想象一下遇到下面的场景你会如何处理:
手机号是否重复注册
用户是否参与过某秒杀活动
伪造请求大量 id 查询不存在的记录,此时缓存未命中,如何避免缓存穿透
针对以上问题常规做法是:查询数据库,数据库硬扛,如果压力并不大可以使用此方法,保持简单即可。
改进做法:用 list/set/tree 维护一个元素集合,判断元素是否在集合内,时间复杂度或空间复杂度会比较高。如果是微服务的话可以用 redis 中的 list/set 数据结构, 数据规模非常大此方案的内存容量要求可能会非常高。
这些场景有个共同点,可以将问题抽象为:如何高效判断一个元素不在集合中? 那么有没有一种更好方案能达到时间复杂度和空间复杂双优呢?
有!布隆过滤器。
布隆过滤器(英语:Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中,它的优点是空间效率和查询时间都远远超过一般的算法。
工作原理
布隆过滤器的原理是,当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组中的 K 个点(offset),把它们置为 1。检索时,我们只要看看这些点是不是都是 1 就(大约)知道集合中有没有它了:如果这些点有任何一个 0,则被检元素一定不在;如果都是 1,则被检元素很可能在。这就是布隆过滤器的基本思想。
简单来说就是准备一个长度为 m 的位数组并初始化所有元素为 0,用 k 个散列函数对元素进行 k 次散列运算跟 len(m)取余得到 k 个位置并将 m 中对应位置设置为 1。
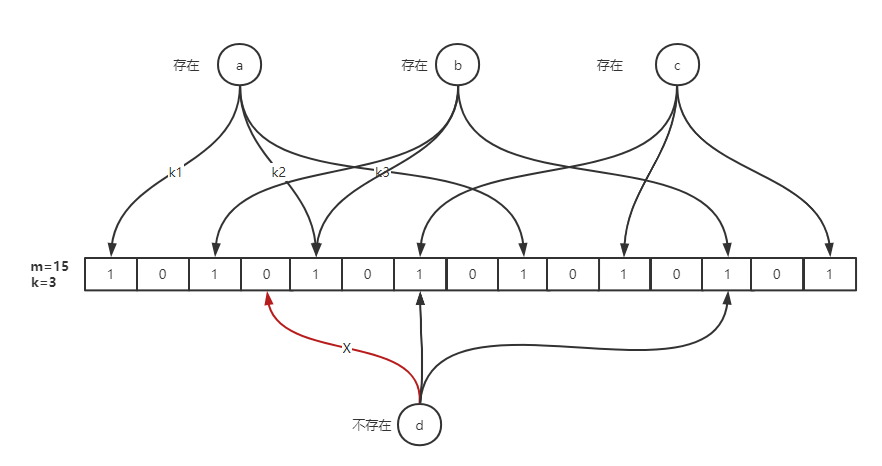
优点:
空间占用极小,因为本身不存储数据而是用比特位表示数据是否存在,某种程度有保密的效果。
插入与查询时间复杂度均为 O(k),常数级别,k 表示散列函数执行次数。
散列函数之间可以相互独立,可以在硬件指令层加速计算。
缺点:
误差(假阳性率)。
无法删除。
误差(假阳性率)
布隆过滤器可以 100% 判断元素不在集合中,但是当元素在集合中时可能存在误判,因为当元素非常多时散列函数产生的 k 位点可能会重复。 维基百科有关于假阳性率的数学推导(见文末链接)这里我们直接给结论(实际上是我没看懂...),假设:
位数组长度 m
散列函数个数 k
预期元素数量 n
期望误差_ε_
在创建布隆过滤器时我们为了找到合适的 m 和 k ,可以根据预期元素数量 n 与 ε 来推导出最合适的 m 与 k 。
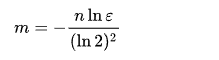
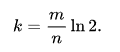
java 中 Guava, Redisson 实现布隆过滤器估算最优 m 和 k 采用的就是此算法:
// 计算哈希次数
@VisibleForTesting
static int optimalNumOfHashFunctions(long n, long m) {
// (m / n) * log(2), but avoid truncation due to division!
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
// 计算位数组长度
@VisibleForTesting
static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
无法删除
位数组中的某些 k 点是多个元素重复使用的,假如我们将其中一个元素的 k 点全部置为 0 则直接就会影响其他元素。 这导致我们在使用布隆过滤器时无法处理元素被删除的场景。
可以通过定时重建的方式清除脏数据。假如是通过 redis 来实现的话重建时不要直接删除原有的 key,而是先生成好新的再通过 rename 命令即可,再删除旧数据即可。
core/bloom/bloom.go 一个布隆过滤器具备两个核心属性:
位数组:
散列函数
go-zero实现的bloom filter中位数组采用的是Redis.bitmap,既然采用的是 redis 自然就支持分布式场景,散列函数采用的是MurmurHash3
Redis.bitmap 为什么可以作为位数组呢?
Redis 中的并没有单独的 bitmap 数据结构,底层使用的是动态字符串(SDS)实现,而 Redis 中的字符串实际都是以二进制存储的。 a 的ASCII码是 97,转换为二进制是:01100001,如果我们要将其转换为b只需要进一位即可:01100010。下面通过Redis.setbit实现这个操作:
set foo a
OK
get foo
"a"
setbit foo 6 1
0
setbit foo 7 0
1
get foo
"b"
bitmap 底层使用的动态字符串可以实现动态扩容,当 offset 到高位时其他位置 bitmap 将会自动补 0,最大支持 2^32-1 长度的位数组(占用内存 512M),需要注意的是分配大内存会阻塞Redis进程。 根据上面的算法原理可以知道实现布隆过滤器主要做三件事情:
k 次散列函数计算出 k 个位点。
插入时将位数组中 k 个位点的值设置为 1。
查询时根据 1 的计算结果判断 k 位点是否全部为 1,否则表示该元素一定不存在。
下面来看看go-zero 是如何实现的:
对象定义
// 表示经过多少散列函数计算
// 固定14次
maps = 14
type (
// 定义布隆过滤器结构体
Filter struct {
bits uint
bitSet bitSetProvider
}
// 位数组操作接口定义
bitSetProvider interface {
check([]uint) (bool, error)
set([]uint) error
}
)
位数组操作接口实现
首先需要理解两段 lua 脚本:
// ARGV:偏移量offset数组
// KYES[1]: setbit操作的key
// 全部设置为1
setScript = `
for _, offset in ipairs(ARGV) do
redis.call("setbit", KEYS[1], offset, 1)
end
`
// ARGV:偏移量offset数组
// KYES[1]: setbit操作的key
// 检查是否全部为1
testScript = `
for _, offset in ipairs(ARGV) do
if tonumber(redis.call("getbit", KEYS[1], offset)) == 0 then
return false
end
end
return true
`
为什么一定要用 lua 脚本呢? 因为需要保证整个操作是原子性执行的。
// redis位数组
type redisBitSet struct {
store *redis.Client
key string
bits uint
}
// 检查偏移量offset数组是否全部为1
// 是:元素可能存在
// 否:元素一定不存在
func (r *redisBitSet) check(offsets []uint) (bool, error) {
args, err := r.buildOffsetArgs(offsets)
if err != nil {
return false, err
}
// 执行脚本
resp, err := r.store.Eval(testScript, []string{r.key}, args)
// 这里需要注意一下,底层使用的go-redis
// redis.Nil表示key不存在的情况需特殊判断
if err == redis.Nil {
return false, nil
} else if err != nil {
return false, err
}
exists, ok := resp.(int64)
if !ok {
return false, nil
}
return exists == 1, nil
}
// 将k位点全部设置为1
func (r *redisBitSet) set(offsets []uint) error {
args, err := r.buildOffsetArgs(offsets)
if err != nil {
return err
}
_, err = r.store.Eval(setScript, []string{r.key}, args)
// 底层使用的是go-redis,redis.Nil表示操作的key不存在
// 需要针对key不存在的情况特殊判断
if err == redis.Nil {
return nil
} else if err != nil {
return err
}
return nil
}
// 构建偏移量offset字符串数组,因为go-redis执行lua脚本时参数定义为[]stringy
// 因此需要转换一下
func (r *redisBitSet) buildOffsetArgs(offsets []uint) ([]string, error) {
var args []string
for _, offset := range offsets {
if offset >= r.bits {
return nil, ErrTooLargeOffset
}
args = append(args, strconv.FormatUint(uint64(offset), 10))
}
return args, nil
}
// 删除
func (r *redisBitSet) del() error {
_, err := r.store.Del(r.key)
return err
}
// 自动过期
func (r *redisBitSet) expire(seconds int) error {
return r.store.Expire(r.key, seconds)
}
func newRedisBitSet(store *redis.Client, key string, bits uint) *redisBitSet {
return &redisBitSet{
store: store,
key: key,
bits: bits,
}
}
到这里位数组操作就全部实现了,接下来看下如何通过 k 个散列函数计算出 k 个位点
k 次散列计算出 k 个位点
// k次散列计算出k个offset
func (f *Filter) getLocations(data []byte) []uint {
// 创建指定容量的切片
locations := make([]uint, maps)
// maps表示k值,作者定义为了常量:14
for i := uint(0); i < maps; i++ {
// 哈希计算,使用的是"MurmurHash3"算法,并每次追加一个固定的i字节进行计算
hashValue := hash.Hash(append(data, byte(i)))
// 取下标offset
locations[i] = uint(hashValue % uint64(f.bits))
}
return locations
}
插入与查询
添加与查询实现就非常简单了,组合一下上面的函数就行。
// 添加元素
func (f *Filter) Add(data []byte) error {
locations := f.getLocations(data)
return f.bitSet.set(locations)
}
// 检查是否存在
func (f *Filter) Exists(data []byte) (bool, error) {
locations := f.getLocations(data)
isSet, err := f.bitSet.check(locations)
if err != nil {
return false, err
}
if !isSet {
return false, nil
}
return true, nil
}
整体实现非常简洁高效,那么有没有改进的空间呢?
个人认为还是有的,上面提到过自动计算最优 m 与 k 的数学公式,如果创建参数改为:
预期总数量expectedInsertions
期望误差falseProbability
就更好了,虽然作者注释里特别提到了误差说明,但是实际上作为很多开发者对位数组长度并不敏感,无法直观知道 bits 传多少预期误差会是多少。
// New create a Filter, store is the backed redis, key is the key for the bloom filter,
// bits is how many bits will be used, maps is how many hashes for each addition.
// best practices:
// elements - means how many actual elements
// when maps = 14, formula: 0.7*(bits/maps), bits = 20*elements, the error rate is 0.000067 < 1e-4
// for detailed error rate table, see http://pages.cs.wisc.edu/~cao/papers/summary-cache/node8.html
func New(store *redis.Redis, key string, bits uint) *Filter {
return &Filter{
bits: bits,
bitSet: newRedisBitSet(store, key, bits),
}
}
// expectedInsertions - 预期总数量
// falseProbability - 预期误差
// 这里也可以改为option模式不会破坏原有的兼容性
func NewFilter(store *redis.Redis, key string, expectedInsertions uint, falseProbability float64) *Filter {
bits := optimalNumOfBits(expectedInsertions, falseProbability)
k := optimalNumOfHashFunctions(bits, expectedInsertions)
return &Filter{
bits: bits,
bitSet: newRedisBitSet(store, key, bits),
k: k,
}
}
// 计算最优哈希次数
func optimalNumOfHashFunctions(m, n uint) uint {
return uint(math.Round(float64(m) / float64(n) * math.Log(2)))
}
// 计算最优数组长度
func optimalNumOfBits(n uint, p float64) uint {
return uint(float64(-n) * math.Log(p) / (math.Log(2) * math.Log(2)))
}
如何预防非法 id 导致缓存穿透?
由于 id 不存在导致请求无法命中缓存流量直接打到数据库,同时数据库也不存在该记录导致无法写入缓存,高并发场景这无疑会极大增加数据库压力。 解决方案有两种:
采用布隆过滤器
数据写入数据库时需同步写入布隆过滤器,同时如果存在脏数据场景(比如:删除)则需要定时重建布隆过滤器,使用 redis 作为存储时不可以直接删除 bloom.key,可以采用 rename key 的方式更新 bloom
缓存与数据库同时无法命中时向缓存写入一个过期时间较短的空值。
布隆过滤器(Bloom Filter)原理及 Guava 中的具体实现
https://github.com/zeromicro/go-zero
欢迎使用 go-zero 并 star 支持我们!
关注『微服务实践』公众号并点击 交流群 获取社区群二维码。
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
我有一个名为Post的类,我需要能够适应以下场景:如果用户选择了一个类别,则只显示该类别的帖子如果用户选择了一种类型,则只显示该类型的帖子如果用户选择了一个类别和类型,则只显示该类别中该类型的帖子如果用户没有选择任何内容,则显示所有帖子我想知道我的Controller是否不可避免地会因大量条件语句而显得粗糙...这是我解决此问题的错误方法-有谁知道我如何才能做到这一点?classPostsController 最佳答案 您最好遵循“胖模型,瘦Controller”的惯例,这意味着您应该将这种逻辑放在模型本身中。Post类应该能够报告
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
我仍然收到标题中的“错误”消息,但不知道如何解决。在ApplicationController中,classApplicationController在routes.rb#match'set_activity_account/:id/:value'=>'users#account_activity',:as=>:set_activity_account--thisdoesn'tworkaswell..resources:usersdomemberdoget:action_a,:action_bendcollectiondoget'account_activity'endend和User
对于用户模型,我有一个过滤器来检查用户的预订状态,该状态由整数值(0、1或2)表示。UserActiveAdmin索引页上的过滤器是通过以下代码实现的:filter:booking_status,as::select然而,这会导致下拉选项为0、1或2。当管理员用户从下拉列表中选择它们时,我更愿意自己将它们命名为“未完成”、“待定”和“已确认”之类的名称。有没有办法在不改变booking_status在模型中的表示方式的情况下做到这一点? 最佳答案 假设booking_status是模型中的枚举字段,您可以使用:过滤器:booking
这个问题有两个部分。在RubyProgrammingLanguage一书中,有一个使用模块扩展字符串对象和类的示例(第8.1.1节)。第一个问题。为什么如果您使用新方法扩展类,然后创建该类的对象/实例,则无法访问该方法?irb(main):001:0>moduleGreeter;defciao;"Ciao!";end;end=>nilirb(main):002:0>String.extend(Greeter)=>Stringirb(main):003:0>String.ciao=>"Ciao!"irb(main):004:0>x="foobar"=>"foobar"irb(main):
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
以下模型通过belongs_to链接:require'mongoid'classSensorincludeMongoid::Documentfield:sensor_id,type:Stringvalidates_uniqueness_of:sensor_idend...require'mongoid'require_relative'sensor.rb'classSensorDataincludeMongoid::Documentbelongs_to:sensorfield:date,type:Datefield:ozonMax1h,type:Floatfield:ozonMax8h
我在RubyonRails4.1.4上有一个项目,使用来自git://github.com/activeadmin/activeadmin的activeadmin1.0.0.pre,pg0.17.1,PostgreSQL9.3在项目中我有这些模型:类用户has_one:账户类账户属于:用户有很多:project_accountshas_many:项目,:through=>:project_accounts类项目#该项目有一个bool属性'archive'has_many:project_accounts类ProjectAccount属于:帐户属于:项目我有一个任务是在索引页面上实现一个