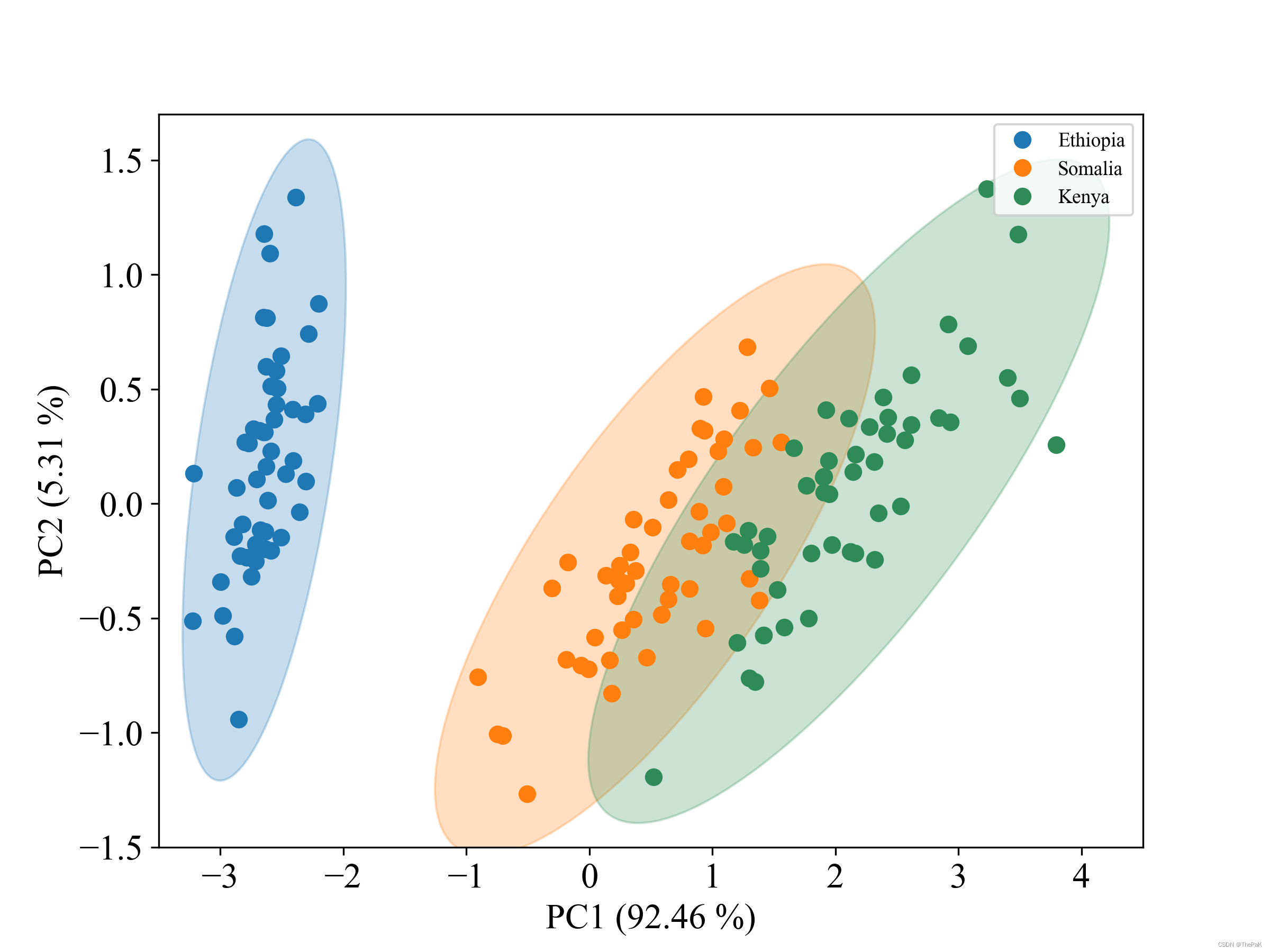
此代码以数据集鸢尾花为例,对其使用PCA降维后,绘制了三个类别的样本点和对应的置信圆(即椭圆)。先放效果图。
from matplotlib.patches import Ellipse
def plot_point_cov(points, nstd=3, ax=None, **kwargs):
# 求所有点的均值作为置信圆的圆心
pos = points.mean(axis=0)
# 求协方差
cov = np.cov(points, rowvar=False)
return plot_cov_ellipse(cov, pos, nstd, ax, **kwargs)
def plot_cov_ellipse(cov, pos, nstd=3, ax=None, **kwargs):
def eigsorted(cov):
cov = np.array(cov)
vals, vecs = np.linalg.eigh(cov)
order = vals.argsort()[::-1]
return vals[order], vecs[:, order]
if ax is None:
ax = plt.gca()
vals, vecs = eigsorted(cov)
theta = np.degrees(np.arctan2(*vecs[:, 0][::-1]))
width, height = 2 * nstd * np.sqrt(vals)
ellip = Ellipse(xy=pos, width=width, height=height, angle=theta, **kwargs)
ax.add_artist(ellip)
return ellip
'''画置信圆'''
def show_ellipse(X_pca, y, pca, flag=1):
# 定义颜色
colors = ['tab:blue', 'tab:orange', 'seagreen']
regions = ['Ethiopia', 'Somalia', 'Kenya']
# 定义分辨率
plt.figure(dpi=300, figsize=(8, 6))
# 三分类则为3
for i in range(0, 3):
pts = X_pca[y == int(i), :]
new_x, new_y = X_pca[y==i, 0], X_pca[y==i, 1]
plt.plot(new_x, new_y, '.', color=colors[i], label=regions[i], markersize=14)
plot_point_cov(pts, nstd=3, alpha=0.25, color=colors[i])
# 添加坐标轴
plt.xlim(-3.5, 4.5)
plt.ylim(-1.5, 1.7)
plt.xticks(size=16, family='Times New Roman')
plt.yticks(size=16, family='Times New Roman')
font = {'family': 'Times New Roman', 'size': 16}
plt.xlabel('PC1 ({} %)'.format(round(pca.explained_variance_ratio_[0] * 100, 2)), font)
plt.ylabel('PC2 ({} %)'.format(round(pca.explained_variance_ratio_[1] * 100, 2)), font)
plt.legend(prop={"family": "Times New Roman", "size": 9}, loc='upper right')
plt.show()
import pandas as pd
from sklearn.decomposition import PCA
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
labels = ['setosa', 'versicolor', 'virginica']
iris = load_iris()
X = iris.data
y = iris.target_names[iris.target]
print("y length--------", len(y))
y_category = pd.Categorical(y,ordered=True,categories=['setosa', 'versicolor', 'virginica'])
y = y_category.codes
print(y)
print(y.shape)
print(type(y[0]))
n_components = 2
pca = PCA(n_components=n_components)
X_pca = pca.fit_transform(X)
show_ellipse(X_pca, y, pca)下面讲解实现过程。
首先导入需要的库和数据集:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from matplotlib.patches import Ellipse
然后定义了一个函数 plot_point_cov(),用于计算样本点的协方差矩阵,并调用另一个函数 plot_cov_ellipse(),绘制置信椭圆。
代码中的cov变量是用于计算数据集协方差矩阵的。协方差矩阵用于描述多个变量之间的关系,其中对角线上的元素表示每个变量本身的方差,非对角线上的元素表示不同变量之间的协方差。
在函数plot_cov_ellipse()中使用协方差矩阵计算数据集的特征向量和特征值。特征向量和特征值用于确定椭圆的大小和方向,以便绘制置信椭圆。
因为在二维空间中,椭圆的方向和大小可以用特征向量和特征值来描述。例如对于一个2x2的协方差矩阵cov,它有两个特征向量和两个特征值,分别表示数据集在两个主要方向上的方差和偏移。特征向量的方向决定了椭圆的主轴方向,而特征值的大小则决定了椭圆沿每个主轴的长度。
在函数plot_cov_ellipse()中,先使用np.linalg.eigh()函数计算协方差矩阵cov的特征值和特征向量,然后按特征值从大到小的顺序排序,这样可以确保主轴方向是正确的。然后根据主轴方向的角度和特征值计算椭圆的宽度和高度,进而绘制置信椭圆。函数np.degrees()用于将弧度转换为角度,函数np.arctan2()用于计算角度。
np.degrees()该函数使用的公式:角度=弧度*180/pi
np.degrees()函数的参数是np.arctan2(*vecs[:, 0][::-1]),它表示计算向量vecs中第一列(即下标为 0 的列)的极角(即与 x 轴的夹角)并将结果转换为角度制。具体来说,
vecs[:, 0]表示选取vecs中所有行的第一列组成的向量,[::-1]表示将该向量反转,从而得到与arctan2函数所需的参数格式一致的向量。然后,
np.arctan2()函数接收两个参数,表示计算以这两个参数组成的向量为起点,与原点连接的向量的极角。这里第一个参数是反转后的向量,即vecs[:, 0][::-1],第二个参数未给出,因此默认为 1。最后,
np.degrees()函数将弧度制的极角值转换为角度制。因此,整个代码行的作用是计算向量vecs的第一列的极角,并将结果转换为角度制。
vals, vecs = eigsorted(cov)其目的是计算输入协方差矩阵的特征值和特征向量并返回排好序的结果。特征值(eigenvalues)是协方差矩阵的一个重要属性,代表着每个特征向量的方差。在PCA中,特征值告诉我们每个主成分解释方差的大小。排序特征值后,我们可以选择最大的K个特征值来保留大部分数据的方差。
特征向量(eigenvectors)是PCA中另一个重要的概念,它们是协方差矩阵的正交基向量。每个特征向量对应着一个特征值。它们可以用来表示主成分的方向,PCA中的主成分就是按特征值大小排序后的特征向量。PCA的主要目的就是通过旋转坐标系来最大化每个主成分方差。
特征向量在这里被用来求出主成分的方向。在函数中,特征向量通过
vecs[:, order]得到,[:, order]表示选中所有行(:)和按照特定顺序排序的所有列(order)。这些特征向量就是主成分方向的坐标轴,可以用来画出置信区间椭圆的角度。椭圆的角度可以通过主成分方向的坐标轴与水平轴的夹角得到。在给定的代码中,
theta被计算为np.degrees(np.arctan2(*vecs[:, 0][::-1])),其中arctan2()计算向量的反正切值,[::-1]表示按照相反的顺序取向量的元素。np.degrees()将弧度转换为角度。
在
plot_cov_ellipse()函数中,width和height分别表示绘制的椭圆的宽度和高度。具体来说,它们是通过将椭圆的半长轴和半短轴的长度设置为:
- 半长轴的长度等于
2 * nstd * sqrt(eigenvalue_1),其中eigenvalue_1是协方差矩阵的第一个特征值。- 半短轴的长度等于
2 * nstd * sqrt(eigenvalue_2),其中eigenvalue_2是协方差矩阵的第二个特征值。因此,
width和height定义了椭圆的大小和形状,这取决于协方差矩阵的特征值以及nstd的值。当nstd=1时,它们定义了一个标准偏差的椭圆,绘制的置信椭圆包含了数据的约68.27%的置信区间。
nstd=2表示椭圆的长度和宽度分别扩展到 2 倍标准差的大小,覆盖了大约 95.45% 的数据。这是因为在正态分布中,大约有 95.45% 的数据落在距离均值两个标准差的范围内。因此,使用nstd=2绘制置信椭圆通常被认为是覆盖 95% 的置信区间。
nstd=3表示椭圆的长度和宽度分别扩展到 3 倍标准差的大小,覆盖了大约 99.73% 的数据。这是因为在正态分布中,大约有 99.73% 的数据落在距离均值三个标准差的范围内。因此,使用nstd=3绘制置信椭圆通常被认为是覆盖 99% 的置信区间。但需要注意的是,这里所提到的百分比是基于正态分布的假设。如果数据不符合正态分布,那么覆盖的百分比可能会有所不同。因此,对于非正态分布的数据,确定置信区间的百分比需要使用其他方法。
def plot_point_cov(points, nstd=3, ax=None, **kwargs):
# 求所有点的均值作为置信圆的圆心
pos = points.mean(axis=0)
# 求协方差矩阵
cov = np.cov(points, rowvar=False)
return plot_cov_ellipse(cov, pos, nstd, ax, **kwargs)
def plot_cov_ellipse(cov, pos, nstd=3, ax=None, **kwargs):
def eigsorted(cov):
cov = np.array(cov)
vals, vecs = np.linalg.eigh(cov)
order = vals.argsort()[::-1]
return vals[order], vecs[:, order]
if ax is None:
ax = plt.gca()
vals, vecs = eigsorted(cov)
theta = np.degrees(np.arctan2(*vecs[:, 0][::-1]))
width, height = 2 * nstd * np.sqrt(vals)
ellip = Ellipse(xy=pos, width=width, height=height, angle=theta, **kwargs)
ax.add_artist(ellip)
return ellip
最后,定义了一个函数 show_ellipse(),用于绘制样本点和置信椭圆。
'''画置信圆'''
def show_ellipse(X_pca, y, pca, flag=1):
# 定义颜色
colors = ['tab:blue', 'tab:orange', 'seagreen']
regions = ['Ethiopia', 'Somalia', 'Kenya']
# 定义分辨率
plt.figure(dpi=300, figsize=(8, 6))
# 三分类则为3
for i in range(0, 3):
pts = X_pca[y == int(i), :]
new_x, new_y = X_pca[y==i, 0], X_pca[y==i, 1]
plt.plot(new_x, new_y, '.', color=colors[i], label=regions[i], markersize=14)
plot_point_cov(pts, nstd=3, alpha=0.25, color=colors[i])
# 添加坐标轴
plt.xlim(-3.5, 4.5)
plt.ylim(-1.5, 1.7)
plt.xticks(size=16, family='Times New Roman')
plt.yticks(size=16, family='Times New Roman')
font = {'family': 'Times New Roman', 'size': 16}
plt.xlabel('PC1 ({} %)'.format(round(pca.explained_variance_ratio_[0] * 100, 2)), font)
plt.ylabel('PC2 ({} %)'.format(round(pca.explained_variance_ratio_[1] * 100, 2)), font)
plt.legend(prop={"family": "Times New Roman", "size": 9}, loc='upper right')
plt.show()以数据集鸢尾花为例进行PCA降维,并使用上面代码画置信圆。
import pandas as pd
from sklearn.decomposition import PCA
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
labels = ['setosa', 'versicolor', 'virginica']
iris = load_iris()
X = iris.data
y = iris.target_names[iris.target]
print("y length--------", len(y))
y_category = pd.Categorical(y,ordered=True,categories=['setosa', 'versicolor', 'virginica'])
y = y_category.codes
print(y)
print(y.shape)
print(type(y[0]))
n_components = 2
pca = PCA(n_components=n_components)
X_pca = pca.fit_transform(X)
show_ellipse(X_pca, y, pca)上面解析均为学习使用,如有问题请指正。
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p