GPT2模型是OpenAI组织在2018年于GPT模型的基础上发布的新预训练模型,其论文原文为 language_models_are_unsupervised_multitask_learners
GPT2模型的预训练语料库为超过40G的近8000万的网页文本数据,GPT2的预训练语料库相较于GPT而言增大了将近10倍。
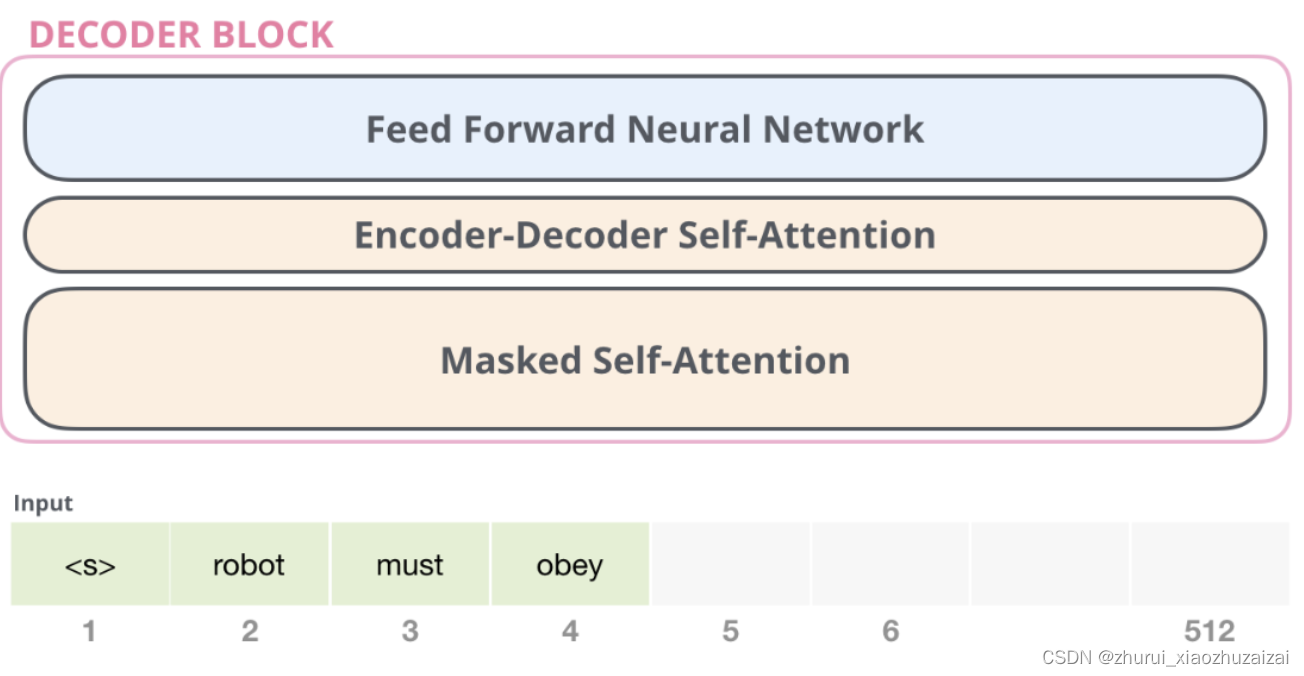
GPT-2 模型由多层单向 Transformer 的解码器部分构成,本质上是自回归模型,自回归的意思是指,每次产生新单词后,将新单词加到原输入句后面,作为新的输入句。其中 Transformer 解码器结构如下图:
GPT-2 模型中只使用了多个 Masked Self-Attention 和 Feed Forward Neural Network 两个模块。
GPT-2 模型会将语句输入上图所示的结构中,预测下一个词,然后再将新单词加入,作为新的输入,继续预测。损失函数会计算预测值与实际值之间的偏差。
从上一节我们了解到 BERT 是基于双向 Transformer 结构构建,而 GPT-2 是基于单向 Transformer,这里的双向与单向,是指在进行注意力计算时,BERT会同时考虑被遮蔽词左右的词对其的影响,而 GPT-2 只会考虑在待预测词位置左侧的词对待预测词的影响。
通过上述数据预处理方法和模型结构,以及大量的数据训练出了 GPT-2 模型。OpenAI 团队由于安全考虑,没有开源全部训练参数,而是提供了小型的预训练模型,接下来我们将在 GPT-2 预训练模型的基础上进行。
预训练模型生成新闻
直接运行一个预训练好的 GPT-2 模型:给定一个预定好的起始单词,然后让它自行地随机生成后续的文本。
问题1:重复性问题。重复生成同一个单词。
解决方式1:从概率前 k 大的单词中随机选取一个单词,作为下一个单词。
问题2:逻辑问题
解决方式:未知。知识??
import random
import logging
logging.basicConfig(level=logging.INFO)
import torch
from pytorch_transformers import GPT2Tokenizer
from pytorch_transformers import GPT2LMHeadModel
# 选择 top-k 的函数的实现,
def select_top_k(predictions, k=10):
predicted_index = random.choice(
predictions[0, -1, :].sort(descending=True)[1][:10]).item()
return predicted_index
# 载入预训练模型的分词器
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# 使用 GPT2Tokenizer 对输入进行编码
text = "Yesterday, a man named Jack said he saw an alien,"
indexed_tokens = tokenizer.encode(text)
tokens_tensor = torch.tensor([indexed_tokens])
tokens_tensor.shape
# 读取 GPT-2 预训练模型
model = GPT2LMHeadModel.from_pretrained("./")
model.eval()
total_predicted_text = text
n = 100 # 预测过程的循环次数
for _ in range(n):
with torch.no_grad():
outputs = model(tokens_tensor)
predictions = outputs[0]
predicted_index = select_top_k(predictions, k=10)
predicted_text = tokenizer.decode(indexed_tokens + [predicted_index])
total_predicted_text += tokenizer.decode(predicted_index)
if '<|endoftext|>' in total_predicted_text:
# 如果出现文本结束标志,就结束文本生成
break
indexed_tokens += [predicted_index]
tokens_tensor = torch.tensor([indexed_tokens])
print(total_predicted_text)
#运行结束后,我们观察一下模型生成的文本,可以看到,大致感觉上这好像是一段正常的文本,不过,仔细看就会发现语句中的逻辑问题,这也是之后研究人员会继续攻克的问题。
微调生成风格文本
接下来,我们将使用一些戏剧剧本对 GPT-2 进行微调。由于 OpenAI 团队开源的 GPT-2 模型预训练参数为使用英文数据集预训练后得到的,虽然可以在微调时使用中文数据集,但需要大量数据和时间才会有好的效果,所以这里我们使用了英文数据集进行微调,从而更好地展现 GPT-2 模型的能力。
首先,下载训练数据集,这里使用了莎士比亚的戏剧作品《罗密欧与朱丽叶》作为训练样本。
数据集已经提前下载好并放在云盘中,
链接:https://pan.baidu.com/s/1LiTgiake1KC8qptjRncJ5w 提取码:km06
with open('./romeo_and_juliet.txt', 'r') as f:
dataset = f.read()
#预处理训练集,将训练集编码、分段。
indexed_text = tokenizer.encode(dataset)
del(dataset)
dataset_cut = []
for i in range(len(indexed_text)//512):
# 将字符串分段成长度为 512
dataset_cut.append(indexed_text[i*512:i*512+512])
del(indexed_text)
dataset_tensor = torch.tensor(dataset_cut)
dataset_tensor.shape
#这里使用 PyTorch 提供的 DataLoader() 构建训练集数据集表示,使用 TensorDataset() 构建训练集数据迭代器。
from torch.utils.data import DataLoader, TensorDataset
# 构建数据集和数据迭代器,设定 batch_size 大小为 2
train_set = TensorDataset(dataset_tensor,
dataset_tensor) # 标签与样本数据相同
train_loader = DataLoader(dataset=train_set,
batch_size=2,
shuffle=False)
#检查是否机器有 GPU,如果有就在 GPU 运行,否则就在 CPU 运行。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#开始训练。
from torch import nn
from torch.autograd import Variable
import time
pre = time.time()
epoch = 30 # 循环学习 30 次
model.to(device)
model.train()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5) # 定义优化器
for i in range(epoch):
total_loss = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data).to(device), Variable(
target).to(device)
optimizer.zero_grad()
loss, logits, _ = model(data, labels=target)
total_loss += loss
loss.backward()
optimizer.step()
if batch_idx == len(train_loader)-1:
# 在每个 Epoch 的最后输出一下结果
print('average loss:', total_loss/len(train_loader))
print('训练时间:', time.time()-pre)
#训练结束后,可以使模型生成文本,观察输出。
text = "From fairest creatures we desire" # 这里也可以输入不同的英文文本
indexed_tokens = tokenizer.encode(text)
tokens_tensor = torch.tensor([indexed_tokens])
model.eval()
total_predicted_text = text
# 使训练后的模型进行 500 次预测
for _ in range(500):
tokens_tensor = tokens_tensor.to('cuda')
with torch.no_grad():
outputs = model(tokens_tensor)
predictions = outputs[0]
predicted_index = select_top_k(predictions, k=10)
predicted_text = tokenizer.decode(indexed_tokens + [predicted_index])
total_predicted_text += tokenizer.decode(predicted_index)
if '<|endoftext|>' in total_predicted_text:
# 如果出现文本结束标志,就结束文本生成
break
indexed_tokens += [predicted_index]
if len(indexed_tokens) > 1023:
# 模型最长输入长度为1024,如果长度过长则截断
indexed_tokens = indexed_tokens[-1023:]
tokens_tensor = torch.tensor([indexed_tokens])
print(total_predicted_text)
#从生成结果可以看到,模型已经学习到了戏剧剧本的文本结构。但是仔细读起来会发现缺少逻辑和关联,这是因为由于时间和设备的限制,对模型的训练比较有限。如果有条件可以用更多的数据,训练更长的时间,这样模型也会有更好的表现。
用到的训练数据是我从网上爬下来的老友记十季的剧本:
https://pan.baidu.com/share/init?surl=blbeVCro1nErh34KUGrPIA
提取码: 40bn
如何用nshepperd 的 gpt-2 库来 finetune 模型
步骤一:下载项目:git clone https://github.com/nshepperd/gpt-2
步骤二:安装所需环境:pip install -r requirements.txt
步骤三:准备模型:python download_model.py 345M
步骤四:准备数据。放到/data目录下
步骤五: finetune【根据机器训练速度会不同,但基本上两三千步就能看到些还算不错的结果了】如想要 finetune 时更快些的话,可以预编码数据成训练格式。
PYTHONPATH=src ./encode.py data/friends.txt data/friends.txt.npz
PYTHONPATH=src ./train.py --dataset data/friends.txt.npz --model_name 345M
其他值得关注参数:
learning_rate: 学习率,默认2e-5,可根据数据集大小适当调整,数据集大的话可以调大些,小的话可以调小些。
sample_every: 每多少步生成一个样本看看效果,默认 100。
run_name: 当前训练命名,分别在samples和checkpoint文件夹下创建当前命名的子文件夹,之后生成的样本和保存的模型分别保存在这两个子文件夹。训练中断想继续训练就可以用同样的run_name,如想跑不同任务请指定不同run_name.步骤六:存储模型:将生成的模型,更改名字,放入models文件夹里,替换掉原来的模型(一定要记得将之前的模型备份!)。
步骤七:生成样本:
自由生成 python src/generate_unconditional_samples.py --top_k 40 --temperature 0.9 --model_name 345M
然后是命题作文,有条件互动生成环节。
python src/interactive_conditional_samples.py --top_k 40 --temperature 0.9 --model_name 345M
运行后会出现一个互动框,输入你想让模型续写的话,给定输入:Rachel loves Andy
在 Rachel loves Andy 两秒后,完美跑题,伤心,不过感觉后半段还是很有意思。
关于参数 --topk 还有 --temperature,会影响生成的效果,可自己尝试调节一下,上面例子使用的是两个推荐设定。
到此 finetune 一个基本 GPT-2 的过程就完了,是不是比想象中要简单很多。
# 步骤一:下载模型
import gpt_2_simple as gpt2
gpt2.download_gpt2(model_name="345M")
# 步骤二:训练
# 很直观,直接调用 gpt2.finetune 就可以了。
sess = gpt2.start_tf_sess()
gpt2.finetune(sess,
dataset="friends.txt",
model_name='345M',
steps=1000,
restore_from='fresh',
print_every=10,
sample_every=200,
save_every=500
)
#gpt2.finetune 训练参数介绍:
# restore_from: fresh 是指从 GPT2 原模型开始, 而 latest是从之前 finetune 保存的模型继续训练
# sample_every: 每多少步输出样本,看看训练效果
# print_every: 每多少步打印训练的一些参数,从左到右,步数、时间,loss,平均loss
# learning_rate: 学习率 (默认 1e-4, 如果数据小于1MB的话可以调低到 1e-5)
# run_name: 运行的时候,保存模型到checkpoint下子文件夹,默认 run1
#步骤三:生成环节,先把模型 load 进来。然后生成文本。
# 要大量生成文本的话可以用gpt2.generate_to_file.
sess = gpt2.start_tf_sess()
gpt2.load_gpt2(sess)
gpt2.generate(sess)
# gpt2.generate 里面也有很多参数可以设置:
#length: 生成文本长度 (默认 1023, 也是可设最大长度)
#temperature: temperature 越高,生成越随意。 (默认 0.7,推荐 0.7 到 1.0之间)
#top_k: 将输出限定在 top k 里面 (默认0,也就是不使用。推荐在生成效果差的时候使用,可以设top_k=40)
#truncate: 从指定符号阶段生成文本 (比如设 truncate='<|endoftext|>', 那么就会取第一个'<|endoftext|>'前的文本作为输出). 可以和一个比较小的length值搭配使用.
#include_prefix: 如果用了 truncate 和 include_prefix=False, 那么在返回文本中就不会包含prefix里的文本。
flask 部署
步骤一:提供模型到models/ 下(Huggingface 的 pytorch 格式)。
命名为gpt2-pytorch_model.bin
也可以先用它提供的实例模型来做个实验:
mkdir models
curl --output models/gpt2-pytorch_model.bin https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-pytorch_model.bin
步骤二:得到访问端口:python deployment/run_server.py.
步骤三:直接用浏览器访问就行了,如果是远程访问把 0.0.0.0 改成服务器IP就好了。
如何部署自己的模型
步骤一:将 tensorflow 的模型转换成 Pytorch 的模型。
这里可以用 Huggingface 的pytorch-pretrained-BERT 库里面的转换脚本,先根据指示安装库,之后运行以下脚本。export GPT2_DIR=模型所在文件夹
pytorch_pretrained_bert convert_gpt2_checkpoint $GPT2_DIR/model_name output_dir/ path_to_config/config.json上面命令 convert_gpt2_checkpoint 后三个参数分别是,输入的 tensorflow 模型路径,转换输出的 pytorch 模型路径,模型的配置参数文件。
需要注意的是,因为这几个库之间的不统一,所以下载下来 345M 模型的设置文件在转换时会出错,需要添加一些参数。前面有下载 345M 模型的话,会发现模型文件夹下有一个设置文件 hparams.json。
cp hparams.json hparams_convert.json #复制一份来修改
之后在 hparams_convert.json里添加几个参数,改成下面这样:
{
“n_vocab”: 50257,
“n_ctx”: 1024,
“n_embd”: 1024,
“n_head”: 16,
“n_layer”: 24,
“vocab_size”:50257,
“n_positions”:1024,
“layer_norm_epsilon”:1e-5,
“initializer_range”: 0.02
}
将这个设置文件指定到转换命令convert_gpt2_checkpoint后面相应参数去。获得转换模型后,把它放入models/ 中去,并且重命名,之后把 deployment/GPT2/config.py 里面的参数设定改成再改成 345M 大模型的参数就好了。
class GPT2Config(object):
def init(
self,
vocab_size_or_config_json_file=50257,
n_positions=1024,
n_ctx=1024,
n_embd=1024,
n_layer=24,
n_head=16,
layer_norm_epsilon=1e-5,
initializer_range=0.02,
):
最后运行 run_server.py,成功载入模型,部署完成!之后测试一下,发现确实是已经 finetune 好的老友记模型。
参考:
GPT2 代码解释: GPT2LMHeadModel类、GPT2Model类、Block类、MLP类与Attention类
GPT-2 进行文本生成
AI界最危险武器 GPT-2 使用指南:从Finetune到部署
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
我正在使用Rails3.1并在一个论坛上工作。我有一个名为Topic的模型,每个模型都有许多Post。当用户创建新主题时,他们也应该创建第一个Post。但是,我不确定如何以相同的形式执行此操作。这是我的代码:classTopic:destroyaccepts_nested_attributes_for:postsvalidates_presence_of:titleendclassPost...但这似乎不起作用。有什么想法吗?谢谢! 最佳答案 @Pablo的回答似乎有你需要的一切。但更具体地说...首先改变你View中的这一行对此#