目录
1、canal->deployer配置
案例中文件的详细配置
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
#canal.admin.register.auto = true
#canal.admin.register.cluster =
#canal.admin.register.name =
canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = tcp
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
canal.instance.filter.dml.insert = false
canal.instance.filter.dml.update = false
canal.instance.filter.dml.delete = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
#canal.instance.binlog.format = ROW
icanal.instance.binlog.image = FULL,MINIMAL,NOBLOB
#canal.instance.binlog.image = FULL
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
#################################################
######### destinations #############
#################################################
canal.destinations = example
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
##################################################
######### MQ Properties #############
##################################################
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
canal.aliyun.uid=
canal.mq.flatMessage = true
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
canal.mq.database.hash = true
canal.mq.send.thread.size = 30
canal.mq.build.thread.size = 8
##################################################
######### Kafka #############
##################################################
kafka.bootstrap.servers = 127.0.0.1:9092
kafka.acks = all
kafka.compression.type = none
kafka.batch.size = 16384
kafka.linger.ms = 1
kafka.max.request.size = 1048576
kafka.buffer.memory = 33554432
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0
kafka.kerberos.enable = false
kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf"
kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf"
##################################################
######### RocketMQ #############
##################################################
rocketmq.producer.group = test
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
rocketmq.namesrv.addr = 127.0.0.1:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host =
rabbitmq.virtual.host =
rabbitmq.exchange =
rabbitmq.username =
rabbitmq.password =
rabbitmq.deliveryMode =
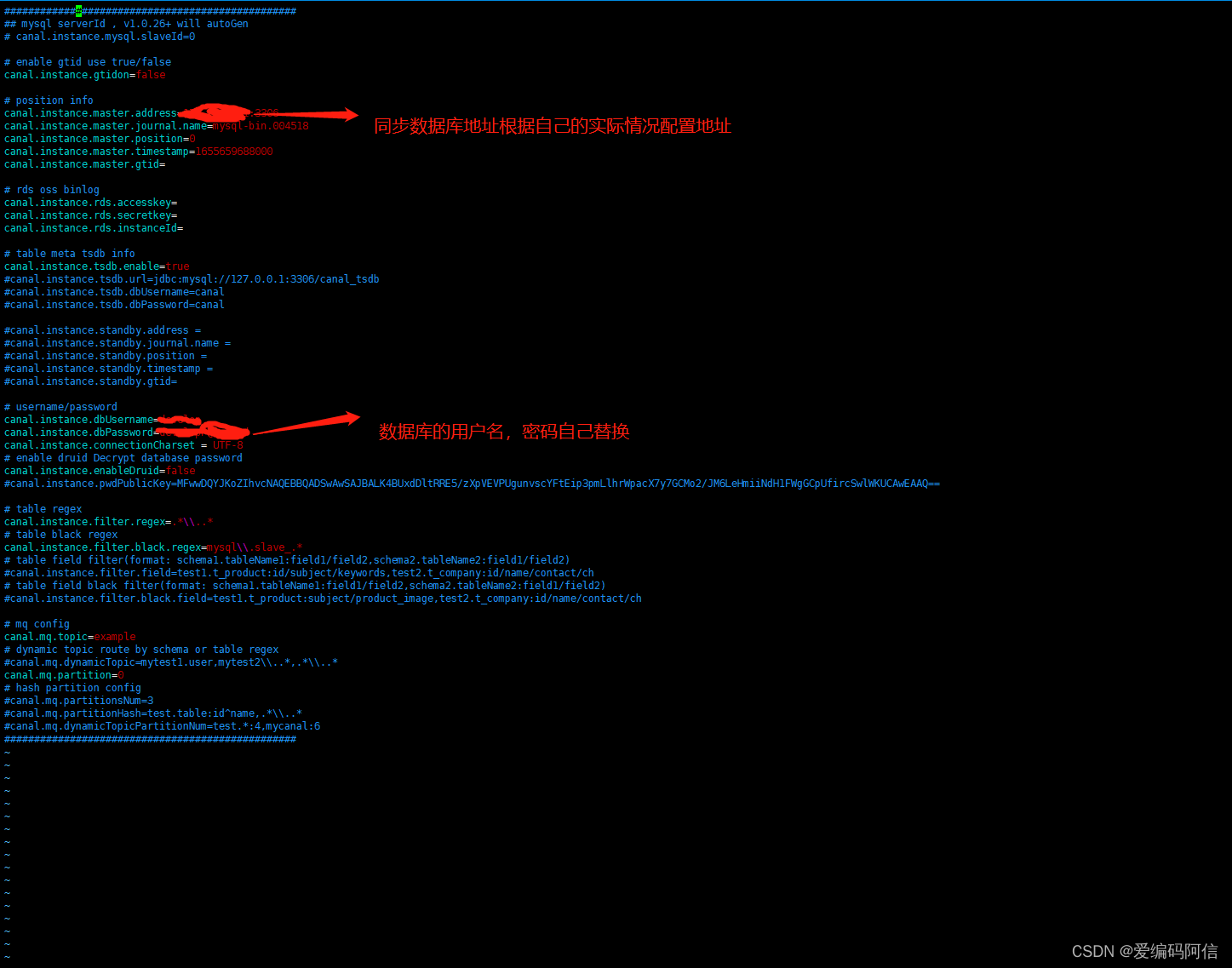
1.2 vim conf/example/instance.properties
本案例使用example实例进行测试,文件的详细配置如下:
进入到canal的deployer下的bin目录启动 命令为./bin/startup.sh
./bin/startup.sh
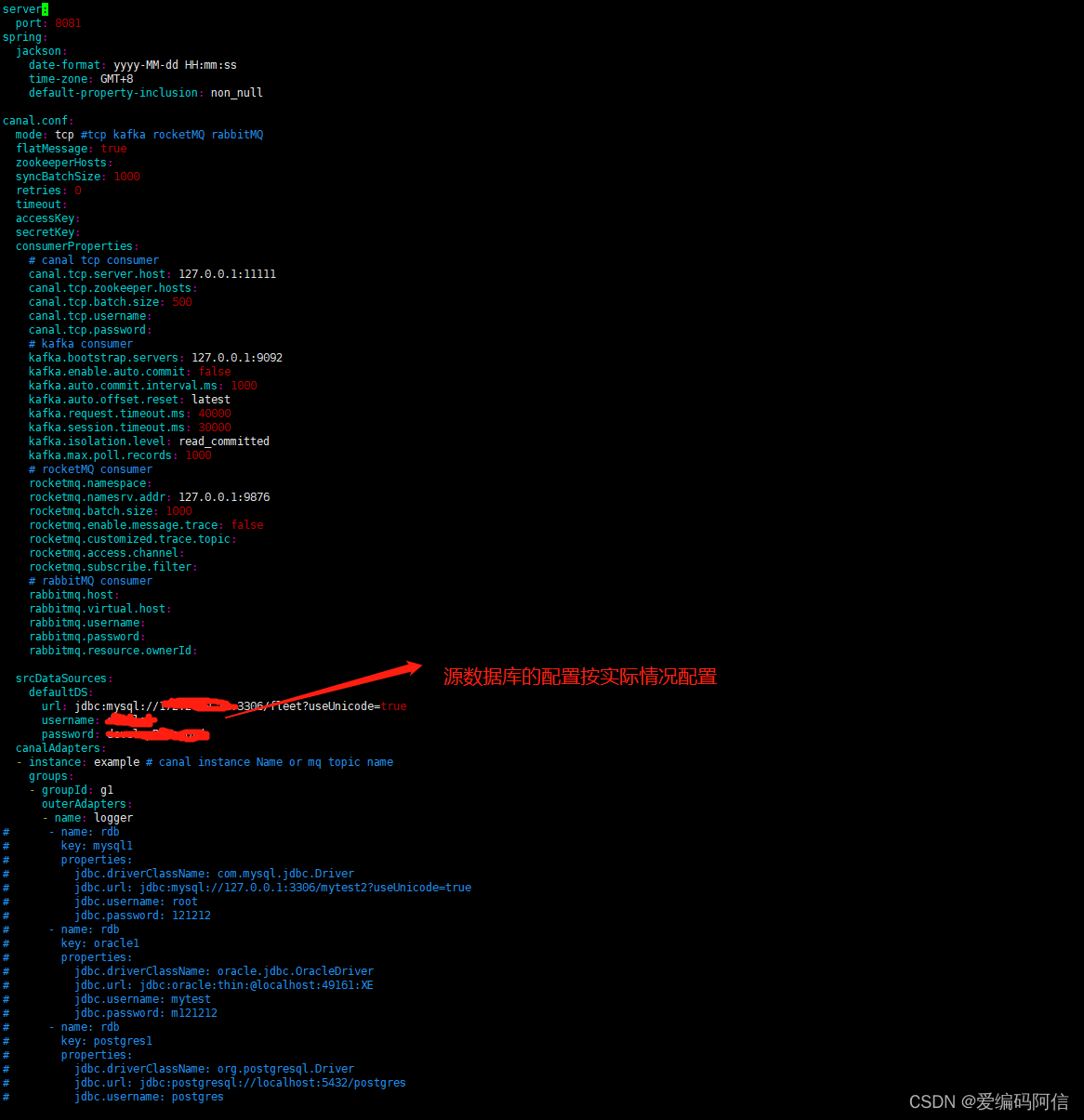
使用命令修改application.yml文件
vim conf/application.yml

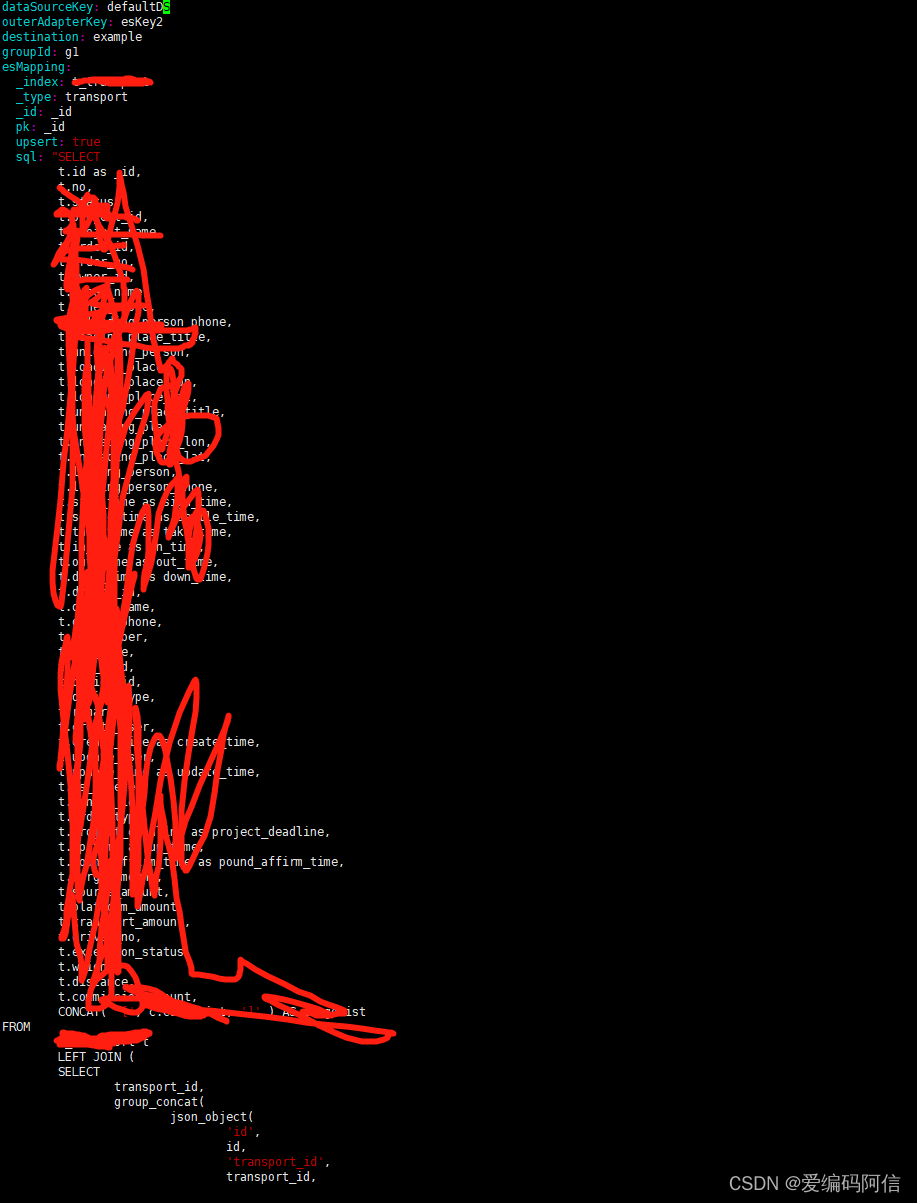
新增t_transport.yml文件并编辑
vim conf/es7/t_transport.yml
./bin/startup.sh
2022-08-24 11:37:37.735 [pool-2-thread-1] INFO c.a.o.canal.client.adapter.logger.LoggerAdapterExample - DML: {"data":[{"project_name":"黔西南水泥项目(示例)88888"}],"database":"fleet","destination":"example","es":1661312257000,"groupId":"g1","isDdl":false,"old":null,"pkNames":["id"],"sql":"","table":"t_transport","ts":1661312257735,"type":"UPDATE"}
从日志中看到old属性为null,说明没有获取到源数据信息,从而修改无效无法同步修改后的数据到ES中。解决此问题需要做如下设置
设置源数据库MySql的my.cnf的binlog配置。把两个关键的参数做如下设置
binlog_format = ROW
binlog_row_image = FULL
使云数据库修改后立即生效,其他模式可能需要重启
修改某条数据的某个字段验证是否修改同步成功:查看日志
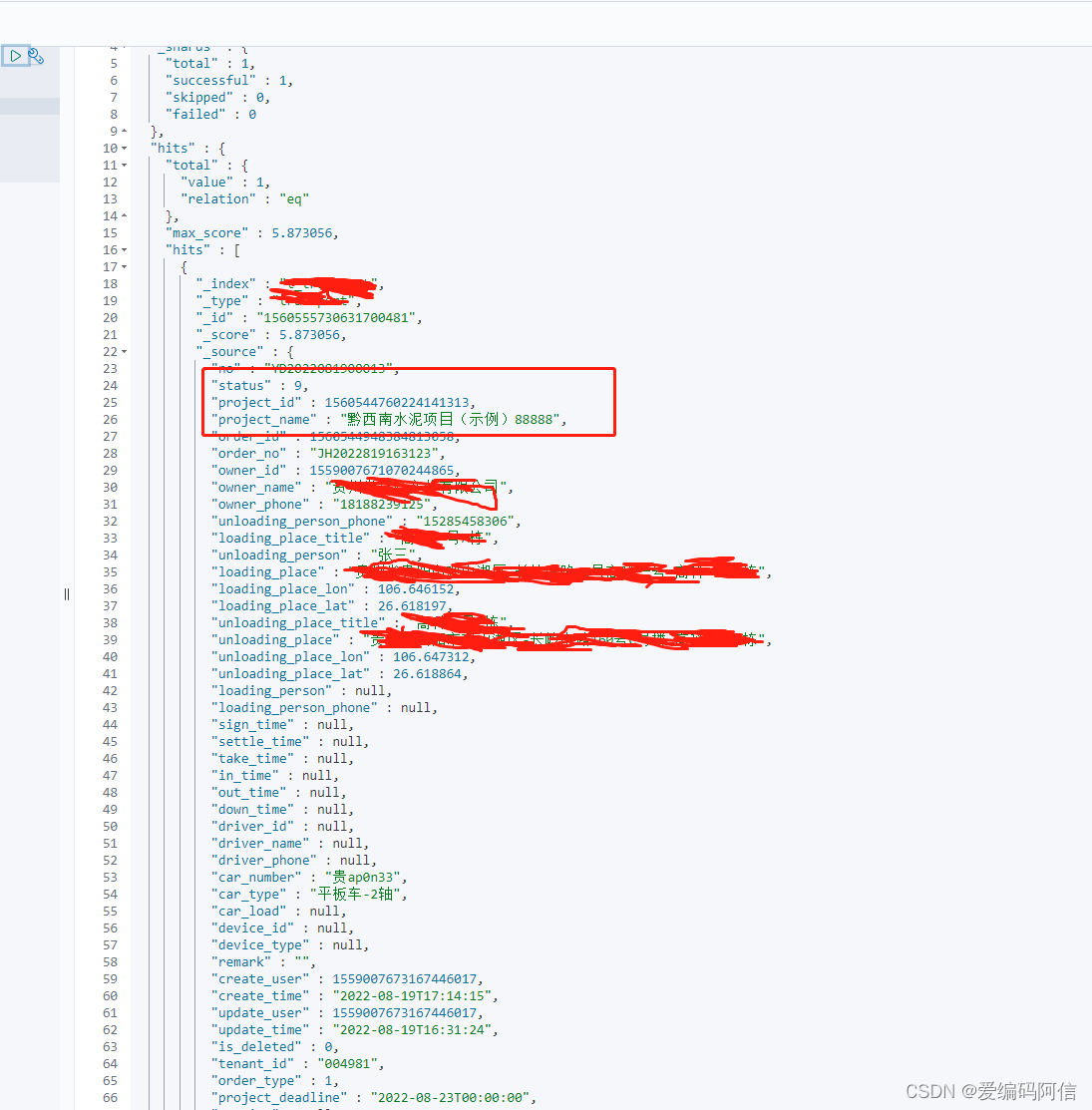
2022-08-24 11:37:37.735 [pool-2-thread-1] INFO c.a.o.canal.client.adapter.logger.LoggerAdapterExample - DML: {"data":[{"id":1560555730631700481,"no":"YD2022081900013","status":1,"project_id":1560544760224141313,"project_name":"黔西南水泥项目(示例)88888","order_id":1560544948384813058,"order_no":"JH2022819163123","owner_id":1559007671070244865,"owner_name":"贵州省卓跃实业有限公司","owner_phone":"18188239125","unloading_person":"张三","unloading_person_phone":"15285458306","loading_place_title":"高科一号A栋","loading_place":"贵州省贵阳市观山湖区-长岭南路40号高科一号-高科一号A栋","loading_place_lon":106.646152,"loading_place_lat":26.618197,"unloading_place_title":"高科一号C栋","unloading_place":"贵州省贵阳市观山湖区-长岭南路160号C号楼-高科一号C栋","unloading_place_lon":106.647312,"unloading_place_lat":26.618864,"loading_person":null,"loading_person_phone":null,"sign_time":null,"settle_time":null,"take_time":null,"in_time":null,"out_time":null,"down_time":null,"driver_id":null,"driver_name":null,"driver_phone":null,"car_number":"贵ap0n33","car_type":"平板车-2轴","car_load":null,"device_id":null,"device_type":null,"remark":"","create_user":1559007673167446017,"create_time":1660900455000,"update_user":1559007673167446017,"update_time":1660897884000,"is_deleted":0,"tenant_id":"004981","order_type":1,"project_deadline":1661184000000,"up_time":null,"pound_affirm_time":null,"cargo_amount":0.0,"source_amount":0.0,"platform_amount":0.0,"transport_amount":0.0,"commission_amount":0.0,"driver_no":null,"exception_status":0,"weight":0.0,"distance":null,"expect_unloading_final_time":1661243483000,"expect_unloading_duration":"96","payee_id":1540231034833031169,"payee_name":"李四","payee_phone":"15285458305","transport_type":0,"start_time":null,"suggest_weight":10.0,"sign_user_id":null,"sign_user_name":null,"order_product_stock":null}],"database":"fleet","destination":"example","es":1661312257000,"groupId":"g1","isDdl":false,"old":[{"project_name":"黔西南水泥项目(示例)55555"}],"pkNames":["id"],"sql":"","table":"t_transport","ts":1661312257735,"type":"UPDATE"}
old已经有源数据信息,再查看ES发现已经同步成功
到此问题处理完成
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我有一个具有一些属性的模型:attr1、attr2和attr3。我需要在不执行回调和验证的情况下更新此属性。我找到了update_column方法,但我想同时更新三个属性。我需要这样的东西:update_columns({attr1:val1,attr2:val2,attr3:val3})代替update_column(attr1,val1)update_column(attr2,val2)update_column(attr3,val3) 最佳答案 您可以使用update_columns(attr1:val1,attr2:val2
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD