25,592,472+8=25,592,480字节 。 |
| 41 56 49 20 | ASCII码转换为“AVI” |
所有AVI文件包含两个必须的LIST chunk和一个索引chunk
结构如下图所示:


| 十六进制数 | 描述 |
| 5C 49 53 54 | 表示“LIST”字符串 |
| CA 22 00 00 | LIST大小 00 00 22 CA=8906字节,列表中长度为8906+8=8914字节 |
| 68 64 72 6C | ASCII码转换为“hdrl”,表示该LIST是'hdrl'LIST |
hdrl LIST块定义AVI文件的数据格式
“hdrl”LIST块包含两个子块,一个是ID为“avih”的子块和一个是ID为”strl”的LIST块。
avih块用于记录AVI文件的全局信息,比如流的数量,视频图像的宽和高等:

| 十六进制数 | 描述 |
| 61 76 69 68 | 表示“avih”字符串 |
| 00 00 00 38 | LIST大小 00 00 00 38=56字节,列表中长度为56+8=64字节 |
typedef struct
{
DWORD ChunID; // 必须为'avih'
DWORD ChunkSize; //本数据结构的大小,不包括最初的8個位元組(ID和Size兩個域)
DWORD dwMicroSecPerFrame ; //显示每帧所需的时间ns,定义avi的显示速率
DWORD dwMaxBytesPerSec; //最大的数据传输率
DWORD dwPaddingGranularity; //记录块的长度需为此值的倍数,通常是2048
DWORD dwFlages; //AVI文件的特殊属性,如是否包含索引块,音视频数据是否交叉存储
DWORD dwTotalFrame; //文件中的总帧数
DWORD dwInitialFrames; //说明在开始播放前需要多少桢
DWORD dwStreams; //文件中包含的数据流个数
DWORD dwSuggestedBufferSize; //建议使用的缓冲区的大小,
//通常为存储一桢图像以及同步声音所需要的数据之和
DWORD dwWidth; //图像宽
DWORD dwHeight; //图像高
DWORD dwReserved[4]; //保留值
}MainAVIHeader;
strl结构块
“strl” LIST块用于记录AVI数据流,每一种数据流都在该LIST块中占有3个子块,他们的ID分别是”strh”,”strf”, “strd”;
1. 文件中有多少个流,这里就对应有多少个“strl”子列表。
2. 每个“strl”字列表至少包含一个“strh”块和一个“strf”块,
3. “strd”块(保存编解码器需要的一些配置信息)和“strn”块(保存流的名字)是可选的。
4. 注意:“strl”子列表出现的顺序与媒体流的编号是对应的,比如第一个“strl”字列表说明的是第一个流(Stream 0),第二个“strl”字列表说明的是第二个流(Stream 1),以此类推

| 十六进制数 | 描述 |
| 4C 49 53 54 | 表示“LIST”字符串 |
| 73 74 72 6C | 表示“strl”字符串 |
| 73 74 72 68 | 表示“strh”字符串 |
| 76 69 64 73 | 表示"vids”字符串,意思是该数据流为视频数据流 |
| 73 74 72 66 | 表示“strf”字符串 |
ID为“movi”的LIST块,包含AVI的音视频序列数据
用于保存真正的媒体流数据(视频图像帧数据或音频采样数据等)。保存方式为:
1. 将数据块直接嵌套在“movi”列表里面
2. 将几个数据块分组成一个“rec”列表后再编排进“movi”列表
(注意:在读取AVI文件内容时,建议将一个“rec”列表中的所有数据块一次性读出)
但是,当文件中包含有多个流的时候,数据块与数据块之间如何来区别呢?于是数据块使用了一个四字符吗来表征它的类型,这个四字符码由2个字节的类型吗和2个字节的流编号组成。
“db”——非压缩视频
“dc”——压缩视频
“pc”——改用新的调色板
“wb”——音缩视频比如:
第一个流(Stream 0)是音频,则表征音频数据块的四字符码为“00wb”;
第二个流(Steam 1)是视频,则表征视频数据块的四字符码为“01db”或“01dc”。
对于视频数据来说,在AVI数据序列中间还可以定义一个新的调色板,每个改变的调色板数据块永“xxpc”来表征,新的调色板使用一个数据结构AVIPALCHANGE来定义。(注意:如果一个流的调色板中途改变,则应在这个流格式的描述中,也及时AVISTREMAHEADER结构的dwFlags中包含一个AVISF_VIDEO_PALCHANGES标记)另外,文字数据块可以使用随意的类型码表征。
ID为“idxl”的子块,定义“movi”LIST块的索引数据,是可选块。
最后紧跟在“hdr”列表块和“movi”列表块之后的,就是AVI文件可选的索引块。这个索引块为AVI文件中每一个媒体数据块进行索引,并且记录它们在文件中的偏移(可能相对于“movi”列表,也可能相对于AVI文件开头)。索引块使用一个四字符码“idxl”来表征,索引信息使用一个数据结构AVIOLDINDEXl来定义。
索引块结构
typedef struct _avioldindex {
FOURCC fcc; // 必须为‘idx1’
DWORD cb; // 本数据结构的大小,不包括最初的8个字节(fcc和cb两个域)
struct _avioldindex_entry {
DWORD dwChunkId; // 表征本数据块的四字符码
DWORD dwFlags; // 说明本数据块是不是关键帧、是不是‘rec ’列表等信息
DWORD dwOffset; // 本数据块在文件中的偏移量
DWORD dwSize; // 本数据块的大小
} aIndex[]; // 这是一个数组!为每个媒体数据块都定义一个索引信息
} AVIOLDINDEX;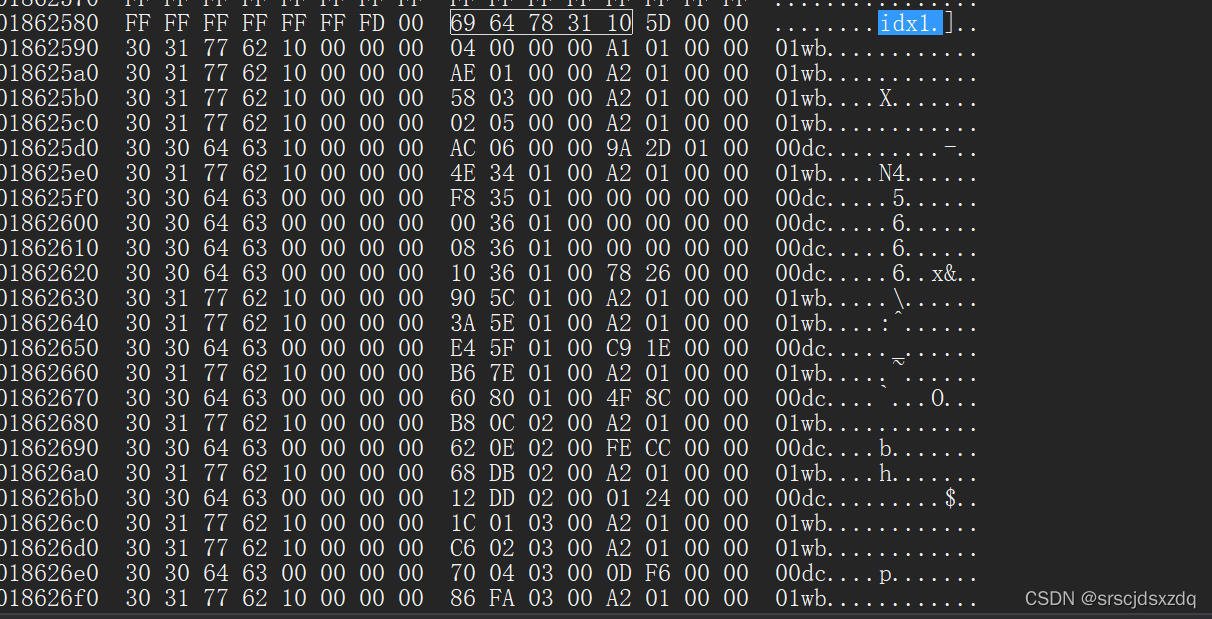
1.该AVI文件视音频交织放置
2.音频帧大约为“00 00 01 A2”418个字节;
视频帧大小有:”00 01 2D 9A“,”00 00 00 00“,”00 00 1E C9“......
可知视频帧大小各不相同。
avi格式说明参考原文链接:https://blog.csdn.net/chenyonken/article/details/79174500
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A