依赖注入 (Dependency Injection, DI) 是 Spring 实现控制反转概念的重要手段。 Spring 提供了多种依赖注入方式,其中最方便、最常用的是 field injection,它应该是许多人第一次写 Spring 项目时所使用的模式,虽然这方式简单易用,却有不少缺点。
例如你会发现, IntelliJ IDEA 会很贴心地告诉我们:
Field Injection is not recommended.
Spring Team recommends: “Always use constructor based dependency
injection in tour beans. Always use assertions for mandatory
dependencies”.
为何 constructor injection 优于 field injection 呢? 接下来我会解析这两种模式。 (虽然 Spring 还有其他种注入方式,但我比较不常用,所以就不在此介绍了)
这种注入方式顾名思义,就是直接在 field 加上 @Autowired
@Component
public class HelloBean {
@Autowired private AnotherBean anotherBean;
@Autowired private AnotherBean2 anotherBean2;
// ...
@RunWith(MockitoJUnitRunner.class)
public class HelloBeanTest {
@Mock
private AnotherBean anotherBean;
@Mock
private AnotherBean2 anotherBean2;
...
@Mock
private AnotherBean10 anotherBean10;
@InjectMocks
private HelloBean helloBean;
@Before
public void setup() {
...
}
// Test cases...
}
这是相当常见的 Mockito+Junit 单元测试写法,但容易造成疑问:
只有短短几行就让人产生诸多疑问,因此理解成本较高。 虽然这种注入方式很简单方便,但写单元测试时就得还债了。 若使用 constructor injection 则不易产生此问题,我们接着看下去:
此方式最大的特点是: Bean 的建立与依赖的注入是同时发生的
@Component
public class HelloBean {
private final AnotherBean anotherBean;
private final AnotherBean2 anotherBean2;
// ...
@Autowired
public HelloBean(AnotherBean anotherBean, AnotherBean2 anotherBean2, ...) {
this.anotherBean = anotherBean;
this.anotherBean2 = anotherBean2;
// ...
}
// ...
}
假设我们需要注入十几个 dependecies,对比 field injection 的方式,这种方式暴露了 constructor 中含有过多的参数 (Long Parameter List),这是个很好的臭味侦测器,正常的开发者看到这么多参数肯定是会头痛的,这就表示我们需要想办法重构它,尽可能使它符合单一职责原则 ( Single Responsibility Principle)。
一看到 constructor 就可以让开发者厘清这个物件所需要的 dependency,且缺一不可,进而缩小该物件在项目中的使用范围,事物的范围越窄,就越容易理解与维护。 另外,我们也可以透过 constructor 注入假的依赖,进而容易写单元测试。
一个简单的范例:
public class HelloBeanTest {
private HelloBean helloBean;
@Before
public void setup() {
AnotherBean anotherBean = mock(AnotherBean.class);
AnotherBean2 anotherBean2 = mock(AnotherBean2.class);
// ...
helloBean = new HelloBean(anotherBean, anotherBean2, ...);
}
// Test cases...
}
相较前面的例子,这种注入方式不需要太多 @Annotation,让测试程式码看起来更干净了,我们也能轻松的用 来实体化待测对象、注入假依赖,整体而言看起来更 清楚、好理解,就算是不熟 Java 或 Mockito 的开发人员应该也能看得懂七八成,对于新人也比较好上手,而且也比较不会有误用 @Annotation 所产生额外成本 ,优秀的单元测试就应该如此。new
意思是 Bean 在被创造之后,它的内部 state, field 就无法被改变了。 不可变意味着只读,因而具备线程安全(Thread-safety)的特性。 此外,相较于可变对象,不可变对象在一些场合下也较合理、易于了解,而且提供较高的安全性,是个良好的设计。 因此,透过 constructor injection,再把依赖宣都告成 final,就可以轻松建立 Immutable Object。
只有在使用 constructor injection 时才会造成此问题。
举个简单的例子,若依赖关系图: Bean C → Bean B → Bean A → Bean C ,则会造成造成此问题,程序在 Runtime 会抛出,更白话来说,这就是鸡生蛋 / 蛋生鸡的问题,而 Spring 容器初始化时无法解决这样的窘境,因此抛出例外并中断程序。BeanCurrentlyInCreationException
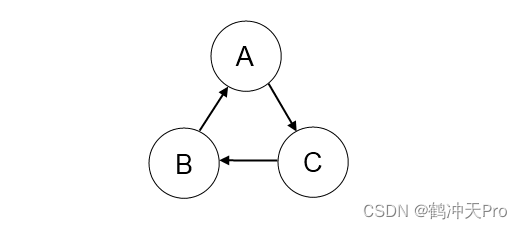
但是,Circular dependency 其实算是一种 Anti-Pattern,所以如果能够实时发现它,提早让开发人员意识到该问题重新设计此 bean,我个人认为这点反而蛮好的。
本文介绍了两种依赖注入模式,它们各有好坏,也都能达到同样的目的,而比较常见的是 field injection,但不幸的这种方式较可能会写出 code smell。 另外,Spring 官方团队建议开发者使用 constructor injection,虽然可能会有循环依赖异常,但无论在开发、测试方面,总体而言都是利大于弊,我也一直遵循这个模式。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我正在使用Ruby2.1.1和Rails4.1.0.rc1。当执行railsc时,它被锁定了。使用Ctrl-C停止,我得到以下错误日志:~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`gets':Interruptfrom~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`verify_server_version'from~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.
我正在尝试修改当前依赖于定义为activeresource的gem:s.add_dependency"activeresource","~>3.0"为了让gem与Rails4一起工作,我需要扩展依赖关系以与activeresource的版本3或4一起工作。我不想简单地添加以下内容,因为它可能会在以后引起问题:s.add_dependency"activeresource",">=3.0"有没有办法指定可接受版本的列表?~>3.0还是~>4.0? 最佳答案 根据thedocumentation,如果你想要3到4之间的所有版本,你可以这
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
转自:spring.profiles.active和spring.profiles.include的使用及区别说明下文笔者讲述spring.profiles.active和spring.profiles.include的区别简介说明,如下所示我们都知道,在日常开发中,开发|测试|生产环境都拥有不同的配置信息如:jdbc地址、ip、端口等此时为了避免每次都修改全部信息,我们则可以采用以上的属性处理此类异常spring.profiles.active属性例:配置文件,可使用以下方式定义application-${profile}.properties开发环境配置文件:application-dev
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl
我今天看到了一个ruby代码片段。[1,2,3,4,5,6,7].inject(:+)=>28[1,2,3,4,5,6,7].inject(:*)=>5040这里的注入(inject)和之前看到的完全不一样,比如[1,2,3,4,5,6,7].inject{|sum,x|sum+x}请解释一下它是如何工作的? 最佳答案 没有魔法,符号(方法)只是可能的参数之一。这是来自文档:#enum.inject(initial,sym)=>obj#enum.inject(sym)=>obj#enum.inject(initial){|mem