1、本文将介绍如何添加自定义StarRocks服务托管在CDH上,需要按照一定的规则流程制作相关程序包,最后发布到CDH上。
链接:https://pan.baidu.com/s/1nT0BgUutW66cyiu2C_jqIg
提取码:Acdy
a. cm添加starrocks服务

b. cm管理starrocks

c. cm启停配置参数,以及日志管理等
制作完成的parcel包和csd jar包需要校验其合法性,cdh提供了jar方便我们对制作完成parcel包和csd jar进行校验。
下载地址见: https://github.com/cloudera/cm_ext
一个完整的集成到CDH的parcel包应包含如下几个包,下面会介绍这几个包如何制作:

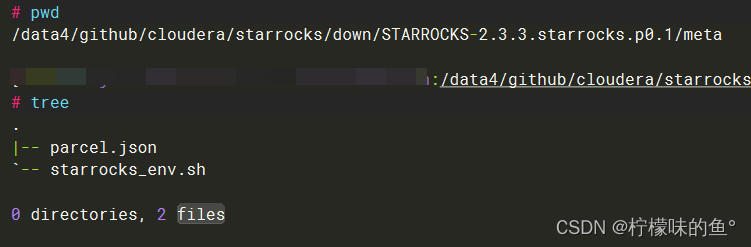
Parcel包目录结构由你的服务目录和一个meta目录组成。meta目录组成文件如下:
parcel.json: 这个文件记录了你的服务信息,如版本、所属用户、适用的CDH平台版本等。
starrocks_env.sh: 声明你的服务运行时的所需的一些变量环境,可以根据你的服务需要可以自行添加设置。
parcel:以".parcel“结尾的gz格式的压缩文件。它必须为一个固定规则的文件名。
parcel包内包含了你的服务组件,同时包含一个重要的描述性文件parcel.json;这个文件记录了你的服务信息,如版本、所属用户、适用的CDH平台版本等parcel必须包置于/opt/cloudera/parcel-repo/目录下才可以被CDH发布程序时识别到。
文件名称格式为三段,第一段是包名,第二段是版本号,第三段是运行平台。
例如:STARROCKS-2.3.3.starrocks.p0.1-el7.parcel
包名:STARROCKS
版本号:2.3.3.starrocks.p0.1
运行环境:el7
el6是代表centos6系统,centos7则用el7表示
STARROCKS-2.3.3.jar文件是一个jar包,它记录了你的服务在CDH上的管理规则,如你的服务在CDH页面上显示的图标、依赖的服务、暴露的端口、启动规则等。csd的jar包必须置于/opt/cloudera/csd/目录才可以在添加集群服务时被识别到(下面有相关介绍如如打csd包)。
1、下载官方 StarRocks 安装包,解压相关软件包,下载地址如下:
官方下载地址:
https://www.starrocks.com/zh-CN/download/community
wget 直接下载:
wget https://download.starrocks.com/zh-CN/download/request-download/59/StarRocks-2.3.3.tar.gz -P /app
2、下载完解压相关tar包
解压 StarRocks-2.3.3.tar.gz:
tar -xzvf /app/StarRocks-2.3.3.tar.gz -C /app

3、创建 meta目录
mkdir /app/StarRocks-2.3.3/meta
4、添加parcel.json、starrocks_env.sh 相关文件
相关参数详解:https://github.com/cloudera/cm_ext/wiki/The-parcel.json-file
cat /app/StarRocks-2.3.3/meta/parcel.json
{
"schema_version": 1,
"name": "STARROCKS",
"version": "2.3.3.starrocks.p0.1",
"setActiveSymlink": true,
"depends": "CDH (>= 5.2)",
"provides": [
"starrocks"
],
"scripts": {
"defines": "starrocks_env.sh"
},
"packages": [
{ "name" : "starrocks",
"version": "2.3.3.starrocks.p0.1"
}
],
"components": [
{ "name" : "starrocks",
"version" : "2.3.3",
"pkg_version": "2.3.3"
}
],
"users": {
"starrocks": {
"longname" : "starrocks",
"home" : "/var/lib/starrocks",
"shell" : "/bin/bash",
"extra_groups": ["starrocks"]
}
},
"groups": [
"starrocks"
]
}
cat /app/StarRocks-2.3.3/meta/starrocks_env.sh
#!/bin/bash
export STARROCKS_HOME=$PARCELS_ROOT/$PARCEL_DIRNAME
5、打parcel包
tar -zcvf STARROCKS-2.3.3.starrocks.p0.1-el7.parcel STARROCKS-2.3.3.starrocks.p0.1

6、验证打包是否正常
java -jar /data/build/build/cm_ext/cm_ext/validator/target/validator.jar -f /data4/github/cloudera/starrocks/down/STARROCKS-2.3.3.starrocks.p0.1-el7.parcel

7、生成.sha哈希校验文件。
sha1sum /data4/github/cloudera/starrocks/down/STARROCKS-2.3.3.starrocks.p0.1-el7.parcel
echo '547daca12f140748b629d28deea0cc404981c4f0' > /data4/github/cloudera/starrocks/down/STARROCKS-2.3.3.starrocks.p0.1-el7.parcel.sha

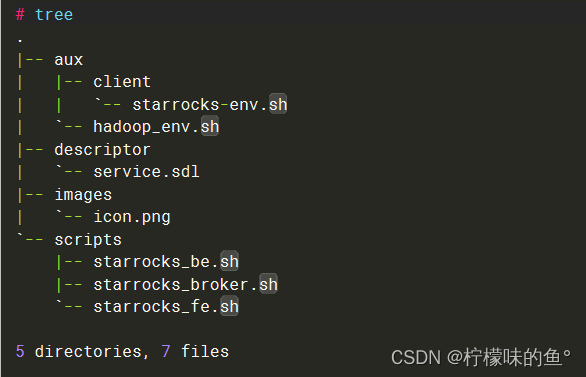
aux:CSD 可以选择有一个aux目录。辅助文件可以存在于此目录中,如果存在,也会与scripts目录一起向下发送到代理。
descriptor: CSD 的核心是服务描述符语言 (SDL) 文件:descriptor/service.sdl. 这是一个 json 文件,描述了如何管理与 CSD 同名的服务类型。该文件包括:
服务类型和相关的角色类型
如何启动服务/角色
服务和角色类型的参数
附加命令
配置文件生成器
images: 放置服务的图标文件,png格式。不放图标文件,则CDH页面不显示图标。
scripts: 该目录包含所有用于控制底层服务的可执行脚本。service.sdl文件通过脚本运行程序引用这些脚本。
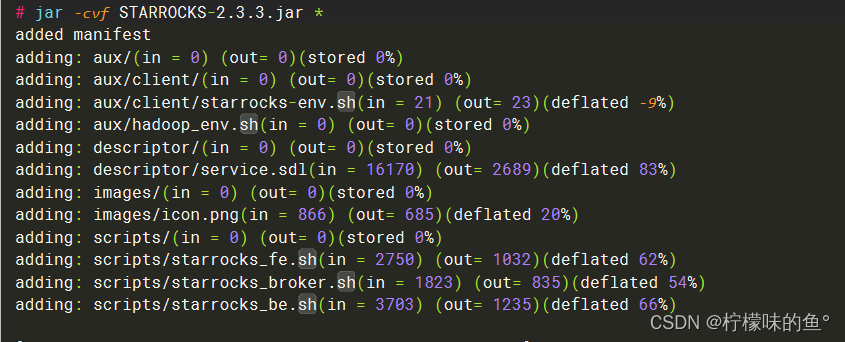
java -jar /data/build/build/cm_ext/cm_ext/validator/target/validator.jar -s /csd-src/descriptor/service.sdl

cd /csd-src
jar -cvf STARROCKS-2.3.3.jar *
1、将parcel包和parcel.sha拷贝到cm节点的/opt/cloudera/parcel-repo/目录


2、将csd jar包拷贝到/opt/cloudera/csd目录下

3、执行重启 cloudera-scm-server
systemctl restart cloudera-scm-server
4、分配 激活 Parcel包


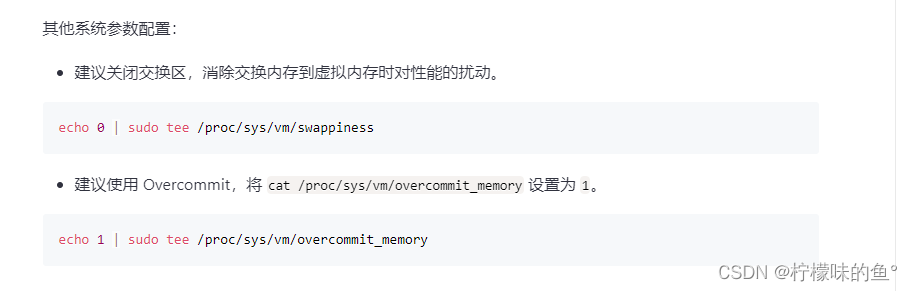
echo 0 | sudo tee /proc/sys/vm/swappiness
echo 1 | sudo tee /proc/sys/vm/overcommit_memory
# 临时关闭swap
swapoff -a
# 永久关闭,注释 /etc/fstab
sed -i '/swap/s/^/#/' /etc/fstab
# 关闭优化交换分区
echo "vm.swappiness=0" >> /etc/sysctl.conf
sysctl -p
1、点击添加服务
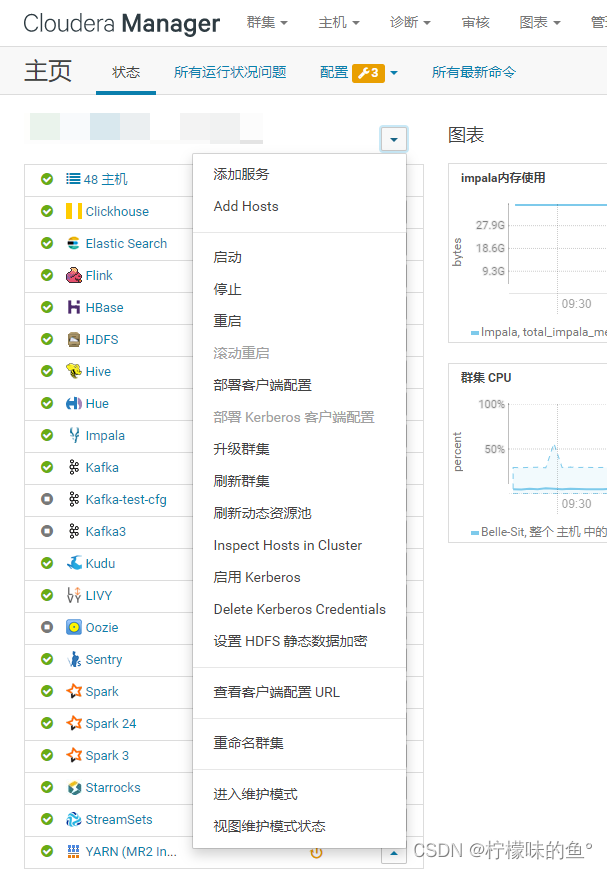
2、选择添加starrocks服务
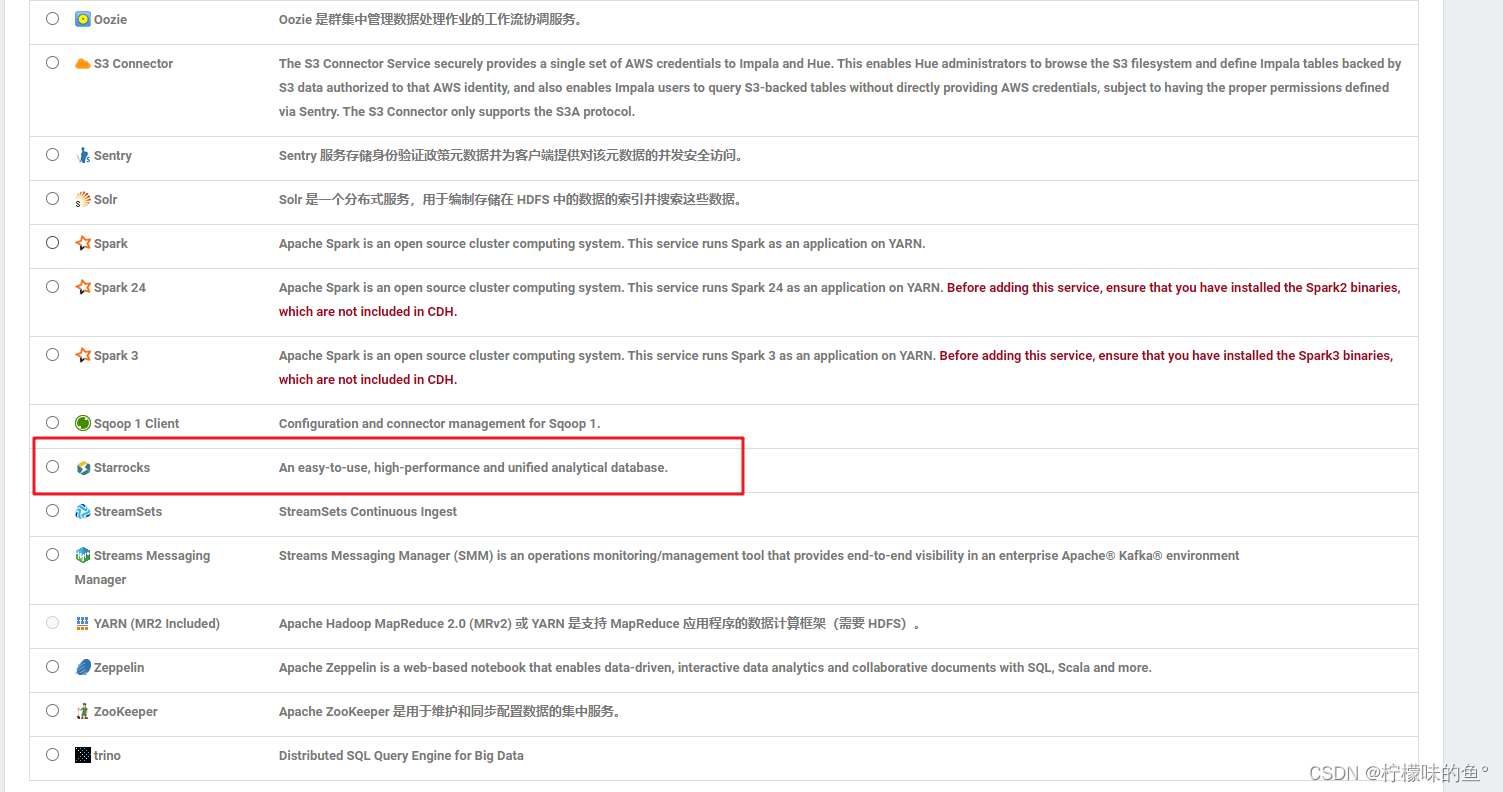
3、因为有适配 hive外部表,所以这里依赖 hdfs、hive服务(可选,如果没有hive外表需求,可以选无)
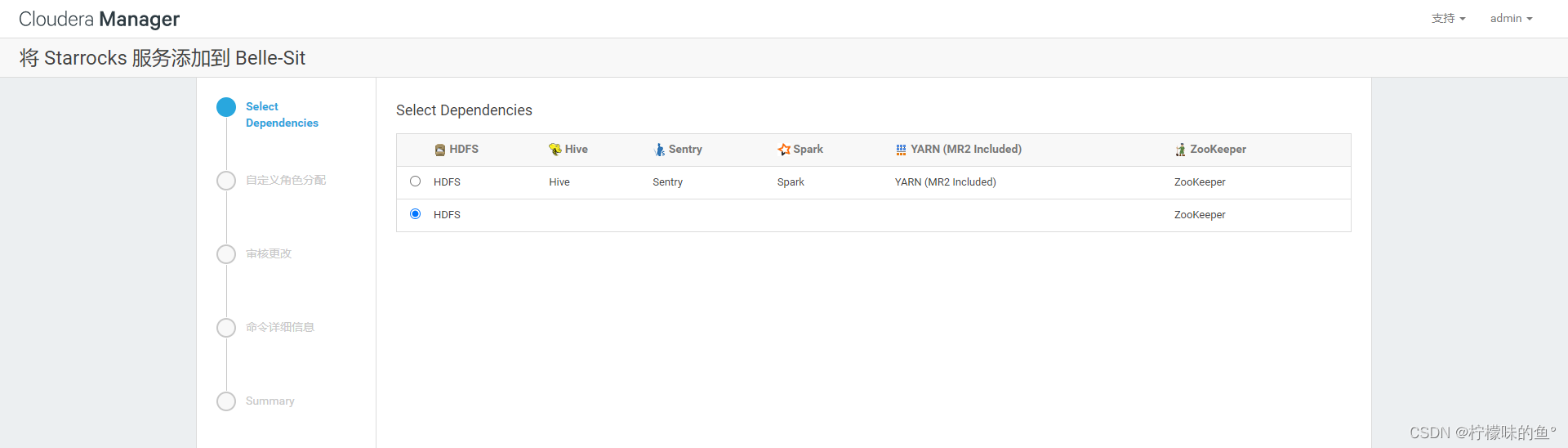
4、选择 Fe、Be、 Broker
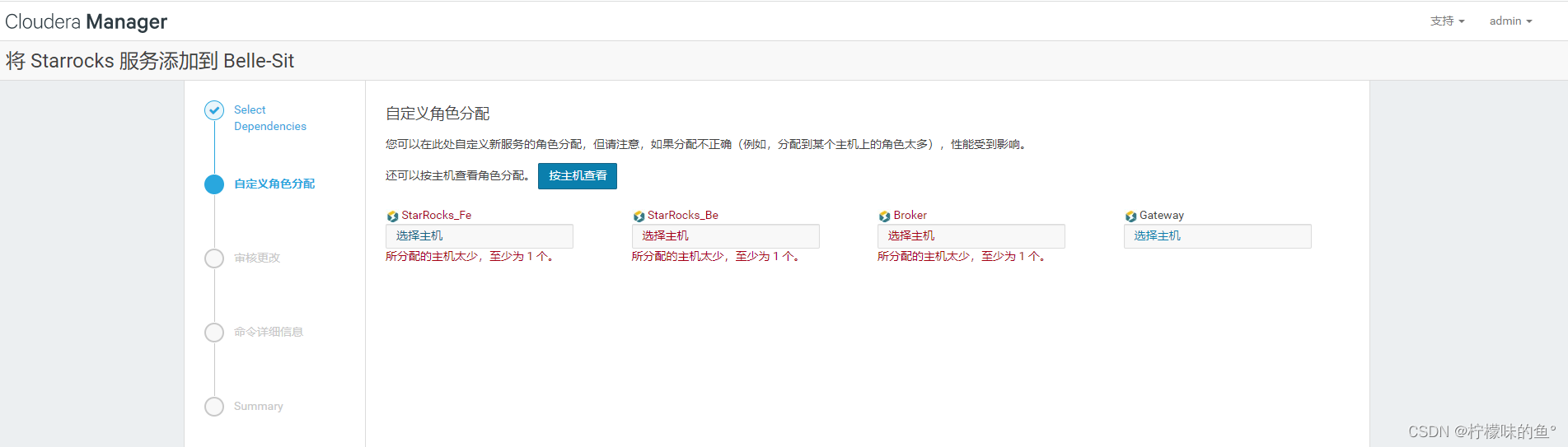
5、再后面就是现在安装的目录、一些相关配置的选择,这里我已经添加了,就不截图了,最后执行成功
后在首页可以看到新添加的服务。
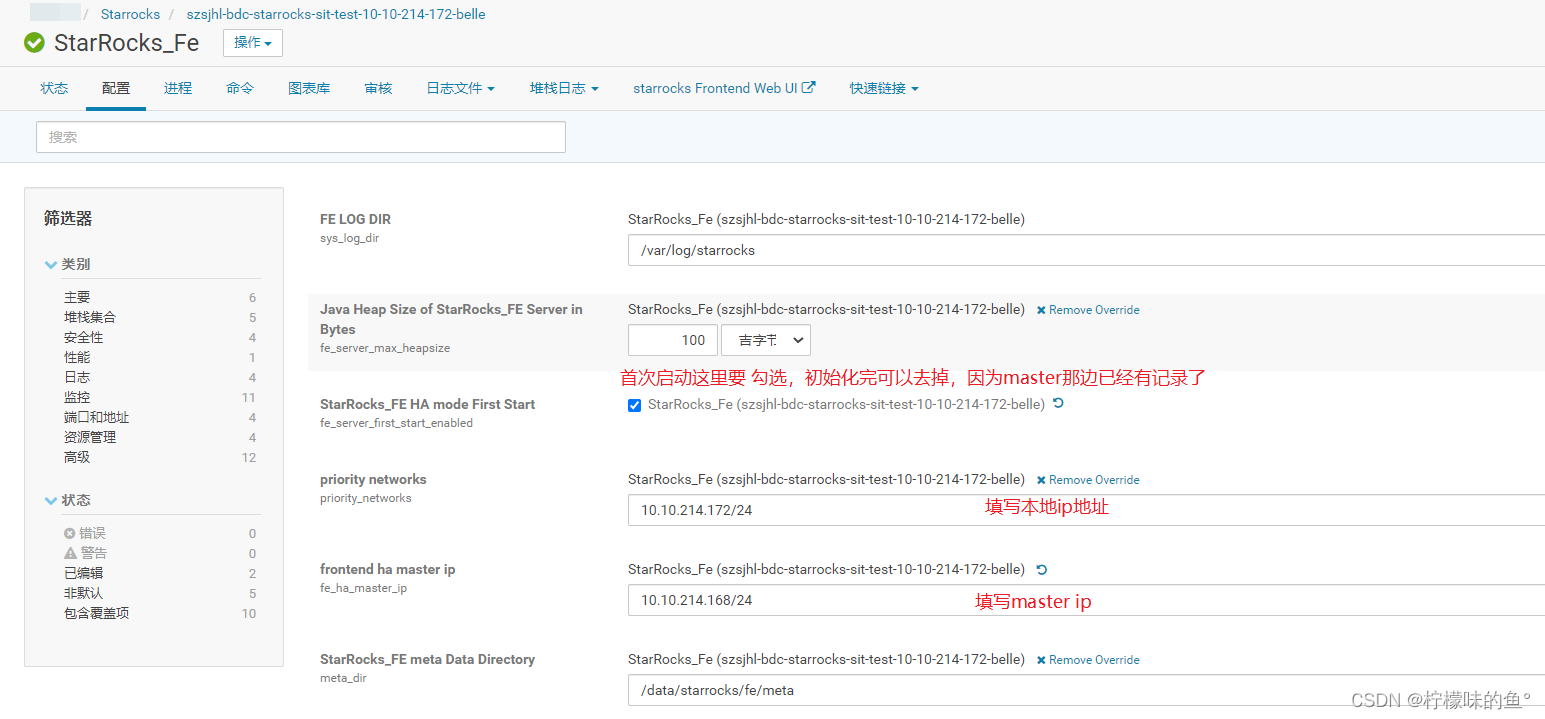
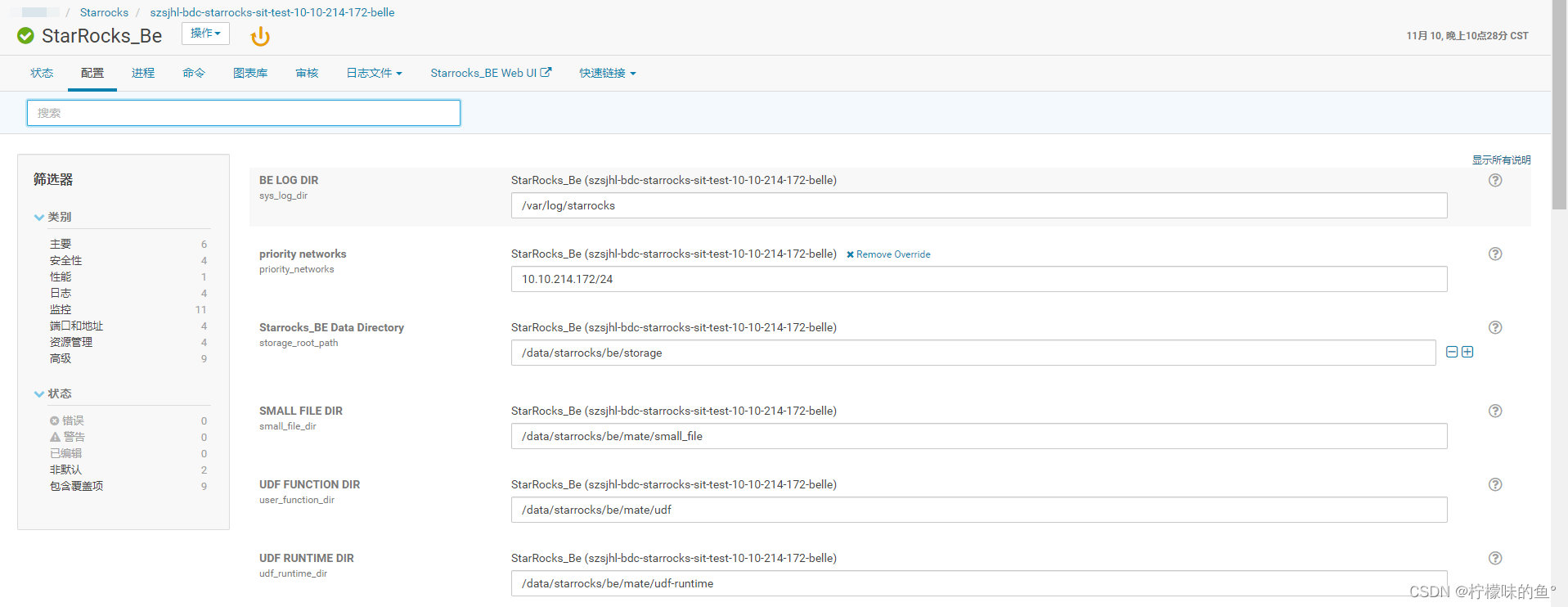
sys_log_dir: fe日志配置位置,需要和cm中日志路径配置一致既可以在页面查看相关日志
fe_server_max_heapsize:用设置fe内存大小的参数,将此值代入脚本启动jvm的
fe_server_first_start_enabled:开启分的HA模式时, 此节点是否第一次启动,开启参数会执行 --helper host:port --daemon
fe_ha_master_ip:fe启动HA模式时此值为master节点ip,用于fe第一次启动
meta_dir:fe元数据的位置
priority_networks: 以CIDR 形式10.10.10.0/24 指定FE节点的IP 地址
-- 添加 follower
ALTER SYSTEM ADD FOLLOWER "xxxx:9010";
-- 或者添加 observer
ALTER SYSTEM ADD OBSERVER "xxxx:9010";
fe 一些重要端口设置,再此页面修改即可,9010为cm端口,注意修改
fe 高级配置代码段:在此配置添加需要变更的参数会同步至fe,不用登录机器修改,cm管理好处,重启即可生效
-- 添加 be
ALTER SYSTEM ADD BACKEND "xxxx:9050";
sys_log_dir:和上述fe log配置一致,主要修改log输出配置,fe日志格式问题,暂无法在页面查看相关日志,如遇到启动报错问题,请直接登录机器查看be日志。
storage_root_path:数据存储目录,支持配置多个
priority_networks: 以CIDR 形式10.10.10.0/24 指定BE节点的IP 地址
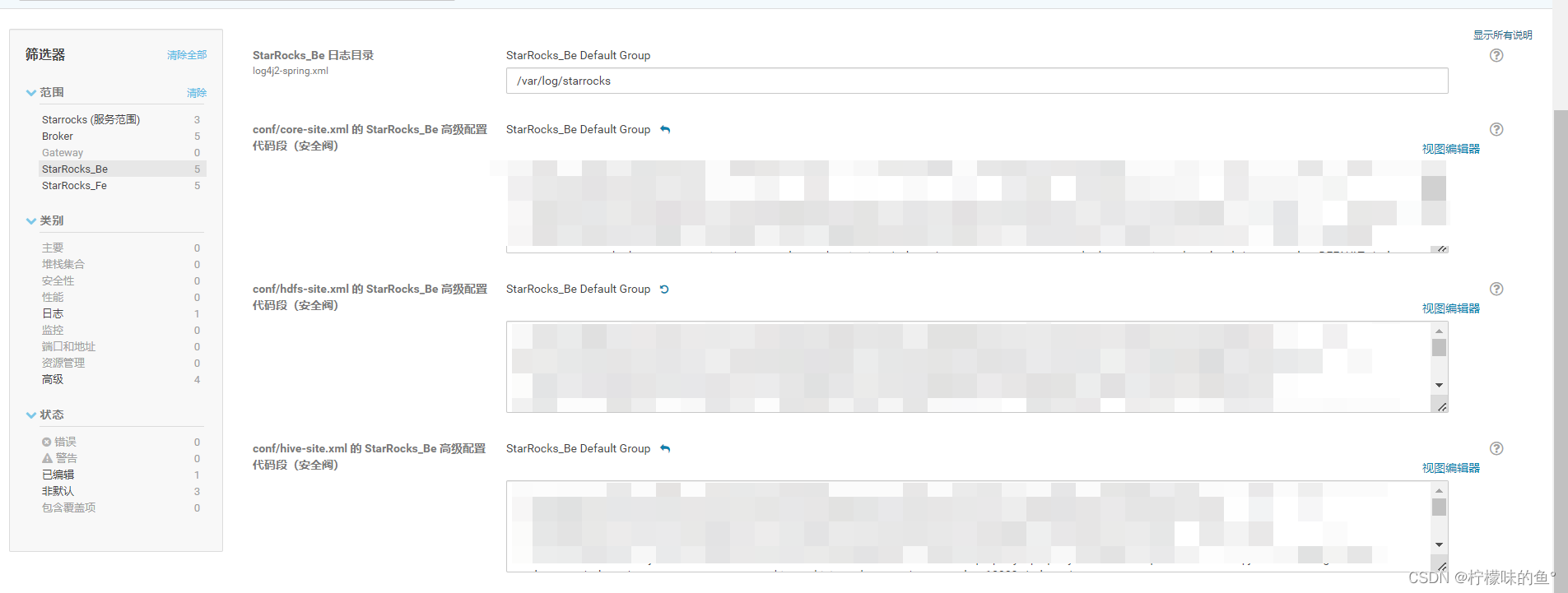
-- 添加 Broker
ALTER SYSTEM ADD BROKER broker "xxxx:8000";
broker_server_max_heapsize :jvm最大值配置
sys_log_dir:日志存储位置,也需要和cm中日志配置位置相同
conf/core-site.xml/hdfs-site.xml/hive-site.xml: 填写相关参数也会代入到broker的启动目录/conf 下面,在使用broker拉取也不会有问题

-- 创建 RESOURCE
CREATE EXTERNAL RESOURCE "hive0"
PROPERTIES (
"type" = "hive",
"hive.metastore.uris" = "thrift://10.10.223.14:9083,thrift://10.10.223.15:9083"
);
-- 查看 StarRocks 中创建的资源
SHOW RESOURCES;
-- 建表
CREATE EXTERNAL TABLE example_db.customer (
`c_custkey` int(11) NULL COMMENT "",
`c_name` varchar(200) NULL COMMENT "",
`c_address` varchar(200) NULL COMMENT "",
`c_city` varchar(200) NULL COMMENT "",
`c_nation` varchar(200) NULL COMMENT "",
`c_region` varchar(200) NULL COMMENT "",
`c_phone` varchar(200) NULL COMMENT "",
`c_mktsegment` varchar(200) NULL COMMENT ""
) ENGINE=HIVE
PROPERTIES (
"resource" = "hive0",
"database" = "ssb",
"table" = "customer"
);

-- 创建 hive_catalog
CREATE EXTERNAL CATALOG hive_catalog0
PROPERTIES (
"type" = "hive",
"hive.metastore.uris" = "thrift://10.10.223.15:9083,thrift://10.10.223.14:9083"
);
-- 查询数据(不用创建表,可以直接查hive表)
select * from hive_catalog_sit.ssb.customer limit 1 ;
-- 查看当前集群中的所有 catalog
show catalogs;

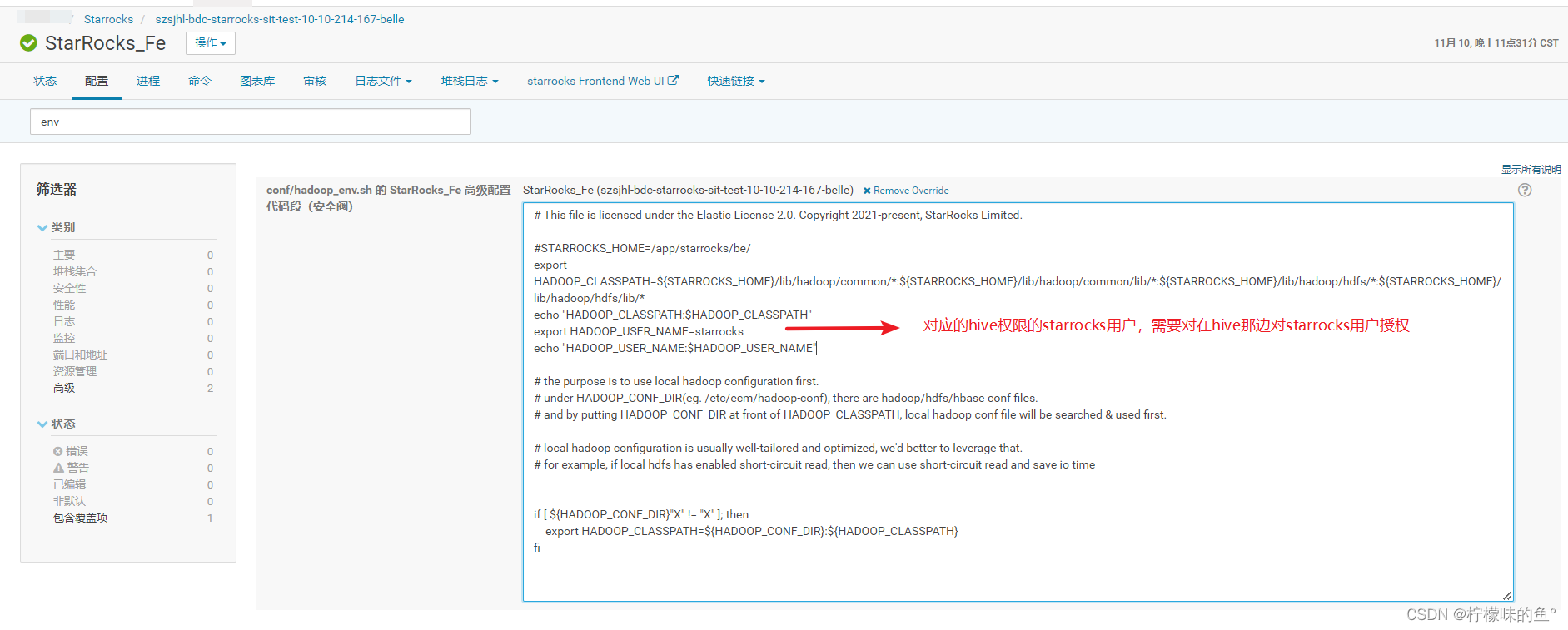
FE 设置 hadoop_env.sh,没有env用户,可能导致FE启动失败。
最后:有任何问题欢迎大家下面评论,多多支持,创作不宜,点赞支持一下,感谢!
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
我一直很高兴地使用DelayedJob习惯用法:foo.send_later(:bar)这会调用DelayedJob进程中对象foo的方法bar。我一直在使用DaemonSpawn在我的服务器上启动DelayedJob进程。但是...如果foo抛出异常,Hoptoad不会捕获它。这是任何这些包中的错误...还是我需要更改某些配置...或者我是否需要在DS或DJ中插入一些异常处理来调用Hoptoad通知程序?回应下面的第一条评论。classDelayedJobWorker 最佳答案 尝试monkeypatchingDelayed::W
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
三分钟集成Tap防沉迷SDK(Unity版)一、SDK介绍基于国家对上线所有游戏必须增加防沉迷功能的政策下,TapTap推出防沉迷SDK,供游戏开发者进行接入;允许未成年用户在周五、六、日以及法定节假日晚上8:00-9:00进行游戏,防沉谜时间段进入游戏会弹窗进行提示!开发环境要求:Unity2019.4或更高版本iOS10或更高版本Android5.0(APIlevel21)或更高版本🔗Unity集成Demo参考链接🔗UnityTapSDK功能体验APK下载链接二、集成前准备1.创建应用进入开发者后台,按照提示开始创建应用;2.开通服务在使用TDS实名认证和防沉迷服务之前,需要在上面创建的应
我被这个难住了。到目前为止教程中的一切都进行得很顺利,但是当我将这段代码添加到我的/spec/requests/users_spec.rb文件中时,事情开始变得糟糕:describe"success"doit"shouldmakeanewuser"dolambdadovisitsignup_pathfill_in"Name",:with=>"ExampleUser"fill_in"Email",:with=>"ryan@example.com"fill_in"Password",:with=>"foobar"fill_in"Confirmation",:with=>"foobar"cl
我需要一些指导来了解如何将Angular整合到rails中。选择Rails的原因:我喜欢他们偏执的做事方式。还有迁移,gem真的很酷。使用angular的原因:我正在研究和寻找最适合SPA的框架。Backbone似乎太抽象了。我不得不在Angular和Ember之间做出选择。我首先开始阅读Angular,它对我来说很有意义。所以我从来没有去读过关于ember的文章。使用Angular和Rails的原因:我研究并尝试使用小型框架,例如grape、slim(是的,我也使用php)。但我觉得需要坚持项目的长期范围。我个人喜欢用Rails的方式做事。这就是我需要帮助的地方,我在Rails4中有
有没有人有在Maven中运行用Ruby编写的单元测试的经验。任何输入,如要使用的库/maven插件,将不胜感激!我们已经在使用Maven+hudson+Junit。但是我们正在引入Ruby单元测试,找不到任何同样好的组合。 最佳答案 我建议让Maven使用ExecMavenPlugin启动rake测试(exec:exec目标)并使用ci_reportergem生成单元测试结果的XML文件,Hudson、Bamboo等可以读取该文件,以与JUnit测试相同的格式显示测试结果。如果您不需要使用mvntest运行Ruby测试,您也可以只使
目前我有一小套针对我的网络服务器运行的集成测试,它发出请求并断言一些关于响应应该是什么的假设。这些是用Ruby编写的,生成http请求。我一直在看Gatling作为压力测试工具,但我想知道它是否也可以用于集成测试。这样,所有端点请求都可以在压力测试和集成测试中重复使用。我可能在这里失去了一些东西,因为没有RSpec的BDD,但不必两次创建相同的测试。有没有人有这样使用gatling的经验? 最佳答案 您可以使用AssertionAPI并设置验收标准。但是,Gatling不是浏览器,不会运行/测试您的Javascript,因此这种方法
文章目录前言一、Elasticsearch版本介绍二、客户端种类三、客户端与版本兼容性四、引入Elasticsearch依赖包五、客户端配置六、Elasticsearch使用前言ElasticSearch是Elastic公司出品的一款功能强大的搜索引擎,被广泛的应用于各大IT公司,它的代码位于https://github.com/elastic/elasticsearch,目前是一个开源项目。ElasticSearch公司的另外两个开源产品Logstash、Kibana与ElasticSearch构成了著名的ELK技术栈。。他们三个共同形成了一个强大的生态圈。简单地说,Logstash负责数据
集成背景我们当前集群使用的是ClouderaCDP,Flink版本为ClouderaVersion1.14,整体Flink安装目录以及配置文件结构与社区版本有较大出入。直接根据Streampark官方文档进行部署,将无法配置FlinkHome,以及后续整体Flink任务提交到集群中,因此需要进行针对化适配集成,在满足使用需求上,尽量提供完整的Streampark使用体验。集成步骤版本匹配问题解决首先解决无法识别Cloudera中的FlinkHome问题,根据报错主要明确到的事情是无法读取到Flink版本、lib下面的jar包名称无法匹配。修改对象:修改源码:(解决无法匹配clouderajar