一天在路边看到一个街头采访
记者:请问,假如你儿子娶媳妇,给多少彩礼合适呢
大爷:一百万吧,再给一套房,一辆车
大爷沉思一下,继续说到:如果有能力的话再给老丈人配一辆车,毕竟他把女儿养这么大也不容易
记者:那你儿子多大了?
大爷:我没有儿子,有两个女儿

最近生产环境出现了一个问题,错误日志类似如下
Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 1010, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_user日志信息提示的很明显:获取 JDBC Connection 失败,因为从 druid 连接池获取 connection 超时了

上图的意思是:执行 select * from tbl_user 之前,需要从 druid 连接池中获取一个 connect
而此时连接池的状态是:一共 10 个激活的 connect ,连接池最大创建 10 个 connect ,正在执行 sql 的 connect 也是 10 个
所以不能创建新的 connect ,那就等呗,一共等了 1010 毫秒,还是拿不到 connect ,就抛出 GetConnectionTimeoutException 异常
简单点说就是是连接池中连接数不够,在规定的时间内拿不到 connect
那有人就说了:连接池的最大数量设置大一点,问题不就解决了吗
最大连接数设置大一点只能说可以降低问题发生的概率,不能完全杜绝,因为网络情况、硬件资源的使用情况等等都是不稳定因素
今天要讲的不是连接池大小问题,而是超时设置问题,我们慢慢往下看
我们先来模拟下上述问题
MySQL 版本: 5.7.21 ,隔离级别:RR
Druid 版本: 1.1.12
spring-jdbc 版本: 5.2.3.RELEASE
为了方便演示,就手动初始化了

线程数多于连接池中 connect 数

如果查询飞快,15 个查询,可能都用不上 10 个 connect ,所以我们需要简单处理下
很简单,给表加写锁呗: LOCK TABLES tbl_user WRITE
给表 tbl_user 加上写锁,然后跑线程去查询 tbl_user 的数据
先锁表,再启动程序
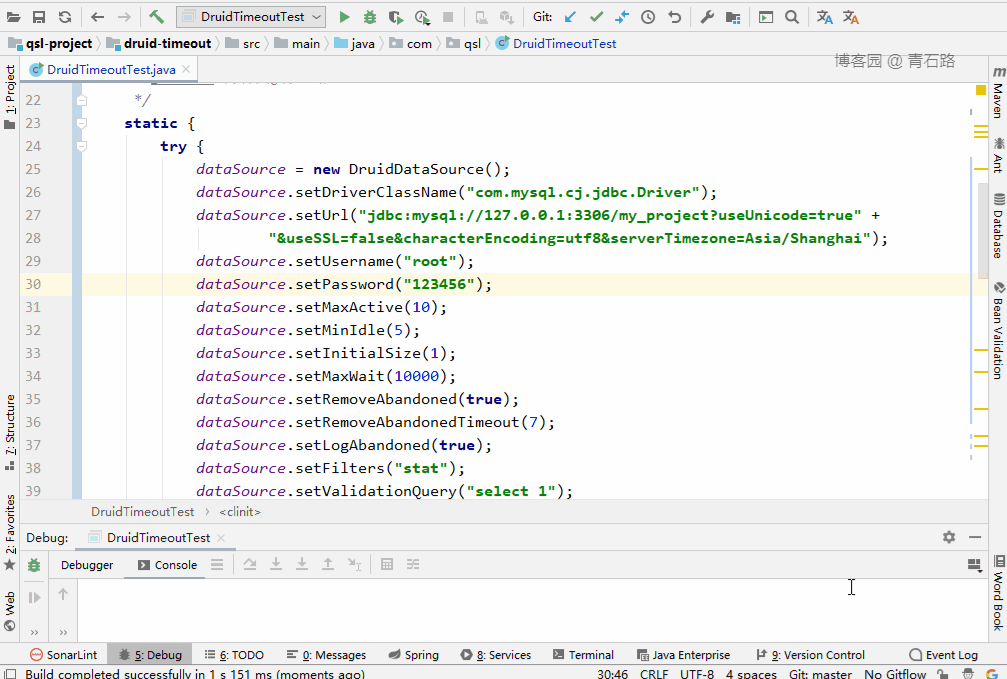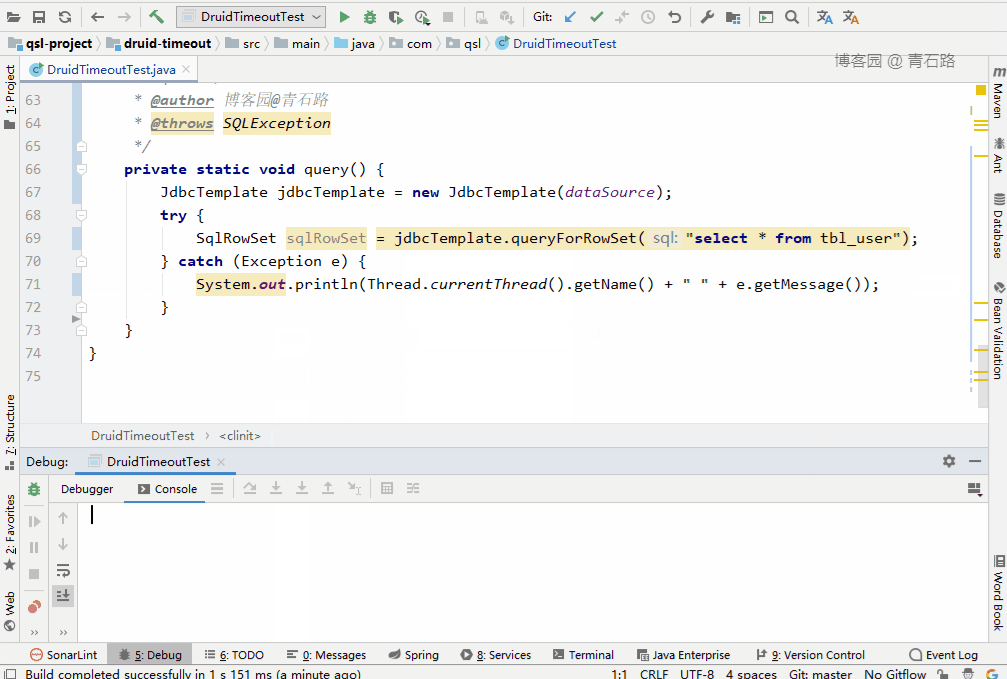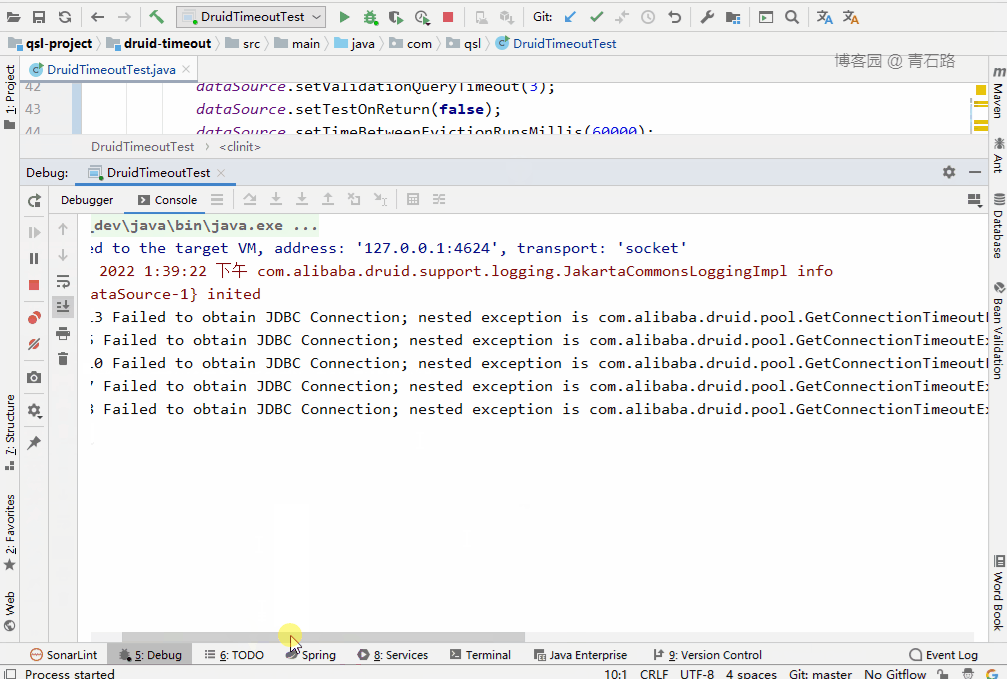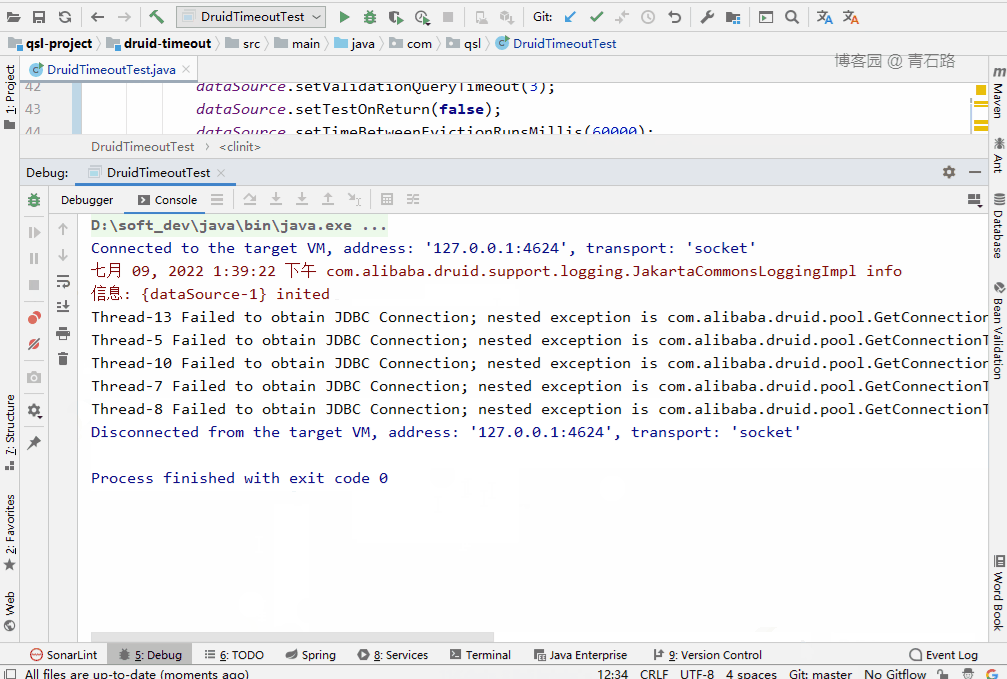
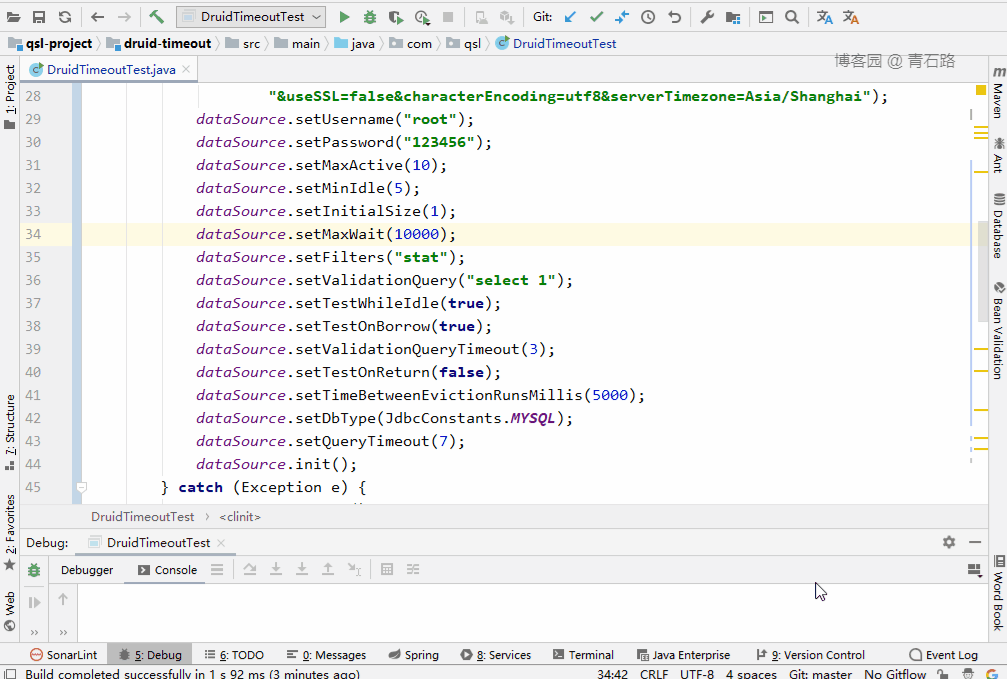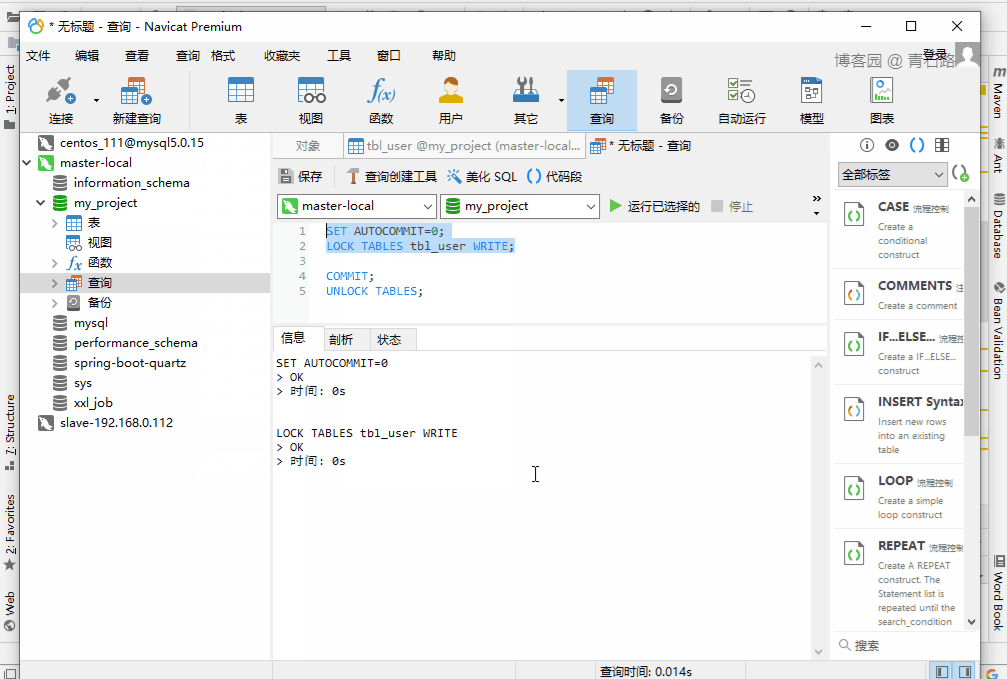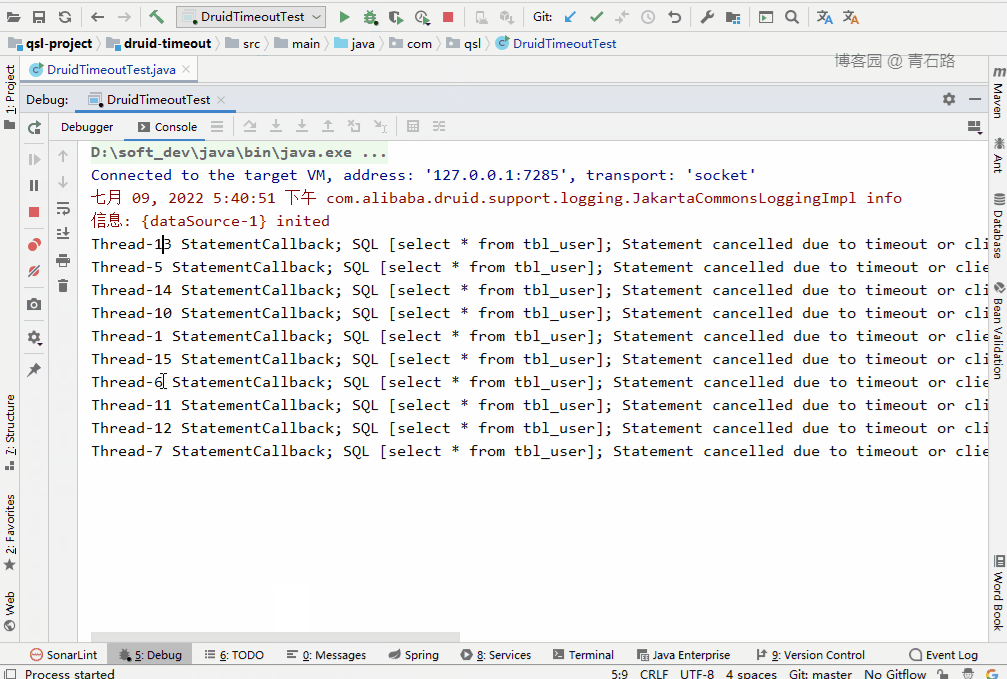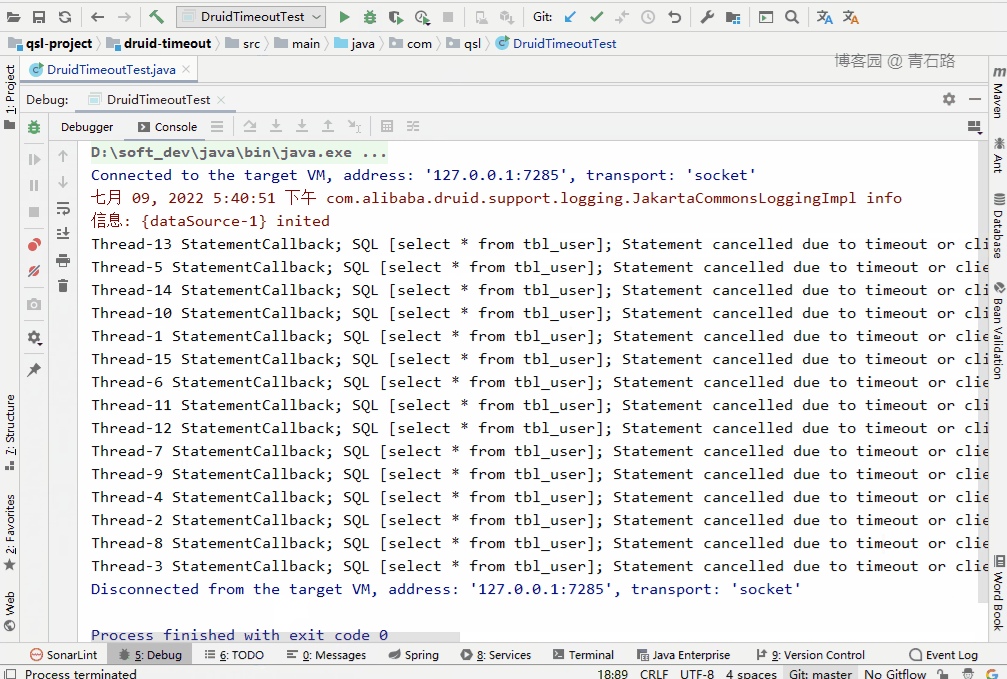
可以看到,15 个线程中,有 5 个线程获取 connect 失败
Thread-13 Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 10004, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_user
Thread-5 Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 10004, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_user
Thread-10 Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 10004, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_user
Thread-7 Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 10004, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_user
Thread-8 Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 10004, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_user示例代码:druid-timeout
Druid 中关于时间的配置项有很多,我们我们重点来看下如下几个
最大等待时长,单位是毫秒,-1 表示无限制
从连接池获取 connect ,如果有空闲的 connect ,则直接获取到,如果没有则最长等待 maxWait 毫秒,如果还获取不到,则抛出 GetConnectionTimeoutException 异常
设置 druid 强制回收连接的时限,单位是秒
从连接池获取到 connect 开始算起,超过此值后, Druid 将强制回收该连接
官网也有说明:连接泄漏监测
检测连接是否有效的超时时间,单位是秒,-1 表示无限制
Druid 内部的一个检测 connect 是否有效的超时时间,需要结合 validationQuery 来配置
检查空闲连接的频率,单位是毫秒, 非正整数表示不进行检查
空闲连接检查的间隔时间, Druid 池中的 connect 数量是一个动态从 minIdle 到 maxActive 扩张与收缩的过程
connect 使用高峰期,数量会从 minIdle 扩张到 maxActive ,使用低峰期, connect 数量会从 maxActive 收缩到 minIdle
收缩的过程会回收一些空闲的 connect ,而 timeBetweenEvictionRunsMillis 就是检查空闲连接的间隔时间
执行查询的超时时间,单位是秒,-1 表示无限制
最终会应用到 Statement 对象上,执行时如果超过此时间,则抛出 SQLException
执行一个事务的超时时间,单位是秒
最小空闲时间,单位是毫秒,默认 30 分钟
如果连接池中非运行中的连接数大于 minIdle ,并且某些连接的非运行时间大于 minEvictableIdleTimeMillis ,则连接池会将这部分连接设置成 Idle 状态并关闭
最大空闲时间,单位是毫秒,默认 7 小时
如果 minIdle 设置的比较大,连接池中的空闲连接数一直没有超过 minIdle ,那么那些空闲连接是不是一直不用关闭?
当然不是,如果连接太久没用,数据库也会把它关闭(MySQL 默认 8 小时),这时如果连接池不把这条连接关闭,程序就会拿到一条已经被数据库关闭的连接
为了避免这种情况, Druid 会判断池中的连接,如果非运行时间大于 maxEvictableIdleTimeMillis ,也会强行把它关闭,而不用判断空闲连接数是否小于 minIdle
其实前面的示例中设置了

获取 connect 的最大等待时长是 10000 毫秒,也就是 10 秒
而 removeAbandonedTimeout 设置是 7 秒
照理来说 connect 如果 7 秒未执行完 SQL 查询,就会被 Druid 强制回收进连接池,那么等待 10 秒应该能够获取到 connect ,为什么会抛出 GetConnectionTimeoutException 异常了?
这也就是文章标题中的超时设置问题
很显然,我们从 dataSource.init(); 开始跟源码
会看到如下一块代码

我们继续跟 createAndStartDestroyThread();

重点来了,我们看下 DestroyTask 到底是怎么样一个逻辑

我们接着跟进 removeAbandoned ,关键代码

如果 connect 正在运行中是不会被强制回收进连接池的
回到我们的示例,connect 都是在运行中,只是都在进行慢查询,所以是无法被强制回收进连接池的,那么其他线程自然在 maxWait 时间内无法获取到 connect
至此文章标题中的问题的原因就找到了
那么问题又来了: removeAbandonedTimeout 作用在哪?
我们再仔细阅读下:连接泄漏监测
Druid 提供了 RemoveAbandanded 相关配置,目的是监测连接泄露,回收那些长时间游离在连接池之外的空闲 connect
可能因为程序问题,导致申请的 connect 在处理完 sql 查询后,不能回到连接池的怀抱,那么这个 connect 处理游离态,它真实存在,但后续谁也申请不到它,这就是连接泄露
而 removeAbandoned 的设计就是为了帮助这些泄露的 connect 回到连接池的怀抱
开启 removeAbandoned 对性能有影响,官方不建议在生产环境使用
那么我们接受官方的建议,不开启 removeAbandoned (不配置即可,默认是关闭的)
为了不让慢查询占用整个连接池,而拖垮整个应用,我们设置查询超时时间 queryTimeout
有两种方式,一个是设置 DataSource 的 queryTimeout ,另一个是设置 JdbcTemplate 的 queryTimeout
如果两个都设置,最终生效的是哪个,为什么?大家自己去分析,权当是给大家留个一个作业
这里就配置 DataSource 的 queryTimeout ,给大家演示下效果
可以看到,所有线程都获取到了 connect
1、 Druid 的 removeAbandoned 对性能有影响,不建议开启
removeAbandoned 的开启后的作用要捋清楚,而非简单的过期强制回收
2、 Druid 的时间配置项有很多,不局限于文中所讲,但常用的就那么几个,其他的保持默认值就好
配置的时候一定要弄清楚各个配置项的具体作业,不要去猜!
3、查询超时 queryTimeout 即可在 DataSource 配置,也可在 JdbcTemplate 配置
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我需要检查DateTime是否采用有效的ISO8601格式。喜欢:#iso8601?我检查了ruby是否有特定方法,但没有找到。目前我正在使用date.iso8601==date来检查这个。有什么好的方法吗?编辑解释我的环境,并改变问题的范围。因此,我的项目将使用jsapiFullCalendar,这就是我需要iso8601字符串格式的原因。我想知道更好或正确的方法是什么,以正确的格式将日期保存在数据库中,或者让ActiveRecord完成它们的工作并在我需要时间信息时对其进行操作。 最佳答案 我不太明白你的问题。我假设您想检查
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url