摘要
XGBoost算法(eXtreme Gradient Boosting)在目前的Kaggle、数学建模和大数据应用等竞赛中非常流行。本文将会从XGBOOST算法原理、Python实现、敏感性分析和实际应用进行详细说明。
目录
数据挖掘和数学建模等比赛中,除了算法的实现,还需要对数据进行较为合理的预处理,包括缺失值处理、异常值处理、定类数据特征编码和冗余特征的删除等等,本文默认读者的数据均已完成数据预处理,如有需要,后续会将数据预处理的方法也进行发布。
Python编译器:Pycharm社区版或个人版等
训练数据集:此处使用2022年数维杯国际大学生数学建模竞赛C题的附件数据为例。
数据处理:经过初步数据清洗和相关性分析等操作得到初步的特征,并利用决策树进行特征重要性分析,完成二次特征降维,得到'CDRSB_bl', 'PIB_bl', 'FBB_bl'三个自变量特征,DX_bl为分类特征。
XGBOOST算法基于决策树的集成方法,主要采用了Boosting的思想,是Gradient Boosting算法的扩展,并使用梯度提升技术来提高模型的准确性和泛化能力。
首先将基分类器层层叠加,然后每一层在训练的时候,对前一层基分类器分错的样本,给予更高的权重,XGBOOST的目标函数为:
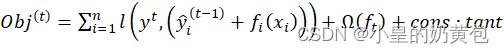
(1)
其中,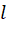 为损失函数;
为损失函数; 为正则项,用于控制树的复杂度;
为正则项,用于控制树的复杂度;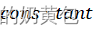 为常数项,
为常数项, 为新树的预测值
为新树的预测值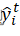 ,它是将树的个数的结果进行求和。
,它是将树的个数的结果进行求和。
此处导入本文所需数据,DataX为自变量数据,DataY为目标变量数据(DX_bl)。
import pandas as pd
X = pd.DataFrame(pd.read_excel('DataX.xlsx')).values # 输入特征
y = pd.DataFrame(pd.read_excel('DataY.xlsx')).values # 目标变量此处仅用0-4来代替五类数据,因为此处仅做预测,并不涉及相关性分析等其他操作,所以普通的分类编码就可以。如果需要用来做相关性分析或其他计算型操作,建议使用独热编码(OneHot- Encoding)。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
label_mapping = {0: 'AD', 1: 'CN', 2: 'EMCI', 3: 'LMCI', 4: 'SMC'}
#此处为了后续输出混淆矩阵时,用原始数据输出本文将原始样本数据通过随机洗牌,并将70%的样本数据作为训练数据,30%的样本数据作为测试数据。这是一个较为常见的拆分方法,读者可通过不同的拆分测试最佳准确率和F1-score。
from sklearn.model_selection import train_test_split
# 将数据分为训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, train_size=0.7, random_state=42)基于70%的样本数据进行训练建模,python有XGBOOST算法的库,所以很方便就可以调用。
import xgboost as xgb
# 训练XGBoost分类器
model = xgb.XGBClassifier()
model.fit(X_train, y_train)
#xgb.plot_tree(model)利用另外的30%样本数据进行测试模型准确率、精确率、召回率和F1度量值。
# 使用测试数据预测类别
y_pred = model.predict(X_test)此处输出混淆矩阵的方法和之前的随机森林、KNN算法都有点不同,因为随机森拉算法不需要将定类数据进行分类编码就可以直接调用随机森林算法模型。
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
cm = confusion_matrix(y_test, y_pred)
# 输出混淆矩阵
for i, true_label in enumerate(label_mapping.values()):
row = ''
for j, pred_label in enumerate(label_mapping.values()):
row += f'{cm[i, j]} ({pred_label})\t'
print(f'{row} | {true_label}')
# 输出混淆矩阵
print(classification_report(y_test, y_pred,target_names=['AD', 'CN', 'EMCI', 'LMCI', 'SMC'])) # 输出混淆矩阵#此处的导库在上一个代码段中已引入
print("Accuracy:")
print(accuracy_score(y_test, y_pred))将混淆矩阵结果图绘制并输出,可以将这一结果图放在论文中,提升论文美感和信服度。
import matplotlib.pyplot as plt
import numpy as np
label_names = ['AD', 'CN', 'EMCI', 'LMCI', 'SMC']
cm = confusion_matrix(y_test, y_pred)
# 绘制混淆矩阵图
fig, ax = plt.subplots()
im = ax.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
ax.figure.colorbar(im, ax=ax)
ax.set(xticks=np.arange(cm.shape[1]),
yticks=np.arange(cm.shape[0]),
xticklabels=label_names, yticklabels=label_names,
title='Confusion matrix',
ylabel='True label',
xlabel='Predicted label')
# 在矩阵图中显示数字标签
thresh = cm.max() / 2.
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(j, i, format(cm[i, j], 'd'),
ha="center", va="center",
color="white" if cm[i, j] > thresh else "black")
fig.tight_layout()
#plt.show()
plt.savefig('XGBoost_Conclusion.png', dpi=300)上面的代码首先计算混淆矩阵,然后使用 matplotlib 库中的 imshow 函数将混淆矩阵可视化,最后通过 text 函数在混淆矩阵上添加数字,并使用 show/savefig 函数显示图像,结果输出如图3.1所示。

图3.1 混淆矩阵结果图
# 导入需要的库
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
import numpy as np
le = LabelEncoder()
label_mapping = {0: 'AD', 1: 'CN', 2: 'EMCI', 3: 'LMCI', 4: 'SMC'}
X = pd.DataFrame(pd.read_excel('DataX.xlsx')).values # 输入特征
y = pd.DataFrame(pd.read_excel('DataY.xlsx')).values # 目标变量
y = le.fit_transform(y)
# 将数据分为训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, train_size=0.7, random_state=42)
# 训练XGBoost分类器
model = xgb.XGBClassifier()
model.fit(X_train, y_train)
#xgb.plot_tree(model)
# 使用测试数据预测类别
y_pred = model.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
# 输出混淆矩阵
for i, true_label in enumerate(label_mapping.values()):
row = ''
for j, pred_label in enumerate(label_mapping.values()):
row += f'{cm[i, j]} ({pred_label})\t'
print(f'{row} | {true_label}')
# 输出混淆矩阵
print(classification_report(y_test, y_pred,target_names=['AD', 'CN', 'EMCI', 'LMCI', 'SMC'])) # 输出混淆矩阵
print("Accuracy:")
print(accuracy_score(y_test, y_pred))
# label_names 是分类变量的取值名称列表
label_names = ['AD', 'CN', 'EMCI', 'LMCI', 'SMC']
cm = confusion_matrix(y_test, y_pred)
# 绘制混淆矩阵图
fig, ax = plt.subplots()
im = ax.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
ax.figure.colorbar(im, ax=ax)
ax.set(xticks=np.arange(cm.shape[1]),
yticks=np.arange(cm.shape[0]),
xticklabels=label_names, yticklabels=label_names,
title='Confusion matrix',
ylabel='True label',
xlabel='Predicted label')
# 在矩阵图中显示数字标签
thresh = cm.max() / 2.
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(j, i, format(cm[i, j], 'd'),
ha="center", va="center",
color="white" if cm[i, j] > thresh else "black")
fig.tight_layout()
#plt.show()
plt.savefig('XGBoost_Conclusion.png', dpi=300)
# 上面的代码首先计算混淆矩阵,然后使用 matplotlib 库中的 imshow 函数将混淆矩阵可视化,最后通过 text 函数在混淆矩阵上添加数字,并使用 show/savefig 函数显示图像。 
图3.2 结果输出示例
敏感性分析也叫做稳定性分析,可以基于统计学思想,通过百次测试,记录其准确率、精确率、召回率和F1-Score的数据,统计其中位数、平均值、最大值和最小值等数据,从而进行对应的敏感性分析。结果表明符合原模型成立,则通过了敏感性分析。前面的随机森林算法和KNN算法也是如此。
XGBOOST算法可应用于大数据分析、预测等方面,尤其是大数据竞赛(Kaggle、阿里天池等竞赛中)特别常用,也是本人目前认为最好用的一个算法。
本文基于XGBOOST算法,从数据预处理、算法原理、算法实现、敏感性分析和算法应用都做了具体的分析,可适用于大部分机器学习算法初学者。
本文为原创文章,禁止转载,违者必究。如需原始数据,可点赞+收藏,然后私聊作者或在评论区中留下你的邮箱,即可获得训练数据一份。
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO