目录
知识点:
1.基本Linux命令:
cd 改变目录
cd.. 回退到上一级目录,直接cd进入默认目录
ls(ll)都是列出当前目录中所有文件,只不过ll列出的内容更详细
touch 新建一个文件,touch index.js就会在当前目录下新建一个index.js文件
rm 删除一个文件,rm index.js就会把index.js文件删除
mkdir 新建一个目录,就是新建一个文件夹
rm -r 上出一个文件夹,rm -r src 删除src目录
mv 移动文件,mv index.html src index.html是我们要移动的文件,src是目标文件夹,当然,这样写必须在同一目录下
reset 重新初始化终端、清屏
clear 清屏
history 查看命令历史
help 帮助
exit 退出
# 表示注释

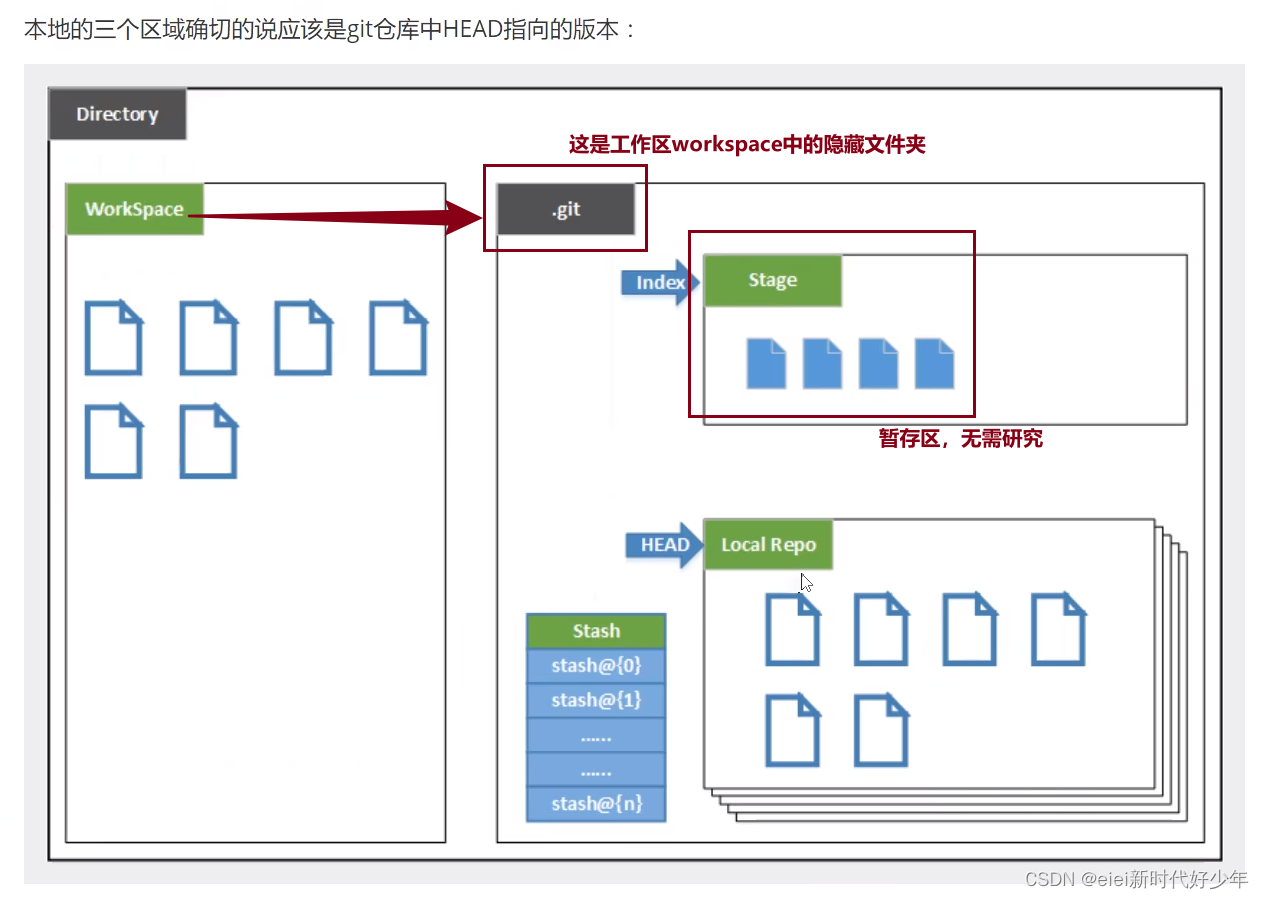
不用配置环境变量,环境变量只是用来可以全局使用。我们任意右键文件可以看git bash所以不用配置。










1.注册登录


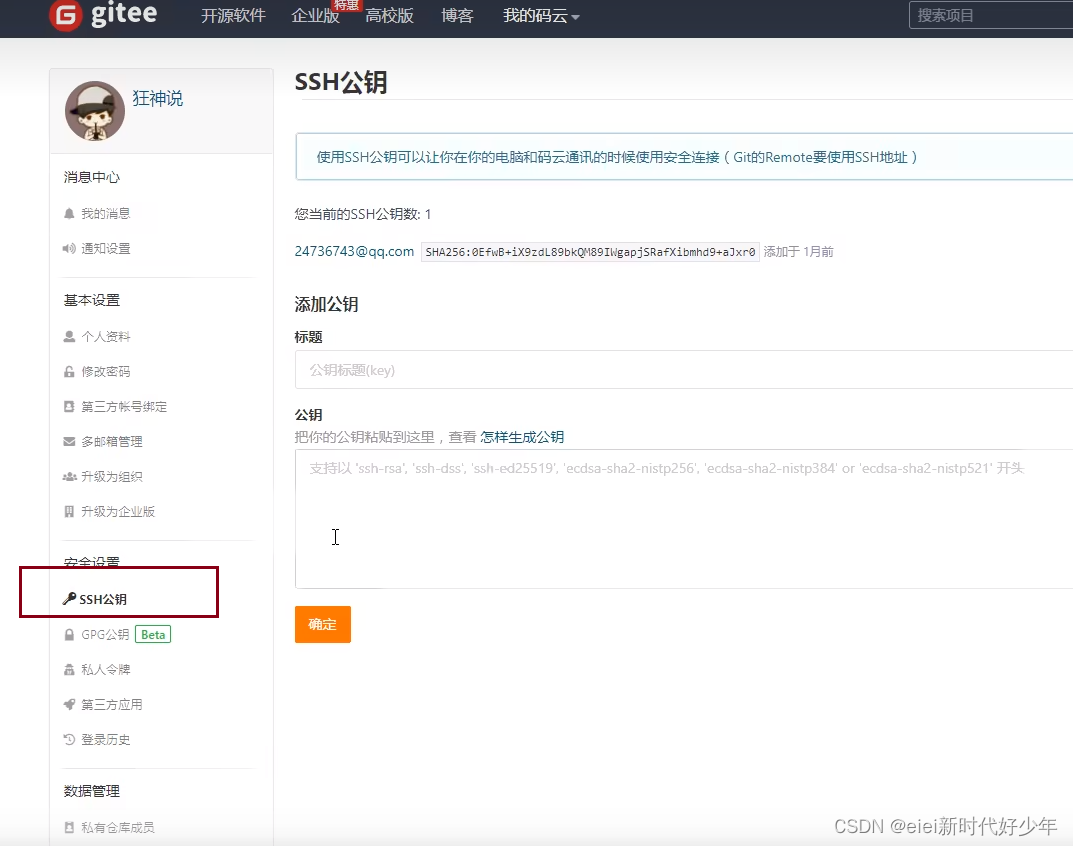
找到c盘的.ssh文件,目前文件是空的,在打开git bash,输入如下:



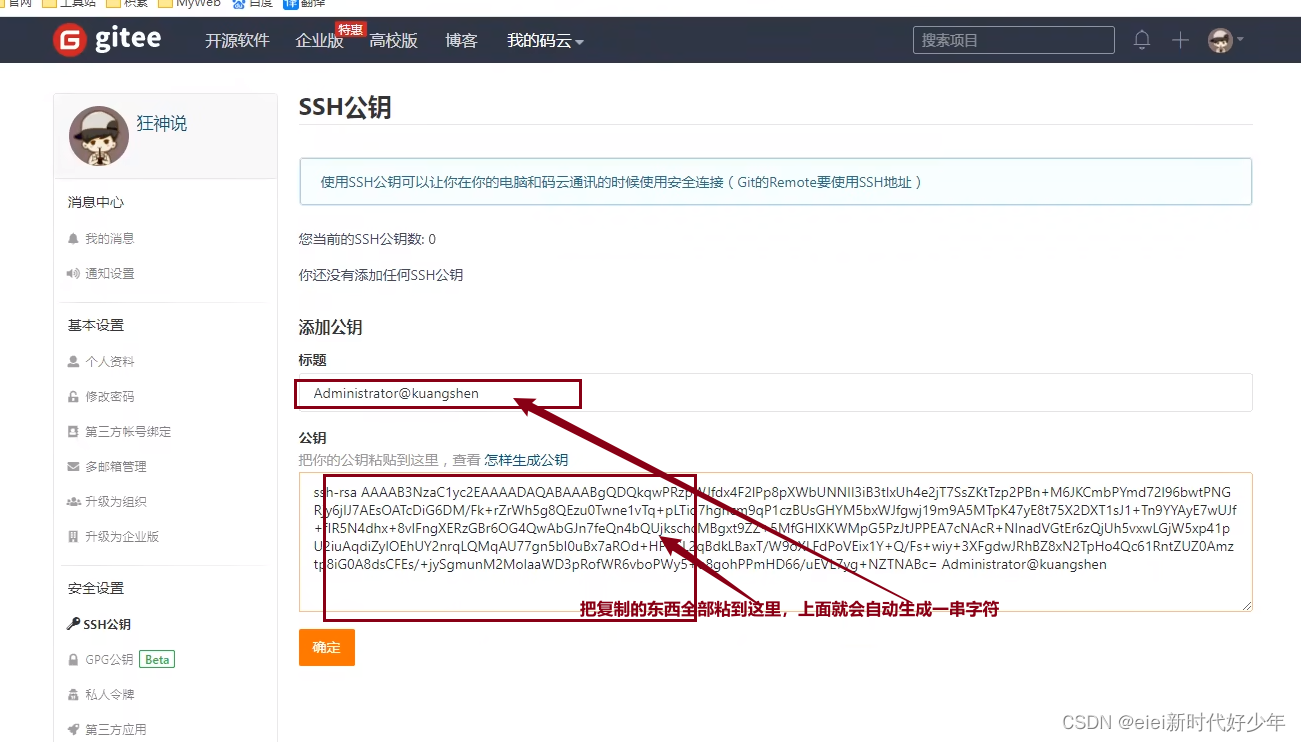
点击确定

 把远程仓库克隆到本地:
把远程仓库克隆到本地:


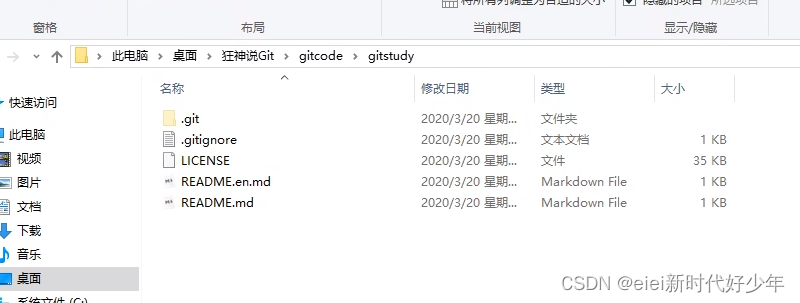






 点一下“提交”,弹出下面页面:
点一下“提交”,弹出下面页面: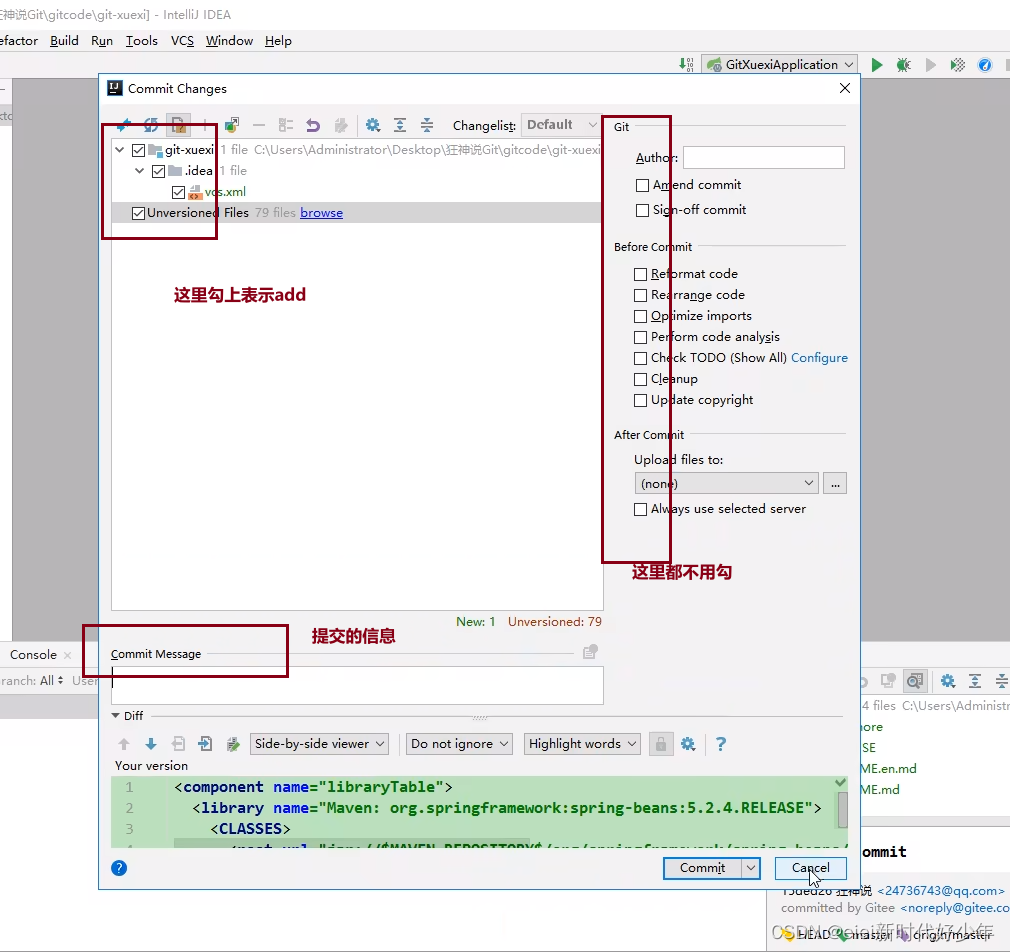
也可以手动进行add:
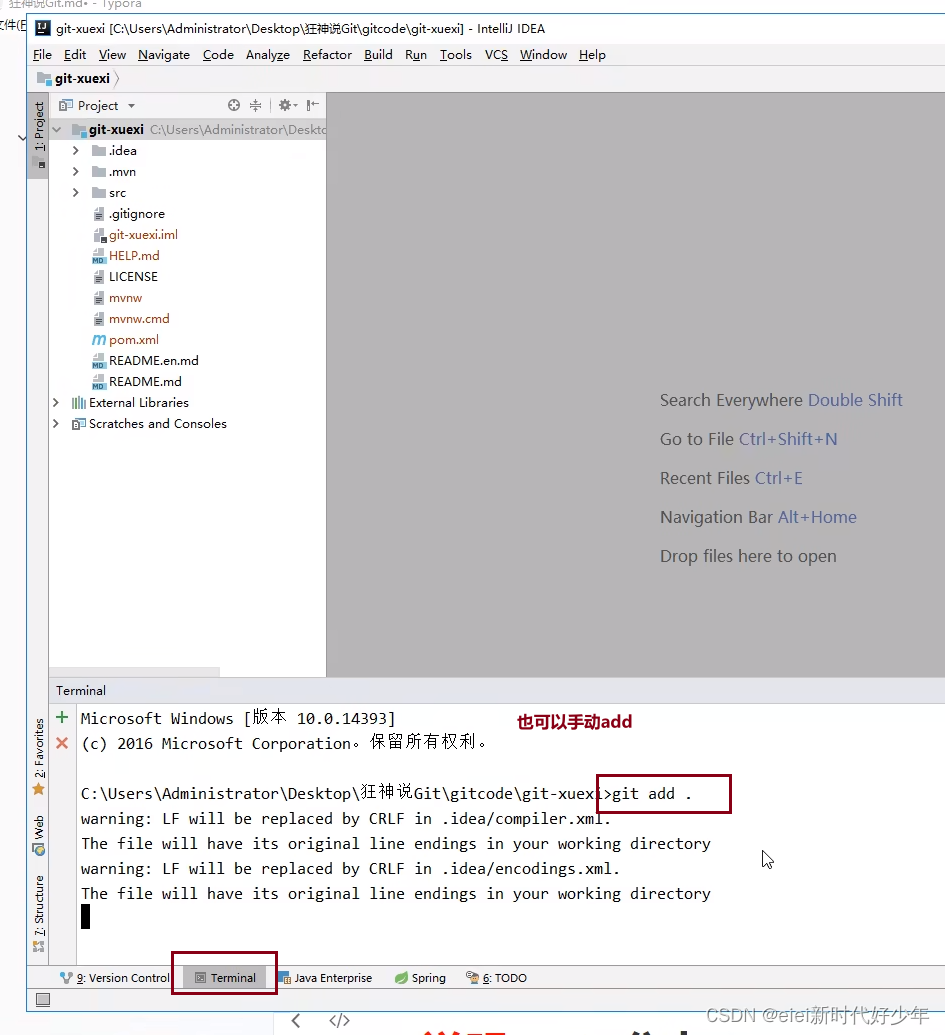

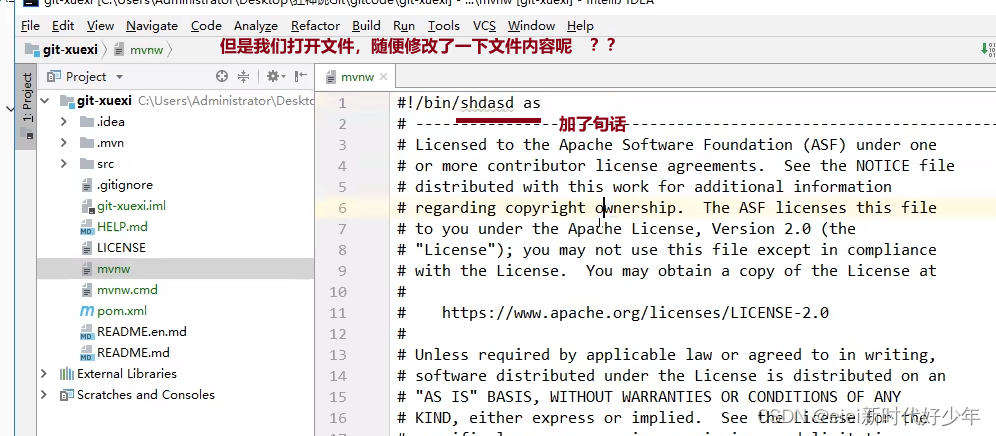




总步骤就是:









在github上拉下代码进行开发,具体步骤如下:
这里见大佬写的博客进行操作吧:Git的下载安装
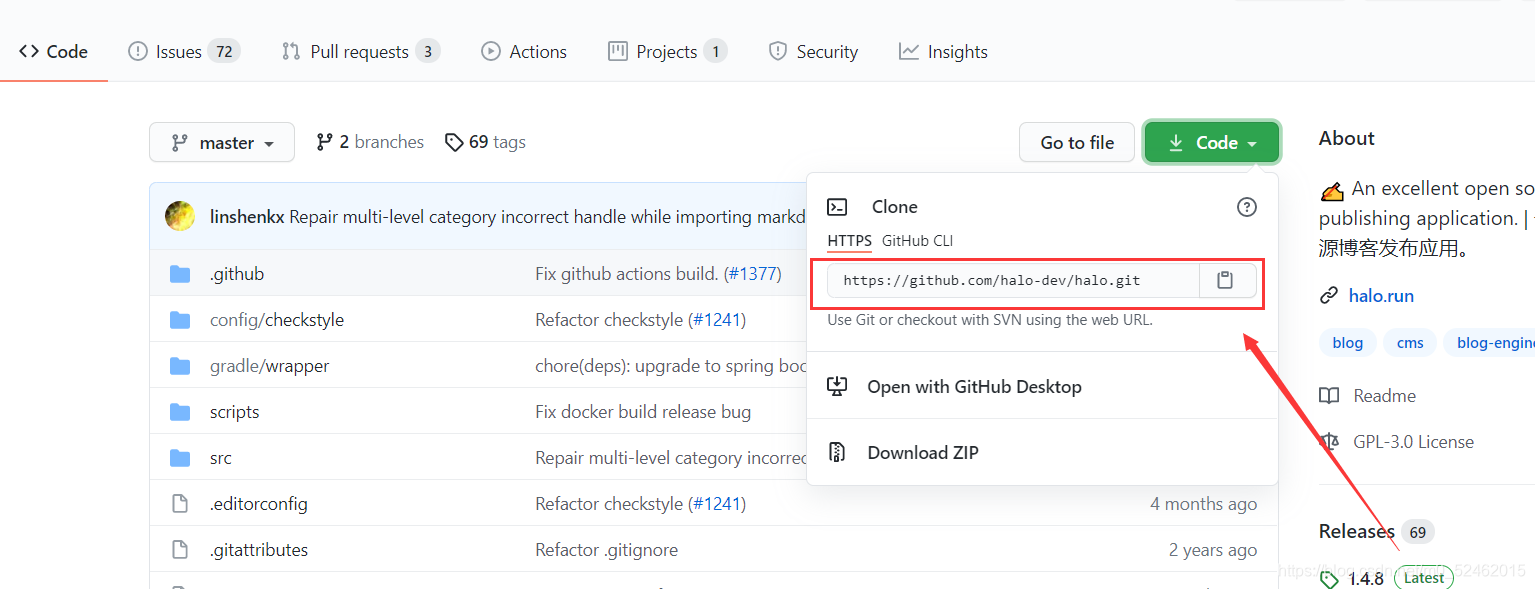
比如我在D盘创建,并且起名qdproduct:
在D盘:右键->新建文件夹

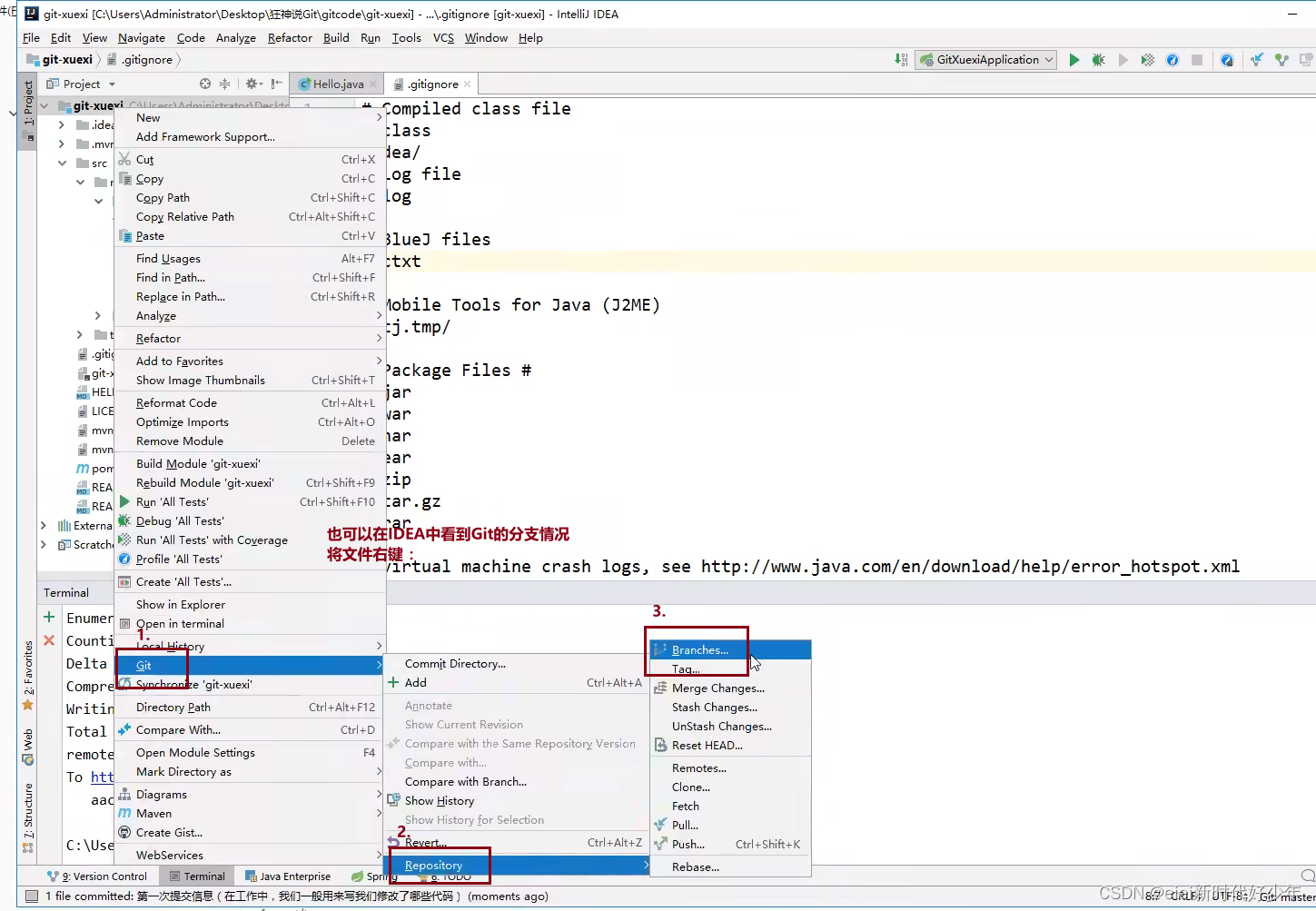
点开这个文件,在这个文件夹的空白处右键,如果你安装成功git,右键会出现下图的两个图标:

我们点击 Git Bash Here,输入下列命令:
git clone +刚刚复制的地址

这时,我们点开刚刚的qdproduct文件夹目录,就能发现文件夹里已经有了我们想要拉取的项目了!
在 Git Bash Here中输入:
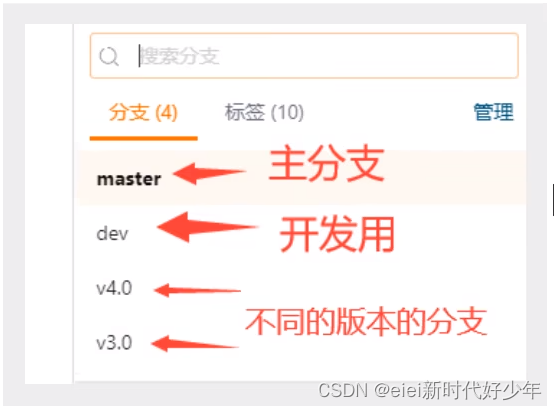
git branch (这个命令可以查看当前项目中的分支有哪些,会发现只有master分支,项目中都会有一个主分支,主分支就叫master)
再输入: git checkout -b panda (panda是自己随便起的分支的名字,这句表示创建了一个新的分支,分支名字为panda,你也可以叫lalaa什么的随便起名,解释:checkout 表示切换,这个命令可以切换到别的分支、-b表示创建的分支之前没有,这是个新的分支)
再输入: git branch 可以看到已经在panda分支上(标绿色,名字前面带*就是表示在哪个分支上)
接下来,我们启动项目程序,在Git Bash Here 依次输入:npm i -> npm run dev
比如我用vscode去打开我拉取的这部分代码,在上面进行修改,因为当前是在panda这个分支上修改的,修改完,会看到:
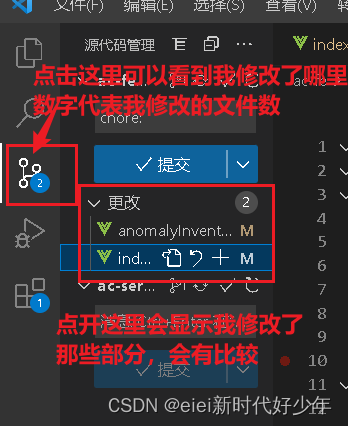
这时我们在终端中打开:

我们输入 cd D:qdproduct (cd命令是改变目录的意思,我们一定要到我们刚刚拉取代码的那个文件去执行之后的操作)
会看到我们会跳转到D:qdproduct的路径,然后输入:
git add .
git commit -m "init panda"
git push origin panda
这样我们就将代码提交到github上面了。

远程仓库中clone代码到本地:git clone 地址
新增文件命令:git add file 或者 git add .
提交文件命令:git commit -m 或者 git commit -a
本地仓库提交到远程仓库:git push
查看工作区状态:git status
拉取合并运程分支的操作:git fetch /git merge 或者 git pull
查看提交记录命令:git reflog
切换到主分支: git checkout master
通过git stash命令,把工作区的修改提交到栈区,目的是保存工作区的修改;
通过git pull命令,拉取远程分支上的代码合并到本地分支,目的消除冲突;
通过git stash pop命令,把保存的栈区的修改部分合并到最新的工作空间中。

git stash是把工作区修改的内容存储在栈区中
(1)解决冲突文件时,会先执行git stash,然后解决冲突;
(2)遇到紧急开发任务但目前不能提交时,会先执行git stash,然后进行紧急任务的开发,然后通过git stash pop取出栈区的内容继续开发;
(3)切换分支,当前工作内容不能提交时,会先执行git stash再进行分支切换
(1)查看分支的提交历史记录:
命令git log -number:查看当前分支前number个详细提交历史记录
命令git log -number -pretty=oneline:在上个命令的基础上进行简化,只显示sha-1码和提交信息;
命令git reflog -number:查看所有分支前number个简化的提交历史记录
命令git reflog -number -pretty=oneline:显示简化的信息历史信息
(2)如果要查看某文件的提交历史记录,直接在上面命令后面加上文件名即可。
注意:如果没有number则显示全部的提交次数
git pull命令从中央存储库中提取特定分支的新更改或提交,并更新本地存储库中的目标分支。
git fetch也是同样目的,但工作方式略有不同。当执行gitfetch时,它会从所需的分支中提取所有新提交,并将其存储在本地存储中的新分支中。如果要在目标分支中反映这些更改,必须在git fetch之后执行git merge,只有在对目标分支和获取的分支进行合并后才会更新目标分支。
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/