目录
零基础 OpenGL ES 学习路线推荐 : OpenGL ES 学习目录 >> OpenGL ES 基础
零基础 OpenGL ES 学习路线推荐 : OpenGL ES 学习目录 >> OpenGL ES 特效
零基础 OpenGL ES 学习路线推荐 : OpenGL ES 学习目录 >> OpenGL ES 转场
零基础 OpenGL ES 学习路线推荐 : OpenGL ES 学习目录 >> OpenGL ES 函数
零基础 OpenGL ES 学习路线推荐 : OpenGL ES 学习目录 >> OpenGL ES GPUImage 使用
零基础 OpenGL ES 学习路线推荐 : OpenGL ES 学习目录 >> OpenGL ES GLSL 编程
OpenGL ES 1.x 支持 初代 iPhone 和 Android;
OpenGL ES 2.0 支持 Android 2.2 以后的平台,支持 iPad , iPhone3GS 和后续版本,以及 iPodTouch3 代和后续版本。
OpenGL ES 3.0 支持 Android 4.3 以后的平台。支持 iPhone 5s ,iPad Air ,iPad mini 2 及后续版本。
OpenGL ES 3.0 是向下兼容 OpenGL ES 2.0 的。也就是说使用 2.0 编写的应用程序是可以在 3.0 中继续使用的。
//顶点着色器
attribute vec4 aPosition; // 应用程序传入顶点着色器的顶点位置
attribute vec2 aTextureCoord; // 应用程序传入顶点着色器的顶点纹理坐标
varying vec2 vTextureCoord; // 用于传递给片元着色器的顶点纹理数据
void main()
{
gl_Position = aPosition; // 此次绘制此顶点位置
vTextureCoord = aTextureCoord; // 将接收的纹理坐标传递给片元着色器
}
//片元着色器
precision mediump float; // 设置工作精度
varying vec2 vTextureCoord; // 接收从顶点着色器过来的纹理坐标
uniform sampler2D sTexture; // 纹理采样器,代表一幅纹理
void main()
{
gl_FragColor = texture2D(sTexture, vTextureCoord);// 进行纹理采样
}
//顶点着色器
#version es 300
uniform mat4 u_matViewProj;
layout(location = 0) in vec4 a_position;
layout(location = 1) in vec3 a_color;
out vec3 v_color;
void main() {
gl_Position = u_matViewProj * a_position;
v_color = a_color;
}
//片元着色器
#version es 300
precision mediump float;
in vec3 v_color; // input form vertex shader
layout(location = 0) out vec4 o_fragColor;
void main() {
o_fragColor = vec4(v_color, 1.0);
}
在 OpenGL ES 3.0 中,顶点着色器和片段着色器的第一行必须声明着色器版本,否则编译报错:
ERROR: 0:1: '' : syntax error: #version directive must occur in a shader before anything
在 OpenGL ES 3.0 中,可以必须声明着色器版本:
#version es 300
在 OpenGL ES 2.0 中,可以不用声明着色器版本,默认为:
#version es 100
备注: 以往 2.0 刚刚出来可编程的图形管线,所以版本声明为 #version 100 es ,后来为了使版本号相匹配,OpenGL ES 3.0 的 shader 版本直接从 1.0 跳到了 3.0 。
#version 300 es 指定使用OpenGL3.0
#version 100 es 指定使用OpenGL2.0 (不指定version 默认为OpenGL2.0)
在顶点语言中有如下预定义的全局默认精度语句:
precision highp float;
precision highp int;
precision lowp sampler2D;
precision lowp samplerCube;
在片元语言中有如下预定义的全局默认精度语句:
precision mediump int;
precision lowp sampler2D;
precision lowp samplerCube;
片元语言没有默认的浮点数精度修饰符。因此,对于浮点数,浮点数向量和矩阵变量声明,要么声明必须包含一个精度修饰符,要不默认的精度修饰符在之前已经被声明过了
precision highp float;
OpenGL ES 3.0 中新增了** in,out,inout **关键字,用来取代 **attribute 和 varying **关键字。
同时 gl_FragColor 和 gl_FragData 也删除了,片段着色器可以使用 out 声明字段输出。
OpenGL ES 3.0 中可以直接使用 layout 对指定位置的变量赋值。例如:
shader脚本中
layout (location = 1) uniform float a;
代码中,直接写上对应的 layout 的值就可以赋值
GLES30.glUniform1f(1, 1f);
而 OpenGL ES 2.0 中必须使用如下形式赋值:
GLES20.glUniform1f(GLES20.glGetAttribLocation(program, "a"), 1f)
VAO (顶点数组对象:Vertex Array Object)是指顶点数组对象,主要用于管理 VBO 或 EBO ,减少 glBindBuffer 、glEnableVertexAttribArray、 glVertexAttribPointer 这些调用操作,高效地实现在顶点数组配置之间切换。
**VBO(顶点缓冲区对象: Vertex Buffer Object)是指把顶点数据保存在显存中,绘制时直接从显存中取数据,减少了数据传输的开销,**因为顶点数据多了,就是坐标的数据多了很多的很多组,切换的时候很麻烦,就出现了这个 VAO,绑定对应的顶点数据
OpenGL 2.0 有 VBO,没有 VAO,VAO 是 OpenGL 3.0 才开始支持的,并且在 OpenGL 3.0 中,强制要求绑定一个 VAO 才能开始绘制。
例如:在 OpenGL 3.0 中,不使用 VAO ,调用完 glVertexAttribPointer, glGetError 报错 GL_INVALID_OPERATION。
int pos_location = glGetAttribLocation(ProgramId, "position");
glVertexAttribPointer(pos_location, 2, GL_FLOAT, GL_FALSE, 0, kVertices);
查看 OpenGL 官方文档 http://docs.gl/gl3/glVertexAttribPointer
GL_INVALID_OPERATION is generated in the core context if there is no Vertex Array Object bound
在 OpenGL 3.0 中,强制要求绑定一个 VAO 才能开始绘制。因此,需要在程序初始化的时候,创建并绑定一个 VAO
GLuint vao;
glGenVertexArrays(1, &vao);
glBindVertexArray(vao);
此外,OpenGL 3.0 中也不允许在 glVertexAttribPointer 直接传数组了,因此要把顶点先传入 vbo 中
GLuint vbo;
glGenBuffers(1, &vbo);
glBindBuffer(GL_ARRAY_BUFFER, vbo);
glBufferData(GL_ARRAY_BUFFER, sizeof(kVertices), kVertices, GL_STATIC_DRAW);
绑定 VBO 之后,glVertexAttribPointer 后面的 pointer 参数就要填 0 了。
glVertexAttribPointer(pos_location, 2, GL_FLOAT, GL_FALSE, 0, 0);
OpenGL 2.0 不支持 PBO ,3.0 支持 PBO , PBO 设计的目的就是快速地向显卡传输数据,或者从显卡读取数据,我们可以使用它更加高效的读取屏幕数据。
单个 PBO 读取屏幕数据效率大概和 glReadPixels 差不多,双 PBO 交换读取效率会很高。
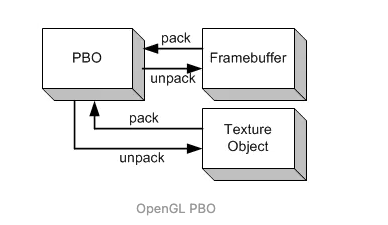
原因是使用 PBO 时,屏幕上的数据不是读取到内存,而是从显卡读到 PBO 中,或者如果内部机制是读取到内存中,但这也是由 DMA 控制器来完成的,而不是 cpu 指令来做的,再加上两个 PBO 交换使用,所以读取效率很高。
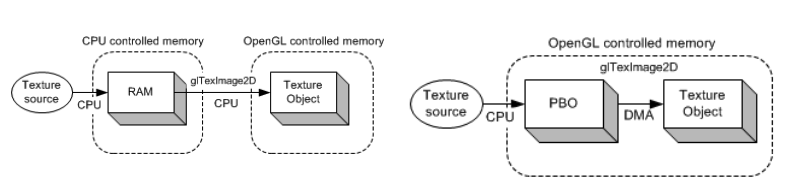
PBO 快速地从内存 CPU 向显卡 GPU 传输数据 —> GL_PIXEL_PACK_BUFFER
**PBO 快速地从显卡 GPU 读取数据到内存 CPU** —> GL_PIXEL_UNPACK_BUFFER
本文由博客 - 猿说编程 猿说编程 发布!
请帮助我理解范围运算符...和..之间的区别,作为Ruby中使用的“触发器”。这是PragmaticProgrammersguidetoRuby中的一个示例:a=(11..20).collect{|i|(i%4==0)..(i%3==0)?i:nil}返回:[nil,12,nil,nil,nil,16,17,18,nil,20]还有:a=(11..20).collect{|i|(i%4==0)...(i%3==0)?i:nil}返回:[nil,12,13,14,15,16,17,18,nil,20] 最佳答案 触发器(又名f/f)是
我正在检查一个Rails项目。在ERubyHTML模板页面上,我看到了这样几行:我不明白为什么不这样写:在这种情况下,||=和ifnil?有什么区别? 最佳答案 在这种特殊情况下没有区别,但可能是出于习惯。每当我看到nil?被使用时,它几乎总是使用不当。在Ruby中,很少有东西在逻辑上是假的,只有文字false和nil是。这意味着像if(!x.nil?)这样的代码几乎总是更好地表示为if(x)除非期望x可能是文字false。我会将其切换为||=false,因为它具有相同的结果,但这在很大程度上取决于偏好。唯一的缺点是赋值会在每次运行
我正在阅读一本关于Ruby的书,作者在编写类初始化定义时使用的形式与他在本书前几节中使用的形式略有不同。它看起来像这样:classTicketattr_accessor:venue,:datedefinitialize(venue,date)self.venue=venueself.date=dateendend在本书的前几节中,它的定义如下:classTicketattr_accessor:venue,:datedefinitialize(venue,date)@venue=venue@date=dateendend在第一个示例中使用setter方法与在第二个示例中使用实例变量之间是
转自:spring.profiles.active和spring.profiles.include的使用及区别说明下文笔者讲述spring.profiles.active和spring.profiles.include的区别简介说明,如下所示我们都知道,在日常开发中,开发|测试|生产环境都拥有不同的配置信息如:jdbc地址、ip、端口等此时为了避免每次都修改全部信息,我们则可以采用以上的属性处理此类异常spring.profiles.active属性例:配置文件,可使用以下方式定义application-${profile}.properties开发环境配置文件:application-dev
打印1:defsum(i)i=i+[2]end$x=[1]sum($x)print$x打印12:defsum(i)i.push(2)end$x=[1]sum($x)print$x后者是修改全局变量$x。为什么它在第二个例子中被修改而不是在第一个例子中?类Array的任何方法(不仅是push)都会发生这种情况吗? 最佳答案 变量范围在这里无关紧要。在第一段代码中,您仅使用赋值运算符=为变量i赋值,而在第二段代码中,您正在修改$x(也称为i)使用破坏性方法push。赋值从不修改任何对象。它只是提供一个名称来引用一个对象。方法要么是破坏性
Ruby中的Fixnum方法.next和.succ有什么区别?看起来它的工作原理是一样的:1.next=>21.succ=>2如果有什么不同,为什么有两种方法做同样的事情? 最佳答案 它们是等价的。Fixnum#succ只是Fixnum#next的同义词。他们甚至在thereferencemanual中共享同一block. 关于ruby-Ruby中.next和.succ的区别,我们在StackOverflow上找到一个类似的问题: https://stacko
我明白了defa(&block)block.call(self)end和defa()yieldselfend导致相同的结果,如果我假设有这样一个blocka{}。我的问题是-因为我偶然发现了一些这样的代码,它是否有任何区别或者是否有任何优势(如果我不使用变量/引用block):defa(&block)yieldselfend这是一个我不理解&block用法的具体案例:defrule(code,name,&block)@rules=[]if@rules.nil?@rules 最佳答案 我能想到的唯一优点就是自省(introspecti
由于匿名block和散列block看起来大致相同。我正在玩它。我做了一些严肃的观察,如下所示:{}.class#=>Hash好的,这很酷。空block被视为Hash。print{}.class#=>NilClassputs{}.class#=>NilClass为什么上面的代码和NilClass一样,下面的代码又显示了Hash?puts({}.class)#Hash#=>nilprint({}.class)#Hash=>nil谁能帮我理解上面发生了什么?我完全不同意@Lindydancer的观点你如何解释下面几行:print{}.class#NilClassprint[].class#A
在Ruby中,我试图理解to_enum和enum_for方法。在我提出问题之前,我提供了一些示例代码和两个示例来帮助理解上下文。示例代码:#replicatesgroup_bymethodonArrayclassclassArraydefgroup_by2(&input_block)returnself.enum_for(:group_by2)unlessblock_given?hash=Hash.new{|h,k|h[k]=[]}self.each{|e|hash[input_block.call(e)]示例#1:irb(main)>puts[1,2,3].group_by2.ins
关于SSHkit-Github它说:Allbackendssupporttheexecute(*args),test(*args)&capture(*args)来自SSHkit-Rubydoc,我明白execute实际上是test的别名?test之间有什么区别?,execute,capture在Capistrano/SSHKit中我应该什么时候使用? 最佳答案 执行只是执行命令。使用非0退出引发错误。测试方法的行为与execute完全相同,但是它返回bool值(true如果命令以0退出,而false否则)。它通常用于控制任务中的流程