目录
使用select语句可以将需要的数据从 mysql数据库中查询出来,如果对查询的结果进行排序,可以使用order by语句来对语句实现排序,并最终将排序后的结果返回给用户,这个语句的排序不光可以针对某一个字段,也可以针对多个字段。
语法
select 字段1,字段2....from 表名 order by 字段1,字段2.......[asc]
#查询结构以升序方式显示,asc可以省略
select 字段1.字段2....from 表名 order by 字段1,字段2........desc
#查询结构以降序的方式显示
mysql> select id,nba,age from ky21 order by id asc;
#查询id,nba,age。字段的记录,并且以id进行升序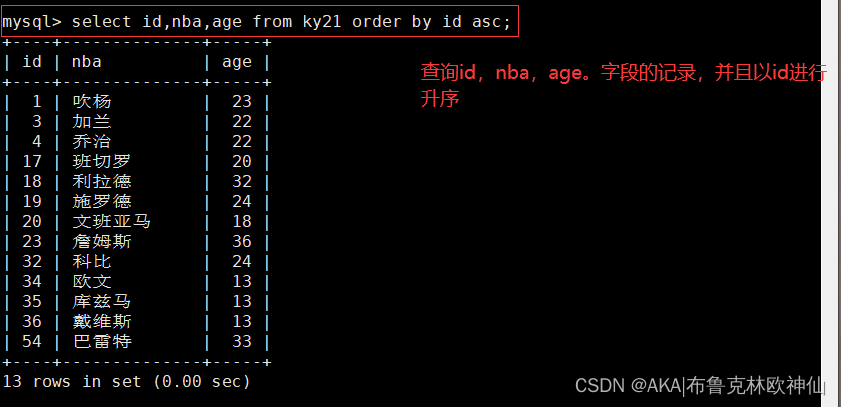
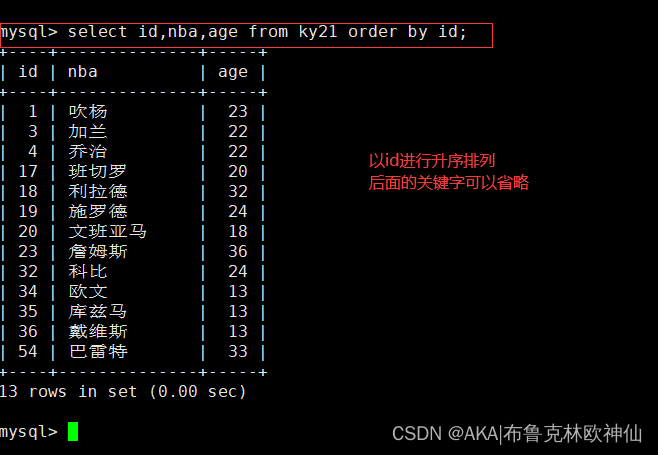
mysql> select id,nba,age from ky21 order by id desc;
查找id,nba,age字段,以id进行降序排序
desc(降序)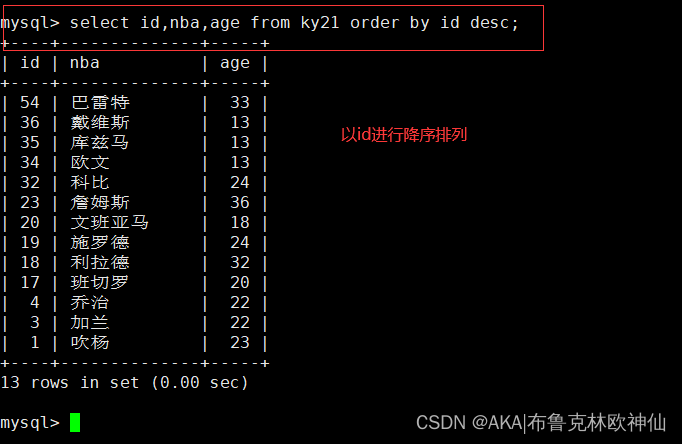
mysql> select id,nba,score,addres from ky21 where addres='洛杉矶' order by score desc;
#查询,id,nab,score,address字段,再进行过滤出address=洛杉矶的字段,在进行score字段进行降序排序
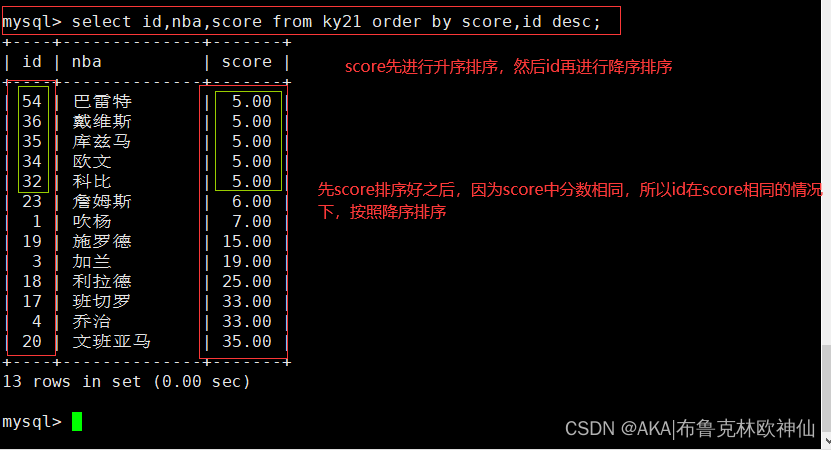
order by 语句也可以使用多个字段来进行排序,当排序的第一个字段相同的记录有多条的情况下,这些多条的记录再安装第二个字段进行排序,order by后面跟多个字段时,字段直接使用英文逗号隔开,优先级是安装优先级顺序而定,但是order by 之后的第一个参数只有在出现相同值的时候,第二个字段才有意义。
mysql> select id,nba,score from ky21 order by score,id desc;
此处做的实验是先升序排序再降序排序,也可以都降序排序或者都升序排序,这里就不做过多的例子了
在大型数据库中,有事查询数据需要数据符合某些特点,“and”和“or” 表示“且”和“或”。
mysql> select id,nba,age from ky21 where id>20;
查找id大于20的记录,并且只显示id,age,nba
mysql> select id,nba,age from ky21 where id>10 and id<30;
查找id大于10的记录并且小于30的记录
mysql> select id,nba,age from ky21 where id>1 or id<30;
查找id大于1 或者小于30的记录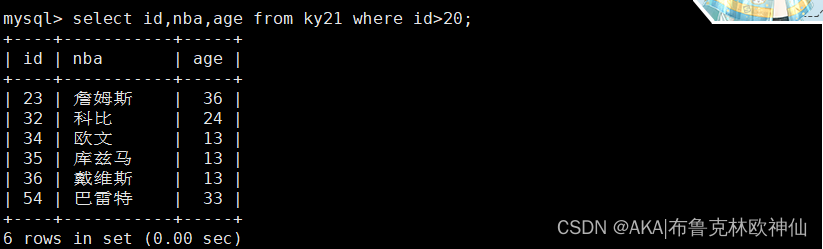

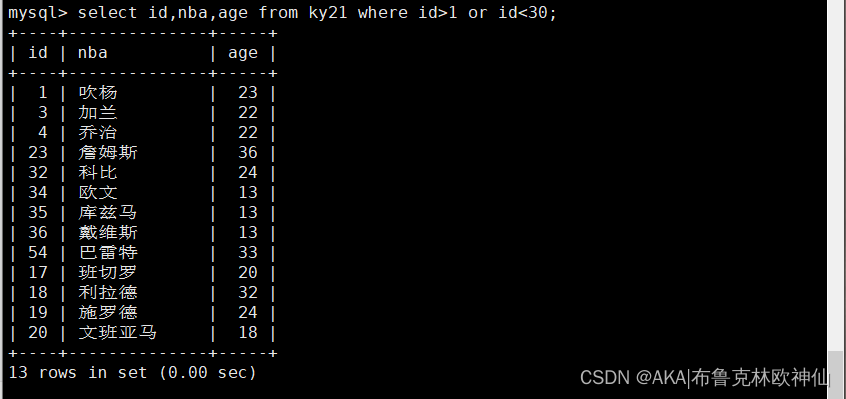
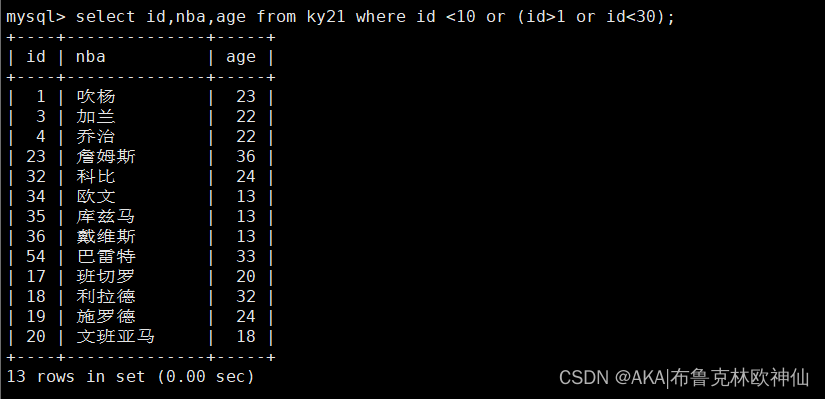
mysql> select id,nba,age from ky21 where id <10 or (id>1 or id<30);
查找id小于10或者大于1和小于30之间的
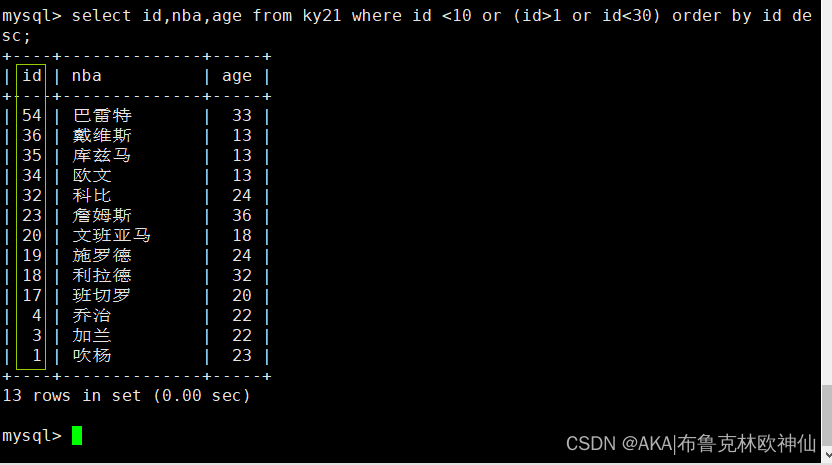
mysql> select id,nba,age from ky21 where id <10 or (id>1 or id<30) order by id desc;
查找id小于10或者大于1和小于30之间的,并且以id进行降序排序
select distinct 字段 from 表名;
- distinct 必须放在最开头
- distinct 只能使用需要去重的字段进行操作
- distinct 去重多个字段时,含义是:几个字段同时重复时才能会过滤,会默认按左边第一个字段为依据。
mysql> select distinct age from ky21;
#使用distinct查询不重复记录,(相当于去重)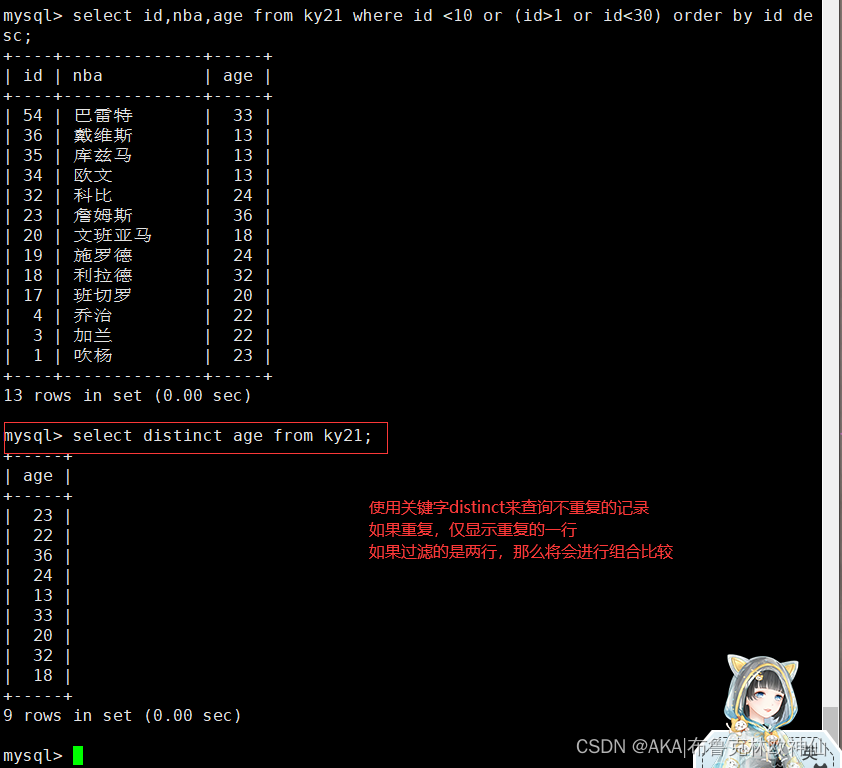
通过sql查询出来的结果,还可以对其进行分组,使用group by语句来实现,group by通常都是结合集合函数来一起实现的。
常用的聚合函数包括:计数(count)、求和(sum)、求平均数(avg)、最大值(max)、最小值(min),group by 分组的时候可以按一个或多个字段对结果进行分组处理。、
select 字段,聚合函数(字段) from 表名【where 字段 (匹配) 数值】group by 字段名;
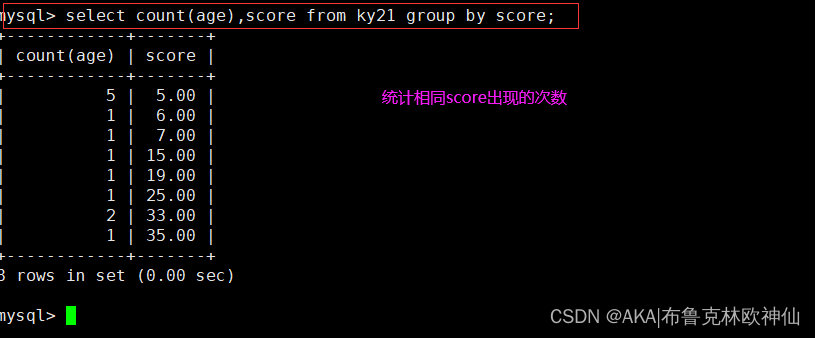
mysql> select count(age),score from ky21 group by score;
#count(age): 记录age字段的数据出现的次数
group by score; 按照score相同的分数进行分组,
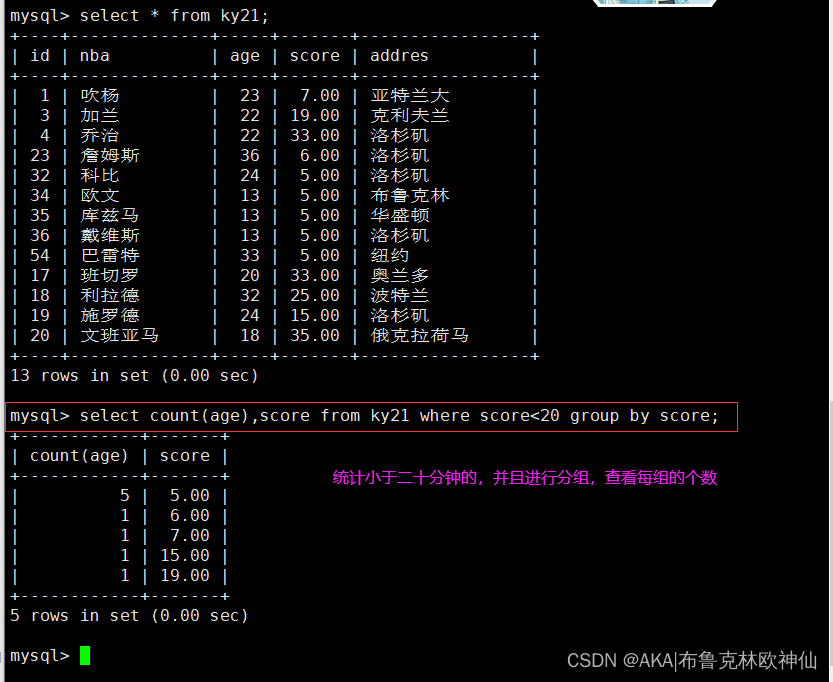
mysql> select count(age),score from ky21 where score<20 group by score;
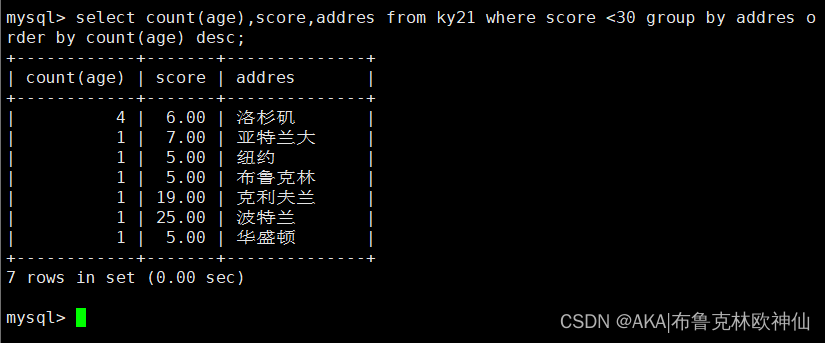
mysql> select count(age),score,addres from ky21 where score <30 group by addres order by count(age) desc;

limit限制输出的结果
在使用mysql select 语句进行查询时,结果集返回的是所以匹配的记录(行)
,有时候仅需返回第一行或者前几行,这时候就需要用到limit子句
语法:select 字段 from 表名 limint [offset] number
- limit的第一个参数是位置偏移量(可选参数),设置mysql从哪一行开始,如果不设定第一个参数,将会从表中的第一条记录开始显示。第一条偏移量是0,将会从表中的第一条记录开始开始
- 第一条偏移量是0,第二条为1
- offset :为索引下标
- number:为索引下标后的几位
查询所以信息显示的前四行记录
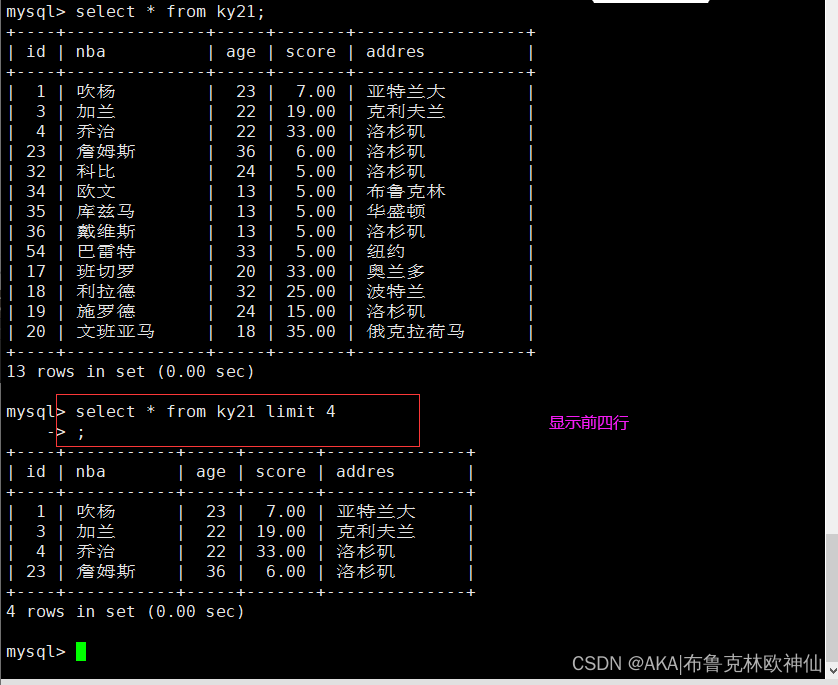
从第四行开始,显示后3行的内容
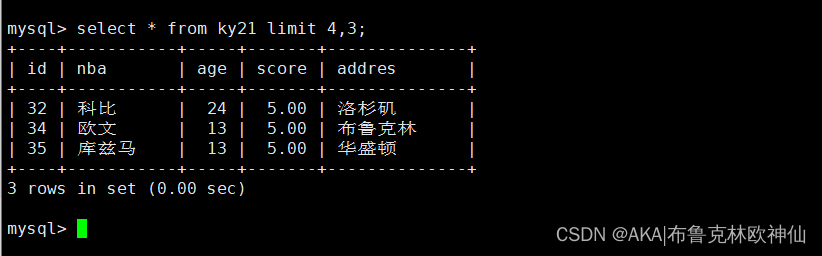
结合order by 来显示按照id的大小升序排列显示前三行
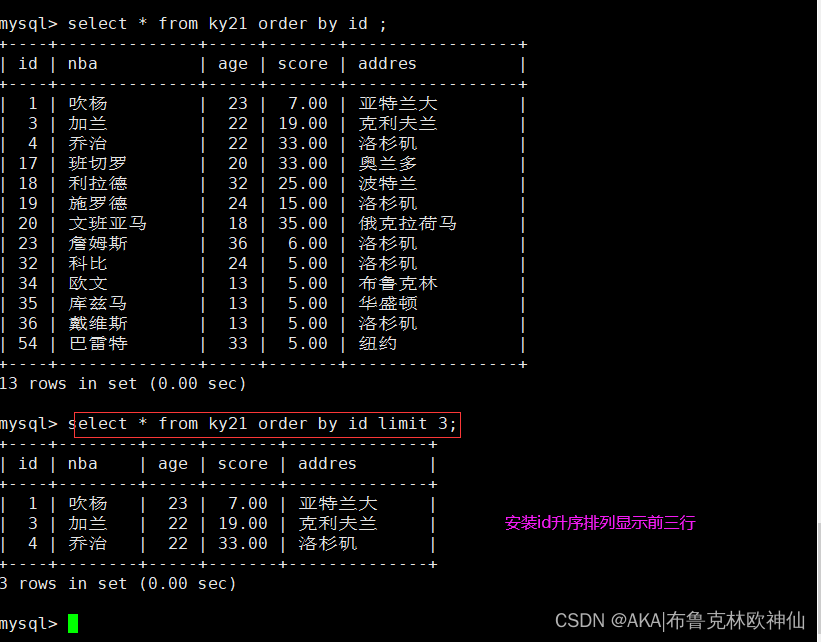
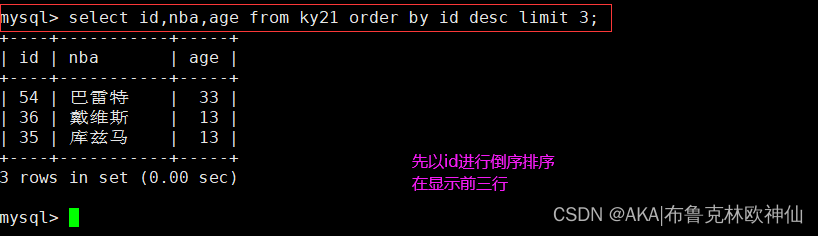
怎么输出最后三行
当在mysql查询时,当表的名字比较长或者表内的某些字段比较长时,为了方便书写或者多次使用相同的表,可以给字段列或者表设置别名,使用的时候直接使用别名,简单明了,增强可读性
语法:对应列的别名:select 字段 as 字段别名 表名:
:对于表的别名:select 别名.字段 from 表名 as 别名;
使用场景
mysql> select nba as 球员,addres as 城市 from ky21;

表,别名设置示例
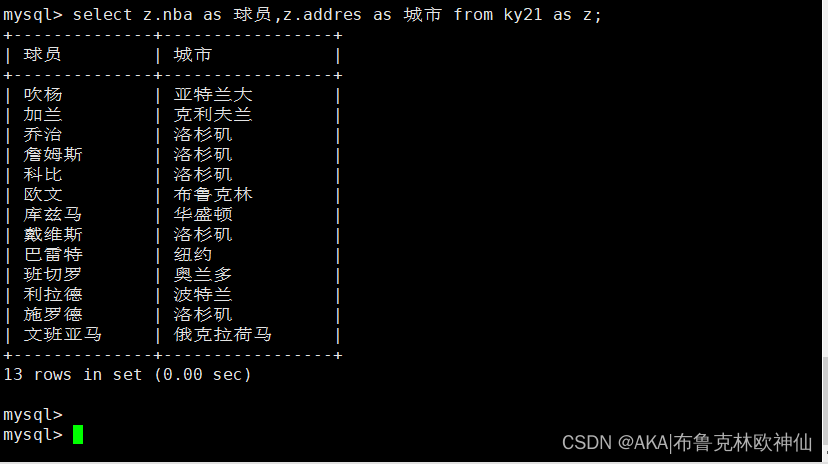
mysql> select addres,count(*)as 城市 from ky21 group by addres;
此处as起到的作用
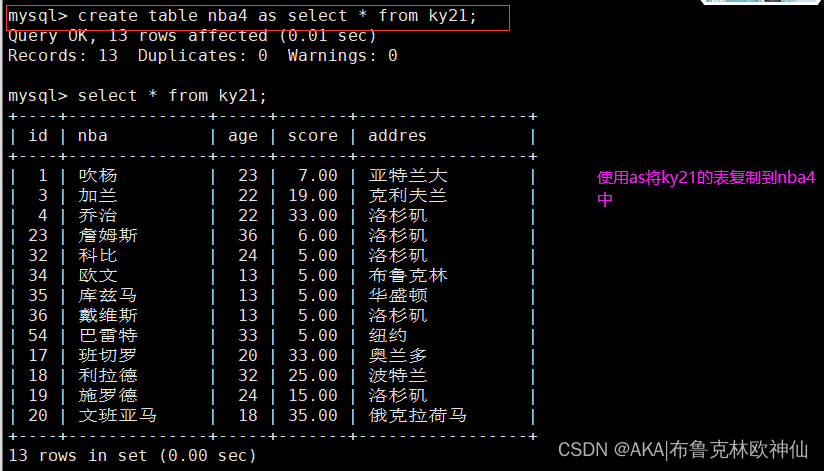
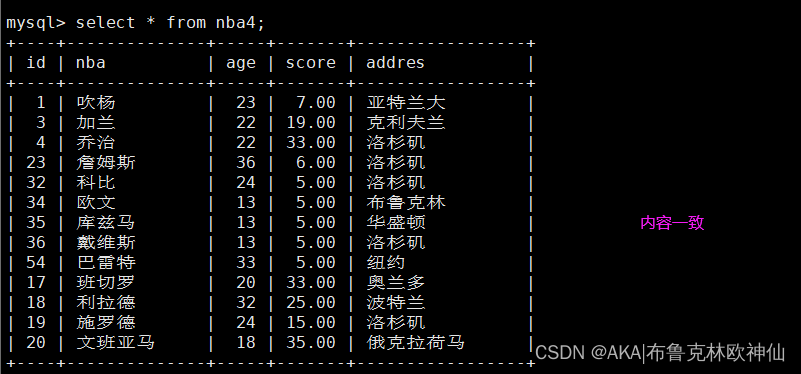
mysql> create table nba4 as select * from ky21;
mysql> select * from nba4;
mysql> select * from ky21;
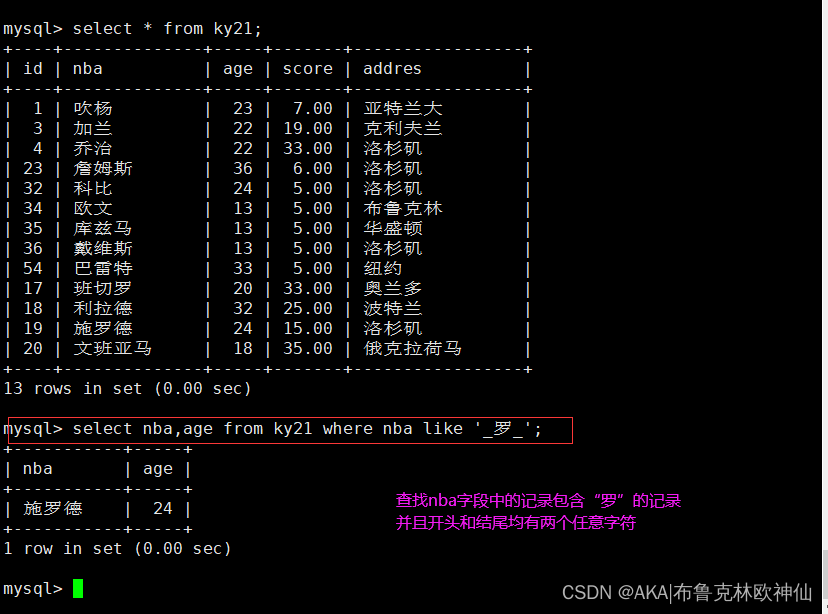
%:百分号表示0个、1个、或多个字符
_:下划线表示单个字符
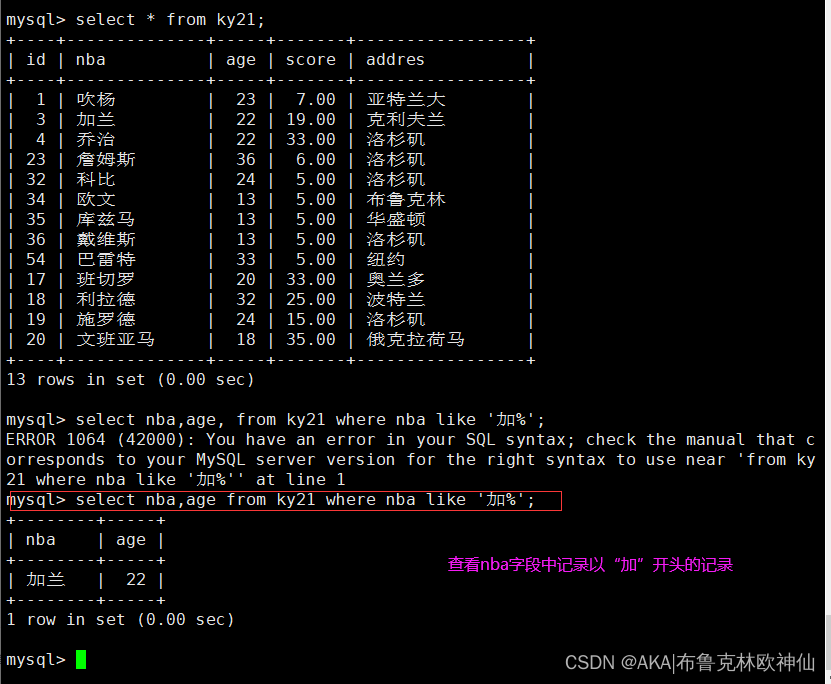
mysql> select nba,age from ky21 where nba like '加%';
#查询名称以“加”开头开头的记录
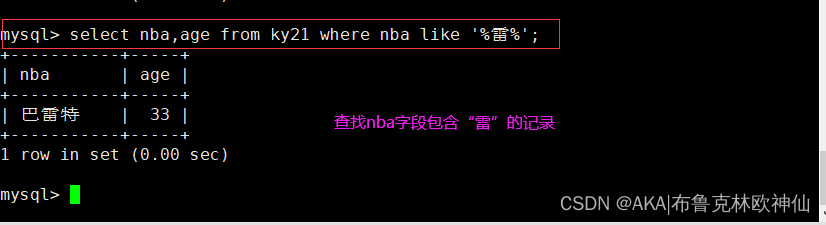
mysql> select nba,age from ky21 where nba like '%雷%';
#查询包含字符“雷”的nba的记录
mysql> select nba,age from ky21 where nba like '_罗_';
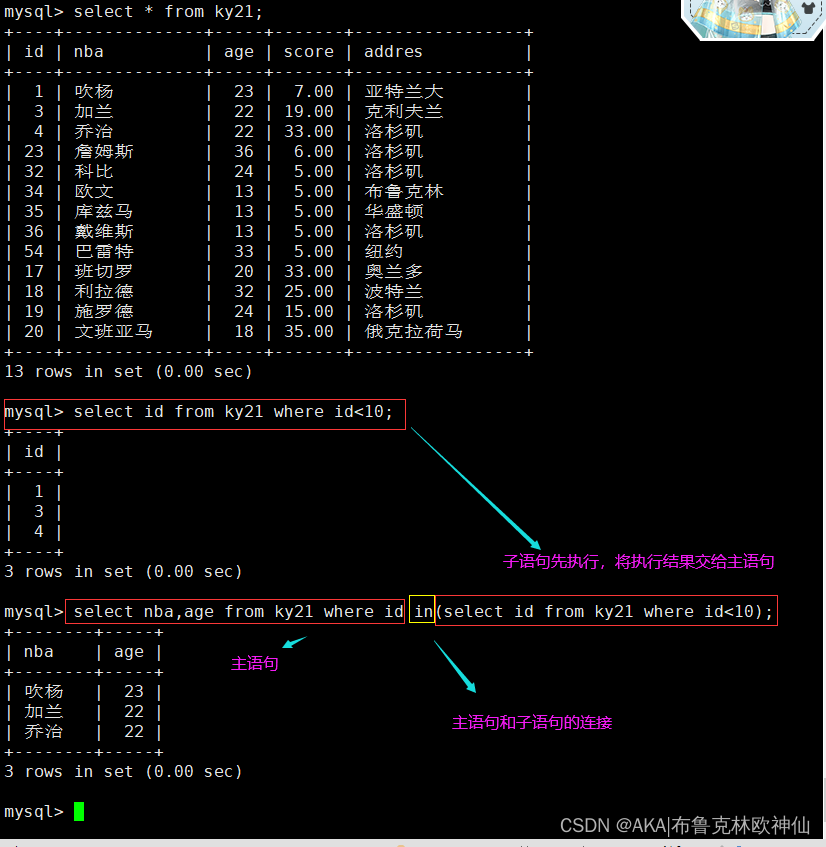
子查询也被称为内查询或者嵌套查询,是指在一个查询语句里面还嵌套者另一个查询语句
子查询语句是先于主查询语句被执行,且结果作为外层的条件返回给主查询进行下一步查询
在查询中可以与主语句相同的表,也可以是不同的表
子语句可以与主语句所查询的表相同,也可以使不同的表
语法格式
select 字段1,字段2 from 表名1 where 字段 in (select 字段 from 表名 where 条件);
- 主语句:select 字段1,字段2 from 表名1 where 字段;
- in:将主表和字表关联/连接的语法
- 子语句(集合):select 字段 from 表名 where 条件;
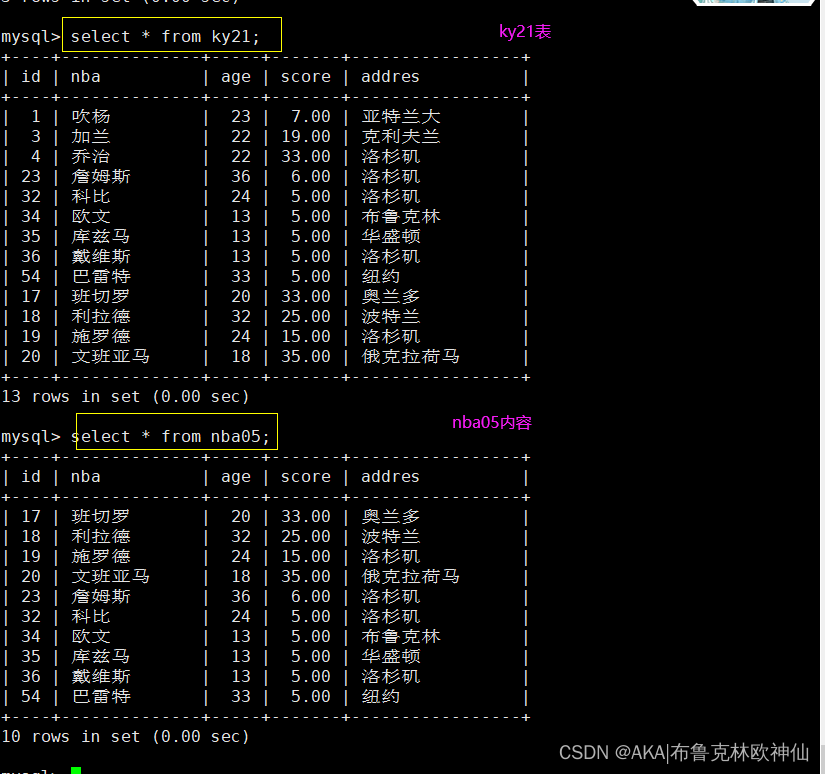
mysql> select nba,age from ky21 where id in(select id from ky21 where id<10);
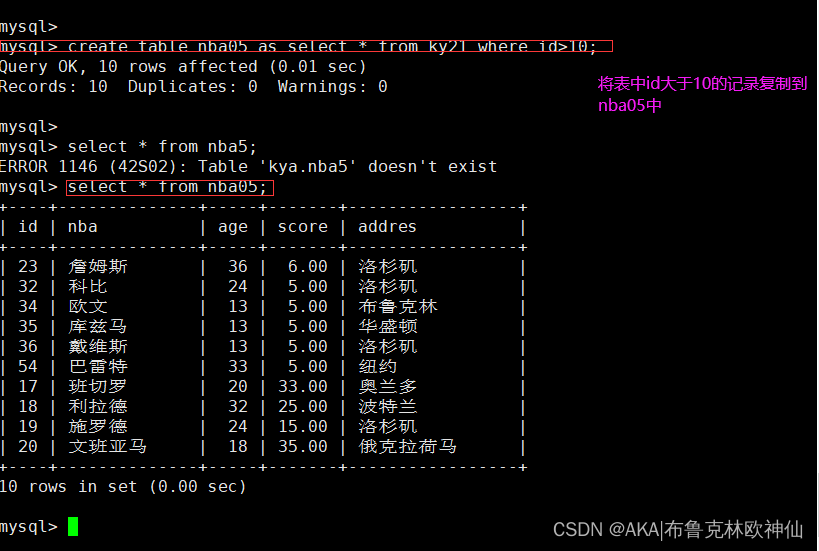
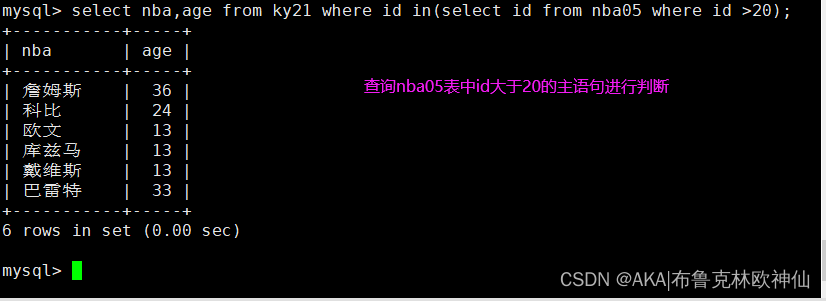
mysql> select nba,age from ky21 where id in(select id from nba05 where id >20);
mysql> select nba,age from ky21 where id not in(select id from nba05 where id >20););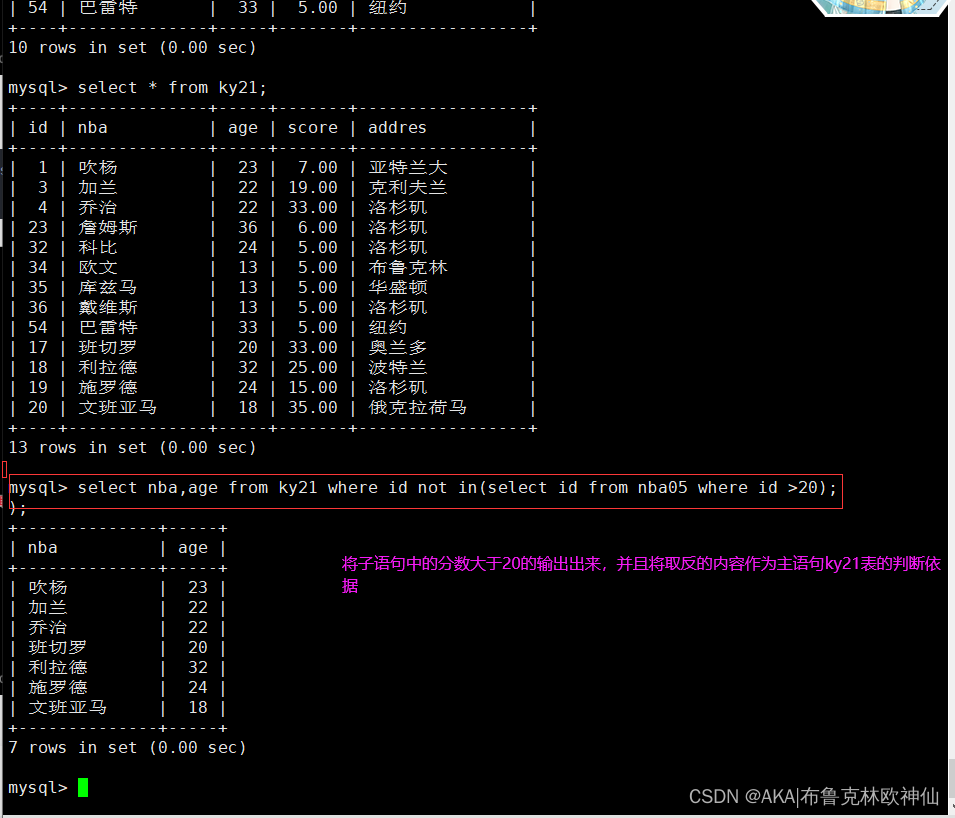
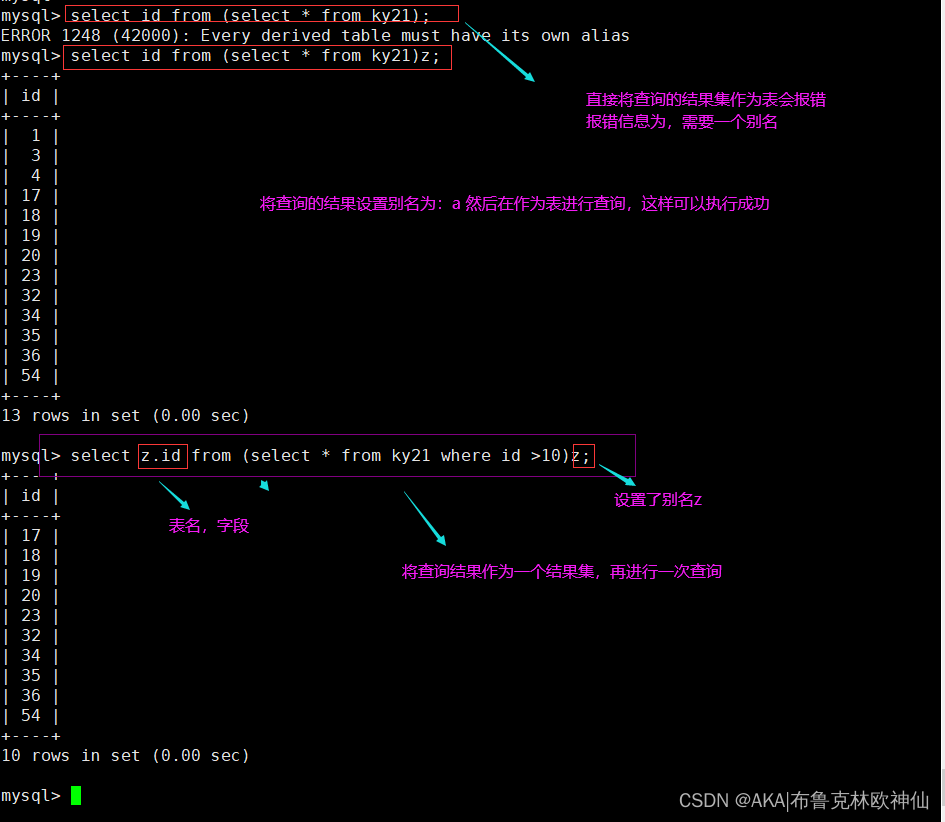
当我们将一个查询的结果集作为一个新表再进行查询时。直接使用会进行报错,我们需要使用到别名
select id from (select * from ky21;
#此条报错
select id from (select * from ky21)a;
#设置了别名,然后再作为表
select a.id from (select * from ky21 where id >80)a;
#将查询结果集设置别名,然后将结果集作为表进行查询,
子查询还可以用在insert语句中,子查询的结果集可以通过insert语句插入到其它表中
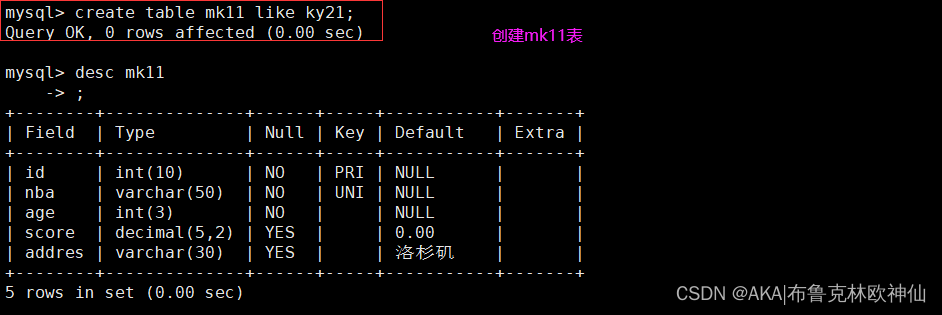
mysql> create table mk11 like ky21;
mysql> desc mk11;
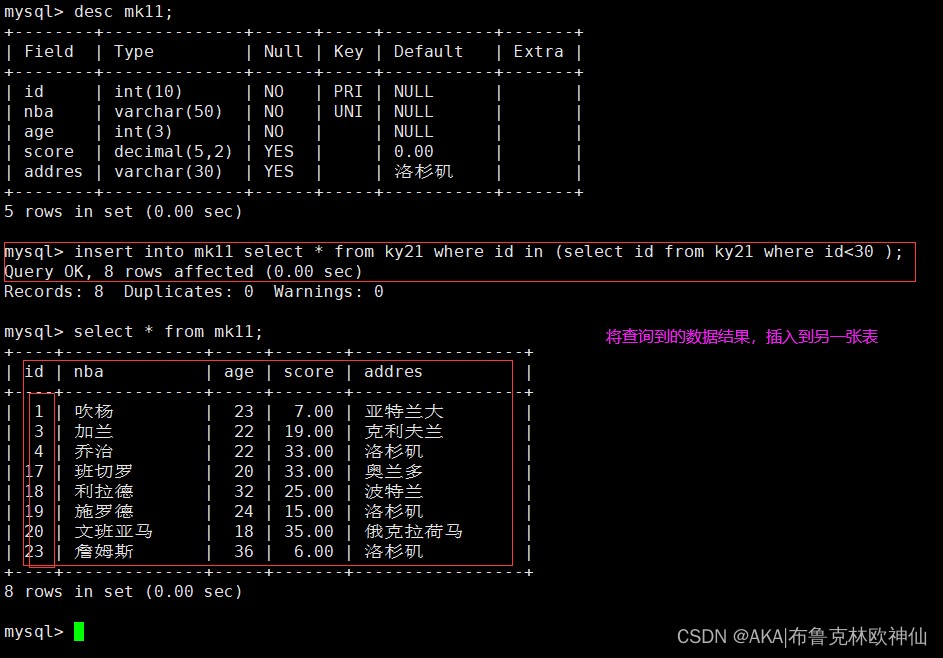
mysql> insert into mk11 select * from ky21 where id in (select id from ky21 where id<30 );
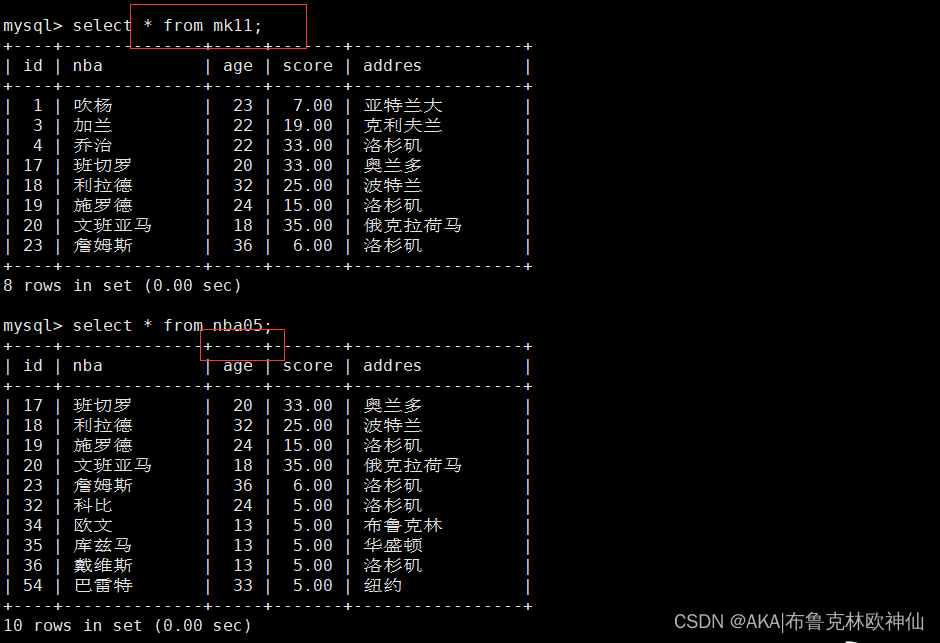
mysql> select * from mk11;
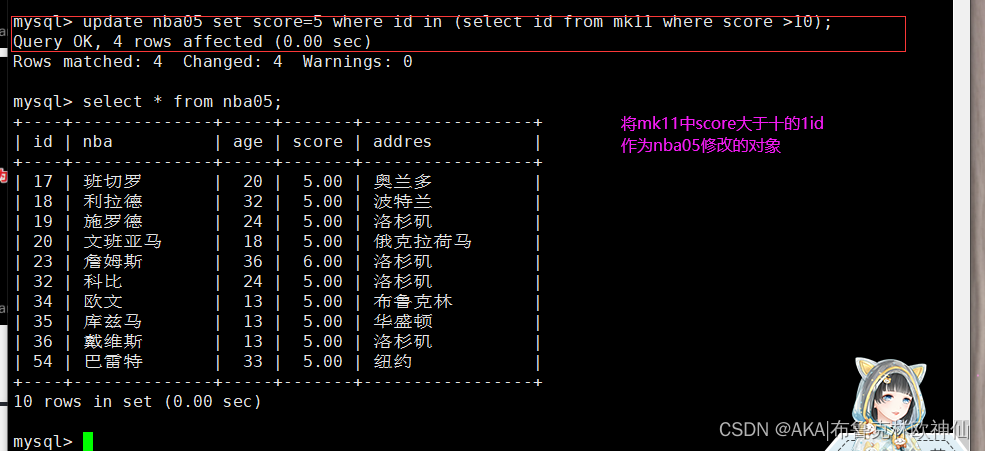
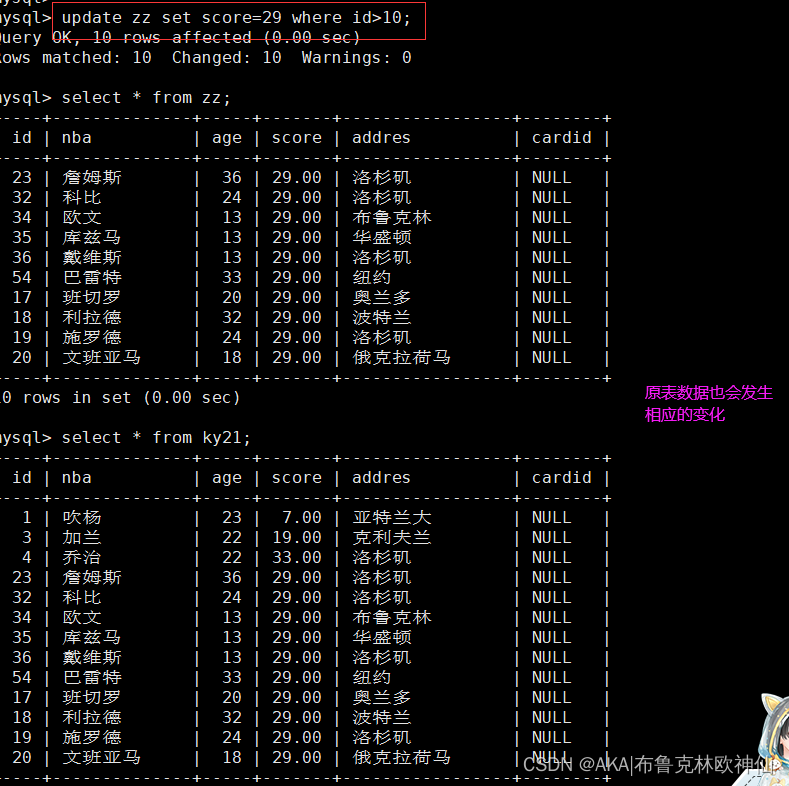
update语句也可以使用子查询,update内的子查询,在set更新内容时,可是单独一列,也可以是多列。
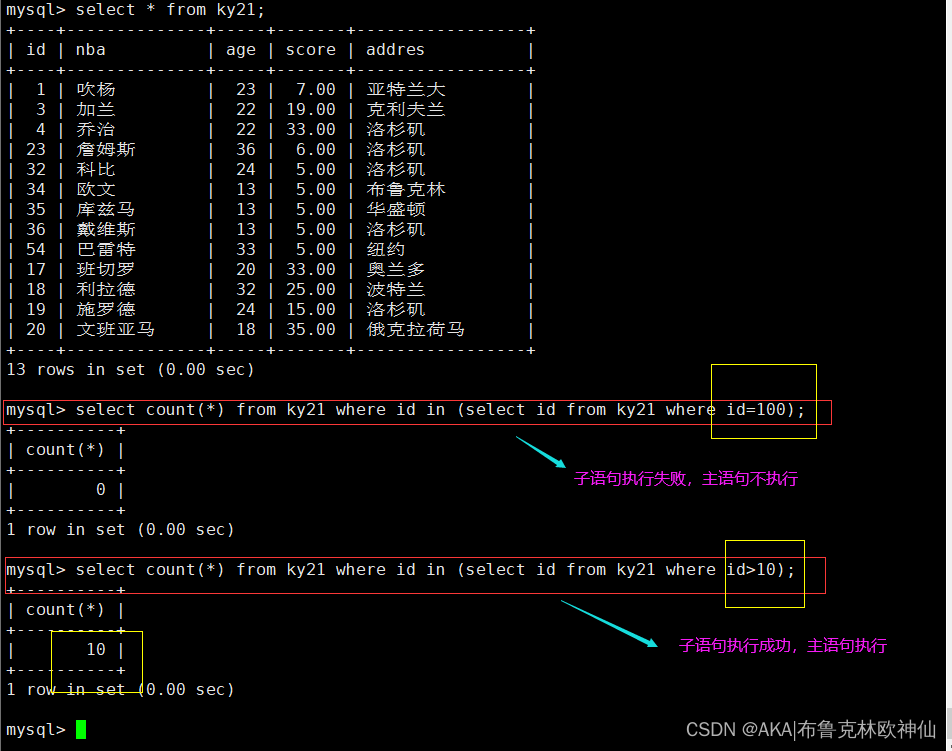
mysql> update nba05 set score=5 where id in (select id from mk11 where score >10);

exists 关键字在子查询时,主要用于判断子查询的结果集是否为空,如果不为空。则返回true,反之返回false。
注意: 在使用exists时,当子查询有结果时,不关心子查询的内容,执行主查询操作,当子查询没有结果时,则不执行主查询操作。子查询只是作为布尔的输出
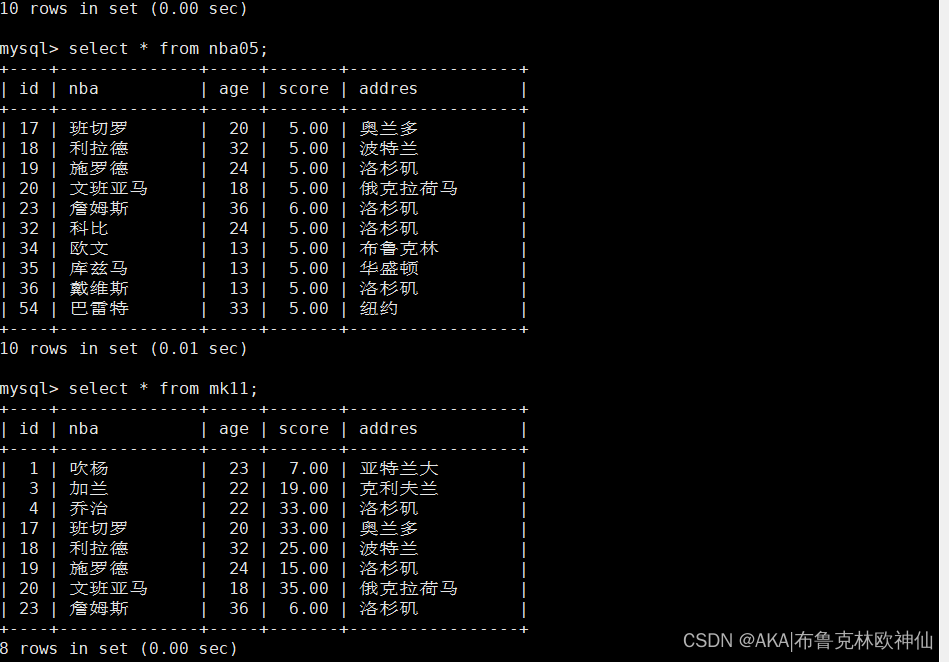
mysql> select count(*) from ky21 where id in (select id from ky21 where id=100);
#子语句执行失败,输出为false,那么主语句不会进行执行,默认输出0
mysql> select count(*) from ky21 where id in (select id from ky21 where id>10);
#子语句执行成功,输出为true,那么主语句会执行,输出info表的行数
视图:优化操作+安全方案
数据库中的虚拟表,这张虚拟表不包含真实数据。只是做了真实数据的映射。
视图可以理解为镜花水月倒影,动态保存结果集
作用场景:针对不同的人(不同权限),提供不同的结果集的表(以表格的形式展示)
功能
注意
视图适合于多表连接浏览时使用,不适合增,删,改,
而存储过程适合于使用较频繁的sql语句,这样可以提供执行效率
区别
联系
语法格式:create view 视图表名 as select * from 表名 where 条件;
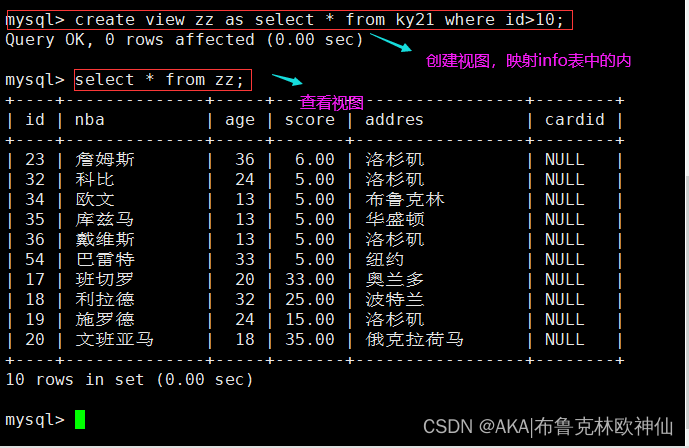
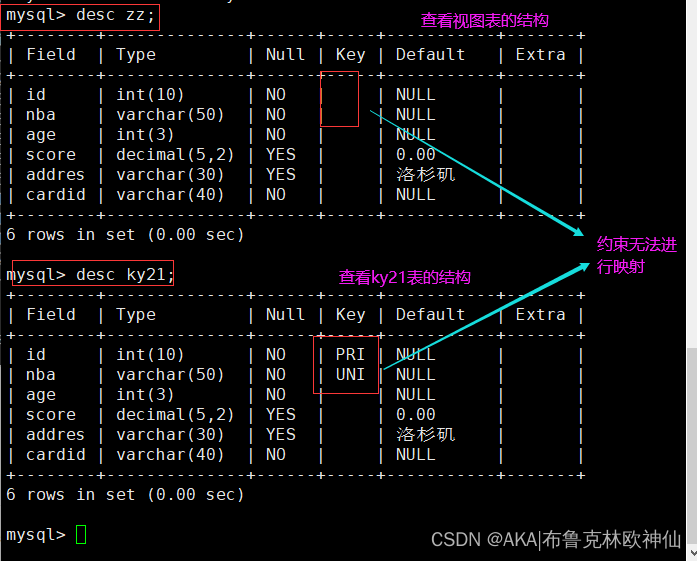
现在有两个表,需要频繁查看其中数据,那就可以使用视图的方式将要看的内容生成一个视图,要查看时,直接查看视图内容即可。
在 SQL 语句使用过程中,经常会碰到 NULL 这几个字符。通常使用 NULL 来表示缺失的值,也就是在表中该字段是没有值的。如果在创建表时,限制某些字段不为空,则可以使用 NOT NULL 关键字,不使用则默认可以为空。在向表内插入记录或者更新记录时,如果该字段没有 NOT NULL 并且没有值,这时候新记录的该字段将被保存为 NULL。需要注意 的是,NULL 值与数字 0 或者空白(spaces)的字段是不同的,值为 NULL 的字段是没有 值的。在 SQL 语句中,使用 IS NULL 可以判断表内的某个字段是不是 NULL 值,相反的用 IS NOT NULL 可以判断不是NULL值
可以使用order by进行针对某一个字段进行排序,使用asc为升序,可默认不写,使用desc为降序。如果同一条语句中写了两条排序字段,则默认按照第一个进行排序,等出现相同字段才会去使用第二个字段排序。
使用and和or可以过来判断条件,常用在查询语句中筛选一些条件,使用在where条件后面
distinct 为查询不重复记录,在查询语句时,定义字段前面加上distinct就可以输出该字段的所有记录,重复的记录只输出一遍。
group by,表示分组,用来指定以哪个字段进行分组,其中还可以使用count(*)来表示统计行数,经常搭配使用。
limit表示限制,可以选定只显示前几行,或者从第几行开始的后几行内容。
是指别名as,表示在对于表名或字段名较长的时候,使用as设置别名,可以方便降低复杂度。还可使用as来获取另一个表的内容,相当于克隆表的内容数据。as可以省略。
通配符查询,有%表示任意长度的只读,_表示单个任意字符,查询时,经常配合like来进行模糊查询。
子查询,就是当进行多个表进行查询时,可以使用子查询的结构作为主查询的判断条件进行。总的来说就是,将子查询的结果作为一个集合交给主查询。
写法有两种,一种是在定义判断条件时,使用where in (子查询内容),或者将子查询结果直接作为主查询的表来实现,这样实现需要使用as将子查询的结果设置别名,不然报错。
子查询还可以进行insert、update、delect、exists布尔判断,来设置。
视图就是将表的不同的内容加载到内存中,用来展现给不同的人看,视图可以理解为时一个快捷方式,加载速度快,不消耗磁盘资源,不影响数据库的资源,查询自己需要查询的内容非常方便快捷。
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我注意到类定义,如果我打开classMyClass,并在不覆盖的情况下添加一些东西我仍然得到了之前定义的原始方法。添加的新语句扩充了现有语句。但是对于方法定义,我仍然想要与类定义相同的行为,但是当我打开defmy_method时似乎,def中的现有语句和end被覆盖了,我需要重写一遍。那么有什么方法可以使方法定义的行为与定义相同,类似于super,但不一定是子类? 最佳答案 我想您正在寻找alias_method:classAalias_method:old_func,:funcdeffuncold_func#similartoca
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
在添加一些空格以使代码更具可读性时(与上面的代码对齐),我遇到了这个:classCdefx42endendm=C.new现在这将给出“错误数量的参数”:m.x*m.x这将给出“语法错误,意外的tSTAR,期待$end”:2/m.x*m.x这里的解析器到底发生了什么?我使用Ruby1.9.2和2.1.5进行了测试。 最佳答案 *用于运算符(42*42)和参数解包(myfun*[42,42])。当你这样做时:m.x*m.x2/m.x*m.xRuby将此解释为参数解包,而不是*运算符(即乘法)。如果您不熟悉它,参数解包(有时也称为“spl
我想从then子句中访问case语句表达式,即food="cheese"casefoodwhen"dip"then"carrotsticks"when"cheese"then"#{expr}crackers"else"mayo"end在这种情况下,expr是食物的当前值(value)。在这种情况下,我知道,我可以简单地访问变量food,但是在某些情况下,该值可能无法再访问(array.shift等)。除了将expr移出到局部变量然后访问它之外,是否有直接访问caseexpr值的方法?罗亚附注我知道这个具体示例很简单,只是一个示例场景。 最佳答案
如何在Ruby的if语句中检查bash命令的返回值(true/false)。我想要这样的东西,if("/usr/bin/fswscell>/dev/null2>&1")has_afs="true"elsehas_afs="false"end它会提示以下错误含义,它总是返回true。(irb):5:warning:stringliteralincondition正确的语法是什么?更新:/usr/bin/fswscell寻找afs安装和运行状态。它会抛出这样的字符串,Thisworkstationbelongstocell如果afs没有运行,命令以状态1退出 最
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我最近与一位同事讨论了以下Ruby语法:value=ifa==0"foo"elsifa>42"bar"else"fizz"end我个人并没有看到太多这种逻辑,但我的同事指出,这实际上是一种相当普遍的Rubyism。我试着用谷歌搜索这个主题,但没有找到任何文章、页面或SO问题来讨论它,这让我相信这可能是一种非常实际的技术。然而,另一位同事发现语法令人困惑,而是将上面的逻辑写成这样:ifa==0value="foo"elsifa>42value="bar"elsevalue="fizz"end缺点是value=的重复声明和隐式elsenil的丢失,如果我们想使用它的话。这也感觉它与Ruby