JVM系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】初识虚拟机与java虚拟机 | https://blog.csdn.net/zhenghuishengq/article/details/129544460 |
| 【二】jvm的类加载子系统以及jclasslib的基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/129610963 |
| 【三】运行时私有区域之虚拟机栈、程序计数器、本地方法栈 | https://blog.csdn.net/zhenghuishengq/article/details/129684076 |
| 【四】运行时数据区共享区域之堆、逃逸分析 | https://blog.csdn.net/zhenghuishengq/article/details/129796509 |
| 【五】运行时数据区共享区域之方法区、常量池 | https://blog.csdn.net/zhenghuishengq/article/details/129958466 |
| 【六】对象实例化、内存布局和访问定位 | https://blog.csdn.net/zhenghuishengq/article/details/130057210 |
对象实例化、内存布局和访问定位
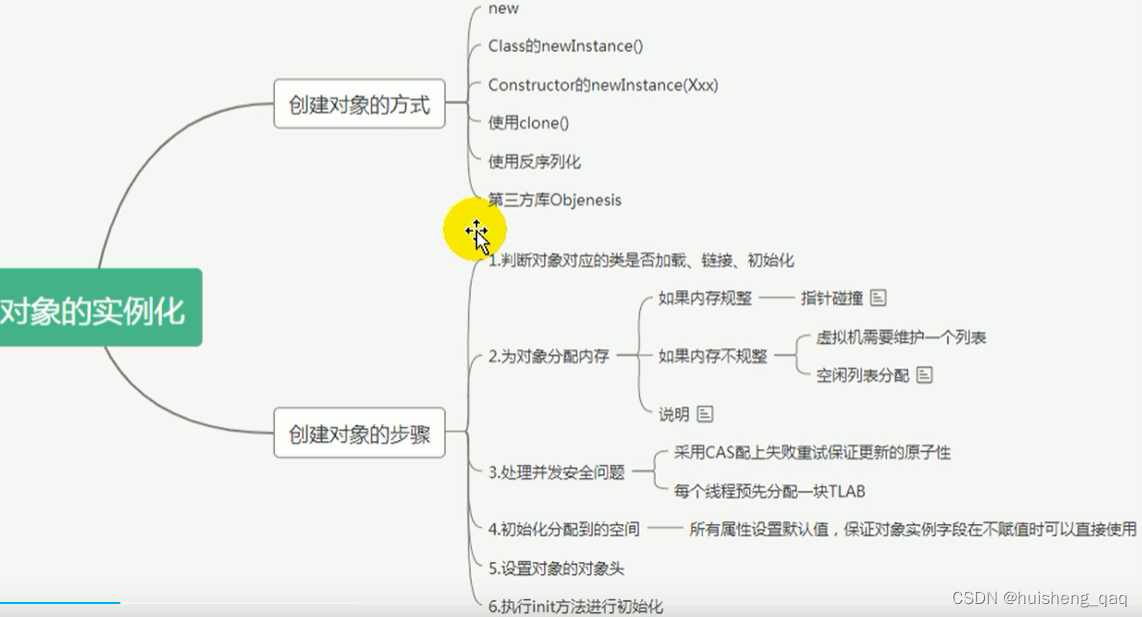
创建对象的方式和创建对象的步骤主要有以下几种方式
在日常开发中,创建对象的方式主要有以下几种:
//new 构造器 创建对象
Object object = new Object();
//构造器静态私有,如典型的单例模式
Object object = Object.getObject();
//工厂加载,SpringBean,SqlSessionBean
Object object = ObjectFactory.getObject();
public class Invoke {
public static void main(String[] args) {
try {
Class<?> clazz1 = Class.forName("com.tky.jvm.Invoke");
//通过类构造器获取对象
Constructor<?> constructor = clazz1.getConstructor();
Invoke invoke1 = (Invoke)constructor.newInstance();
//通过类名获取
Class<Invoke> clazz2 = Invoke.class;
Invoke invoke2 = clazz2.newInstance();
//通过对象获取
Invoke in = new Invoke();
Class<? extends Invoke> clazz3 = in.getClass();
Invoke invoke3 = clazz3.newInstance();
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
* @author zhenghuisheng
* @date : 2023/4/10
*/
@Data
public class Clone implements Cloneable {
private Long id;
private String username;
private String password;
@Override
protected Clone clone() throws CloneNotSupportedException {
return (Clone)super.clone();
}
}
class TestClone{
public static void main(String[] args) {
Clone clone1 = new Clone();
clone1.setId(1L);
clone1.setUsername("zhenghuisheng");
clone1.setUsername("123456");
try {
Clone clone2 = clone1.clone();
System.out.println(clone2.getId());
} catch (Exception e) {
e.printStackTrace();
}
}
}
//对象序列化
Student s = new Student("1","zhenghuisheng","18");
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("d:/a.txt"));
objectOutputStream.writeObject(s);
objectOutputStream.close();
//对象反序列化
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("d:/a.txt"));
Student student = (Student) inputStream.readObject();
//构建 Objenesis 对象 Objenesis需要对应的pom依赖对象
Objenesis objenesis = new ObjenesisStd();
ObjectInstantiator<Student> instantiator = objenesis.getInstantiatorOf(Student.class);
Student student = instantiator.newInstance();
这里主要从执行的角度来分析这个对象创建的步骤,如上图所示,主要分为六个步骤来创建对象

虚拟机在遇到一条new指令的时候,首先会去检查这个指令的参数是否能在元空间的常量池中定位到一个类的符号,并且检查这个类是否经历过了加载、验证、准备、解析和初始化这个几个步骤。如果没有,那么类加载器还在双亲委派的模式下,使用当前类加载器的以 ClassLoader + package + class 为key进行查找对应的.class文件,如果没有找到对应的文件,则会抛出 ClassNotFoundException 异常,如果找到,则进行类加载,并生成对应的Class对象
首先需要计算对象占用空间的大小,接着在堆中划分一块内存给新对象,如果实例成员变量时引用变量,那么仅分配引用变量空间即可,即四个字节大小。如根据不同的基本数据类型其所占用的字节数,从而得知每个变量占多大的空间,最后将这些变量所需要的空间全部叠加在一起,得到的就是这个总空间的字节数。
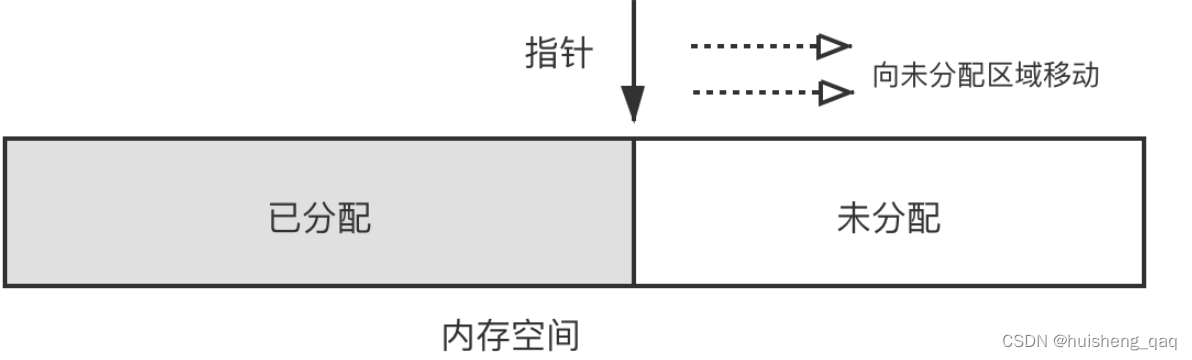
而内存如果是规整的,那么虚拟机将采用的是 指针碰撞 的方式来为对象分配内存。如下图,就是将用过的内存放在一边,空闲的内存放在另外一边,中间放着一个分界点的指示器,内存分配就是将指针向空闲那边挪动,挪动的距离就是对象所需要的大小 ,而指针碰撞这种方式,取决于虚拟机的垃圾回收算法是否具有压缩功能。
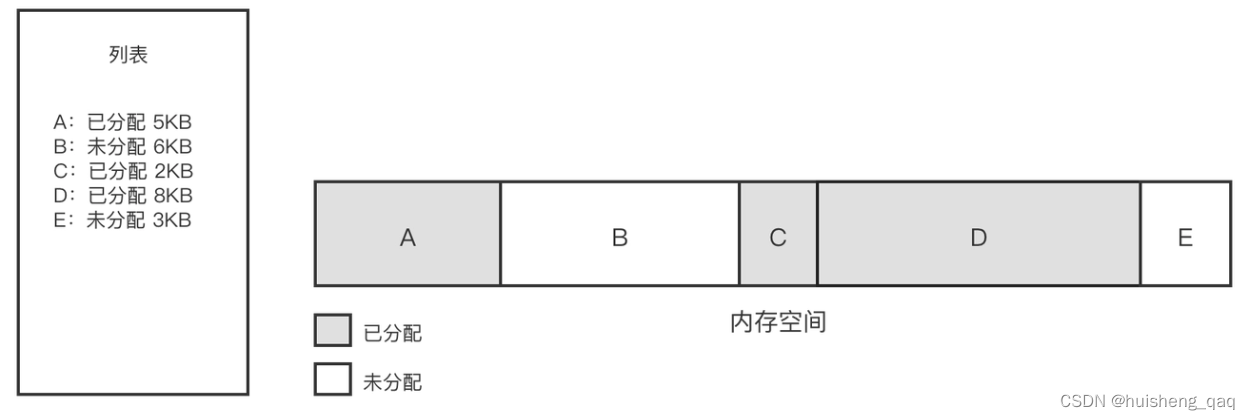
如果内存内部不是规整的,虚拟机内部就得维护一个列表来管理已使用的内存和未使用的内存,其方式被称为 空闲列表 。如下图,虚拟机内部维护了一张表,记录的是哪块内存时可用的,哪块内存时不可用的,然后在分配的时候,就从列表中找到一块足够打的空间划分给对象实例,并更新表上的内容。
由于对象是在堆中创建,而堆又是共享区域,因此避免不了会出现这个并发的问题,而在堆内部,主要采用了两种方式来保证实例的安全性。
一种是采用CAS比较与交换的方式,失败则重试,区域加锁来保证更新的原子性,另一种是 每个线程预先分配一个 TLAB。主要是通过这两种方式来解决并发安全的问题。
这里进行一个默认的初始化。这样所有属性都有一个默认值,保证对象实例字段在不赋值时就可以使用。因此在方法内部,静态变量在准备阶段就进行了初始赋值,实例变量在分配空间的时候也进行了初始赋值,因此这两个可以直接使用变量,其他的变量如果没有进行显示的初始化,那么会出现直接编译失败的情况。
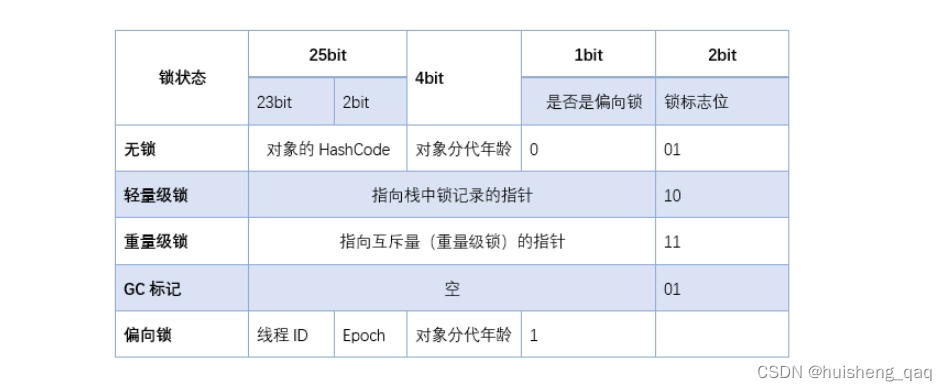
将对象所属的类、对象的hashCode、GC信息、年龄、锁信息等存储在对象的对象头中。
这里就行一个显示初始化,初始化工作才正式开始。初始化成员变量,执行实例化代码块,调用类的构造方法,并把堆对象的首地址赋值给引用对象。因此一般来说,new 指令之后会接着就是执行方法,将对象按照程序员的意愿进行初始化,这样真正可用的对象才算完整的创建出来。
对象的内存布局中,主要包括对象头、实例数据和对其填充
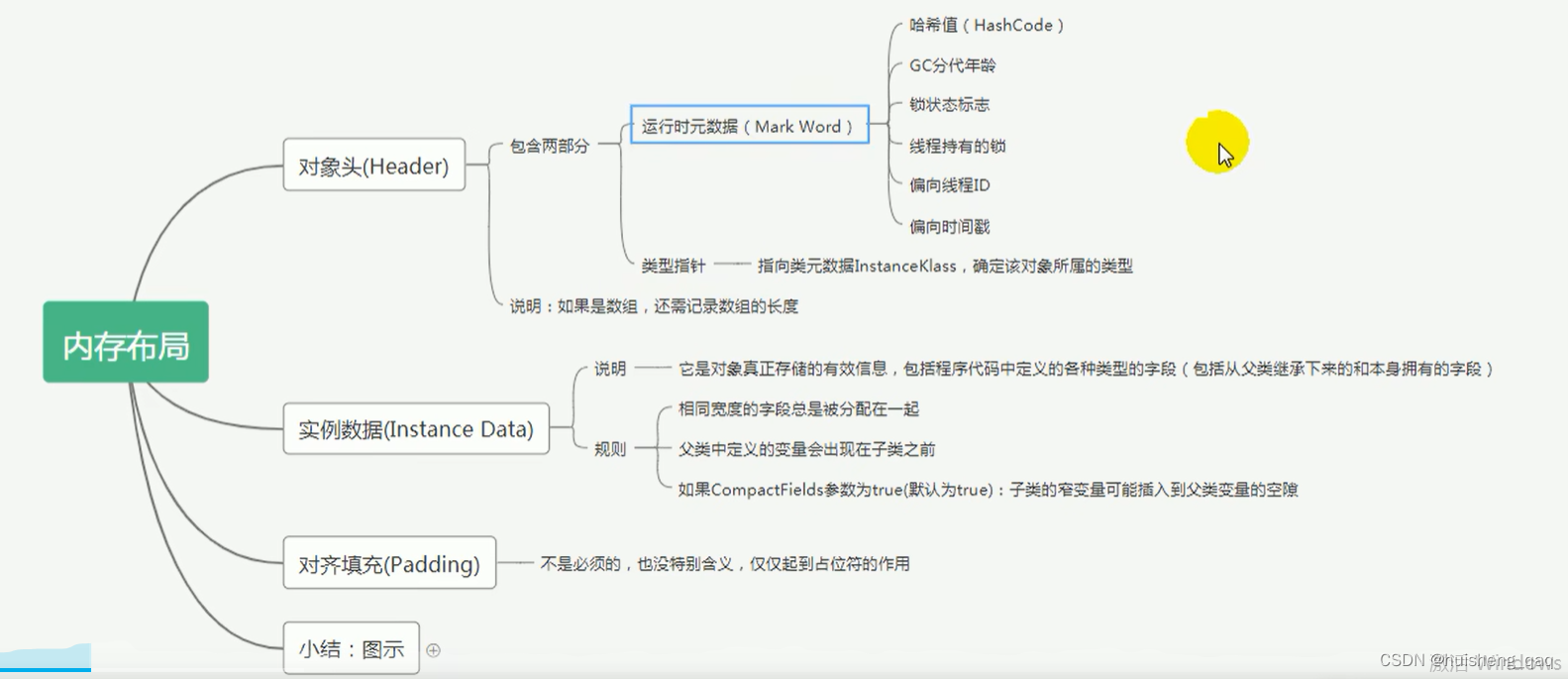
在对象头中,又可以分为两部分,一部分是运行时的元数据,另一部分就是类型指针。
运行时元数据包括哈希码、GC年龄分代、线程持有的锁、持有锁标志、线程id、线程时间戳。
由下图可知,在对象的年龄分代为4bit,因此最大为1111,即15,又由于是从0开始,因此其最大年龄为15,所以在设置这个年龄的时候,只能往小设置。锁的标志位对应的字节码用01、10、11表示,其值分别对应着1、2、3,并且这段锁升级的过程是不可逆的。
而类型指针指向的是元数据InstanceKlass,确定该对象所属的类型。如果是数组,还需要记录数组的长度
对象真正存储的有效信息,包括代码中定义的各种类型的字段,以及父类继承下来的和本身拥有的字段 。并且在这些对象中,父类定义的变量会出现在子类之前,并且相同的字段总是会被分配在一起,如果CompactFields参数为true,子类的窄变量可能插入到父类变量的空隙。
接下来分析一下以下这段代码
/**
* @author zhenghuisheng
* @date : 2023/4/7
*/
public class Customer {
Integer id = 1001;
String name = "zhenghuisheng";
public Customer(){
Account account = new Account();
}
}
public class Test{
public static void main(String[] args){
Customer cust = new Customer();
}
}
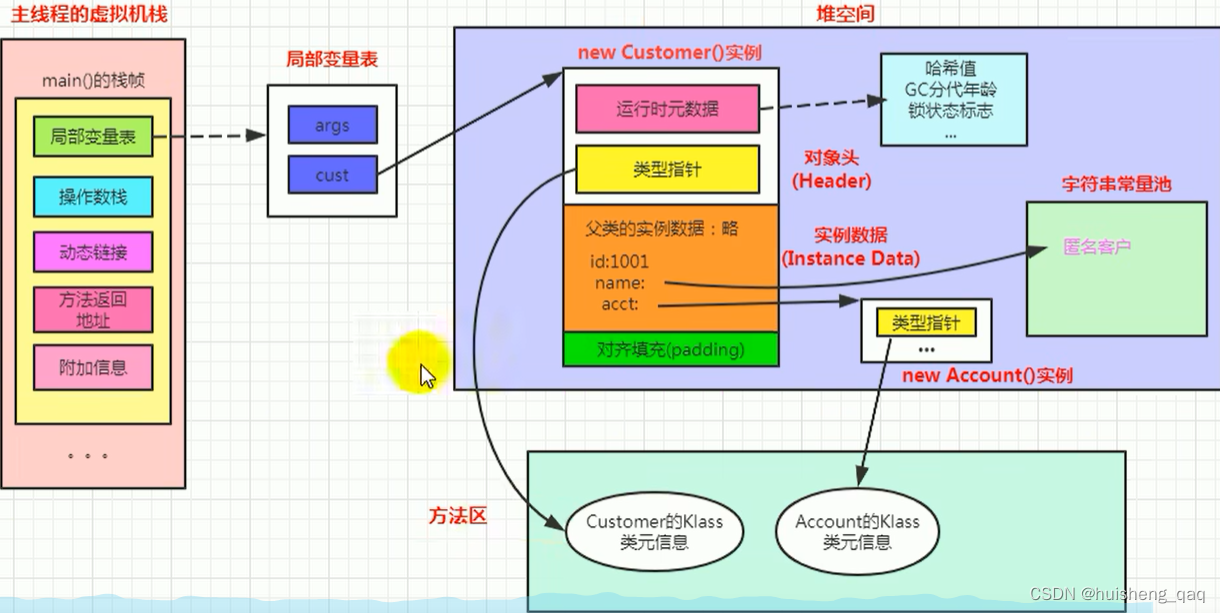
然后其对应的内存结构如下图所示,在这个main方法中,由于是静态方法,因此局部变量表的第一个slot不是this,而局部变量表中的第二个cust是引用着堆中 new Customer()的实例地址,该实例对象中,主要就是上面的运行时元数据、类型指针、对其填充等组成。运行时数据区就包括唯一地址哈希值、结果多次GC后的年龄、是否获得锁等标志;类型指针对应的就是Customer的Klass类元信息;实例数据就包括自身的属性以及父类属性
创建对象主要是为了更好的去使用他,JVM内部主要是通过两种方式实现对象引用访问到内部对象的,一种是直接指针,一种是句柄访问。
如下代码所示,一个创建对象需要涉及到堆,栈和方法区,因此对象的定位以及访问也需要设计这三个地方
//第一个User存在方法区,主要是存储类信息和运行时常量池
//第二个user在栈中,作为变量存储
//最后的 new User存储在堆中
User user = new User();
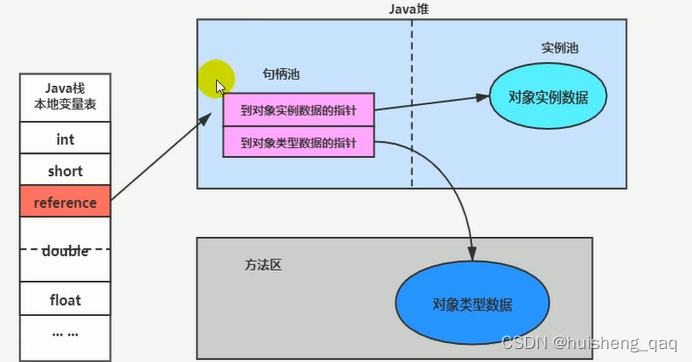
句柄访问 的方式如下,在Java堆中有一个句柄池,然后句柄池中保存指向堆中的实例的地址和指向方法区中保存类信息的地址,而在栈中只需保存句柄池的地址即可。
直接指针 就是不需要使用句柄池,在栈的局部变量表中直接保存堆中实例的地址,而在堆中会有一个指针去指向方法区中保留类信息的地址。在Hotspot虚拟机中,主要采用的是这种方式
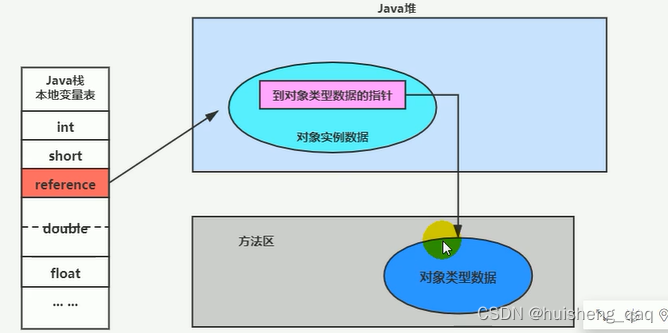
句柄指针需要在堆空间中开辟空间存储句柄池,因此会有一定的空间浪费,并且效率相对较低,但是如果出现对象的位置发生改变,如出现垃圾回收的情况,或者使用标记整理算法的时候 ,这个栈中指向堆中的句柄池的指针可以不用发生改变,只需改变句柄池只向实例数据和方法区的指针。而这个直接指针的优缺点就是就和句柄指针相反。
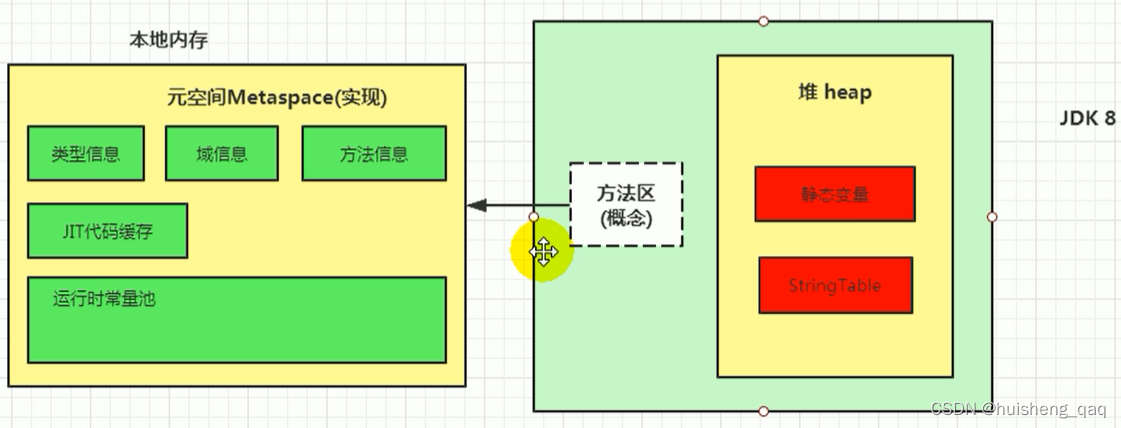
在JDK8中,方法区的具体实现从永久代变成了元空间,而元空间使用的是本地内存,又名直接内存,这部分不属于运行时数据区的一部分,也不是《java虚拟机规范》中定义的内存区域
在java代码中,可以直接通过这个 ByteBuffer.allocateDirect() 来进行本地内存空间的分配, 即直接通过这个NIO来进行操作,并且在通常直接内存的速度会直接优于Java堆,其读写性能相对较高。因此处于性能考虑,读写频繁的场合可以使用直接内存,并且Java的NIO库,也允许Java程序使用直接内存。
也可能会出现 OutOfMemoryError 异常,由于直接内存在Java堆之外,因此其大小不会受限于 -Xmx 指定的最大堆大小,但又由于系统的内存始终是有限的,因此堆和直接内存的总和依然受限于操作系统给出的最大内存,但是在直接内存中,也存在一定的缺点:分配回收成本较高,并且不受JVM内存回收管理。
因此可以直接内存可以通过 MaxDirectMemorySize 进行大小的设置,如果未指定,那么默认和堆的最大值 -Xmx 参数值一致
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(100 * 1024);
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
我正在查看instance_variable_set的文档并看到给出的示例代码是这样做的:obj.instance_variable_set(:@instnc_var,"valuefortheinstancevariable")然后允许您在类的任何实例方法中以@instnc_var的形式访问该变量。我想知道为什么在@instnc_var之前需要一个冒号:。冒号有什么作用? 最佳答案 我的第一直觉是告诉你不要使用instance_variable_set除非你真的知道你用它做什么。它本质上是一种元编程工具或绕过实例变量可见性的黑客攻击
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象