目录
进程之间可能会存在特定的协同工作的场景,而协同就必须要进行进程间通信,协同工作可能有以下场景。
数据传输:一个进程需要将它的数据发送给另一个进程
资源共享:多个进程之间共享同样的资源。
通知事件:一个进程需要向另一个或一组进程发送消息,通知它发生了某种事件。
进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另 一个进程的所有陷入和异常,并能够及时知道它的状态改变
由于一个进程是不能访问到另一个进程的资源的,即进程之前是具有独立性的。
那么进程之间要通信,就不能使用属于进程的资源,而应该使用一份公共的资源。
所以进程间通信的本质是:由OS参与,提供一份所以进程都能访问的公共资源。
而公共资源是什么,例如:文件、队列、内存块。
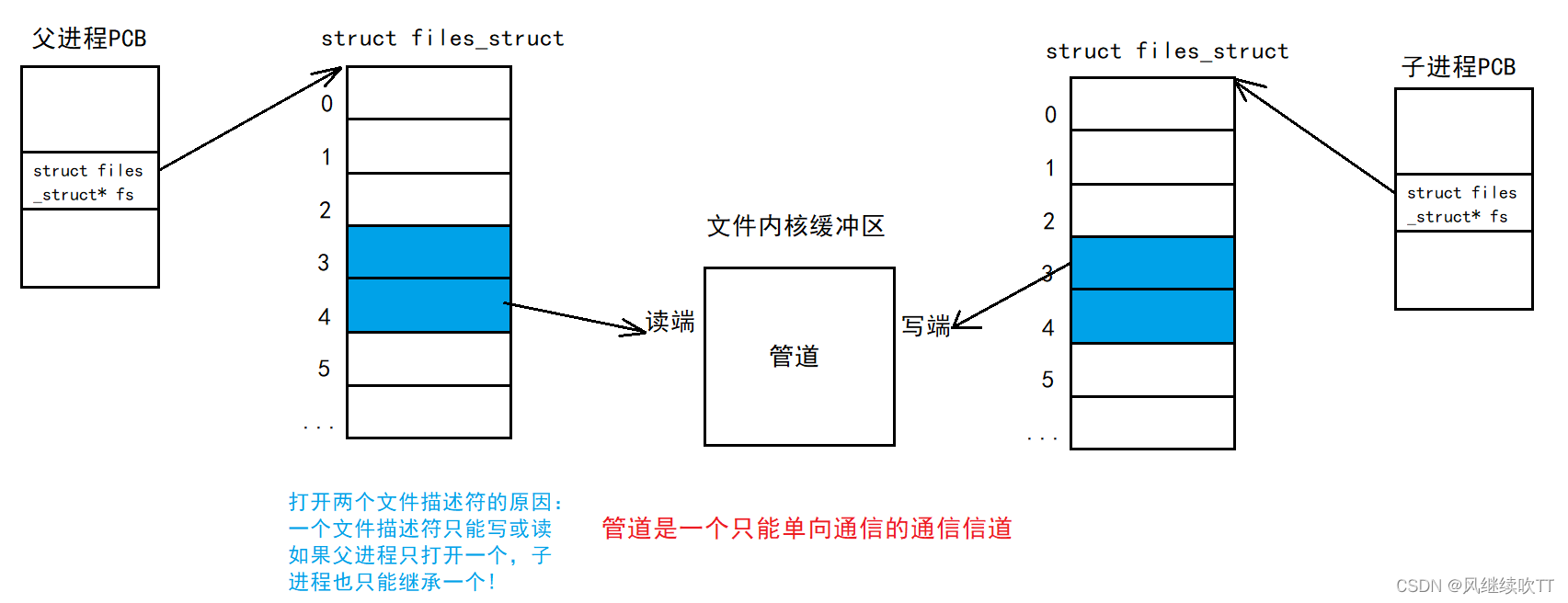
适用场景:父子进程间通信。
基本原理:通过打开同一个文件,父子进程对文件进行读写操作,父子进程在文件内核缓冲区中写入或读出数据,从而实现通信。
使用接口

pipe:创建一个管道,参数为输出型参数,打开两个文件描述符(fd),返回值为0表示打开失败。
具体代码:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
int main()
{
int pipefd[2] = {0};
if(pipe(pipefd) != 0)
{
perror("pipe");
return 1;
}
// 父进程读取数据,子进程写入数据
// 规定:pipedfd[0]为读取端,pipefd[1]为写入端
if(fork() == 0)
{
//child
close(pipefd[0]);// 关闭读取端
const char* msg = "hello world\n";
while(1)
{
write(pipefd[1], msg, strlen(msg));
sleep(1);
}
exit(0);
}
// father
close(pipefd[1]);// 关闭写入端
while(1)
{
char buffer[64] = {0};
ssize_t s = read(pipefd[0], buffer, sizeof(buffer));// 如果read的返回值是0,表示子进程关闭了文件描述符
if(s == 0)
{
printf("child quit\n");
break;
}
else if(s > 0)
{
buffer[s] = 0;// 子进程写入时没有添加'\0',需要手动添加
printf("child say:%s",buffer);
}
else
{
printf("read error\n");
break;
}
}
return 0;
}子进程写入数据,父进程读出数据,这样就实现了简单的父子进程间的通信:

问题分析:为什么上面的代码中,需保证读端比写端快?
因为管道是面向字节流的,字符串之间没由规矩分隔符,如果读取速度慢于写入速度,可能读端还没有将整个字符串读完,写端又写入了数据,会导致数据混乱。

匿名管道的五个特点:
只能单向通信的信道
面向字节流
只能在父子进程间通信
管道自带同步机制,原子性写入
管道也是文件,管道的生命周期随进程
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
int main()
{
int pipefd[2] = {0};
if(pipe(pipefd) != 0)
{
perror("pipe");
return 1;
}
if(fork() == 0)
{
//child
close(pipefd[0]);// 关闭读取端
int count = 0;
char c = 'a';
while(1)
{
write(pipefd[1], &c, 1);
count++;
printf("%d\n", count);
}
exit(0);
}
// father
close(pipefd[1]);// 关闭写入端
while(1)
{
sleep(5);
char buffer[4*1024+1] = {0};
ssize_t s = read(pipefd[0], buffer, sizeof(buffer)-1);
buffer[s] = 0;
printf("father take:%s\n", buffer);
}
return 0;
}
云服务器中,管道的大小为64KB,写端写满后不会再写,会等读端读取管道内容,且读取4KB后才会重新写入(读端的容量为4KB)。

管道读写规则
当没有数据可读时
O_NONBLOCK disable:read调用阻塞,即进程暂停执行,一直等到有数据来到为止。 O_NONBLOCK enable:read调用返回-1,errno值为EAGAIN。
当管道满的时候
O_NONBLOCK disable: write调用阻塞,直到有进程读走数据
O_NONBLOCK enable:调用返回-1,errno值为EAGAIN
如果所有管道写端对应的文件描述符被关闭,则read返回0 如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程退出
当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。
当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。
即匿名管道的四种情况:
读端不读或读的慢,写端要等读端
读端关闭,写端收到SIGPIPE信号直接终止
写端不写或者写的慢,读端要等写端
写端关闭,读端会读完管道内的数据然后再读,会读到0,表示读道文件结尾
为了解决匿名管道只能在父子进程间通信的缺陷,引入了命名管道。
其性质除了能让任意进程间通信外,与匿名管道基本一致,即创建一个文件一个进程往文件中写数据,一个进程读数据,且不让文件内容刷新到磁盘上,从而实现任意进程间的通信。
命令行创建
使用命令 mkfifo 管道
 然后使用一个简单的shell脚本,将 hello world 每间隔一秒输入到管道中,然后另一边读取管道中的内容。
然后使用一个简单的shell脚本,将 hello world 每间隔一秒输入到管道中,然后另一边读取管道中的内容。
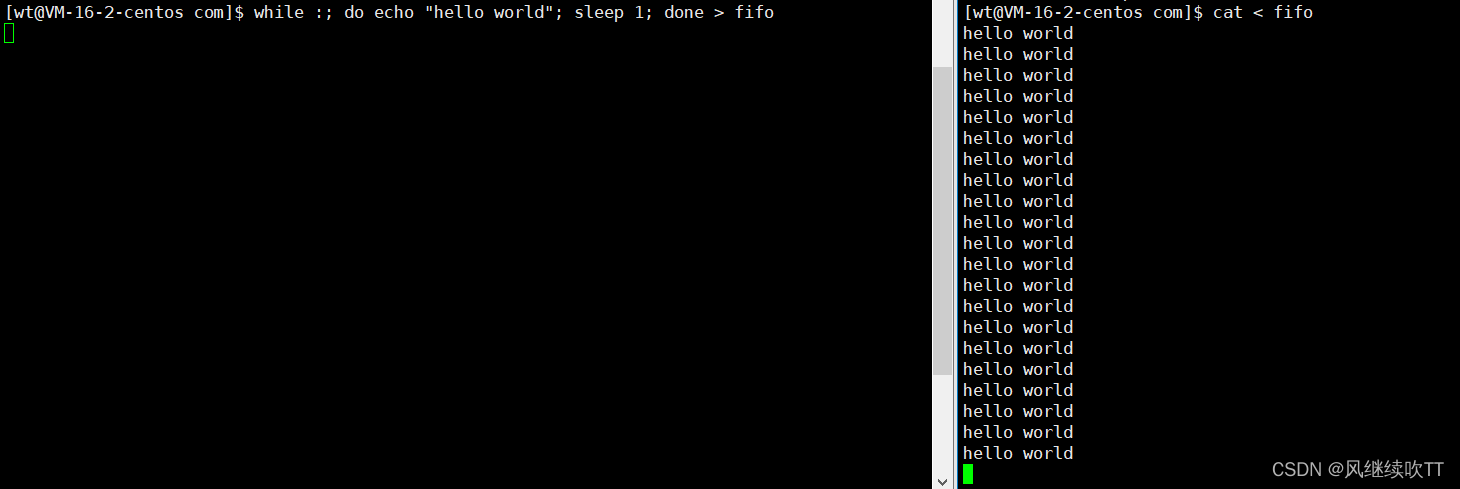
通过这种方式,显示不是重点。
代码创建
使用接口:mkfifo

因为是不同进程间的通信,所以这里需要创建两个进程:
comm.h
#include<string.h> #include<stdio.h> #include<sys/stat.h> #include<sys/types.h> #include<fcntl.h> #include<unistd.h> #define MY_FIFO "./fifo"server.c#include"comm.h" int main() { umask(0); if(mkfifo(MY_FIFO, 0666) < 0) //创建命名管道 { perror("mkfifo"); return 1; } // 只需要文件操作即可 int fd = open(MY_FIFO, O_RDONLY); if(fd < 0) { perror("open"); return 2; } // 业务逻辑 while(1) { char buffer[64] = {0}; ssize_t s = read(fd, buffer, sizeof(buffer)-1); if(s > 0) { buffer[s] = 0; printf("client-> %s\n", buffer); } else if(s == 0) { printf("client quit...\n"); break; } else { perror("read"); break; } } close(fd); return 0; }client.c
#include"comm.h" int main() { int fd = open(MY_FIFO, O_WRONLY); if(fd < 0) { perror("open"); return 1; } // 业务逻辑 while(1) { printf("请输入-> "); fflush(stdout); char buffer[64] = {0}; ssize_t s = read(0, buffer, sizeof(buffer)-1); // 从显示器上读取数据,然后写入到文件中 if(s > 0) { buffer[s-1] = 0; printf("%s\n", buffer); write(fd, buffer, strlen(buffer)); } } return 0; }
运行起来后,就实现了简单的命名管道的通信:

为什么命名管道有名字,而匿名管道没有?
命名管道有名字是为了保证让不同进程看到同一个文件。
匿名管道没有名字,是因为他是通过父子继承放入方式,看到同一份资源不需要名字。
system V:同一主机内的进程间通信方案,在OS层面专门为进程间通信设计的方案
进程间通信的本质:让不同的进程看到同一份资源
system V标准下的三种通信方式
共享内存
消息队列
信号量
通过系统调用,在内存中创建一份内存空间
通过系统调用,让进程"挂接"到这份新开辟的内存空间上(即在页表上建立虚拟地址与物理地址的映射关系)
去关联(挂接)
释放共享内存
使用接口:
shmget:申请共享内存
#include <sys/ipc.h> #include <sys/shm.h> int shmget(key_t key, size_t size, int shmflg); // key:创建共享内存时的算法和数据结构中唯一标识符,由用户自己设定需用到接口ftok // size:共享内存的大小,建议是4KB的整数倍 // shmflg:有两个选项:IPC_CREAT(0),创建一个共享内存,如果已经存在则返回共享内存;IPC_EXCL(单独使用没有意义) // IPC_CREAT|IPC_EXCL(如果调用成功,一定会得到一个全新的共享内存):如果不存在共享内存,就创建;反之,返回出错 // 返回值:shmdi,描述共享内存的标识符 #include <sys/types.h> #include <sys/ipc.h> key_t ftok(const char *pathname, int proj_id); // 算法生成key // pathname:自定义路径名 // proj_id:自定义项目id
shmctl:控制共享内存
#include <sys/ipc.h> #include <sys/shm.h> int shmctl(int shmid, int cmd, struct shmid_ds *buf); // shmid:共享内存id // cmd:控制方式,这里我们只使用IPC_RMID 选项,表示删除共享内存 // buf:描述共享内存的数据结构struct_shmid_ds结构体:
shmat、shmdt:关联、去关联共享内存
#include <sys/types.h> #include <sys/shm.h> void *shmat(int shmid, const void *shmaddr, int shmflg); // 关联 // shmid:共享内存id // shmaddr:挂接地址(自己不知道地址,所以默认为NULL) // shmflg:挂接方式,默认为0 // 返回值:挂接成功返回共享内存起始地址(虚拟地址),类似C语言malloc int shmdt(const void *shmaddr); // 去关联(取消当前进程和共享内存的关系) // shmaddr:去关联内存地址,即shmat返回值 // 返回值:调用成功返回0,失败返回-1
命令行查看共享内存:
ipcs -m // ipcs 查看ipc资源
system V 的IPC资源,生命周期随内核,只能通过程序员显示释放(或者OS重启)
命令行删除共享内存方法:
ipcrm -m shmid
comm.h
#include<stdio.h> #include<sys/ipc.h> #include<sys/types.h> #include<sys/shm.h> #include<unistd.h> #include<string.h> #define PATH_NAME "./" #define PROJ_ID 0x6666 #define SIZE 4096server.c
#include"comm.h" int main() { key_t key = ftok(PATH_NAME, PROJ_ID); if(key < 0) { perror("ftok"); return 1; } printf("key-> %x\n", key); int shmid = shmget(key, SIZE, IPC_CREAT|IPC_EXCL|0666); // 创建全新共享内存 if(shmid < 0) { perror("shmget"); return 1; } printf("shmid-> %d\n", shmid); char* mem = (char*)shmat(shmid, NULL, 0); // 通信逻辑 while(1) { printf("%s\n", mem);// 打印mem内存中的内容 sleep(1); } shmdt(mem); shmctl(shmid, IPC_RMID, NULL); return 0; }client.c
#include"comm.h" int main() { key_t key = ftok(PATH_NAME, PROJ_ID); if(key < 0) { perror("ftok"); return 1; } int shmid = shmget(key, SIZE, IPC_CREAT); if(shmid < 0) { perror("shmget"); return 1; } // 挂接 char* mem = (char*)shmat(shmid, NULL, 0); // 通信逻辑 char c = 'A'; while(c <= 'Z') { mem[c - 'A'] = c; c++; mem[c - 'A'] = 0; sleep(2); } // 去关联 shmdt(mem); //该共享内存不由client创建,所以不用它删除 return 0; }
运行结果:

使用共享内存进行通信时,不需要使用read和write 接口。
共享内存是所有进程间通信中速度最快的。
共享内存不提供任何同步或互斥机制,需要程序员自行保证数据安全。
ps: 共享内存在内核中的申请的基本单位是页,内存页的大小为4KB,如果申请4097个字节,内核会分配8KB空间。
接口类似与共享内存,底层是一个队列结构
msgget:创建消息队列
#include <sys/types.h> #include <sys/ipc.h> #include <sys/msg.h> int msgget(key_t key, int msgflg);msgctl:控制消息队列
#include <sys/types.h> #include <sys/ipc.h> #include <sys/msg.h> int msgctl(int msqid, int cmd, struct msqid_ds *buf);
什么是信号量?
信号量不是以传输数据为目的,通过共享“资源”的方式,来达到多个进程的同步和互斥的目的!
本质是一个计数器,衡量临界资源中的资源数目。
临界资源:同时被多个进程访问的资源。例如:显示器打印,共享内存,消息队列
临界区:用来访问临界资源的代码,就是临界区。
原子性:执行事件时没有中间过程,且操作不可中断,要么执行完,要么没有执行。
互斥:在任意时刻,只允许一个进程进入临界资源。
同步:两个或多个数据库、文件、模块、线程之间用来保持数据内容一致性的机制。
接口类似共享内存
semget:创建信号量
#include <sys/types.h> #include <sys/ipc.h> #include <sys/sem.h> int semget(key_t key, int nsems, int semflg);semctl:控制信号量
#include <sys/types.h> #include <sys/ipc.h> #include <sys/sem.h> int semctl(int semid, int semnum, int cmd, ...);
所有的ipc资源都是通过数组组织起来的。
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
我正在尝试使用以下代码通过将ffmpeg实用程序作为子进程运行并获取其输出并解析它来确定视频分辨率:IO.popen'ffmpeg-i'+path_to_filedo|ffmpegIO|#myparsegoeshereend...但是ffmpeg输出仍然连接到标准输出并且ffmepgIO.readlines是空的。ffmpeg实用程序是否需要一些特殊处理?或者还有其他方法可以获得ffmpeg输出吗?我在WinXP和FedoraLinux下测试了这段代码-结果是一样的。 最佳答案 要跟进mouviciel的评论,您需要使用类似pope
我目前正在用Ruby编写一个项目,它使用ActiveRecordgem进行数据库交互,我正在尝试使用ActiveRecord::Base.logger记录所有数据库事件具有以下代码的属性ActiveRecord::Base.logger=Logger.new(File.open('logs/database.log','a'))这适用于迁移等(出于某种原因似乎需要启用日志记录,因为它在禁用时会出现NilClass错误)但是当我尝试运行包含调用ActiveRecord对象的线程守护程序的项目时脚本失败并出现以下错误/System/Library/Frameworks/Ruby.frame
我想从rubyrake脚本运行一个可执行文件,比如foo.exe我希望将foo.exe的STDOUT和STDERR输出直接写入我正在运行rake任务的控制台.当进程完成时,我想将退出代码捕获到一个变量中。我如何实现这一目标?我一直在玩backticks、process.spawn、system但我无法获得我想要的所有行为,只有部分更新:我在Windows上,在标准命令提示符下,而不是cygwin 最佳答案 system获取您想要的STDOUT行为。它还返回true作为零退出代码,这可能很有用。$?填充了有关最后一次system调
A/ctohttp://wiki.nginx.org/CoreModule#usermaster进程曾经以root用户运行,是否可以以不同的用户运行nginxmaster进程? 最佳答案 只需以非root身份运行init脚本(即/etc/init.d/nginxstart),就可以用不同的用户运行nginxmaster进程。如果这真的是你想要做的,你将需要确保日志和pid目录(通常是/var/log/nginx&/var/run/nginx.pid)对该用户是可写的,并且您所有的listen调用都是针对大于1024的端口(因为绑定(
我有一个应用程序正在从Ruby迁移到JRuby(由于需要通过Java提供更好的Web服务安全支持)。我使用的gem之一是daemons创建后台作业。问题在于它使用fork+exec来创建后台进程,但这对JRuby来说是禁忌。那么-是否有用于创建后台作业的替代gem/wrapper?我目前的想法是只从shell脚本调用rake并让rake任务永远运行......提前致谢,克里斯。更新我们目前正在使用几个与Java线程相关的包装器,即https://github.com/jmettraux/rufus-scheduler和https://github.com/philostler/acts
在尝试实现应用auto_orient的过程之后!对于我的图片,我收到此错误:ArgumentError(noimagesinthisimagelist):app/uploaders/image_uploader.rb:36:in`fix_exif_rotation'app/controllers/posts_controller.rb:12:in`create'Carrierwave在没有进程的情况下工作正常,但在添加进程后尝试上传图像时抛出错误。流程如下:process:fix_exif_rotationdeffix_exif_rotationmanipulate!do|image|
