layout: post
title: 深度学习环境搭建
subtitle: 深度学习环境搭建
date: 2021-04-25
author: Yin
header-img: img/post-bg-cook.jpg
catalog: true
tags:
- 深度学习
到官网下载Ubuntu18.04LTS版本。 {width="5.833333333333333in"
{width="5.833333333333333in"
height="3.948611111111111in"}
1)安装制作工具:UltraISO(点我下载),下载完成后安装
2)插入用来做启动盘的U盘(最好是usb3.0接口,16GB或以上),并清空里面的文件
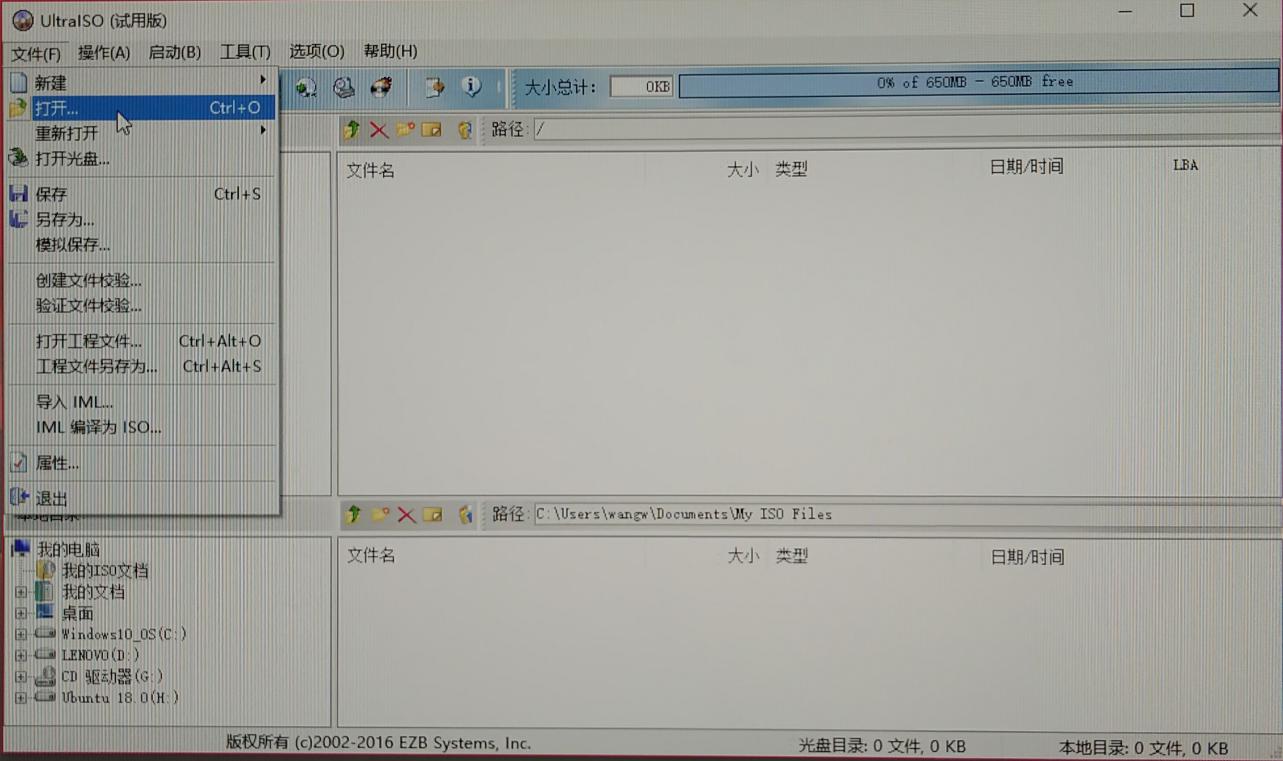
3)打开安装好的UltraISO,点击继续试用按钮工作界面
4)进入工作界面后,点击菜单栏文件(F),在弹出的选项卡里点击打开
 {width="5.833333333333333in"
{width="5.833333333333333in"
height="3.459722222222222in"}
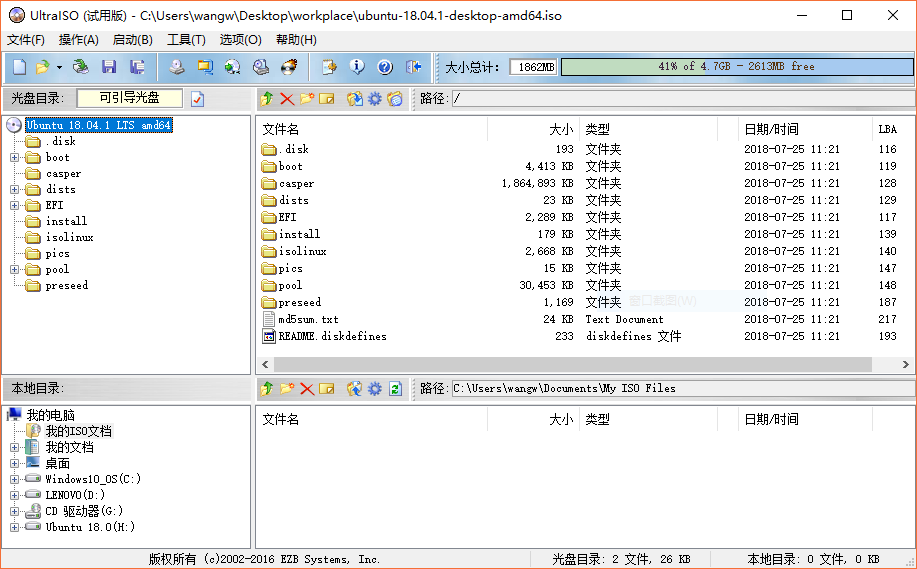
5)在弹出的文件选择对话框中找到下载好的 Ubuntu18.04.1 LTS
镜像文件,打开后如下图所示:
 {width="5.833333333333333in"
{width="5.833333333333333in"
height="3.6194444444444445in"}
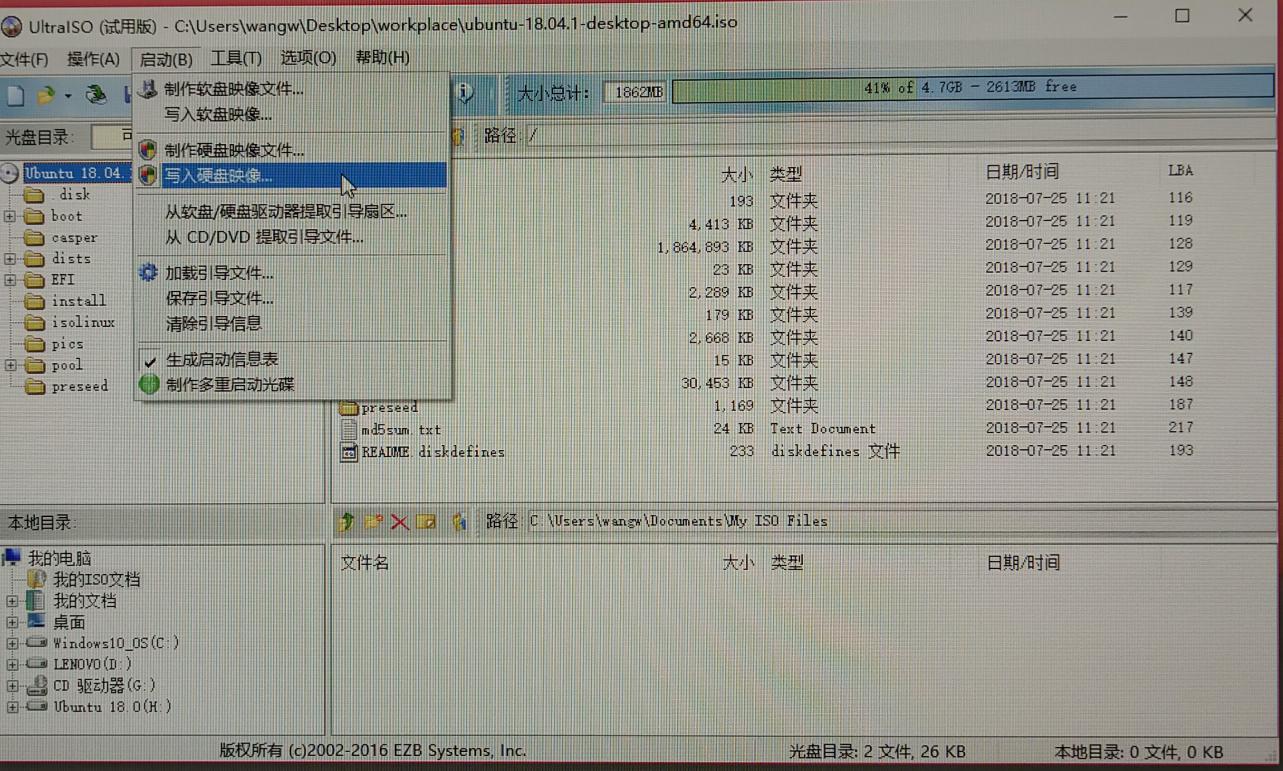
6)点击菜单栏上的启动,在弹出的选项卡里点击写入硬盘映像
 {width="5.833333333333333in"
{width="5.833333333333333in"
height="3.50625in"}
7)在弹出的新窗口中, 硬盘驱动器:选择刚刚插入的U盘
写入方式:设置为USB-HDD+ 其余需要勾选的不管,采用默认的设置就行
然后可以格式化一下 最后点击最下面一栏的写入按钮
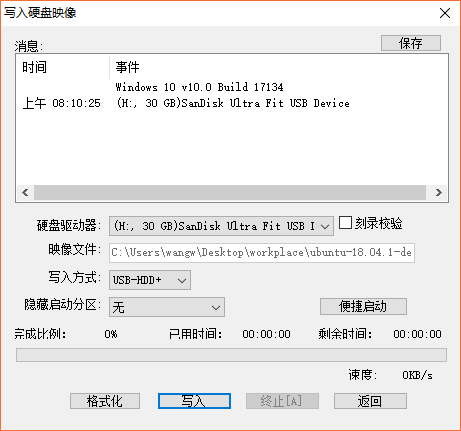 {width="4.852083333333334in"
{width="4.852083333333334in"
height="4.5368055555555555in"}
8)写入过程大概会持续4~5分钟,完成后界面如下图所示,接着点击返回按钮。
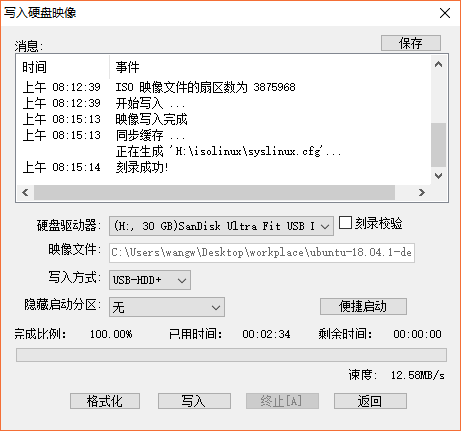 {width="4.852083333333334in"
{width="4.852083333333334in"
height="4.5368055555555555in"}
至此,启动盘制作完成。
关闭要安装 Ubuntu18.04 的目标主机,然后插入启动盘,接着开机,迅速的按住
F12直到进入 bios 设置界面(不同的电脑进入 bios 的按键不同,一般为
F12 或者 Delete 键),通过方向键选择Boot Menu,然后回车
进入Boot Manager后,选择 EFI USB 作为启动项,回车
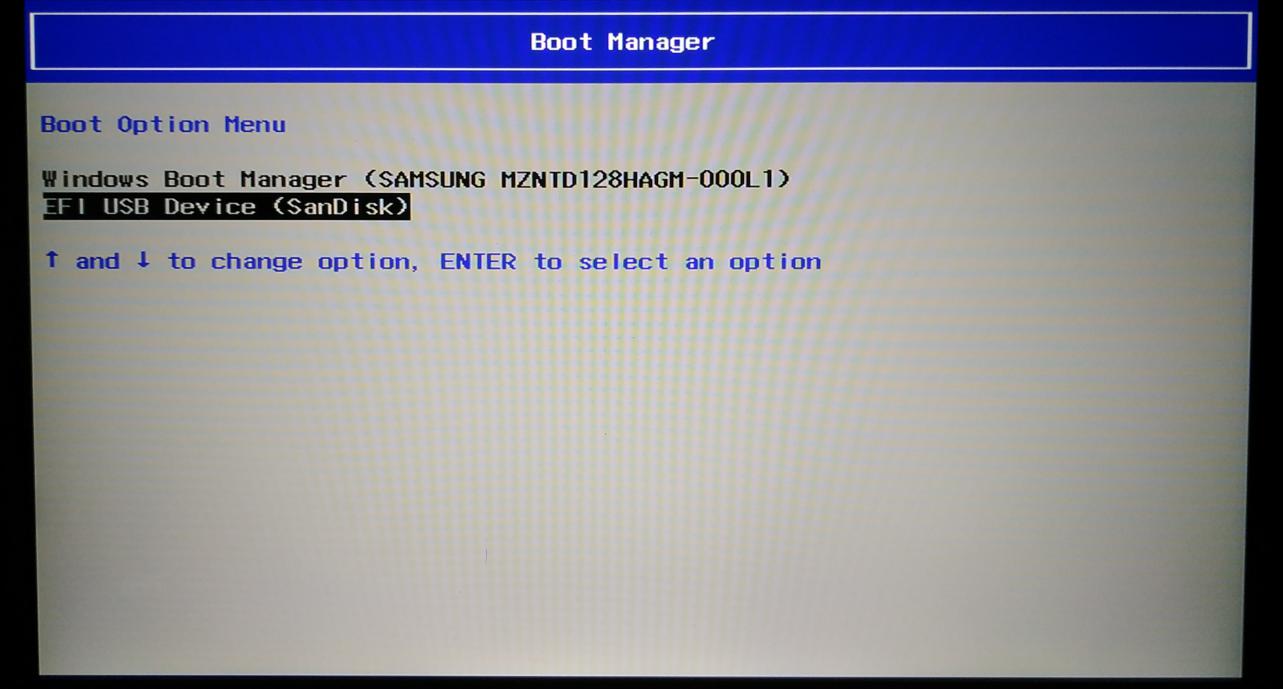 {width="5.833333333333333in"
{width="5.833333333333333in"
height="3.134027777777778in"}
选择 Install Ubuntu, 回车直接安装
选者中文简体
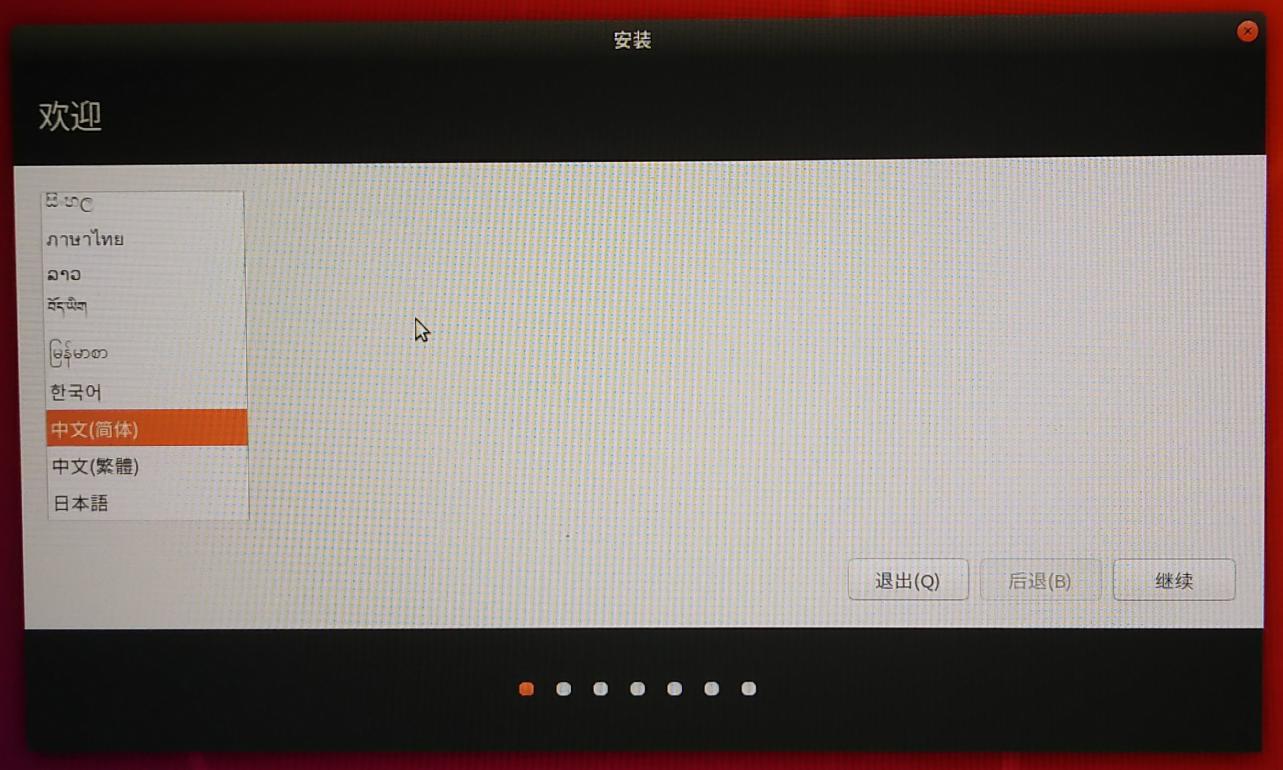 {width="5.833333333333333in"
{width="5.833333333333333in"
height="3.4993055555555554in"}
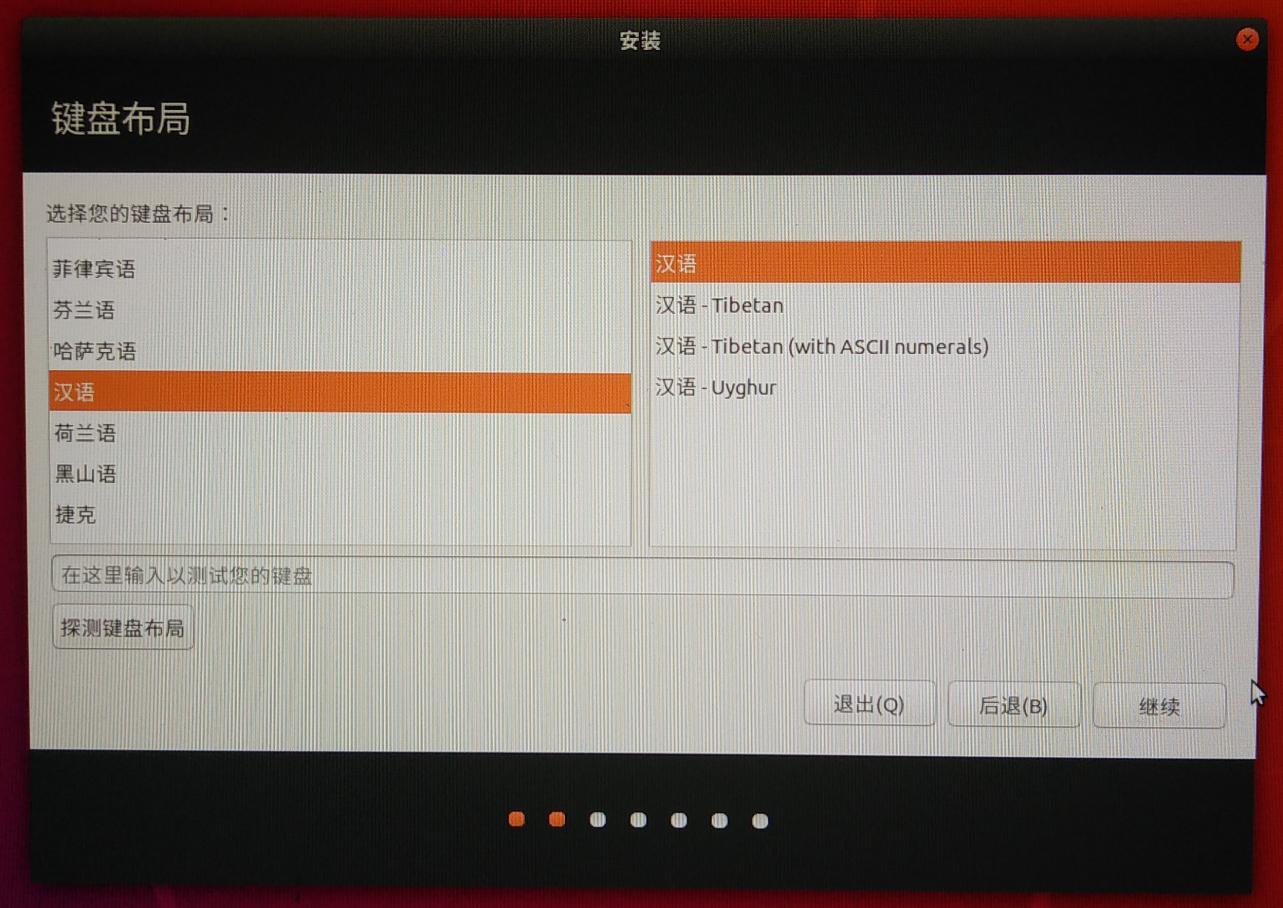
键盘布局
 {width="5.833333333333333in"
{width="5.833333333333333in"
height="4.129166666666666in"}
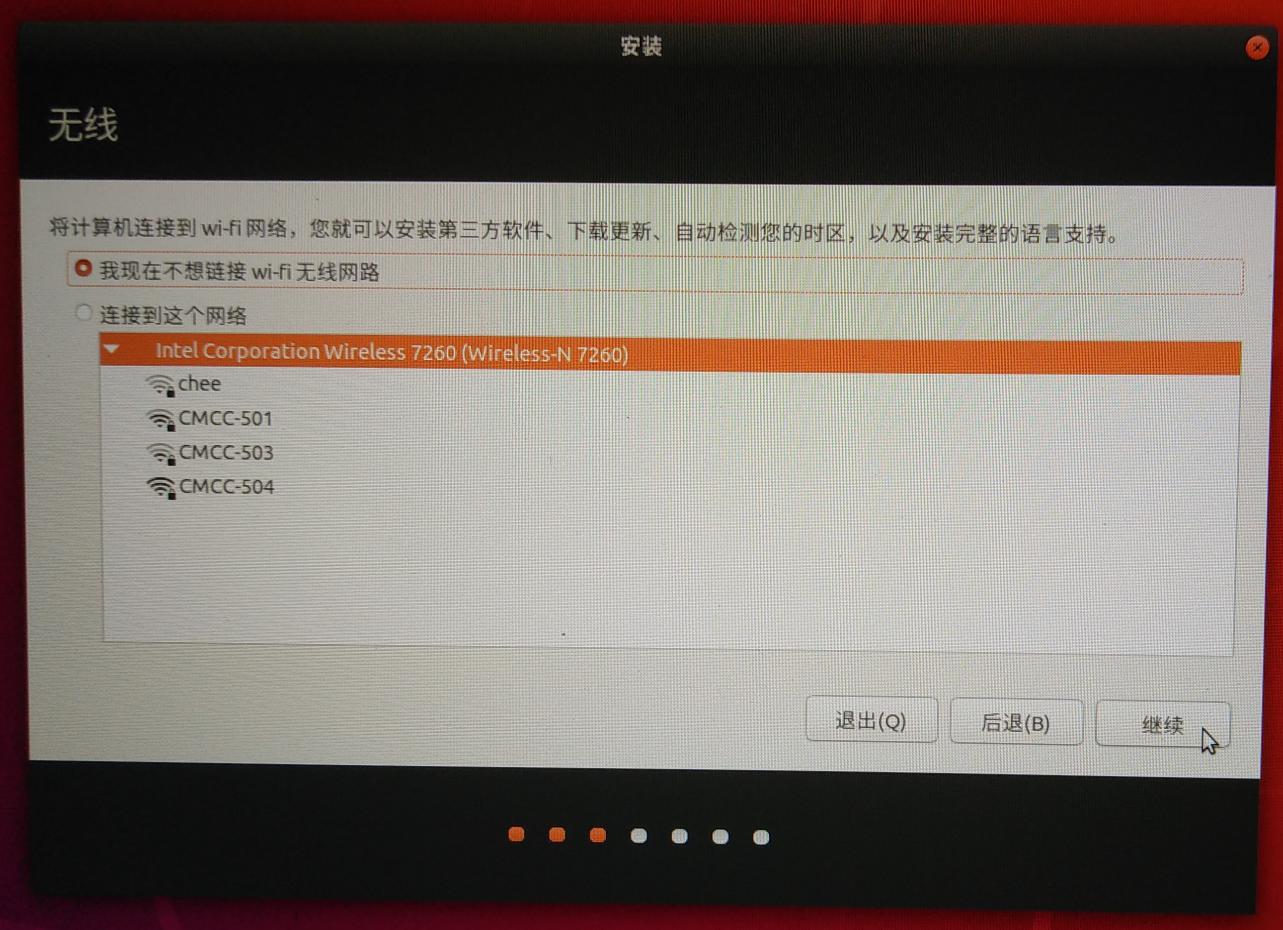
不要无线联网(否则安装会很慢)
 {width="5.833333333333333in"
{width="5.833333333333333in"
height="4.227777777777778in"}
更新选项最小安装即可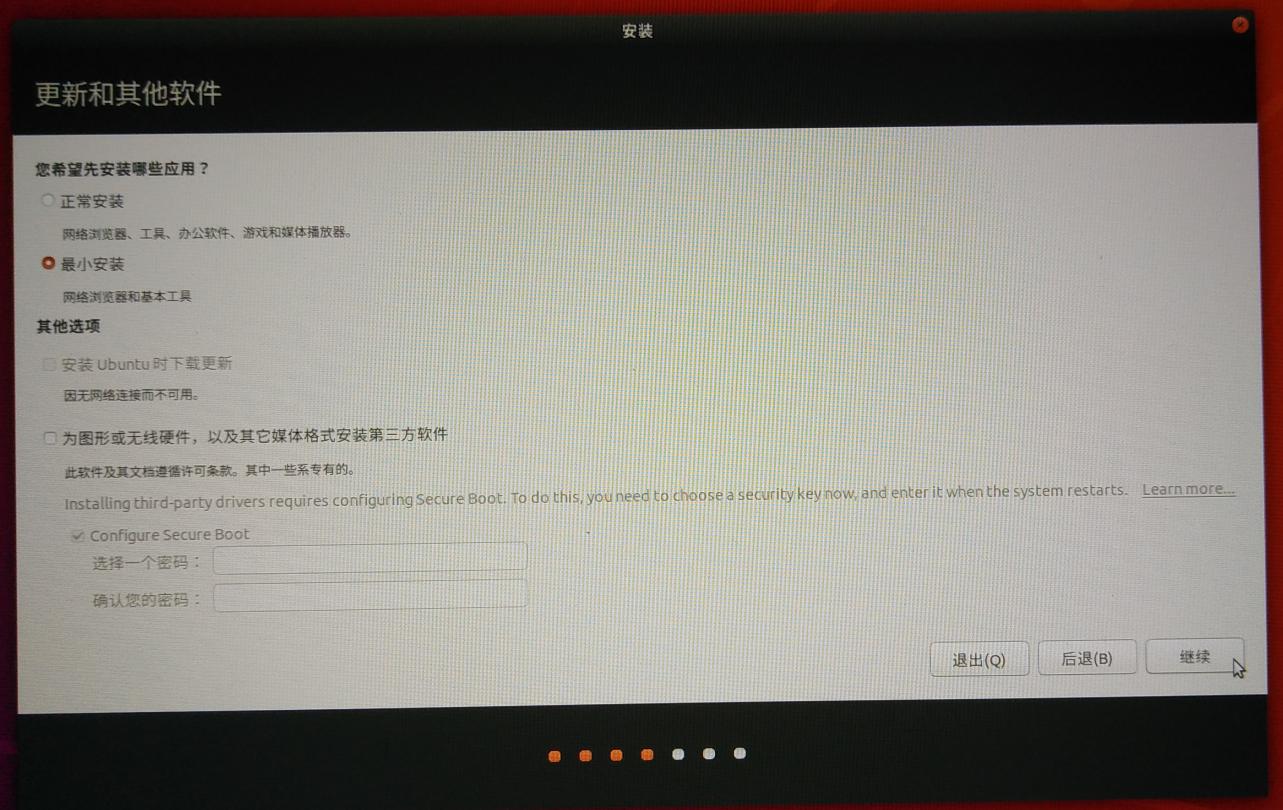 {width="5.833333333333333in"
{width="5.833333333333333in"
height="3.682638888888889in"}
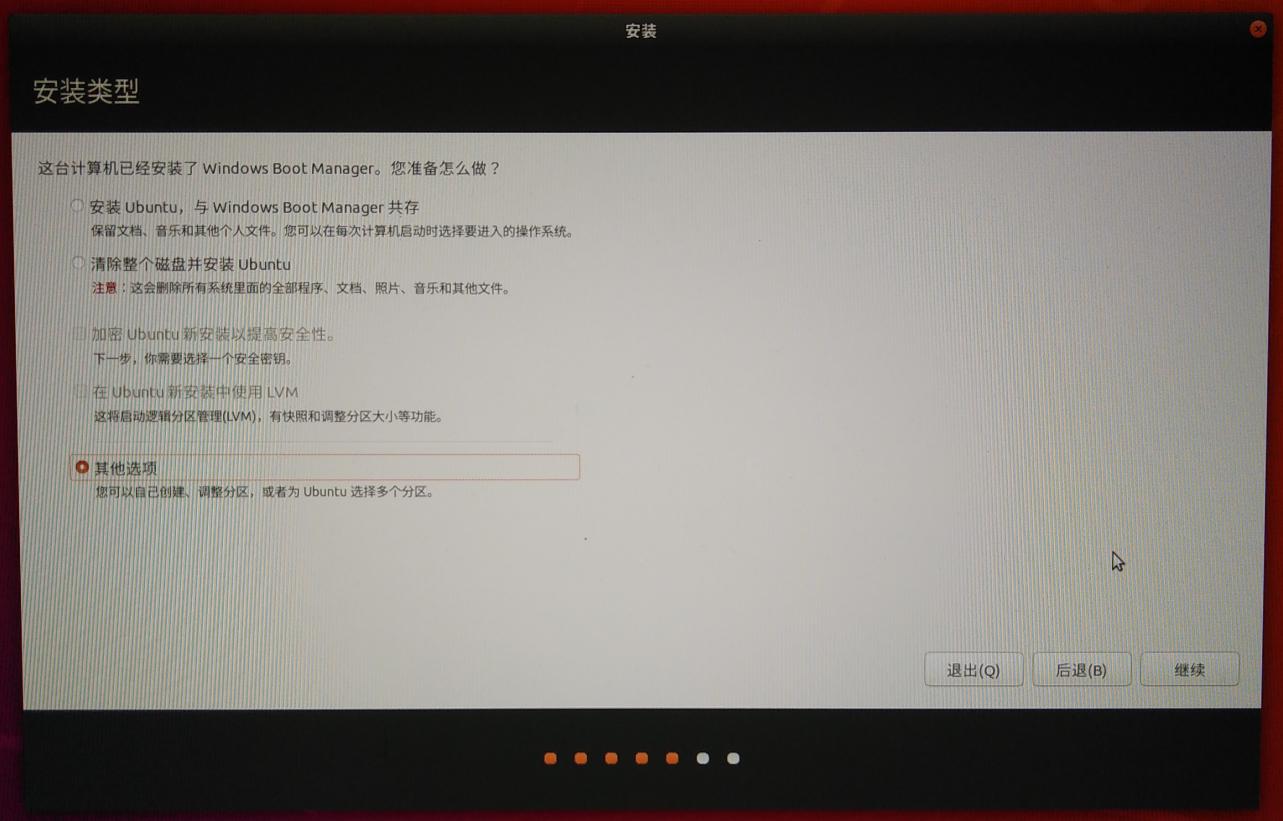
选择安装类型,选择清楚整个磁盘并安装
 {width="5.833333333333333in"
{width="5.833333333333333in"
height="3.734027777777778in"}
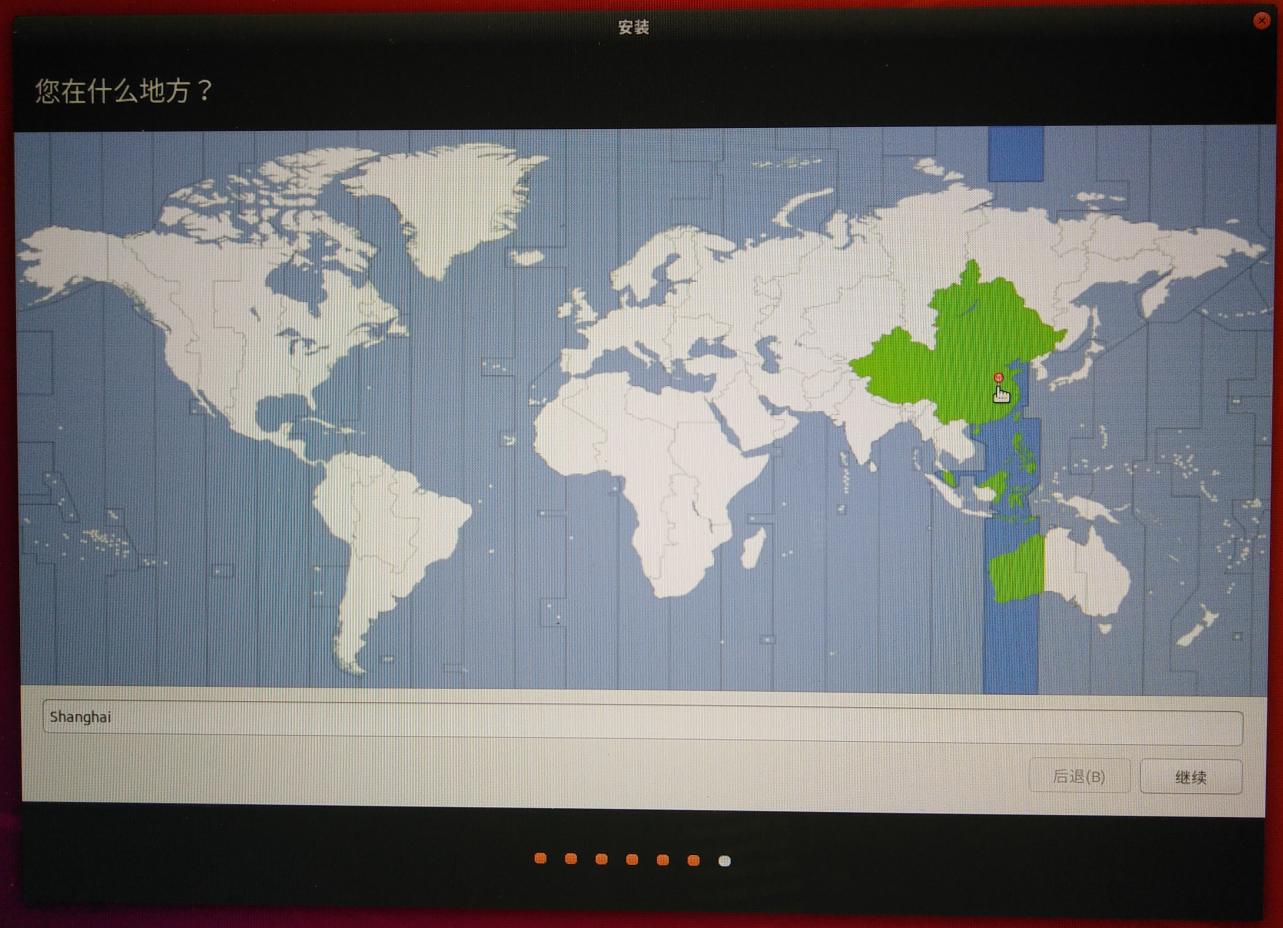
选择时区、上海
 {width="5.833333333333333in"
{width="5.833333333333333in"
height="4.21875in"}
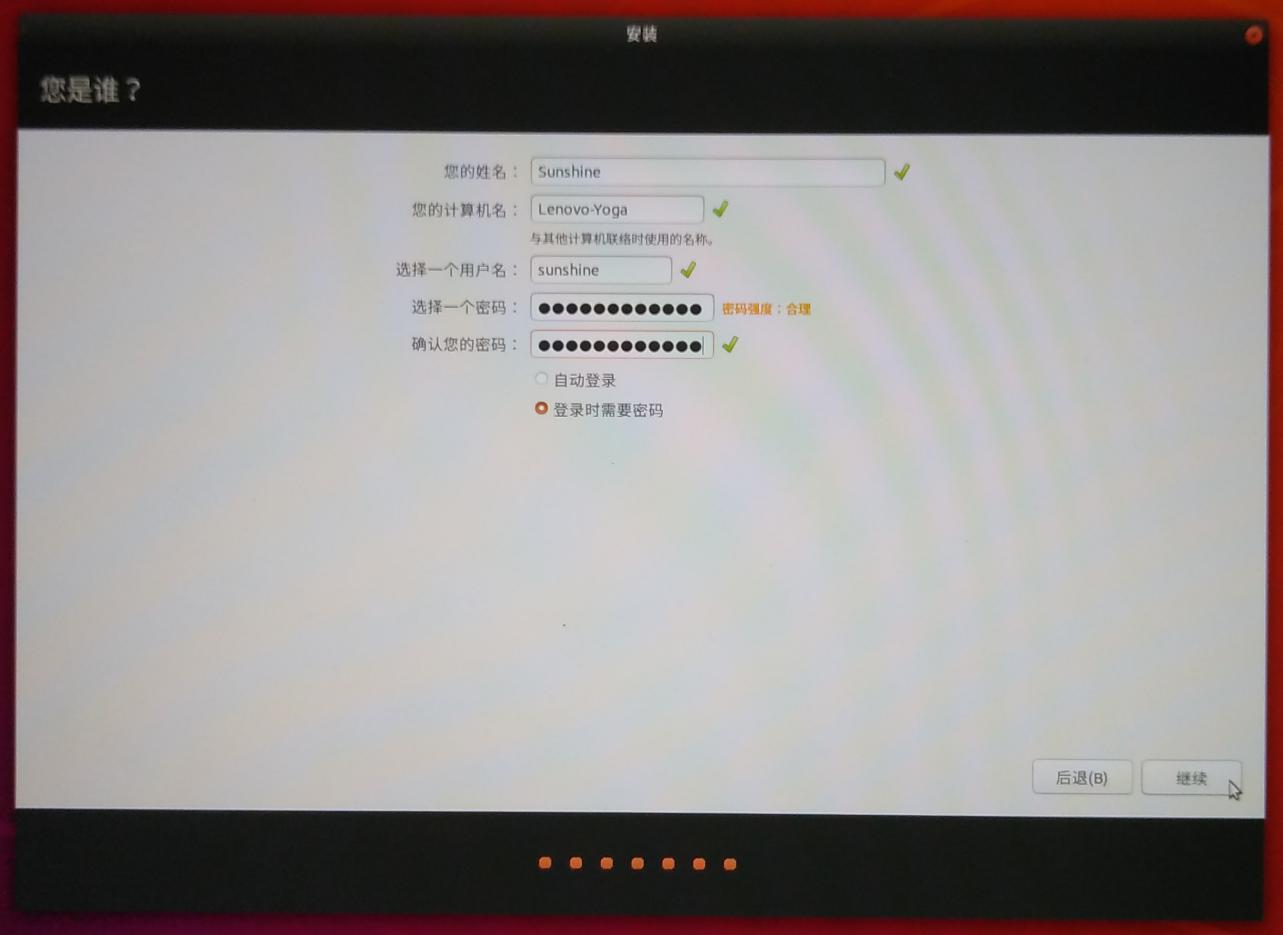
创建用户名和密码
 {width="5.833333333333333in"
{width="5.833333333333333in"
height="4.249305555555556in"}
安装完成后弹出下面的对话框,拔掉U盘重启
 {width="5.833333333333333in"
{width="5.833333333333333in"
height="2.422222222222222in"}
在这里插入图片描述
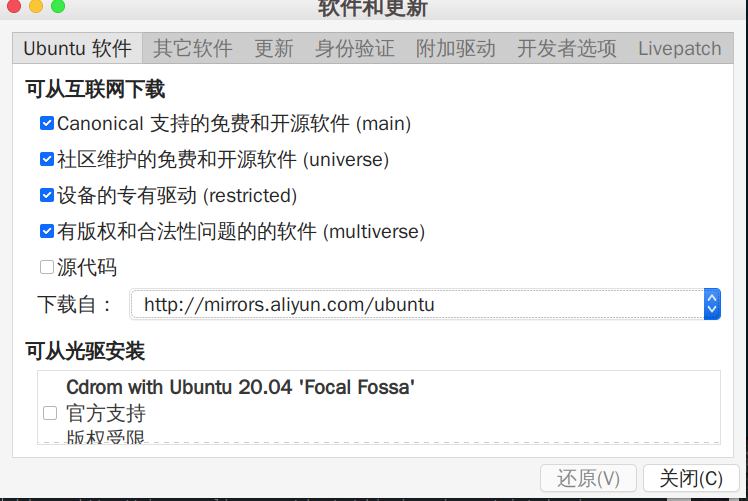
1、更换国内软件源,推荐阿里云
打开LivePatch,选择阿里云
 {width="5.833333333333333in"
{width="5.833333333333333in"
height="3.9069444444444446in"}
2、ctrl+T打开终端执行
sudo apt update
sudo apt upgrade
root密码为安装系统设置的密码
1)安装NVIDIA独立显卡驱动
sudo ubuntu-drivers install
2)安装cuda
sh cuda_11.3.0_465.19.01_linux.run
3)官网下载cudnn库文件
cd到下载目录
解压缩将
Include下的文件复制到/usr/local/cuda-11.0/include下
Lib64下的文件复制到/usr/local/cuda-11.0/下
配置环境变量:
将下面文字写入profile文件
export LD_LIBRARY_PATH=/usr/local/cuda-11.2/lib64
验证是否安装完毕:
终端输入:
nvcc -v
1)为了方便包的安装与管理、我们选择安装annconda最新版本,选择国内镜像源下载速度会比较快。
以清华源为例,下载Anaconda3-2020.11-Linux-x86_64.sh这个版本。
下载完成后进入下载目录
1、赋予可执行权限
sudo chmod +x ./Anaconda3-2020.11-Linux-x86_64.sh
2、安装
sh ./Anaconda3-2020.11-Linux-x86_64.sh
安装过程比较简单,一直选择默认就好。
2)安装完成后将Anaconda写如环境变量PATH
sudo vim /etc/profile
 {width="5.833333333333333in"
{width="5.833333333333333in"
height="0.7645833333333333in"}
写好后保存退出
执行 sudo source /etc/profile
在终端执行conda`` -``V查看版本
 {width="5.833333333333333in"
{width="5.833333333333333in"
height="0.41458333333333336in"}
01.安装构建工具和所有的依赖软件包:
sudo apt install build-essential cmake git pkg-config libgtk-3-dev \
libavcodec-dev libavformat-dev libswscale-dev libv4l-dev \
libxvidcore-dev libx264-dev libjpeg-dev libpng-dev libtiff-dev \
gfortran openexr libatlas-base-dev python3-dev python3-numpy \
libtbb2 libtbb-dev libdc1394-22-dev libopenexr-dev \
libgstreamer-plugins-base1.0-dev libgstreamer1.0-dev
02.克隆所有的OpenCV 和 OpenCV contrib 源:
mkdir ~/opencv_build && cd ~/opencv_build
git clone https://github.com/opencv/opencv.git
git clone https://github.com/opencv/opencv_contrib.git
03.一旦下载完成,创建一个临时构建目录,并且切换到这个目录:
cd ~/opencv_build/opencv
mkdir -p build && cd build
使用 CMake 命令配置 OpenCV 构建:
cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D INSTALL_C_EXAMPLES=ON \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D OPENCV_GENERATE_PKGCONFIG=ON \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_build/opencv_contrib/modules \
-D BUILD_EXAMPLES=ON ..
输出将会如下:
-- Configuring done
-- Generating done
-- Build files have been written to: /home/vagrant/opencv_build/opencv/build
04.开始编译过程:
make -j8
根据处理器核心修改-f值。
编译将会花费几分钟,或者更多,这依赖于你的系统配置。
05.安装 OpenCV:
sudo make install
06.验证安装结果,输入下面的命令,那你将会看到 OpenCV 版本:
C++ bindings:
pkg-config --modversion opencv4
输出:
4.3.0
Python bindings:
python3 -c "import cv2; print(cv2.__version__)"
输出:
4.3.0-dev
到这里opencv安装完成 ### 4、Darknet编译使用
1、克隆仓库darknet到本地 如果没有安装git、先安装git git安装命令:
sudo apt install git
克隆仓库
git clone git@github.com:AlexeyAB/darknet.git
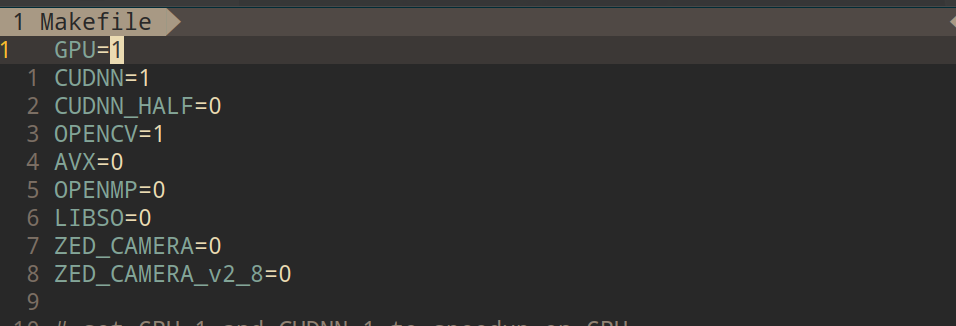
2、根据需要自该Makefile 文件
将这里GPU,CUDNN,OPENCV的值都改为1(1表示启用这个)
 {width="5.833333333333333in"
{width="5.833333333333333in"
height="1.988888888888889in"} 3、编译 在darknet目录下执行编译命令
make -j8
编译时间根据根据硬件情况有所不同,编译完成在目录下会生成一个darknet的二进制文件。
测试
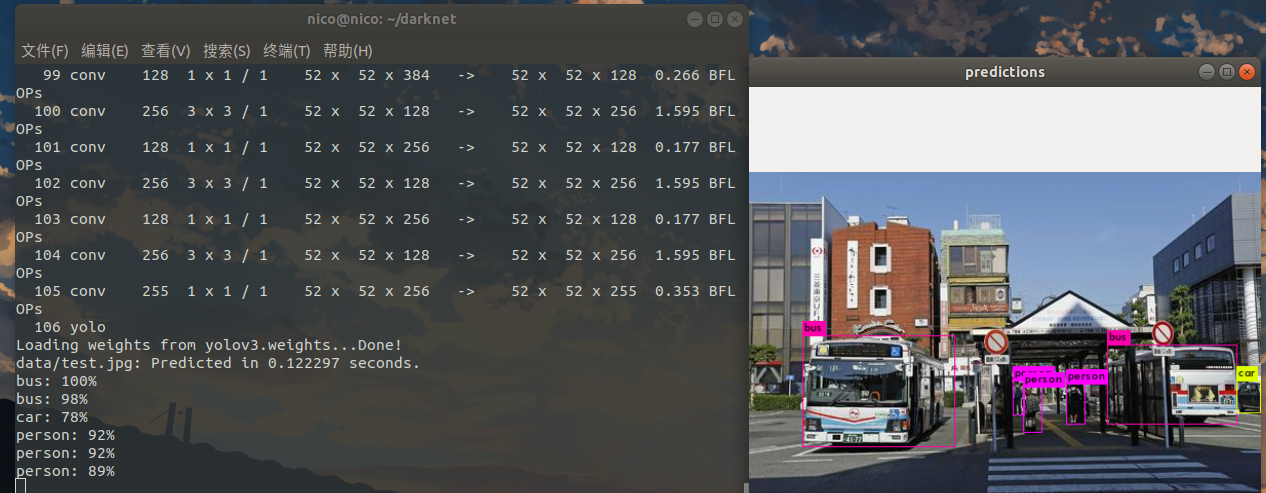
①图像检测
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
 {width="6.040972222222222in"
{width="6.040972222222222in"
height="2.3534722222222224in"}
②视频检测
使用本地视频进行检测
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
test.mp4
调用摄像头实时检测
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
Darknet框架:
1、框架介绍
Darknet深度学习框架是由Joseph
Redmon提出的一个用C和CUDA编写的开源神经网络框架。支持CPU和GPU(CUDA/cuDNN)计算。且支持opencv(可选,用于图像和视频的显示)和openmp(可选,用于支持for语句的并行处理,可以加快cpu的并行处理速度并大幅提高框架的检测效率)。
2、框架特点:
内含多个已经训练完成的神经网络模型、库,可进行简单的物体识别。它安装速度快,易于安装部署。
3、框架测试
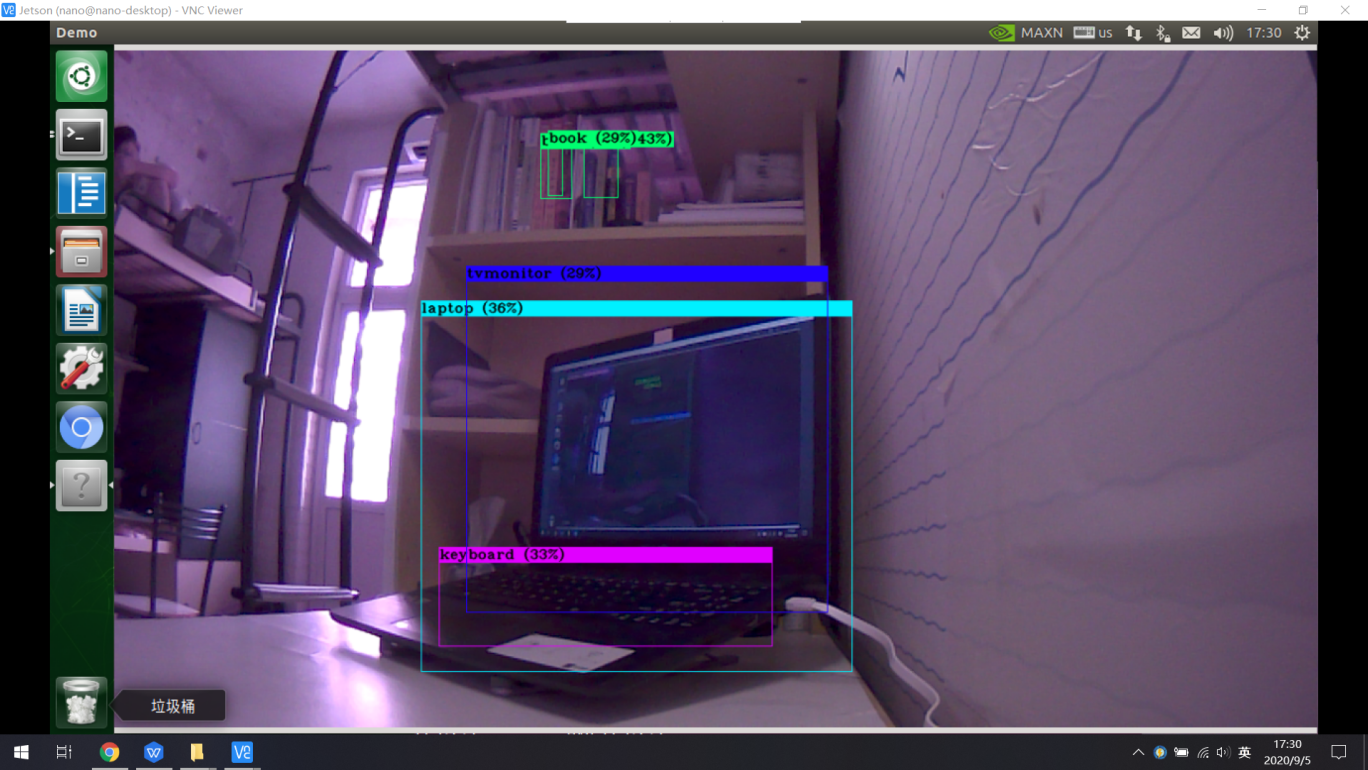
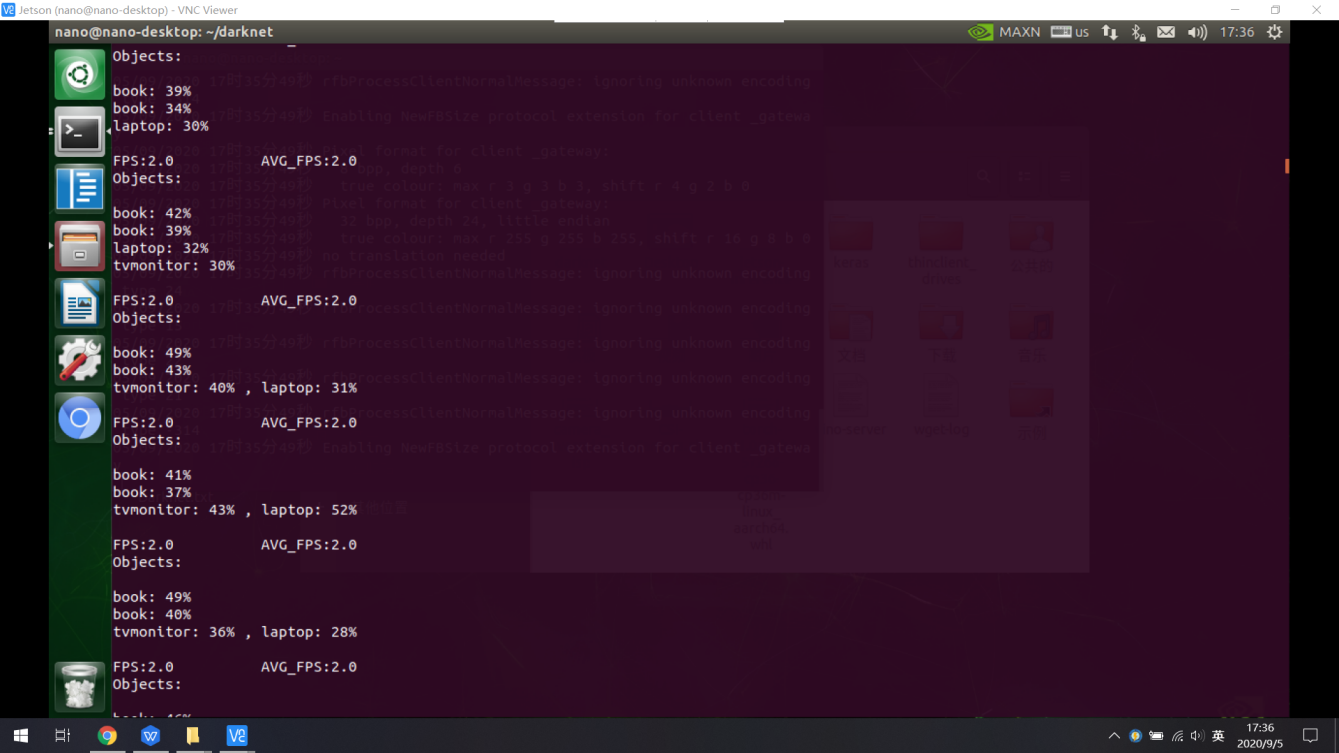
1)视频实时识别
可以调用CSI摄像头,并对CSI拍摄的图像进行实时检测
处理速度:fps=2.0-2.5
 {width="6.219444444444444in"
{width="6.219444444444444in"
height="3.4993055555555554in"}
 {width="6.085416666666666in"
{width="6.085416666666666in"
height="3.423611111111111in"}
2)图片识别
能对于特定的图像内物体进行识别
识别对比:
平均识别时间:2800ms
 {width="4.353472222222222in"
{width="4.353472222222222in"
height="3.4833333333333334in"}
平均识别时间:2700ms
 {width="4.654166666666667in"
{width="4.654166666666667in"
height="1.9395833333333334in"}
平均识别时间:2700ms
 {width="4.669444444444444in"
{width="4.669444444444444in"
height="3.5027777777777778in"}
平均识别时间:2880ms
{width="3.7465277777777777in"
height="2.997916666666667in"}
平均识别时间:2830ms
 {width="4.551388888888889in"
{width="4.551388888888889in"
height="2.560416666666667in"}
平均识别时间:2700ms
 {width="4.548611111111111in"
{width="4.548611111111111in"
height="3.013888888888889in"}
YOLO算法:
YOLO(You Only Look Once)是Joseph
Redmon针对darknet框架提出的核心目标检测算法,作者在算法中把物体检测问题处理成回归问题,用一个卷积神经网络结构就可以从输入图像直接预测bounding
box和类别概率。
YOLO是基于深度学习的端到端的实时目标检测系统。与大部分目标检测与识别方法(比如Fast
R-CNN)将目标识别任务分类目标区域预测和类别预测等多个流程不同,YOLO将目标区域预测和目标类别预测整合于单个神经网络模型中,实现在准确率较高的情况下快速目标检测与识别,更加适合现场应用环境。
经过版本的更新换代、目前yolo已经发展第五个版本,yolo
v5。在本项目中,我们选择使用yolov3。YOLOv3相比前两个版本,是速度和精度最均衡的目标检测网络。通过多种先进方法的融合,将YOLO系列的短板(速度很快,不擅长检测小物体等)全部补齐。达到了令人惊艳的效果和拔群的速度。它具有一下特性:
在YOLO9000之后,我们的系统使用维度聚类(dimension clusters )作为anchor
boxes来预测边界框,网络为每个边界框预测4个坐标,
在YOLOv3中使用逻辑回归预测每个边界框(bounding box)的对象分数。
如果先前的边界框比之前的任何其他边界框重叠ground
truth对象,则该值应该为1。如果以前的边界框不是最好的,但是确实将ground
truth对象重叠了一定的阈值以上,我们会忽略这个预测,按照进行。我们使用阈值0.5。与YOLOv2不同,我们的系统只为每个ground
truth对象分配一个边界框。如果先前的边界框未分配给grounding
box对象,则不会对坐标或类别预测造成损失。
在YOLOv3中,每个框使用多标签分类来预测边界框可能包含的类。该算法不使用softmax,因为它对于高性能没有必要,因此YOLOv3使用独立的逻辑分类器。在训练过程中,我们使用二元交叉熵损失来进行类别预测。对于重叠的标签,多标签方法可以更好地模拟数据。
YOLOv3采用多个尺度融合的方式做预测。原来的YOLO v2有一个层叫:passthrough
layer,假设最后提取的feature
map的size是13*13,那么这个层的作用就是将前面一层的26*26的feature
map和本层的13*13的feature
map进行连接,有点像ResNet。这样的操作也是为了加强YOLO算法对小目标检测的精确度。这个思想在YOLO
v3中得到了进一步加强,在YOLO
v3中采用类似FPN的上采样(upsample)和融合做法(最后融合了3个scale,其他两个scale的大小分别是26*26和52*52),在多个scale的feature
map上做检测,对于小目标的检测效果提升还是比较明显的。虽然在YOLO
v3中每个网格预测3个边界框,看起来比YOLO v2中每个grid
cell预测5个边界框要少,但因为YOLO
v3采用了多个尺度的特征融合,所以边界框的数量要比之前多很多。
YOLO
v3使用新的网络来实现特征提取。在Darknet-19中添加残差网络的混合方式,使用连续的3×3和1×1卷积层,但现在也有一些shortcut连接,YOLO
v3将其扩充为53层并称之为Darknet-53。
二、Jetson Nano环境搭建上与测试
1、Jetson Nano软件环境配置
首先需要对于Jetson
Nano软件环境进行配置,使用TF卡,将Nano镜像文件烧录至开发板中,并需要对于系统进行配置,完成Nano的开机。
开机后还需要对于Ubuntu18.04系统进行初始化设置,配置镜像源、语言输入法等,可以实现使用电脑远程桌面控制Jetson
Nano主机。
 {width="5.638194444444444in"
{width="5.638194444444444in"
height="3.1694444444444443in"}
图2-1-1 Jetson Nano系统配置
在完成系统配置后,还需要进行神经网络环境的搭建,安装TensorFlow-GPU、Keras、YOLO
V3、Cuda等必要图像识别的工具、包,构建Java、Python等开发语言环境,实现在Jetson
Nano中运行检测模型。
 {width="1.6618055555555555in"
{width="1.6618055555555555in"
height="3.222916666666667in"} {width="2.4541666666666666in"
{width="2.4541666666666666in"
height="3.2152777777777777in"}
图2-1-2 Jetson Nano软件配置
2、Jetson Nano外围硬件开发
安装无线模块,使得Jetson Nano能够接入Wifi网络,连接蓝牙设备。将网卡Intel
8265AC模块嵌入开发板中,安装天线,开机后对于网卡模块进行配置后即可正常使用。
安装风扇模块,使得开发板在运行过程中能更好的扇热,提升识别性能。需要编写风扇开机驱动脚本,Nano开机自动开启风扇,还可实现风扇的调速功能。
按键安装,实现Nano按键开机、按键重置功能。需要根据开发板针脚原理图,对于开发板针脚进行连线,完成按键的安装。
 {width="3.584722222222222in"
{width="3.584722222222222in"
height="2.692361111111111in"}
图2-2-1 Jetson Nano外围硬件组装
Jetson
Nano摄像头安装及调试。为Nano安装CSI摄像头,通过CSI接口将Nano与IMX219红外夜视摄像头相连。开机后在Nano上编写调用摄像头的脚本,测试摄像头。
 {width="4.1618055555555555in"
{width="4.1618055555555555in"
height="3.122916666666667in"}
图2-2-2 Jetson Nano整机
3、Jetson Nano硬件调试
①网卡模块的测试
可以完成WIFI连接及蓝牙鼠标、键盘的连接
 {width="4.538194444444445in"
{width="4.538194444444445in"
height="0.33055555555555555in"}
图2-3-1 WIFI、蓝牙连接情况
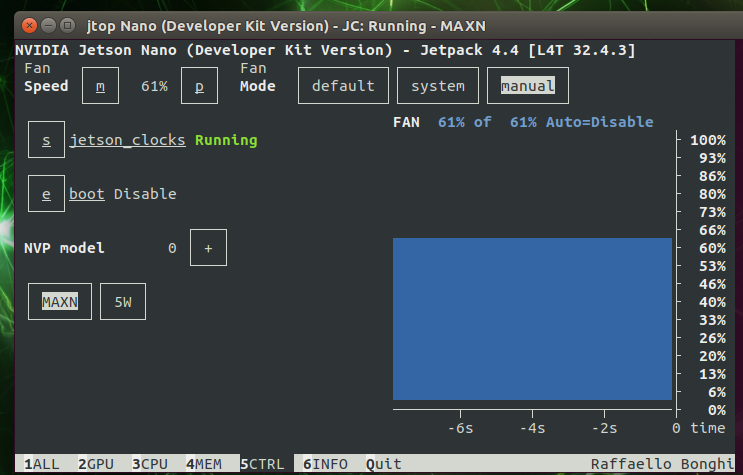
②风扇模块测试
编写风扇驱动脚本,实现开机自动运行风扇,也可以使用Jtop通过终端控制台控制风扇转速。
 {width="4.022916666666666in"
{width="4.022916666666666in"
height="2.5770833333333334in"}
图2-3-2 Jtop界面控制风扇
③摄像头测试
在CSI摄像头连接完成后,使用命令行指令调用摄像头,并对摄像头进行画质的调整。
4、Jetson Nano运行识别模型
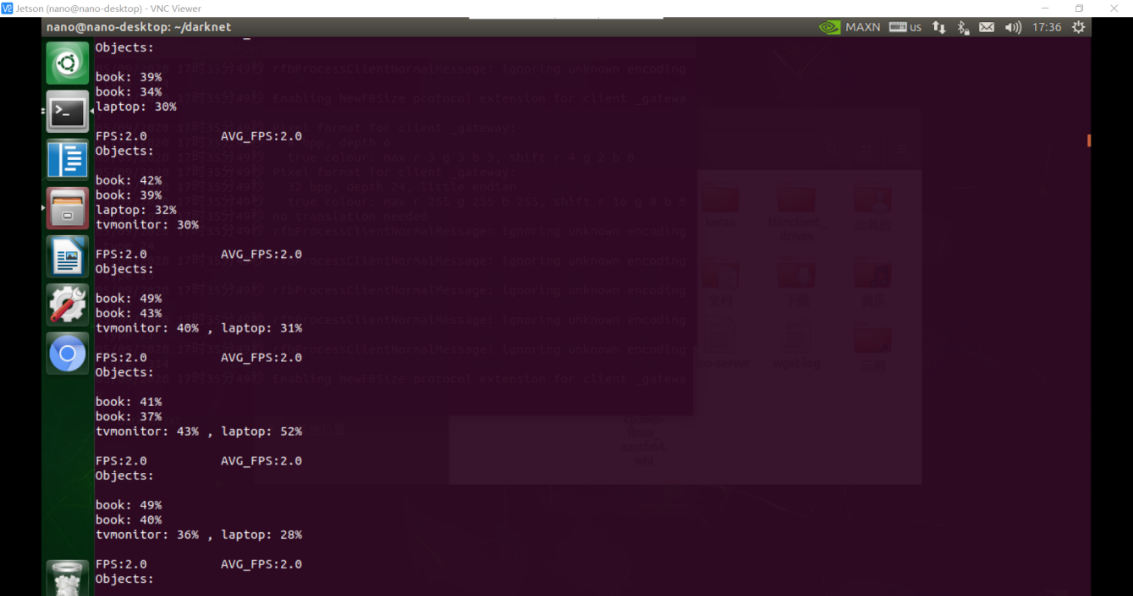
使用Darknet框架,搭配YoloV3训练的模型、coco数据集进行测试,测试有以下两种检测模式:
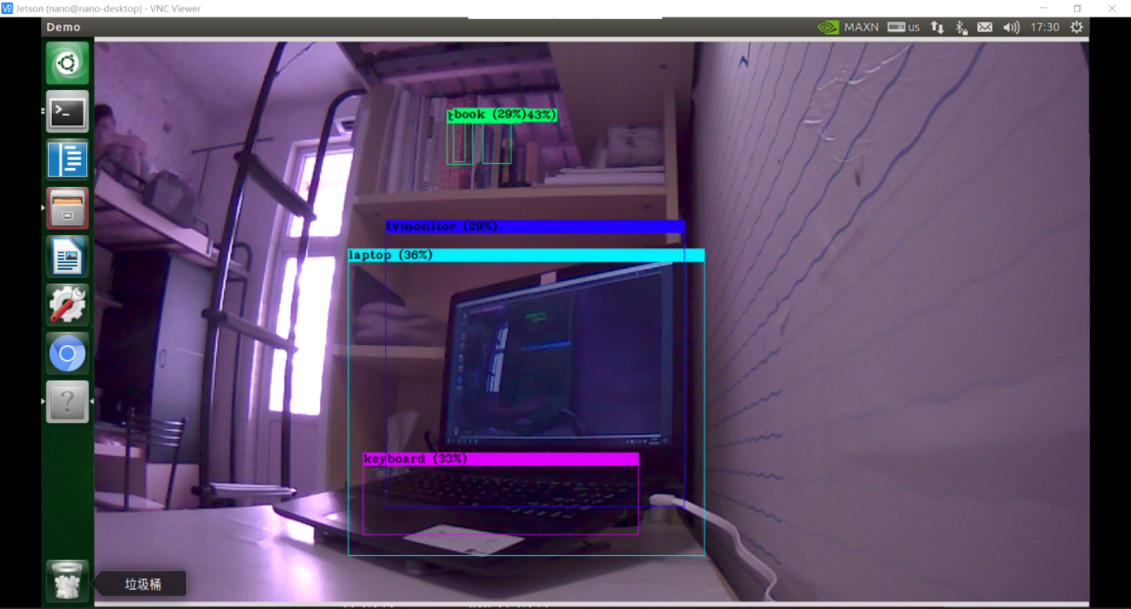
①视频实时识别
可以调用CSI摄像头,并对CSI拍摄的图像进行实时检测
处理速度:fps=2.0-2.5
 {width="5.654166666666667in"
{width="5.654166666666667in"
height="3.0458333333333334in"}
图2-4-1 CSI摄像头实时检测
 {width="5.6618055555555555in"
{width="5.6618055555555555in"
height="2.984722222222222in"}
图2-4-2 摄像头检测结果
②图片识别
能对于特定的图像内物体进行识别
图片1:3840*3072(大小:13.0m)格式:PNG
平均识别时间:2800ms
 {width="4.115277777777778in"
{width="4.115277777777778in"
height="3.292361111111111in"}
图2-4-3 静态图像检测效果
4、Jetson Nano GUI界面设计、
制作GUI界面,实现检测系统在多种检测模式的切换,实现与用户间的交互。
 {width="2.692361111111111in"
{width="2.692361111111111in"
height="1.5694444444444444in"}
图2-5-1 GUI系统登陆界面
 {width="2.845833333333333in"
{width="2.845833333333333in"
height="2.484722222222222in"} {width="2.8229166666666665in"
{width="2.8229166666666665in"
height="2.4770833333333333in"}
图2-5-2 GUI系统操作界面
三、系统运行测试
把pc机上训练好的模型下载到nano系统上,对视频进行检测和分析。
视频实时检测,识别率
检测速度
我试过重新启动apache,缓存的页面仍然出现,所以一定有一个文件夹在某个地方。我没有“公共(public)/缓存”,那么我还应该查看哪些其他地方?是否有一个URL标志也可以触发此效果? 最佳答案 您需要触摸一个文件才能清除phusion,例如:touch/webapps/mycook/tmp/restart.txt参见docs 关于ruby-如何在Ubuntu中清除RubyPhusionPassenger的缓存?,我们在StackOverflow上找到一个类似的问题:
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我试图在rails中了解rubygems是如何变得可以自动使用的,而不是在使用required的文件中gem? 最佳答案 这是通过bundler/setup完成的:http://bundler.io/v1.3/bundler_setup.html.它在您的config/boot.rb文件中是必需的。简而言之,它首先将环境变量设置为指向您的Gemfile:ENV['BUNDLE_GEMFILE']||=File.expand_path('../../Gemfile',__FILE__)然后它通过要求bundler/setup将所有ge
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or