在 Docker Desktop 4.17.0 版本中,可以按照以下步骤来修改 Docker 镜像存储路径
打开 Docker Desktop 应用程序,单击顶部菜单栏中的 Docker Desktop 菜单,然后选择 Resources(资源)选项卡。
在 Resources 选项卡中,选择 Advanced部分。
在Disk image location配置中点击Brower进行浏览路径
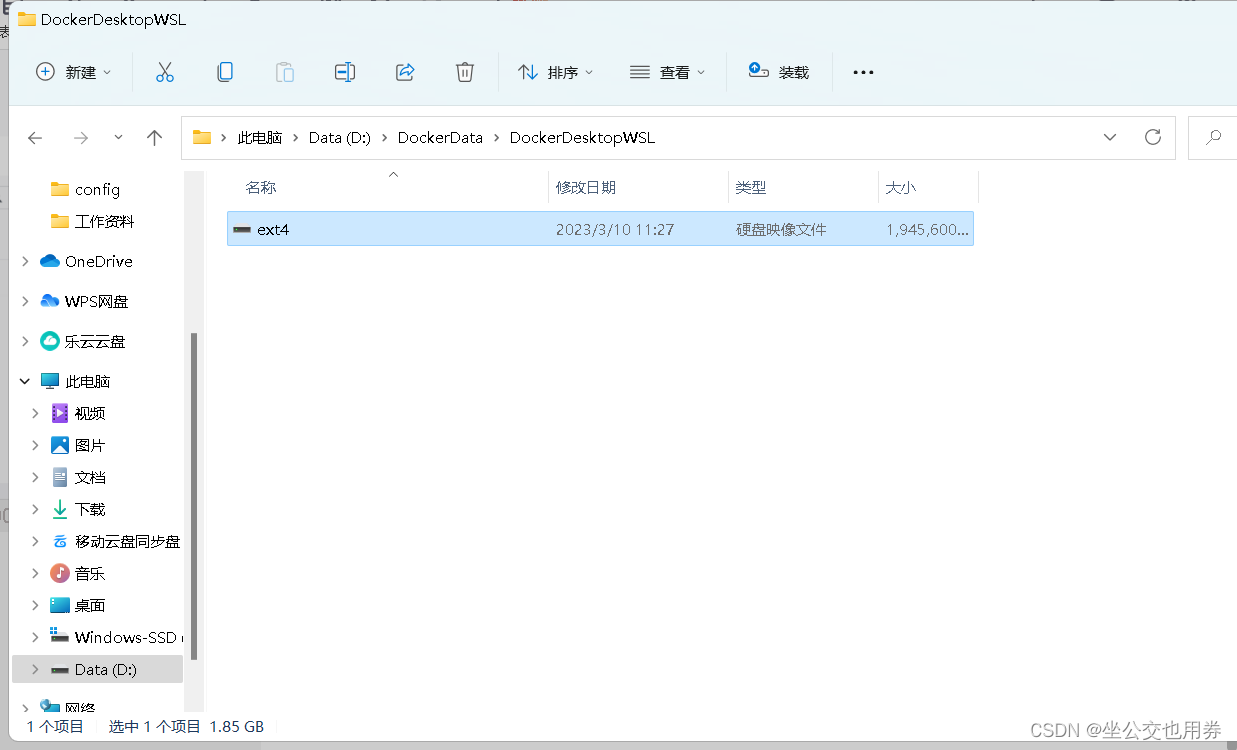
在弹出的对话框中,选择新的存储路径,然后单击 Apply & Restart(应用并重启)按钮以保存更改并重启 Docker。
重启后,Docker 镜像将被移动到新的存储路径。
请注意,在更改 Docker 镜像存储路径时,请确保选择的新路径具有足够的可用磁盘空间。在镜像迁移期间,请不要关闭
Docker Desktop应用程序。
如图
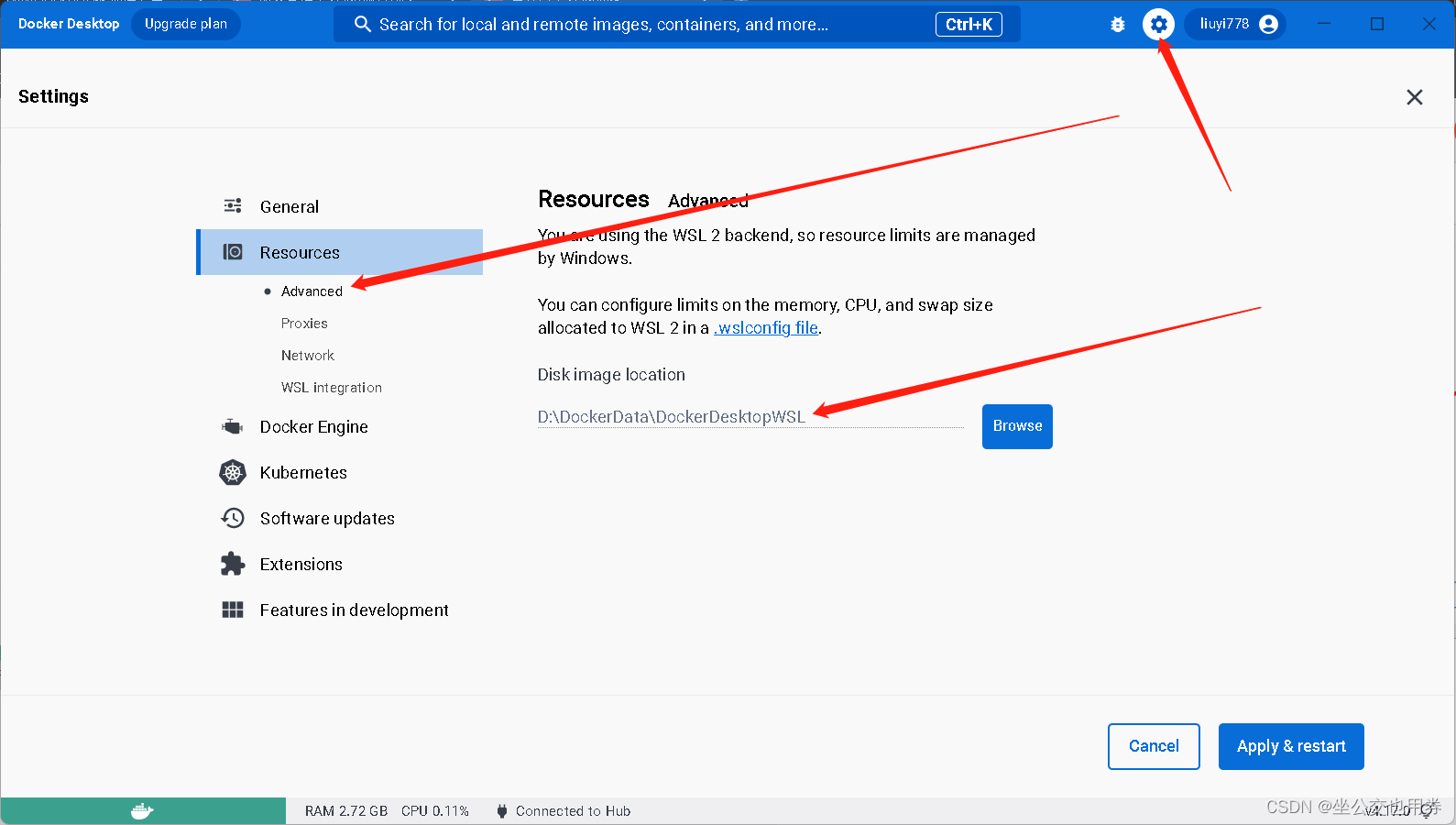
如果提示
You are using the WSL 2 backend, so resource limits are managed by Windows.请使用下面的方法修改
Wsl容器进行下面的操作之前,请先停止容器和Docker的运行
PS C:\Users\td> wsl --export docker-desktop-data "D:\DockerData\data.tar"
正在导出,这可能需要几分钟时间。
操作成功完成。
PS C:\Users\td> wsl --unregister docker-desktop-data
正在注销。
操作成功完成。
wsl --unregister docker-desktop-data
语法
wsl --import docker-desktop-data <新的存储路径> <需要导入的数据文件> --version <Wsl版本>
如下
PS C:\Users\td> wsl --import docker-desktop-data "D:\DockerData\DockerDesktopWSL" "D:\DockerData\data.tar" --version 2
正在导入,这可能需要几分钟时间。
操作成功完成。
导入成功之后就可以启动Docker了
PS C:\Users\td> wsl -l -v
NAME STATE VERSION
* docker-desktop-data Running 2
docker-desktop Running 2
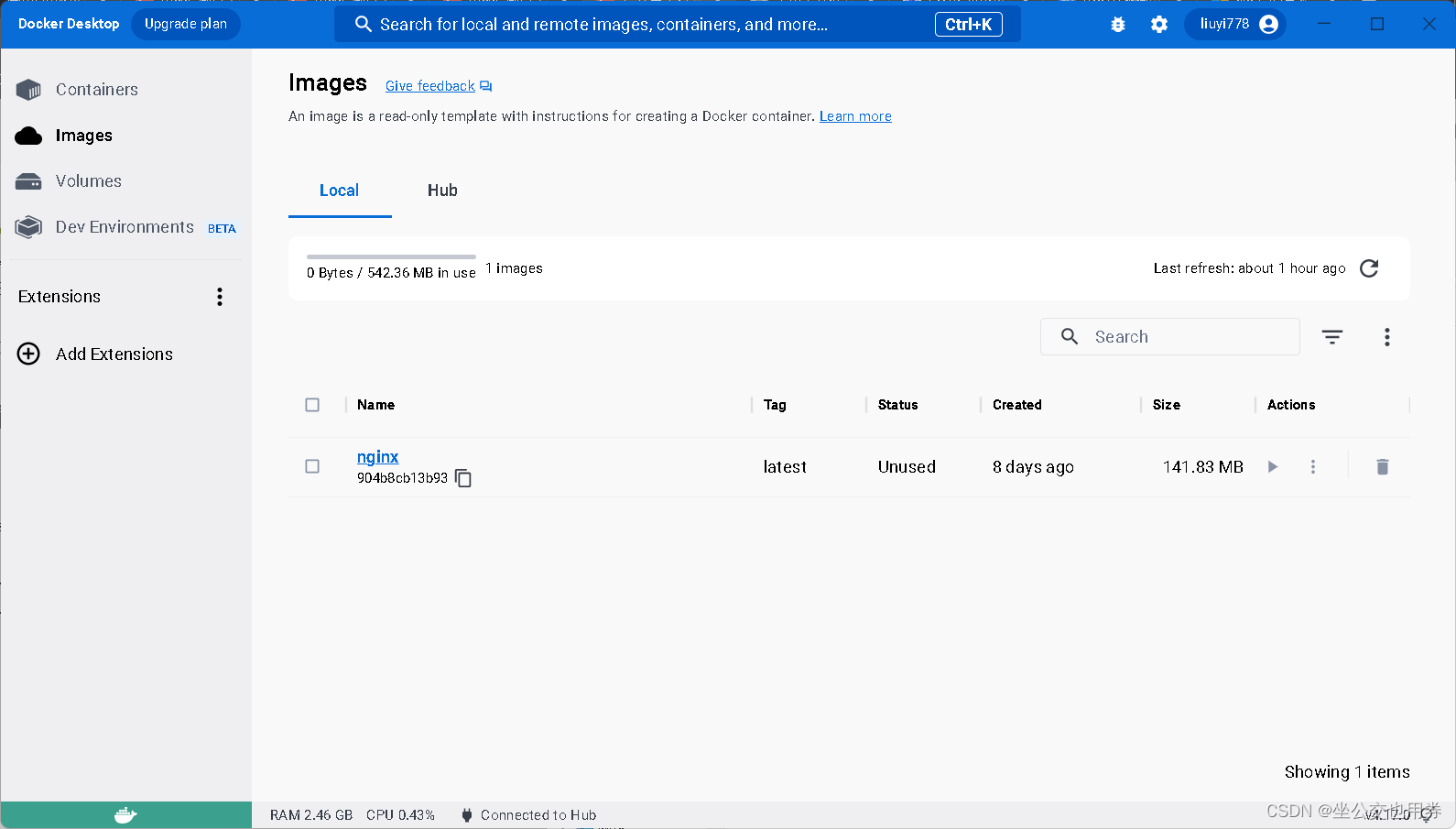
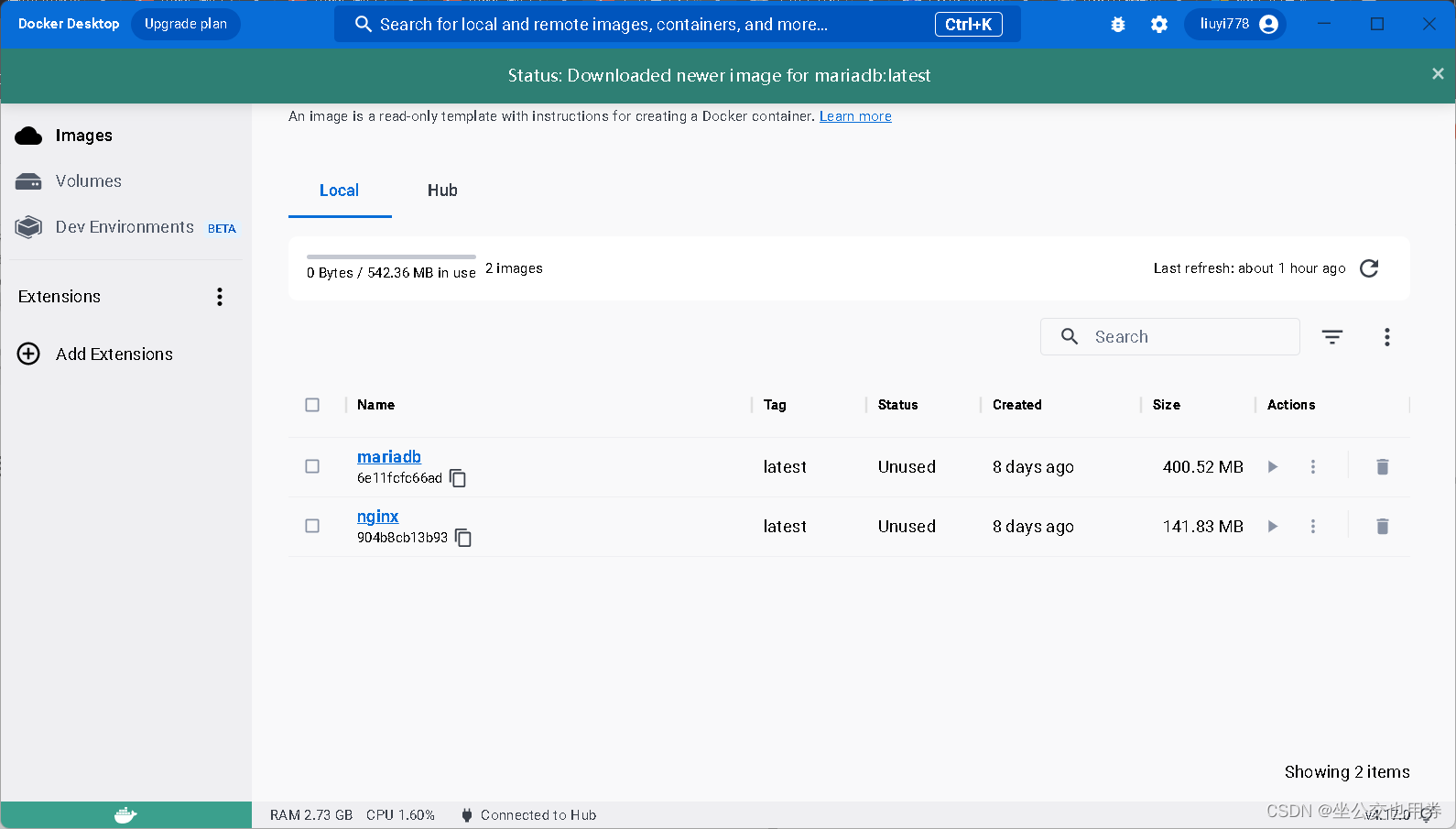
可以看到,拉取了新的镜像之后,数据大小也相应的增加了
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
我正在编写一个简单的静态Rack应用程序。查看下面的config.ru代码:useRack::Static,:urls=>["/elements","/img","/pages","/users","/css","/js"],:root=>"archive"map'/'dorunProc.new{|env|[200,{'Content-Type'=>'text/html','Cache-Control'=>'public,max-age=6400'},File.open('archive/splash.html',File::RDONLY)]}endmap'/pages/search.
如何使此根路径转到:“/dashboard”而不仅仅是http://example.com?root:to=>'dashboard#index',:constraints=>lambda{|req|!req.session[:user_id].blank?} 最佳答案 您可以通过以下方式实现:root:to=>redirect('/dashboard')match'/dashboard',:to=>"dashboard#index",:constraints=>lambda{|req|!req.session[:user_id].b
最近因为项目需要,需要将Android手机系统自带的某个系统软件反编译并更改里面某个资源,并重新打包,签名生成新的自定义的apk,下面我来介绍一下我的实现过程。APK修改,分为以下几步:反编译解包,修改,重打包,修改签名等步骤。安卓apk修改准备工作1.系统配置好JavaJDK环境变量2.需要root权限的手机(针对系统自带apk,其他软件免root)3.Auto-Sign签名工具4.apktool工具安卓apk修改开始反编译本文拿Android系统里面的Settings.apk做demo,具体如何将apk获取出来在此就不过多介绍了,直接进入主题:按键win+R输入cmd,打开命令窗口,并将路
我去了这个website查看Rails5.0.0和Rails5.1.1之间的区别为什么5.1.1不再包含:config/initializers/session_store.rb?谢谢 最佳答案 这是删除它的提交:Setupdefaultsessionstoreinternally,nolongerthroughanapplicationinitializer总而言之,新应用没有该初始化器,session存储默认设置为cookie存储。即与在该初始值设定项的生成版本中指定的值相同。 关于
我需要根据字符串路径的长度将字符串路径数组转换为符号、哈希和数组的数组给定以下数组:array=["info","services","about/company","about/history/part1","about/history/part2"]我想生成以下输出,对不同级别进行分组,根据级别的结构混合使用符号和对象。产生以下输出:[:info,:services,about:[:company,history:[:part1,:part2]]]#altsyntax[:info,:services,{:about=>[:company,{:history=>[:part1,:pa
我正在关注Hartl的railstutorial.org并已到达11.4.4:Imageuploadinproduction.我做了什么:注册亚马逊网络服务在AmazonIdentityandAccessManagement中,我创建了一个用户。用户创建成功。在AmazonS3中,我创建了一个新存储桶。设置新存储桶的权限:权限:本教程指示“授予上一步创建的用户读写权限”。但是,在存储桶的“权限”下,未提及新用户名。我只能在每个人、经过身份验证的用户、日志传送、我和亚马逊似乎根据我的名字+数字创建的用户名之间进行选择。我已经通过选择经过身份验证的用户并选中了上传/删除和查看权限的框(而不
Organization和Image具有一对一的关系。Image有一个名为filename的列,它存储文件的路径。我在Assets管道中包含这样一个文件:app/assets/other/image.jpg。播种时如何包含此文件的路径?我已经在我的种子文件中尝试过:@organization=...@organization.image.create!(filename:File.open('app/assets/other/image.jpg'))#Ialsotried:#@organization.image.create!(filename:'app/assets/other/i
我正在使用mechanize登录网站,然后检索页面。我遇到了一些问题,我怀疑这是由于cookie中的某些值造成的。当Mechanize登录网站时,我假设它存储了cookie。如何通过Mechanize打印出存储在cookie中的所有数据? 最佳答案 代理有一个cookie方法。agent=Mechanize.newpage=agent.get("http://www.google.com/")agent.cookiesagent.cookies.to_scookie返回一个Mechanize::Cookiesobject