本篇介绍使用HTTP协议实现文件下载和上传。在客户端和服务器的通信过程中,可能有些多媒体或数据文件需要下载或上传,可以通过HTTP协议实现。
首先看使用HTTP协议下载文件的原理:客户端发送一个HTTP GET请求,并且在消息中用URL指出要下载的文件。

Web服务器都实现了对文件下载请求的响应,响应的消息头中包含文件的基本信息,消息体中包含文件的具体内容,文件内容是二进制格式的。

客户端用HTTP GET实现文件下载的流程和用HTTP GET从服务器获取数据的流程是一致的,区别在于对返回的响应消息的处理。在用HTTP GET从服务器上获取数据时,对于返回的消息体中的内容是直接当作数据来处理的。用HTTP GET下载文件时,对于返回的消息体中的内容要当作文件内容来保存。具体来说,就是获取消息体输入流、读取数据保存到文件、关闭流。

对应的代码是这样的,获取输入流对应的是connection.getInputStream方法,从流中读取数据用的是输入流的read方法,写到文件用的是输出流的write方法,最后用close关闭流。代码的整体框架和用HTTP GET从服务器上获取数据是一样的。
String download(String urlStr, File f) {
String result = null;
HttpURLConnection connection = null;
try{
URL url = new URL(urlStr);
connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(8000);
connection.setReadTimeout(5000);
int statusCode = connection.getResponseCode();
if(statusCode==200) {
InputStream in = connection.getInputStream();
if(f.exists()) f.delete();
f.createNewFile();
FileOutputStream out = new FileOutputStream(f);
byte[] buf = new byte[1024];
int j = 0;
while( (j=in.read(buf))!=-1) out.write(buf, 0, j);
out.flush();
out.close();
in.close();
result = "Download OK.\nFrom: " + urlStr + "\nTo: " + f.getPath();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if(connection!=null) connection.disconnect();
}
return result;
}
文件下载也需要用AsyncTask异步执行。
在前一篇BBS的例子中,我们继续添加文件下载和上传功能。关于文件下载是这样设计的,当点击Download按钮时,就会用AsyncTask异步下载上面URL中的文件。该文件保存到外部存储根目录下,因为需要向外部存储写文件,所以需要android.permission.WRITE_EXTERNAL_STORAGE权限。Android6.0以后采用了动态权限管理,这个权限是危险权限,所以最好在执行之前先检查用户是否允许了,如果没有允许则询问,具体代码如下:
if(checkSelfPermission(Manifest.permission.WRITE_EXTERNAL_STORAGE)!= PackageManager.PERMISSION_GRANTED){
requestPermissions(new String[]{Manifest.permission.WRITE_EXTERNAL_STORAGE}, 1);
return;
}此外,Android 10(API29)引入了分区存储(scoped storage)的功能,不允许应用直接读写外部存储根目录下的文件。要想让本例子在Android11上运行,可以将文件存放到应用在外部存储上的私有目录下,该目录可以用方法getExternalFilesDir(null)来获得,其实际位置为:Android/data/<package-name>/files/。
检查完权限后,就可以执行异步下载,具体代码是这样的:

异步执行的代码中先准备好本地文件,然后下载文件。这个文件必须事先放在服务器的WebContent目录下,或相应子目录中。下载完成后,会在下面的文本框中显示下载文件的信息,内容是是否下载成功,从哪个链接下载到本地哪个文件。
如果文件下载需要的时间比较长,就需要显示下载进度。下面,我们用一个ProgressDialog进度对话框来显示文件下载进度,界面就像下面这样。

下载进度等于已下载字节数 / 文件总长度,文件总长度从消息头中得到,用connection对象的getContentLength方法获得,已下载字节数在读取文件内容的循环中统计。具体代码是在基本的文件下载流程的基础上,添加统计进度的代码,也就是红色代码部分。每读取一次数据,就更新下下载进度。
下载进度要显示在进度对话框中,但文件下载代码是在后台线程中执行的,不能直接操作进度对话框。所以更新进度时要调用AsyncTask的publishProgress方法,把进度传递到在主线程执行的onProgressUpdate方法,在这个方法中更新进度对话框。
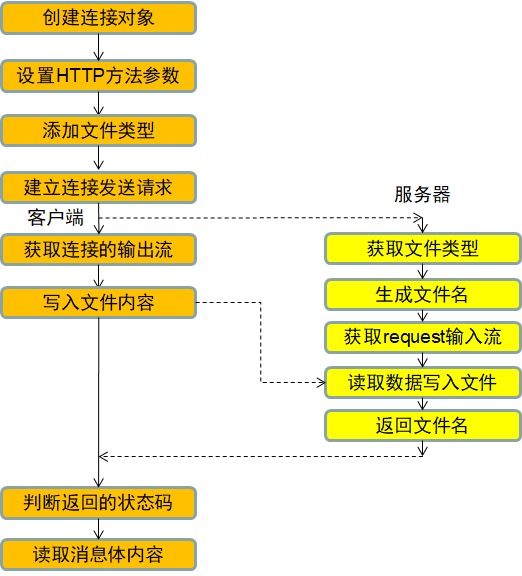
接下来看文件上传的原理。客户端发送HTTP POST请求,用URL指出服务器端接收上传文件的程序,比如JavaEE中的Servlet。另外消息头中一般要包含文件类型,以便服务器端生成文件后缀。文件的内容以二进制格式放在消息体中。

Web服务器一般不会自带接收上传文件的功能,需要开发者自己编写。接收文件时,服务器端一般是按照文件上传时间生成一个文件名,不用客户端文件名是为了防止不同客户端上传同名文件互相覆盖。然后把POST消息体中的文件内容保存到该文件中。再在响应消息中把文件名或链接返回给客户端,客户端可以在其它Post中使用该文件名或链接作为参数。

客户端用HTTP上传文件的流程和用HTTP上传数据的流程是一致的,区别是在消息头中添加文件类型描述,在消息体中写入的是文件内容。服务器端流程是获取文件类型、生成文件名、获取请求的输入流,读取数据写入文件,返回文件名。
客户端上传文件的代码是这样的:
String upload(String urlStr, File f) {
String result = null;
HttpURLConnection connection = null;
try{
URL url = new URL(etUrl.getText().toString());
connection = (HttpURLConnection) url.openConnection();
connection.setDoInput(true);
connection.setDoOutput(true);
connection.setUseCaches(false);
connection.setRequestMethod("POST");
connection.setRequestProperty("Charset", "UTF-8");
connection.setRequestProperty("Connection", "Keep-Alive");
connection.setRequestProperty("Content-Type", "binary/" + FileUtils.getExtName(f));
OutputStream os = connection.getOutputStream();
FileInputStream fis = new FileInputStream(f);
byte[] buf = new byte[1024];
int j = 0;
while( (j=fis.read(buf))!=-1) {
os.write(buf, 0, j);
}
fis.close();
os.flush();
os.close();
int statusCode = connection.getResponseCode();
if(statusCode==200) {
InputStream in = connection.getInputStream();
result = readInputStream(in);
in.close();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if(connection!=null) connection.disconnect();
}
return result;
}添加文件类型用的是setRequestProperty方法,在消息头中添加一行Content-Type属性,值是binary/文件扩展名。然后用getOutputStream打开HttpURLConnection连接的输出流,把文件内容用write方法一块一块写进去。
服务器端是用一个Servlet实现的,具体代码在Servlet的doPost方法中。
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String contentType = request.getContentType();
int separate = contentType.lastIndexOf("/");
String fileType = contentType.substring(separate+1);
String uploadPath = "/upload";
String filePath = this.getServletContext().getRealPath(uploadPath);
String fileName = Long.toString(System.currentTimeMillis()) + "." + fileType;
// 必须创建upload文件夹
File f = new File(filePath + "/" + fileName);
if(!f.getParentFile().exists()) f.getParentFile().mkdir();
System.out.println("File upload: " + f.getPath());
InputStream in = request.getInputStream();
FileOutputStream fos = new FileOutputStream(f);
byte[] buffer = new byte[1024];
int j = 0;
while( (j=in.read(buffer))!=-1 ) fos.write(buffer, 0, j);
fos.flush();
fos.close();
in.close();
response.setCharacterEncoding("utf-8");
response.getWriter().print(fileName);
}
先获取文件扩展名,再用系统当前时间生成文件名,在加上路径,从而生成上传文件的名称和位置。然后从request获得输入流,从输入流读取数据保存到该文件。最后,返回该文件名。
文件上传也需要用AsyncTask异步执行。在这个例子中,关于文件上传是这样设计的,当点击Upload按钮时,就会用AsyncTask异步上传一个本地文件到URL指定的程序,具体代码是这样的。

异步执行的代码中先准备好本地文件,这个文件就是前面下载到本地的某个文件,然后上传文件。上传完成后,会在下面的文本框中显示上传文件的信息,内容是该文件上传到服务器上后的新文件名。
如果文件上传需要的时间比较长,就需要显示上传进度。下面,我们用一个ProgressDialog进度对话框来显示文件上传进度,界面就像下面这样。
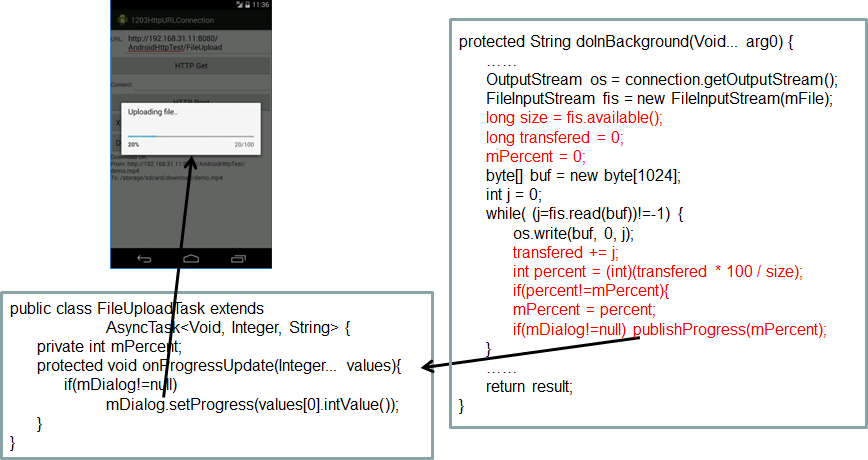
上传进度等于已上传字节数 / 文件总长度,文件总长度从文件输入流得到,已上传字节数在上传文件内容的循环中统计。具体代码是在基本的文件上传流程的基础上,添加统计进度的代码,也就是红色代码部分。每上传一块数据,就更新一下上传进度。上传进度要显示在进度对话框中,也是通过AsyncTask的publishProgress方法,把进度传递到在主线程执行的onProgressUpdate方法,在这个方法中更新进度对话框。
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您