一.概述
随着对象存储使用得到广泛普及,越来越多的企业客户从其他云对象存储迁移到Amazon S3时对实时性,安全性,稳定性,易用性和同步效率有不同的要求。其次,数据存储如关系型/非关系型数据库,Elasticsearch,Redis等皆可通过导出文件或快照进行数据导入,使数据迁移变为基于文件的迁移。本文以迁移阿里MaxCompute数据为示例,通过阿里OSS对象存储实时事件触发,部署Data Transfer Hub以将阿里MaxCompute数据导入到Amazon S3数据湖。除了上述场景外,本文也同样适用于普通对象存储文件迁移。
阅读本文,您将会了解到:
二.简要说明
Data Transfer Hub(数据在线传输解决方案),是一个安全,可靠,可扩展和可追踪的数据传输解决方案,使用户可以轻松地创建和管理不同数据类型, 从不同的来源到Amazon Web Service云原生服务的传输任务,例如将数据从其他云服务商的对象存储服务 (包括阿里云 OSS、腾讯 COS、七牛 Kodo 和其他兼容 Amazon S3 的云存储服务) 复制到 Amazon S3。您可以访问亚马逊云科技解决方案官方网站了解该解决方案并在您的账户中进行部署。
该方案支持基于Amazon CloudFormation一键部署,采用无服务器架构,并提供了友好的用户界面,有着易于使用的特性。同时该方案采用了Amazon Graviton2 作为工作集群,大大降低云上费用。并且该方案运用了 BBR 加速,提升10倍传输性能。在架构设计上该方案采用集群架构,以实现海量数据极速传输。
此方案的 CloudFormation 模板会自动部署和配置包含 Amazon AppSync, Amazon DynamoDB, Amazon ECS Fargate, Amazon Lambda, Amazon Step Functions 等服务的架构。该解决方案提供一个托管于 Amazon S3 的 Web 前端,通过 Amazon CloudFront 对外提供服务。Web 前端使用 Amazon Cognito User Pool 或 OpenID Connect(OIDC)服务提供商进行身份验证。下图为前端部分的架构。

当用户通过前端界面启动数据传输任务后,会调用后端数据传输CloudFormation 模板自动部署和配置包含Amazon DynamoDB, Amazon ECS Fargate, Amazon Lambda, Amazon Step Functions, Amazon EC2, Amazon SQS 等服务的架构。其中Fargate会定期对比数据源和目标端之间的数据差异,并将有差异的数据任务发送到任务队列Amazon SQS中,以实现定时批量数据传输任务的创建。同时数据传输任务可以以Event的形式直接发送到任务队列SQS中,以实现实时增量数据传输任务的创建。Amazon EC2作为数据传输的工作者,其数量被Auto Scaling Group 所控制,根据SQS内待传输任务数进行自动扩展。EC2将把每一个数据传输任务的结果存储到DynamoDB中。下图为后端部分的架构。
综上所述,Data Transfer Hub数据在线传输解决方案具有以下特点:
三.方案部署
Data Transfer Hub方案可以在亚马逊云科技中国官网的解决方案栏页面启动,如下图所示,具体的部署教程请参考官方界面的“查看部署指南”。
您可以在亚马逊云科技中国区域部署该方案,也可以在亚马逊云科技海外区域进行部署。本教程将在us-west-2区域进行演示。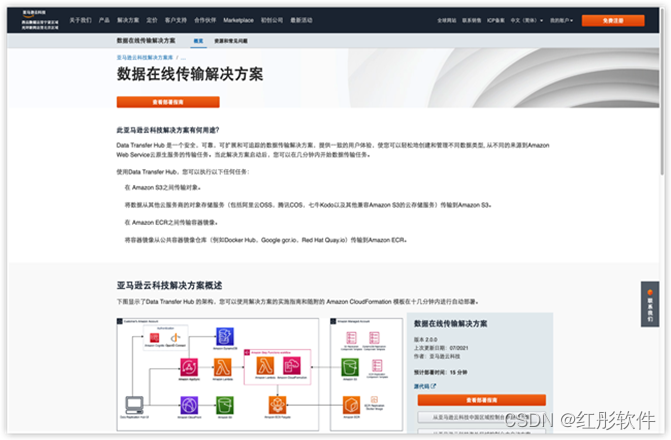
在成功创建CloudFormation堆栈后,您将收到一封电子邮件通知,其中包含用于登录的临时密码,用户名是您启动CloudFormation时设置的AdminEmail。
界面的网址可在CloudFormation堆栈的输出选项中找到,请参见以下屏幕截图:
随后请在浏览器中输入界面的URL,并使用您的用户名和临时密码登录,按指令更改临时密码,最后完成验证电子邮件(可选)。
四.方案使用
1.配置凭证
{
"access_key_id": "<Your Access Key ID>",
"secret_access_key": "<Your Access Key Secret>"
}
2.在界面中创建数据迁移任务





3.通过Cloudwatch 面板进行监控
点击任务下对应的CloudWatch链接,打开CloudWatch 面板对任务的相关数据进行监控。注意,任务第一次启动时,面板的监控指标数据可能会有5分钟左右的延迟。
在CloudWatch面板中,可以看到数据传输任务的相关性能指标:例如系统最大传输网络速度、已传输文件数、等待的任务总数、当前EC2实例数量以及Auto Scaling Group期望EC2实例数量等参数,具体如下图所示。
4.通过OSS事件触发器进行实时数据迁移
Data Transfer Hub支持将数据近乎实时地从阿里云OSS迁移到Amazon S3。 其原理为运用阿里云的计算函数将新增文件通过event的形式直接发送到Amazon SQS中,以实现数据传输任务的实时创建和消费。
1)预备工作
Data Transfer Hub 必须部署在亚马逊云科技的账户中,本教程假设您部署在 us-west-2区域. 在您创建task之后,前往SQS 控制台 并记下`Queue URL` 和 `Queue arn`, 我们将在后续步骤中用到他们.
2)准备您的亚马逊云科技账户的 AK/SK
前往 IAM 控制台, 点击创建一个新的策略(Create Policy).
点击 JSON,并将下面的权限Json文件输入到策略中。注意替换JSON中的Queue arn 为您前述步骤中的arn.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"sqs:SendMessage"
],
"Resource": "arn:aws:sqs:us-west-2:xxxxxxxxxxx:DTHS3Stack-S3TransferQueue-1TSF4ESFQEFKJ"
}
JSON

随后创建一个User. 前往 User 控制台 然后点击 添加用户(Add User).
然后将您先前创建的策略附加到该用户上。

保存 AK/SK,您将在下一步中使用它们。
3)准备阿里云中的发送函数
打开终端并输入以下命令,建议使用docker或linux机器。
mkdir tmp
cd tmp
pip3 install -t . boto3
随后在同一文件夹中创建 index.py,然后输入下述代码:
import json
import logging
import os
import boto3
def handler(event, context):
logger = logging.getLogger()
logger.setLevel('INFO')
evt = json.loads(event)
if 'events' in evt and len(evt['events']) == 1:
evt = evt['events'][0]
logger.info('Got event {}'.format(evt['eventName']))
obj = evt['oss']['object']
# logger.info(obj)
ak = os.environ['ACCESS_KEY']
sk = os.environ['SECRET_KEY']
queue_url = os.environ['QUEUE_URL']
region_name = os.environ['REGION_NAME']
# minimum info of a message
obj_msg = {
'key': obj['key'],
'size': obj['size']
}
# start sending the msg
sqs = boto3.client('sqs', region_name=region_name,
aws_access_key_id=ak, aws_secret_access_key=sk)
try:
sqs.send_message(
QueueUrl=queue_url,
MessageBody=json.dumps(obj_msg)
)
except Exception as e:
logger.error(
'Unable to send the message to Amazon SQS, Exception:', e)
else:
logger.warning('Unknown Message '+evt)
return 'Done'
打包代码(包括boto3)
zip -r code.zip *
4)在阿里云上创建函数
打开阿里云 函数计算/Function Compute的服务及函数, 点击 新建函数/create function
运用刚刚打包的zip文件创建函数
然后点击 新建/create
5)配置函数的环境变量
点击 修改配置/Edit Config
然后在“环境变量”中输入json配置文件,请记住使用自己的ACCESS_KEY,SECRET_KEY和QUEUE_URL
{
"ACCESS_KEY": "XXXXXXXXXXXXXXXXXXXXX",
"QUEUE_URL": "https://sqs.us-west-2.amazonaws.com/xxxx/DTHS3Stack-S3TransferQueue-xxxx",
"REGION_NAME": "us-west-2",
"SECRET_KEY": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
}

6)配置函数的环境变量
点击创建触发器以创建函数的触发器。
然后配置触发器,如下图所示。 触发事件, 请选择:
oss:ObjectCreated:PutObject
oss:ObjectCreated:PostObject
oss:ObjectCreated:CopyObject
oss:ObjectCreated:CompleteMultipartUpload
oss:ObjectCreated:AppendObject
7)MaxCompute表数据通过ODPS SQL输出到OSS
在Dataworks数据开发控制面板创建ODPS SQL,配置定时或触发调动任务,将数据以Parquet+LZO压缩格式导出至OSS
UNLOAD FROM $MAXCOMPUTE_INTERNAL_TABLE
INTO
LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/$BUCKET_NAME/$PATH'
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES ('odps.properties.rolearn'='acs:ram::$ID:role/$UPLOAD2OSS_ROLE')
stored as PARQUET
properties('mcfed.parquet.compression'='LZO');

五.常见问题和优化方法
1)Data Transfer Hub定时批量同步和OSS事件触发同步是否会冲突?
Data Transfer Hub默认每1小时进行批量同步。Data Transfer Hub会进行源端全量扫描将新建,更新和删除的文件进行同步。如果OSS事件触发的同步还在处理中,则会自动撤销批量同步,等待下一次定时批量同步。
2)如何确认文件是否传输完成?
有些业务要求必须在一组文件全部传输完成才能进行下一步处理。Data Transfer Hub会记录文件传输结果。可通过亚马逊云科技控制台或CLI查看DynamoDB文件传输记录,如下图所示:
3)为什么出现文件大小不一致?
如果文件大小很小且在很短的时间间隔内修改同一个文件以触发OSS事件,Worker多线程机制将无法保证事件顺序处理。


4)Multi-upload失败报错?
Cloudwatch日志中出现api error NoSuchUpload: The specified upload does not exist. The upload ID may be invalid, or the upload may have been aborted or completed报错
可能是由于大文件传输过程中文件没有被完整写入S3前有文件更改事件被触发。需要在s3桶内对[删除过期的删除标记或未完成的分段上传]配置生命周期的规则https://docs.aws.amazon.com/AmazonS3/latest/userguide/how-to-set-lifecycle-configuration-intro.html
六.总结
本文以MaxCompute数据迁移为例,阿里云OSS事件监听到数据表导出或外表创建,实时将数据同步至S3数据湖。除此之外,本方案也可以实现腾讯 COS、七牛 Kodo 和其他兼容 Amazon S3 的云存储服务的数据向Amazon S3的数据定时批量同步或实时增量同步。
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
如何正确创建Rails迁移,以便将表更改为MySQL中的MyISAM?目前是InnoDB。运行原始执行语句会更改表,但它不会更新db/schema.rb,因此当在测试环境中重新创建表时,它会返回到InnoDB并且我的全文搜索失败。我如何着手更改/添加迁移,以便将现有表修改为MyISAM并更新schema.rb,以便我的数据库和相应的测试数据库得到相应更新? 最佳答案 我没有找到执行此操作的好方法。您可以像有人建议的那样更改您的schema.rb,然后运行:rakedb:schema:load,但是,这将覆盖您的数据。我的做法是(假设
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h