 如果你的 Linux 发行版支持 systemd,那么从启动时开始,它每秒钟都会从系统的所有进程和应用程序中收集日志。所有这些日志事件都由 systemd 的
如果你的 Linux 发行版支持 systemd,那么从启动时开始,它每秒钟都会从系统的所有进程和应用程序中收集日志。所有这些日志事件都由 systemd 的 journald 守护程序管理。journald 收集所有的日志(信息、警告、错误等),并将其作为二进制数据存储在磁盘文件中。由于日志保留在磁盘中,而且每秒钟都在收集,所以它占用了巨大的磁盘空间;特别是对于旧的系统、服务器来说。例如,在我的一个运行了一年左右的测试系统中,日志文件的大小是 GB 级的。如果你管理多个系统、服务器,建议一定要正确管理 journald 日志,以便高效运行。让我们来看看如何管理日志文件。journalctl 工具,你可以查询这些日志,对其进行各种操作。例如,查看不同启动时的日志文件,检查特定进程或应用程序的最后警告和错误。如果你对这些不了解,我建议你在学习本指南之前先快速浏览一下此教程:使用 journalctl 查看和分析 systemd 日志(附实例) 》。/var/log/journal,文件夹为机器 ID。比如说: 日志文件位置的截图-1
日志文件位置的截图-1 日志文件位置的截图-2另外,请记住,根据系统配置,运行时日志文件被存储在
日志文件位置的截图-2另外,请记住,根据系统配置,运行时日志文件被存储在 /run/log/journal/。而这些在每次启动时都会被删除。journalctl 工具清除日志文件以释放磁盘空间。journalctl --disk-usage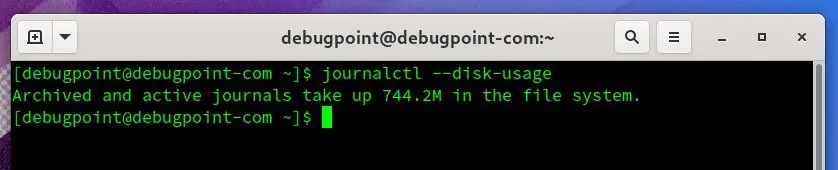 journalctl 磁盘使用命令如果你有一个图形化的桌面环境,你可以打开文件管理器,浏览路径
journalctl 磁盘使用命令如果你有一个图形化的桌面环境,你可以打开文件管理器,浏览路径 /var/log/journal,并检查属性。journald.conf 配置文件来完成。正常情况下,即使 journalctl 提供了删除日志文件的工具,你也不应该手动删除这些文件。让我们来看看如何 手动 删除它,然后我将解释 journald.conf 中的配置变化,这样你就不需要时不时地手动删除文件;相反,systemd 会根据你的配置自动处理它。flush 和 rotate 日志文件。轮换rotate是将当前活动的日志文件归档,并立即开始创建一个新的日志文件继续记录日志。冲洗flush 开关要求日志守护进程将存储在 /run/log/journal/ 中的所有日志数据冲入 /var/log/journal/,如果持久性存储被启用的话。然后,在 flush 和 rotate 之后,你需要用 vacuum-size、vacuum-time 和 vacuum-files 选项运行 journalctl 来强制 systemd 清除日志。例 1:sudo journalctl --flush --rotatesudo journalctl --vacuum-time=1s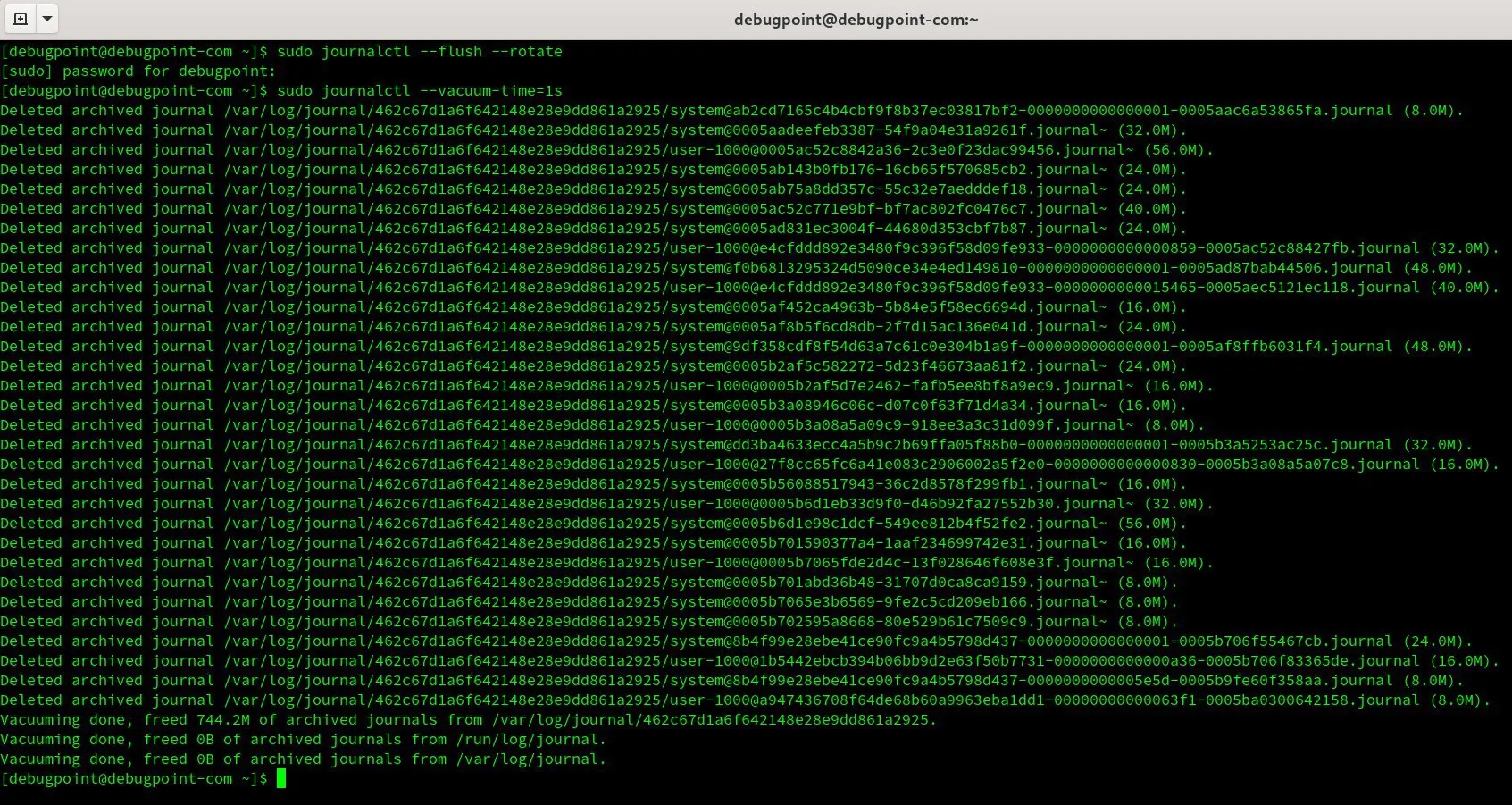 日志清理-例子清理完毕后:
日志清理-例子清理完毕后: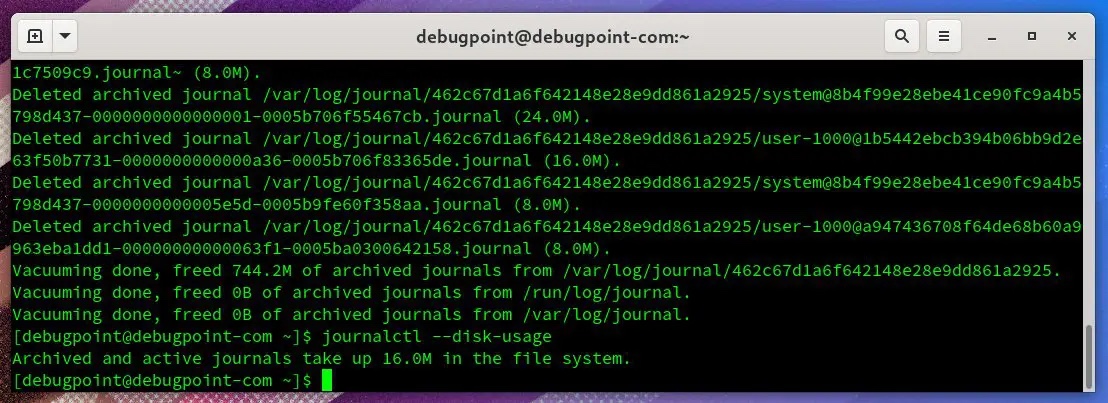 清理后--日志的占用空间你也可以根据你的需要在
清理后--日志的占用空间你也可以根据你的需要在 --vacuum-time 的数字后面提供以下后缀:s:秒m:分钟h:小时days:天months:月weeks:周years:年sudo journalctl --flush --rotatesudo journalctl --vacuum-size=400MK:KBM:MBG:GBsudo journalctl --flush --rotatesudo journalctl --vacuum-files=2vacuum-files 选项会清除所有低于指定数量的日志文件。因此,在上面的例子中,只有最后两个日志文件被保留,其他的都被删除。同样,这只对存档的文件有效。如果你愿意,你可以把两种选项结合起来,但我建议不要这样做。然而,如果同时使用两个选项,请确保先用 --rotate 选项运行。/etc/systemd/journald.conf。systemd 为你提供了许多参数来有效管理日志文件。通过组合这些参数,你可以有效地限制日志文件所占用的磁盘空间。让我们来看看。| journald.conf 参数 | 描述 | 实例 |
SystemMaxUse | 指定日志在持久性存储中可使用的最大磁盘空间 | SystemMaxUse=500M |
SystemKeepFree | 指定在将日志条目添加到持久性存储时,日志应留出的空间量。 | SystemKeepFree=100M |
SystemMaxFileSize | 控制单个日志文件在被轮换之前在持久性存储中可以增长到多大。 | SystemMaxFileSize=100M |
RuntimeMaxUse | 指定在易失性存储中可以使用的最大磁盘空间(在 /run 文件系统内)。 | RuntimeMaxUse=100M |
RuntimeKeepFree | 指定将数据写入易失性存储(在 /run 文件系统内)时为其他用途预留的空间数量。 | RuntimeMaxUse=100M |
RuntimeMaxFileSize | 指定单个日志文件在被轮换之前在易失性存储(在 /run 文件系统内)所能占用的空间量。 | RuntimeMaxFileSize=200M |
/etc/systemd/journald.conf 文件中添加这些值,那么在更新文件后,你必须重新启动 journald。要重新启动,请使用以下命令。sudo systemctl restart systemd-journaldPASS)、失败(FAIL)。journalctl --verify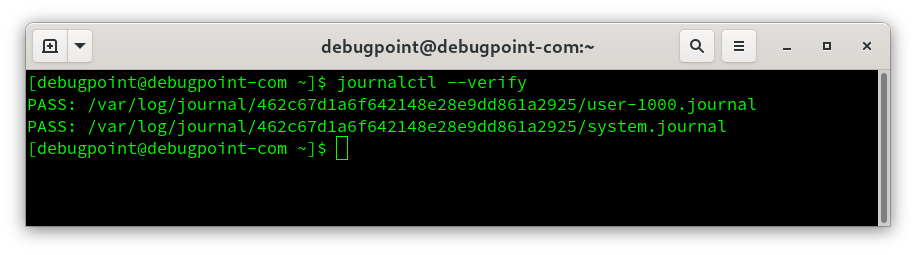 验证日志文件
验证日志文件我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我正在查看instance_variable_set的文档并看到给出的示例代码是这样做的:obj.instance_variable_set(:@instnc_var,"valuefortheinstancevariable")然后允许您在类的任何实例方法中以@instnc_var的形式访问该变量。我想知道为什么在@instnc_var之前需要一个冒号:。冒号有什么作用? 最佳答案 我的第一直觉是告诉你不要使用instance_variable_set除非你真的知道你用它做什么。它本质上是一种元编程工具或绕过实例变量可见性的黑客攻击
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我正在处理旧代码的一部分。beforedoallow_any_instance_of(SportRateManager).toreceive(:create).and_return(true)endRubocop错误如下:Avoidstubbingusing'allow_any_instance_of'我读到了RuboCop::RSpec:AnyInstance我试着像下面那样改变它。由此beforedoallow_any_instance_of(SportRateManager).toreceive(:create).and_return(true)end对此:let(:sport_
我收到格式为的回复#我需要将其转换为哈希值(针对活跃商家)。目前我正在遍历变量并执行此操作:response.instance_variables.eachdo|r|my_hash.merge!(r.to_s.delete("@").intern=>response.instance_eval(r.to_s.delete("@")))end这有效,它将生成{:first="charlie",:last=>"kelly"},但它似乎有点hacky和不稳定。有更好的方法吗?编辑:我刚刚意识到我可以使用instance_variable_get作为该等式的第二部分,但这仍然是主要问题。
我正在写一篇关于在Ruby中几乎一切都是对象的博客文章,我试图通过以下示例来展示这一点:classCoolBeansattr_accessor:beansdefinitialize@bean=[]enddefcount_beans@beans.countendend所以从类中我们可以看出它有4个方法(当然,除非我错了):它可以在创建新实例时初始化一个默认的空bean数组它可以计算它有多少个bean它可以读取它有多少个bean(通过attr_accessor)它可以向空数组写入(或添加)更多bean(也通过attr_accessor)但是,当我询问类本身它有哪些实例方法时,我没有看到默认
如果我有以下一段Ruby代码:classBlahdefself.bleh@blih="Hello"@@bloh="World"endend@blih和@@bloh到底是什么?@blih是Blah类中的一个实例变量,@@bloh是Blah类中的一个类变量,对吗?这是否意味着@@bloh是Blah的类Class中的一个变量? 最佳答案 人们似乎忽略了该方法是类方法。@blih将是常量Bleh的类Class实例的实例变量。因此:irb(main):001:0>classBlehirb(main):002:1>defself.blehirb
我理解(我认为)Ruby中类变量和类的实例变量之间的区别。我想知道如何从该类外部访问该类的实例变量。从内部(即在类方法中而不是实例方法中),它可以直接访问,但是从外部,有没有办法做MyClass.class.[@$#]variablename?我没有任何具体原因要这样做,只是学习Ruby并想知道是否可行。 最佳答案 classMyClass@my_class_instance_var="foo"class上述yield:>>foo我相信Arkku演示了如何从类外部访问类变量(@@),而不是类实例变量(@)。我从这篇文章中提取了上述内
print"Enteryourpassword:"pass=STDIN.noecho(&:gets)puts"Yourpasswordis#{pass}!"输出:Enteryourpassword:input.rb:2:in`':undefinedmethod`noecho'for#>(NoMethodError) 最佳答案 一开始require'io/console'后来的Ruby1.9.3 关于ruby-为什么不能使用类IO的实例方法noecho?,我们在StackOverflow上