 池化,降低可重用对象的创建和回收代价。不知道你们发现没有,无论是电影还是游戏中,主角总是孤胆单英雄,最多三五成群。但Boss不一样,Boss手一挥,必须有一群小怪一拥而上,毕竟帮主角刷点经验也是好的。小怪的特点是:数量多,容易死,循环用。电影不可能请太多的群演,因此我们经常能发现一人分饰多角的超级龙套。而游戏里,也不可能每一个小怪都完全不一样,因为创建它们还挺消耗时间和内存的。哈哈,现在你知道了,你正在打的小怪很可能与刚刚死前掉金币的那只是同一只。代码中,如果某些对象有重用的价值,并且创建的时候会消耗大量的CPU或IO资源。那么在出现性能瓶颈的时候,一个合理的优化方向就是池化。刚刚例子中,对游戏中小怪进行池化,通常称为对象池,类似的还有线程池、连接池等。灰太狼:我一定会回来的~
池化,降低可重用对象的创建和回收代价。不知道你们发现没有,无论是电影还是游戏中,主角总是孤胆单英雄,最多三五成群。但Boss不一样,Boss手一挥,必须有一群小怪一拥而上,毕竟帮主角刷点经验也是好的。小怪的特点是:数量多,容易死,循环用。电影不可能请太多的群演,因此我们经常能发现一人分饰多角的超级龙套。而游戏里,也不可能每一个小怪都完全不一样,因为创建它们还挺消耗时间和内存的。哈哈,现在你知道了,你正在打的小怪很可能与刚刚死前掉金币的那只是同一只。代码中,如果某些对象有重用的价值,并且创建的时候会消耗大量的CPU或IO资源。那么在出现性能瓶颈的时候,一个合理的优化方向就是池化。刚刚例子中,对游戏中小怪进行池化,通常称为对象池,类似的还有线程池、连接池等。灰太狼:我一定会回来的~ 当年做游戏的时候,我见过很多人使用hash表存储场景中的各类对象:花鸟鱼虫、白云苍狗,并每帧遍历hash表以确定位置或攻击信息。我建议他们改成遍历有序表的快照(MVCC了解一下),其中一个原因是可以提高遍历性能,而另一个更重要的原因是可以在遍历的过程中修改表结构(插入删除对象)。有序表一种基于有序数组的字典结构,C#中有一个名为SortList的标准库实现多年以来,CPU一直是计算机中跑得最快的部件,也因此被惯出来一个多吃多占的毛病。无论是读内存还是读磁盘,从来不讲究按需分配,而是大块大块的拿数据。当把一大块连续的数据拿到手里的时候,CPU自己也知道一次肯定吞不下,但总觉得多吞几次就好了。但这个特点其实是需要程序员去配合的,如果代码使用连续内存的数据结构,比如array,那在遍历的时候就相当于投其所好;而如果代码使用hash表,则遍历的时候cache miss的可能性就大大增加。鉴于java在服务器领域的成功,有些公司使用java开发游戏服务器,我建议他们换一种语言。原因是游戏服务器很可能需要处理大量跟点、向量等三维空间相关的运算,而在java中,默认一切都是对象。于是在一个Vertex(顶点)数组中,看似连续的Vertex对象在物理内存中实际上是离散的,这样的遍历效果就会差很多。而对C++, Golang,甚至C#这类语言来说,它们都支持struct。当把Vertex定义为struct的时候,一个Vertex数组的占用的内存就是连续的,遍历效果会比java好很多。在后端的技术栈中,kafka绝对是一个非常另类的存在。擅长kafka的人,觉得无它不欢,而不了解它的人,则觉得可有可无。关于kafka为什么这么快的讨论有很多,其中有一个绕不过的原因是:kafka会顺序读写磁盘。我们通常认为磁盘的读写性能远低于内存,但实际上,在关闭fsync的前提下,SSD固态硬盘的顺序读写速度与内存的随机读写速度是相当的,大概都是1 GiB/s,而如果是随机读取,则SSD固态硬盘SSD的Seek速度会直降到70MiB/s,速度下降到1/15。
当年做游戏的时候,我见过很多人使用hash表存储场景中的各类对象:花鸟鱼虫、白云苍狗,并每帧遍历hash表以确定位置或攻击信息。我建议他们改成遍历有序表的快照(MVCC了解一下),其中一个原因是可以提高遍历性能,而另一个更重要的原因是可以在遍历的过程中修改表结构(插入删除对象)。有序表一种基于有序数组的字典结构,C#中有一个名为SortList的标准库实现多年以来,CPU一直是计算机中跑得最快的部件,也因此被惯出来一个多吃多占的毛病。无论是读内存还是读磁盘,从来不讲究按需分配,而是大块大块的拿数据。当把一大块连续的数据拿到手里的时候,CPU自己也知道一次肯定吞不下,但总觉得多吞几次就好了。但这个特点其实是需要程序员去配合的,如果代码使用连续内存的数据结构,比如array,那在遍历的时候就相当于投其所好;而如果代码使用hash表,则遍历的时候cache miss的可能性就大大增加。鉴于java在服务器领域的成功,有些公司使用java开发游戏服务器,我建议他们换一种语言。原因是游戏服务器很可能需要处理大量跟点、向量等三维空间相关的运算,而在java中,默认一切都是对象。于是在一个Vertex(顶点)数组中,看似连续的Vertex对象在物理内存中实际上是离散的,这样的遍历效果就会差很多。而对C++, Golang,甚至C#这类语言来说,它们都支持struct。当把Vertex定义为struct的时候,一个Vertex数组的占用的内存就是连续的,遍历效果会比java好很多。在后端的技术栈中,kafka绝对是一个非常另类的存在。擅长kafka的人,觉得无它不欢,而不了解它的人,则觉得可有可无。关于kafka为什么这么快的讨论有很多,其中有一个绕不过的原因是:kafka会顺序读写磁盘。我们通常认为磁盘的读写性能远低于内存,但实际上,在关闭fsync的前提下,SSD固态硬盘的顺序读写速度与内存的随机读写速度是相当的,大概都是1 GiB/s,而如果是随机读取,则SSD固态硬盘SSD的Seek速度会直降到70MiB/s,速度下降到1/15。 在系统设计之初,每次修改对应一次IO可能是最简单、最直接的设计,不过随着系统流量变大,IO可能会很快成为系统瓶颈。相比于内存操作来说,磁盘IO吞吐小,网络IO延迟大。为了减少IO与内存之间的速度差异,争取每次IO都物尽其用才是上上之选。将多次IO合并为一次,减少磁盘IO(特别是fsync)的次数和网络IO的round-trip次数。所谓读优化靠缓存,写优化靠缓冲,而分批≈缓存+缓冲。往小了说,缓存就是一块用于读内存,缓冲就是一块用于写的内存。往大了说,缓存就是Redis,缓冲就是Kafka。这些都是在微服务体系中司空见惯的招数,不用我多说。分批优化化身千万,可谓无孔不入,甚至多数流行的数据中间件都提供了批量IO操作的API:
在系统设计之初,每次修改对应一次IO可能是最简单、最直接的设计,不过随着系统流量变大,IO可能会很快成为系统瓶颈。相比于内存操作来说,磁盘IO吞吐小,网络IO延迟大。为了减少IO与内存之间的速度差异,争取每次IO都物尽其用才是上上之选。将多次IO合并为一次,减少磁盘IO(特别是fsync)的次数和网络IO的round-trip次数。所谓读优化靠缓存,写优化靠缓冲,而分批≈缓存+缓冲。往小了说,缓存就是一块用于读内存,缓冲就是一块用于写的内存。往大了说,缓存就是Redis,缓冲就是Kafka。这些都是在微服务体系中司空见惯的招数,不用我多说。分批优化化身千万,可谓无孔不入,甚至多数流行的数据中间件都提供了批量IO操作的API: 随着77年恢复高考,这些年近视的年轻人越来越多了,于是人们越发的无法区分那些换个马夹儿就重新出来混的二货们。就像洗发水,猛一看飘柔、海飞丝、潘婷百花齐放,仔细一看,全特么是宝洁的。没错,这么土味的名字,竟然不是国货,害我自以为爱了这么多年的国。分片、分区、分库、分表也一样,名字挺花,疗效一样,都是为了突破单体性能限制的水平扩展的方案,洋名字:scale out。因为方案类似,大家遇到的问题自然也是相同的。它们首先要搞定的就是路由问题,也就是把数据拆分之后,某个key储存到哪个分片/区/库/表的问题。路由方案可简单分为两类:一种是非确定性路由,即相同的key多次路由可以映射到的不同的计算单元,常见方案有:轮询、随机。非确定性路由多用于无状态节点间的任务分配,比如nginx把请求随机分配到无状态的微服务节点上。另一种是确定性路由,即相同的key多次路由必须映射到的相同的存储单元,常见方案为:区间,Hash,配置表。确定性路由多用于有状态节点间的任务分配,比如Kafka按user_id把来自同一用户的请求映射到同一个存储分区。以MySQL为例,它支持四种分区类型,分别是Range, List, Hash, Key。因为跟存储密切相关,它们全是确定性路由算法,其中Range对应区间,List是配置表,Hash与Key则都是Hash类型。除了应用于多机水平扩展,在单机内存中分片方案也有应用。比如JDK1.8之前,ConcurrentHashMap通过将整个Map划分成N(默认16个)个Segment,而每个Segment各自持有独立的锁,从而从整体上减少并发冲突。
随着77年恢复高考,这些年近视的年轻人越来越多了,于是人们越发的无法区分那些换个马夹儿就重新出来混的二货们。就像洗发水,猛一看飘柔、海飞丝、潘婷百花齐放,仔细一看,全特么是宝洁的。没错,这么土味的名字,竟然不是国货,害我自以为爱了这么多年的国。分片、分区、分库、分表也一样,名字挺花,疗效一样,都是为了突破单体性能限制的水平扩展的方案,洋名字:scale out。因为方案类似,大家遇到的问题自然也是相同的。它们首先要搞定的就是路由问题,也就是把数据拆分之后,某个key储存到哪个分片/区/库/表的问题。路由方案可简单分为两类:一种是非确定性路由,即相同的key多次路由可以映射到的不同的计算单元,常见方案有:轮询、随机。非确定性路由多用于无状态节点间的任务分配,比如nginx把请求随机分配到无状态的微服务节点上。另一种是确定性路由,即相同的key多次路由必须映射到的相同的存储单元,常见方案为:区间,Hash,配置表。确定性路由多用于有状态节点间的任务分配,比如Kafka按user_id把来自同一用户的请求映射到同一个存储分区。以MySQL为例,它支持四种分区类型,分别是Range, List, Hash, Key。因为跟存储密切相关,它们全是确定性路由算法,其中Range对应区间,List是配置表,Hash与Key则都是Hash类型。除了应用于多机水平扩展,在单机内存中分片方案也有应用。比如JDK1.8之前,ConcurrentHashMap通过将整个Map划分成N(默认16个)个Segment,而每个Segment各自持有独立的锁,从而从整体上减少并发冲突。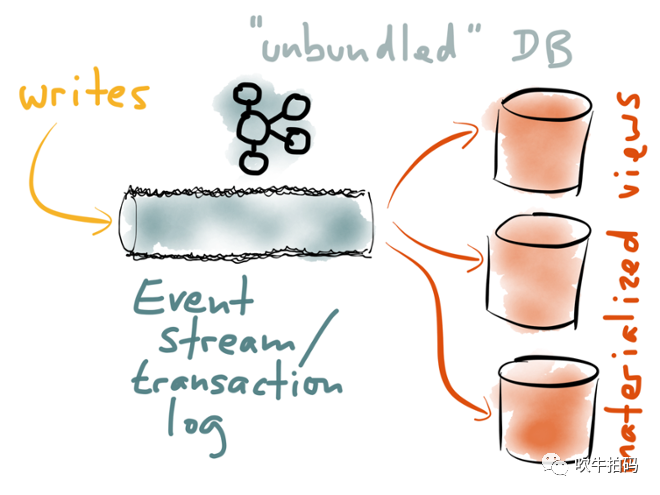 这里我想强调的是,读写分离是分离式DB(Unbunding Databases)的雏形。我们应该认识到,不存在一种单一的数据模型可以满足所有的访问模式。MySQL在线业务、Redis加速查询、ES全文索引、DW离线分析,每一种衍生数据系统都有各自不可替代作用。如上图所示,通过统一写端,派生读端,可以形成一种遵循unix传统的架构模型:单一任务做好单一事情,内部通过低级API(pipe)通信,外部通过高级语言(shell)组合。在分离式DB架构中,目前看来最合适的,能起到粘接剂作用的是Event Stream(Event Log)。期望未来有那么一天,我们能像在shell中写ps | grep java一样,写出mysql | elasticsearch这样的代码,届时就是分离式DB摘取王之桂冠的荣耀时刻。如果说读写分离是拆功能,那么存算分离就是拆资源:把计算资源(CPU、内存)和存储资源(磁盘)拆分开来。早期的云DB,其实是把单体DB搬到云上。人们很快发现云DB与单机DB的不同之处:一是随着企业数字化转型的深入,数量总量飙升,单机存储捉襟见肘;二是在应对双十一这类突发性流量时,计算峰值波动很大,这使得云DB对弹性伸缩能力要求极高。问题一可以通过分库分表这类trick的方式缓解,但问题二对原有单体DB『存算一体』的架构提出了挑战。于是,存算分离的架构应运而生,也就是云原生数据库架构。
这里我想强调的是,读写分离是分离式DB(Unbunding Databases)的雏形。我们应该认识到,不存在一种单一的数据模型可以满足所有的访问模式。MySQL在线业务、Redis加速查询、ES全文索引、DW离线分析,每一种衍生数据系统都有各自不可替代作用。如上图所示,通过统一写端,派生读端,可以形成一种遵循unix传统的架构模型:单一任务做好单一事情,内部通过低级API(pipe)通信,外部通过高级语言(shell)组合。在分离式DB架构中,目前看来最合适的,能起到粘接剂作用的是Event Stream(Event Log)。期望未来有那么一天,我们能像在shell中写ps | grep java一样,写出mysql | elasticsearch这样的代码,届时就是分离式DB摘取王之桂冠的荣耀时刻。如果说读写分离是拆功能,那么存算分离就是拆资源:把计算资源(CPU、内存)和存储资源(磁盘)拆分开来。早期的云DB,其实是把单体DB搬到云上。人们很快发现云DB与单机DB的不同之处:一是随着企业数字化转型的深入,数量总量飙升,单机存储捉襟见肘;二是在应对双十一这类突发性流量时,计算峰值波动很大,这使得云DB对弹性伸缩能力要求极高。问题一可以通过分库分表这类trick的方式缓解,但问题二对原有单体DB『存算一体』的架构提出了挑战。于是,存算分离的架构应运而生,也就是云原生数据库架构。 存算分离听起来很云端,似乎跟我们平时的工作关系很小。但其实有一类架构它就在我们身边,只是我们可能没有意识到它也是存算分离架构,那就是微服务架构。计算节点无状态,存储节点无计算;计算节点横向扩展,存储节点纵向扩展。就像Duck Test讲的:如果它看起来像鸭子、游泳像鸭子、叫声像鸭子,那么它可能就是只鸭子。
存算分离听起来很云端,似乎跟我们平时的工作关系很小。但其实有一类架构它就在我们身边,只是我们可能没有意识到它也是存算分离架构,那就是微服务架构。计算节点无状态,存储节点无计算;计算节点横向扩展,存储节点纵向扩展。就像Duck Test讲的:如果它看起来像鸭子、游泳像鸭子、叫声像鸭子,那么它可能就是只鸭子。我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=