文章目录
看到网上各式各样关于Elasticsearch面试题的文章,但是貌似都不是很全面,所以特意整理了一篇关于常见的ES面试题,已收录至面试专栏,计划更新 10/50 个常见面试题,此次先发出来 10个,后续更新,请关注我的博客,第一时间查看更新。
另外,本文目前对面试问题的描述存在以下几个问题,将在后续更新中不断改善,是的这篇文章还会改进!
Elasticsearch是什么
Elasticsearch是由 Java语言开发基于Lucene的一款开源的搜索、聚合分析和存储引擎。同时它也可以称作是一种非关系型文档数据库。
天生分布式、高性能、高可用、易扩展、易维护。
跨语言、跨平台:几乎支持所有主流编程语言,并且支持在“Linux、Windows、MacOS”多平台部署
支持结构化、非结构化、地理位置搜索等
海量数据的全文检索,搜索引擎、垂直搜索、站内搜索:
数据分析和聚合查询
日志系统:ELK
mapping是什么,你知道ES的哪些数据类型
ES中的mapping有点类似与RDB中“表结构”的概念,在MySQL中,表结构里包含了字段名称,字段的类型还有索引信息等。在Mapping里也包含了一些属性,比如字段名称、类型、字段使用的分词器、是否评分、是否创建索引等属性,并且在ES中一个字段可以有对个类型。分词器、评分等概念在后面的课程讲解。
date和date_nanos.除了上述字段类型之外,其他类型都必须显示映射,也就是必须手工指定,因为其他类型ES无法自动识别。
PUT /product
{
"mappings": {
"properties": {
"field": {
"mapping_parameter": "parameter_value"
}
}
}
}
PUT my_index
{
"mappings": {
"enabled": false
}
}
"date": {
"type": "date",
"format": "yyyy-MM-dd"
}
什么是全文检索
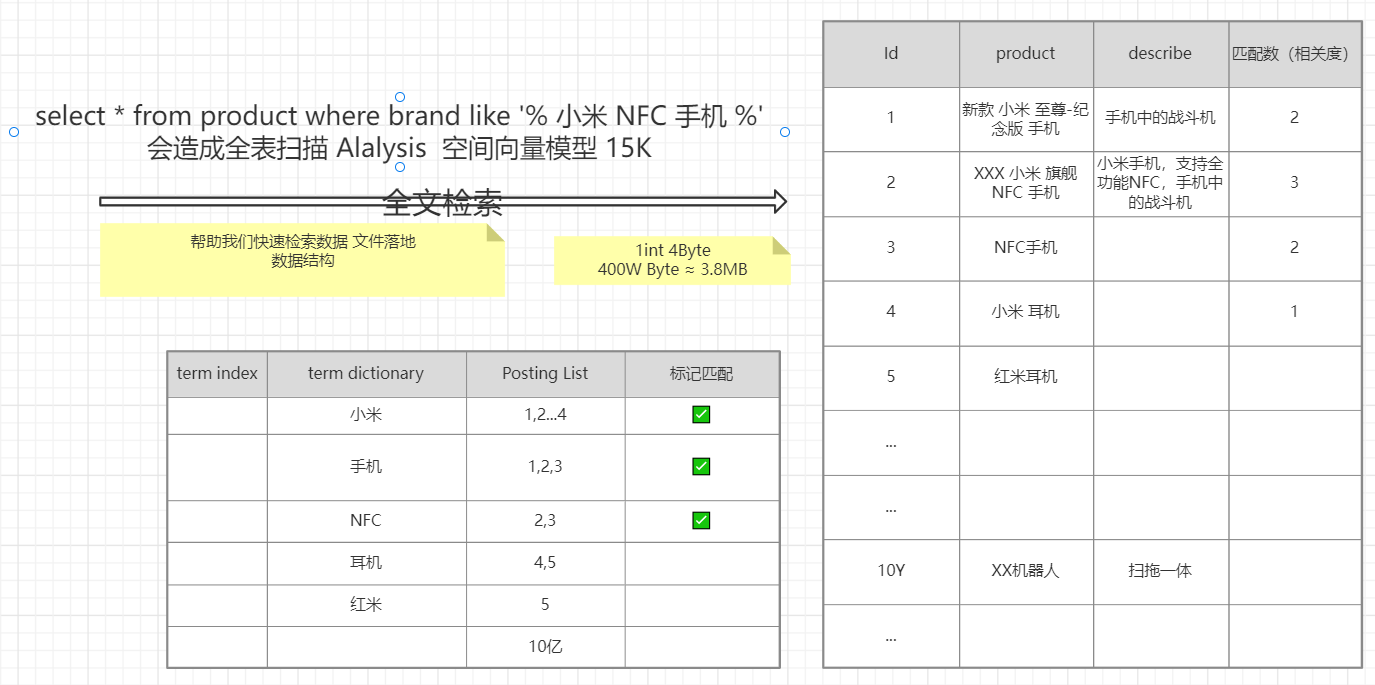
GET index/_search
{
"query": {
***
}
}
ES支持哪些类型的查询
此题目答案不唯一,按照不同的分类方式,答案也不一样
Query DSL:Domain Specific Language
Script:脚本查询
Aggregations:聚合查询
SQL查询
EQL查询
查询所有:
GET /product/_search
带参数:
GET /product/_search?q=name:xiaomi
分页:
GET /product/_search?from=0&size=2&sort=price:asc
精准匹配 exact value
GET /product/_search?q=date:2021-06-01
_all搜索 相当于在所有有索引的字段中检索
GET /product/_search?q=2021-06-01
验证_all搜索
PUT product
{
"mappings": {
"properties": {
"desc": {
"type": "text",
"index": false
}
}
}
}
# 先初始化数据
POST /product/_update/5
{
"doc": {
"desc": "erji zhong de kendeji 2021-06-01"
}
}
```
GET index/_search
{
"query": {
***
}
}
```
GET _search
{
"query": {
"constant_score": {
"filter": {
"term": {
"status": "active"
}
}
}
}
}
filter:query和filter的主要区别在: filter是结果导向的而query是过程导向。query倾向于“当前文档和查询的语句的相关度”而filter倾向于“当前文档和查询的条件是不是相符”。即在查询过程中,query是要对查询的每个结果计算相关性得分的,而filter不会。另外filter有相应的缓存机制,可以提高查询效率。
bool:可以组合多个查询条件,bool查询也是采用more_matches_is_better的机制,因此满足must和should子句的文档将会合并起来计算分值
minimum_should_match:参数指定should返回的文档必须匹配的子句的数量或百分比。如果bool查询包含至少一个should子句,而没有must或 filter子句,则默认值为1。否则,默认值为0
Object
Nested
Join
全文检索:match
精确查找:term
模糊查询:suggester、模糊查询、通配符、正则查找
term和match的区别
term:对搜索词不分词,不影响源数据
match:对搜索词分词,不影响源数据
term:检索类型
keyword:字段类型
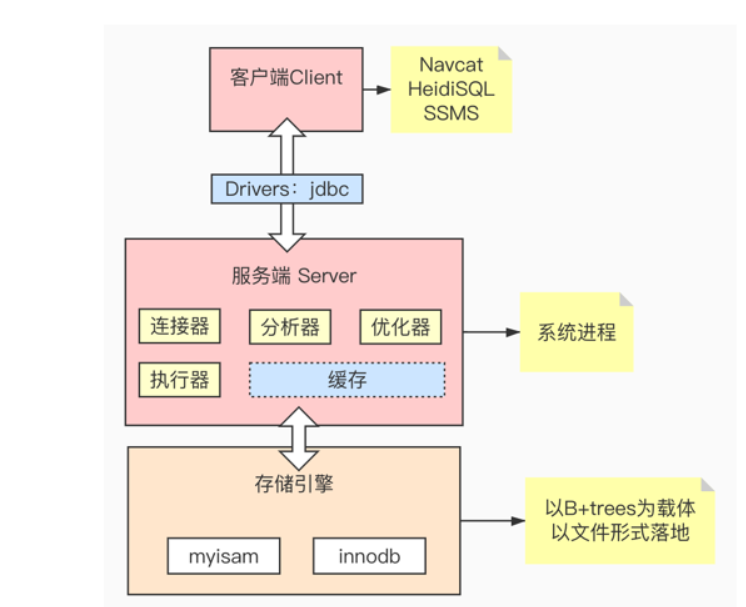
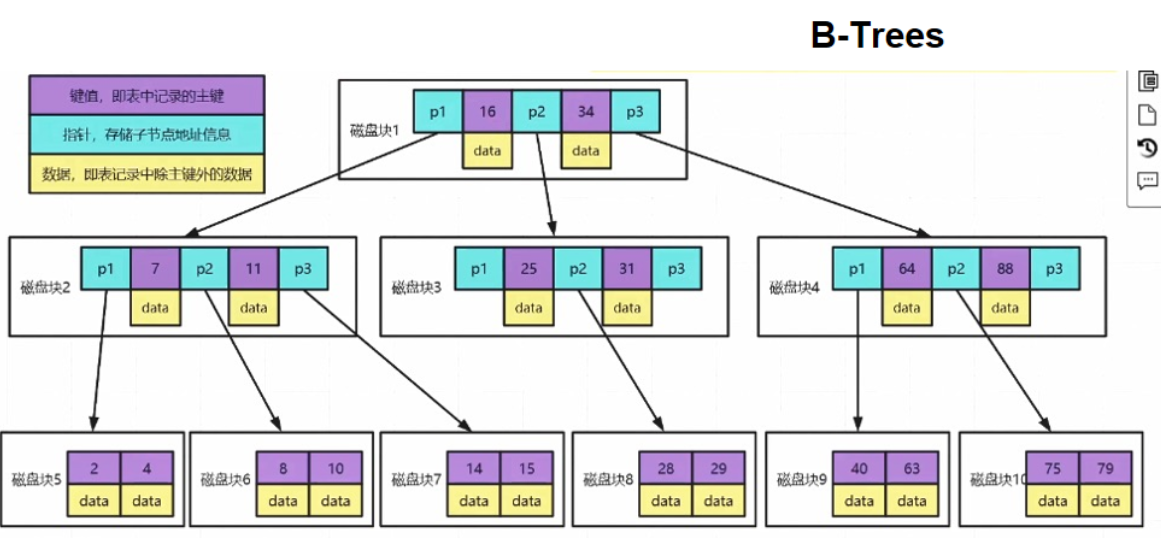
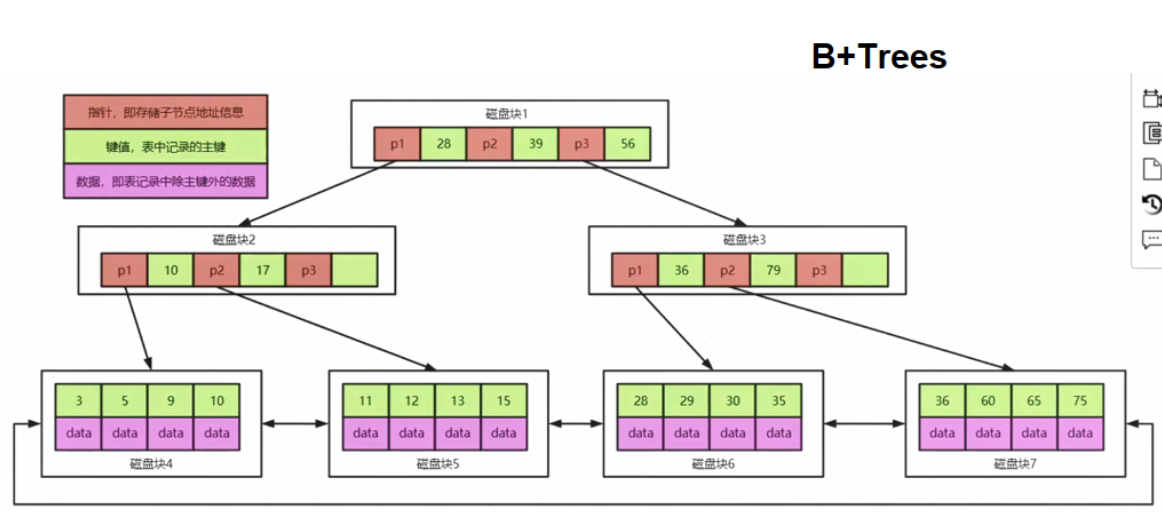
MySQL(B+Trees)为什么不适合做全文检索
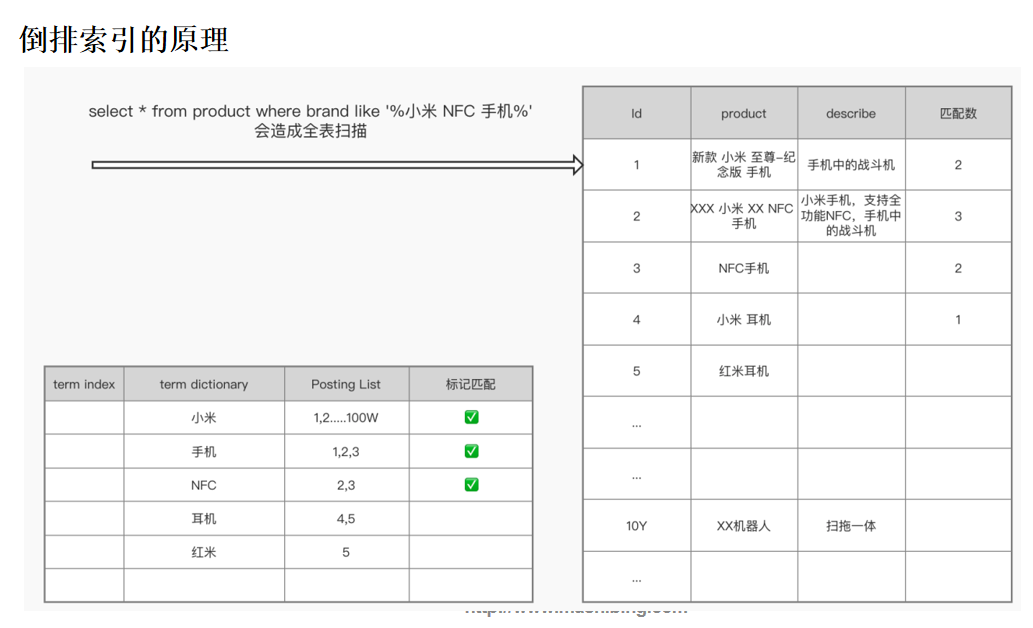
倒排索引基本原理
倒排索引:“关键词”=> “文档ID”,即关键词到文档id的映射。
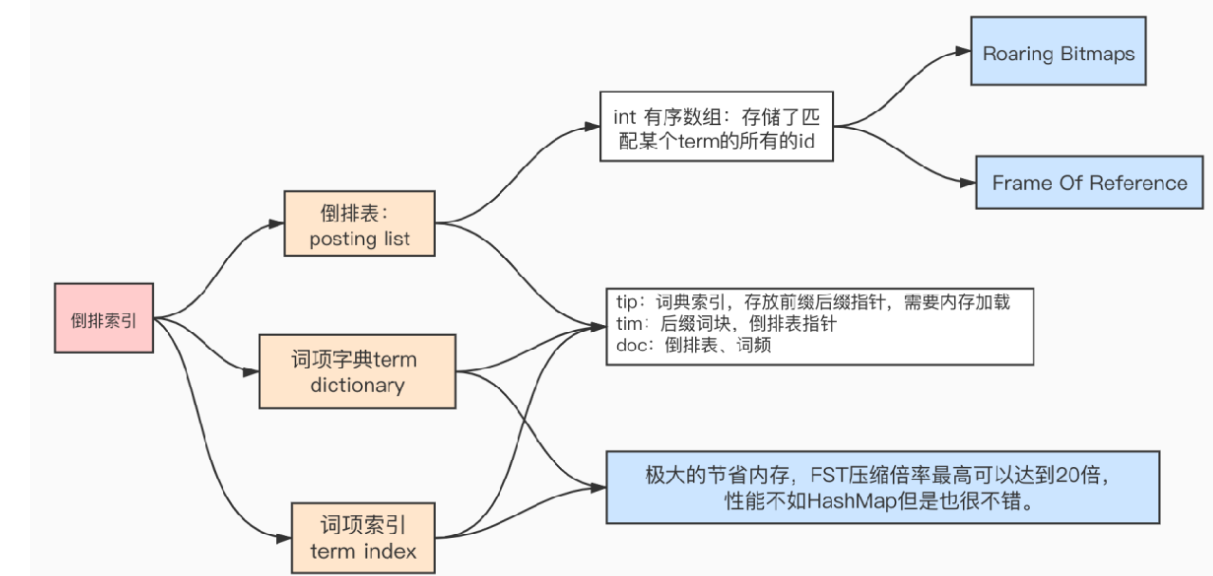
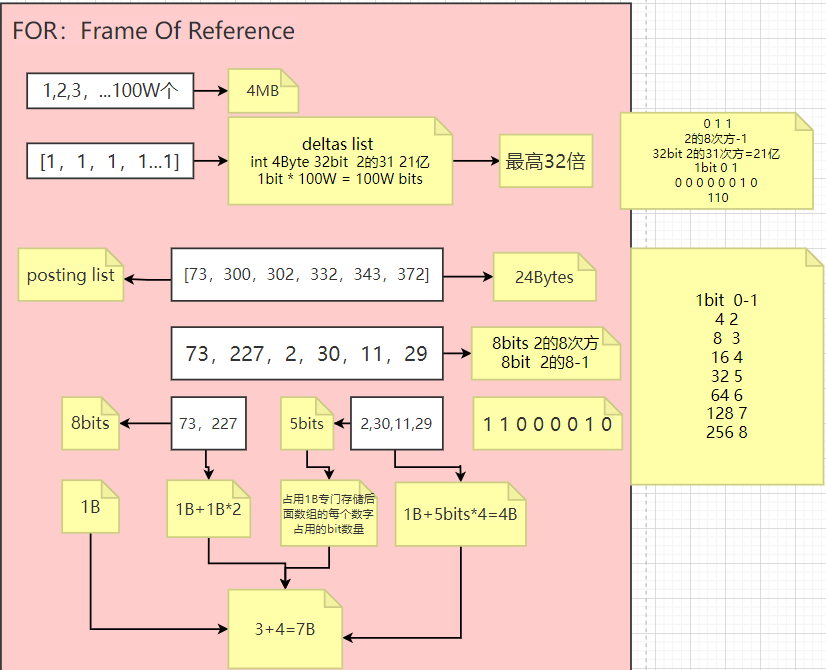
倒排表的压缩算法:FOR
搜索引擎级别的数据量级通常通常在亿级甚至十亿级上,那么也就说如果我们对其建立倒排索引,每个字段被拆分成了若干Term,结果就有可能导致倒排索引的数据量甚至超过了source data,即便我们对倒排索引的检索不必全表扫描,但是太多的数据不管是存储成本还是查询性能可能都不是我们想要的,解决办法就是采用高效的压缩算法和快速的编码和解码算法。
倒排表的压缩算法:RBM
其实上述例子中的数组仍然具有一定的特殊性。因为它是一个稠密数组,可以理解为是一个取值区间波动不大的数组。如果倒排表中出现这样的情况:[1000W, 2001W, 3003W, 5248W, 9548W, 10212W, … , 21Y],情况将会特别糟糕,因为我们如果还按照FOR的压缩算法对这个数组进行压缩,我们对其计算dealta list,可以发现其每个项与前一个数字的差值仍然是一个很大的数值,也就意味着dealta list的每个元素仍然是需要很多bit来存储的。于是Lucene对于这种稀疏数组采用了另一种压缩算法:RBM(Roaring Bitmaps)
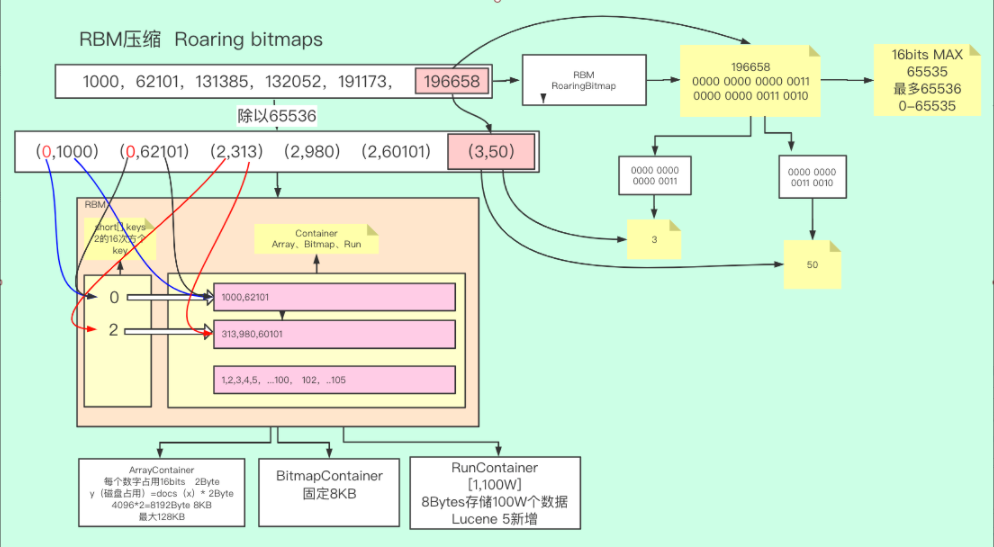
这是一个典型的稀疏型数组。在进行数据压缩的时候,其实不管何种方法,我们的最终目的都是把原来的数字转换成足够小的数字以便于我们存储,同时又必须保证压缩后的数据是可以快速解码的。“减法”不好用,这次我们尝试使用“除法”。由于无符号int类型的最大值不超过2 32 ,因此RBM的策略就是把一个int型拆成两个short型的乘机,具体做法是把数组中的每个元素对216取模,因为被除数是232除数是2 16 ,因此商和余数均小于2 16 。其实这种想法是国内开发者强行转化的逻辑,RBM算法本身的设计思路是将原数字的的32个bit分为了高16位和低16位。以原数组中的196658这个id为例,将其转化为二进制结果为 110000000000110010,我们看到其实结果是不足32bits的,但因为每个int型都是有32个bit组成的,不足32bit会在其前面补0,实际其占用的空间大小仍然为32bits,如果这一点不理解,打个比方,公交车有32个座位,无论是否坐满,都是使用了32个座位。最终196658转换成二进制就是0000 0000 0000 0011 0000 0000 0011 0010,前16位就是高16位,转换成十进制就是3,后16位也就是低16位,转换成十进制就是50,3和50分别正好是196658除以63326(2 16 )的得数和余数,换句话说,int类型的高16位和低16位分别就是其本身对216的商和模。
对数组中每个数字进行相同的操作,会得到以下结果:(0,1000)(0,62101)(2,313)(2,980)(2,60101)(3,50),其含义就是每个数字都由一个很大的数字变为了两个很小的数字,并且这两个数字都不超过65536,更重要的是,当前结果是非常适合压缩的,因为不难看出,出现了很多重复的数字,比如前两个数字的得数都是0,以及第2、3、4个数字的得数都是2。RBM使用了非常适合存储当前结果的数据结构。这种数据结构是一种类似于哈希的结构,只不过Key值是一个short有序不重复数组,用于保存每个商值,value是一个容器,保存了当前Key值对应的所有模,这些模式不重复的,因为同一个商值的余数是不会重复的。这里的容器官方称之为Container,RBM中包含三种Container,分别是ArrayContainer、BitmapContainer和RunContainer。
首先ArrayContainer,顾名思义,Container中实际就是一个short类型的数组,其空间占用的曲线如下图中的红色线段,注意这里是线段,因为docs的数量最大不会超过65536,其函数为 y(空间占用)=x(docs 长度) x 2Bytes,当长度达到65536极限值的时候,其占用的大小就是16bit * 65536 / 8 /1024 = 128KB,乘以65536是总bit数,除以8是换算成Byte,除以1024是换算成KB。
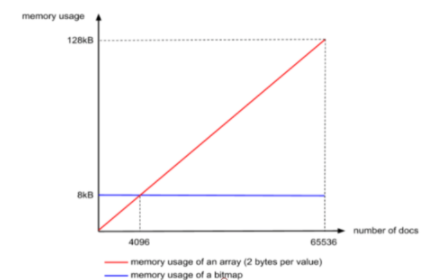
第二种是BitmapContainer,理解BitmapContainer之前首先要了解什么是bitmap。以往最常见的数据存储方式都是二进制进位存储,比如我们使用8个bit存储数字,如果存十进制0,那二进制就是 0 0 0 0 0 0 0 0,如果存十进制1,那就是 0 0 0 0 0 0 0 1,如果存十进制2,那就是 0 0 0 0 0 0 1 1,用到了第二个bit。这种做法在当前场景下存储效率显然不高,如果我们现在不用bit来存储数据,而是用来作为“标记”,即标记当前bit位置商是否存储了数字,出的数字值就是bit的下标,如图所示,就表示存储了2、3、5、7四个数字,第一行数字的bit仅代表当前index位置上是否存储了数字,如果存储了就记作1,否则记为0,存储的数字值就是其index,并且存储这四个数字只使用了一个字节。

不过这种存储方式的问题就是,存储的数字不能包含重复数字,并且Bitmap的大小是固定的,不管是否存储了数值,不管存储了几个值,占用的空间都是恒定的,只和bit的长度有关系。但是我们刚才已经说过,同一个Container中的数字是不会重复的,因此这种数据类型正好适合用这种数据结构作为载体,而因为我们Container的最大容量是65536,因此Bitmap的长度固定为65536,也就是65536个bit,换算成千字节就是8KB,如上面图中的蓝色线段所示,即Lucene的RBM中BitmapContainer固定占用8KB大小的空间,通过对比可以发现,当doc的数量小于4096的时候,使用ArrayContainer更加节省空间,当doc数量大于4096的时候,使用BitmapContainer更加节省空间。
第三种Container叫RunContainer,这种类型是Lucene 5之后新增的类型,主要应用在连续数字的存储商,比如倒排表中存储的数组为 [1,2,3…100W] 这样的连续数组,如果使用RunContainer,只需存储开头和结尾两个数字:1和100W,即占用8个字节。这种存储方式的优缺点都很明显,它严重收到数字连续性的影响,连续的数字越多,它存储的效率就越高。
字典树的存储和遍历过程
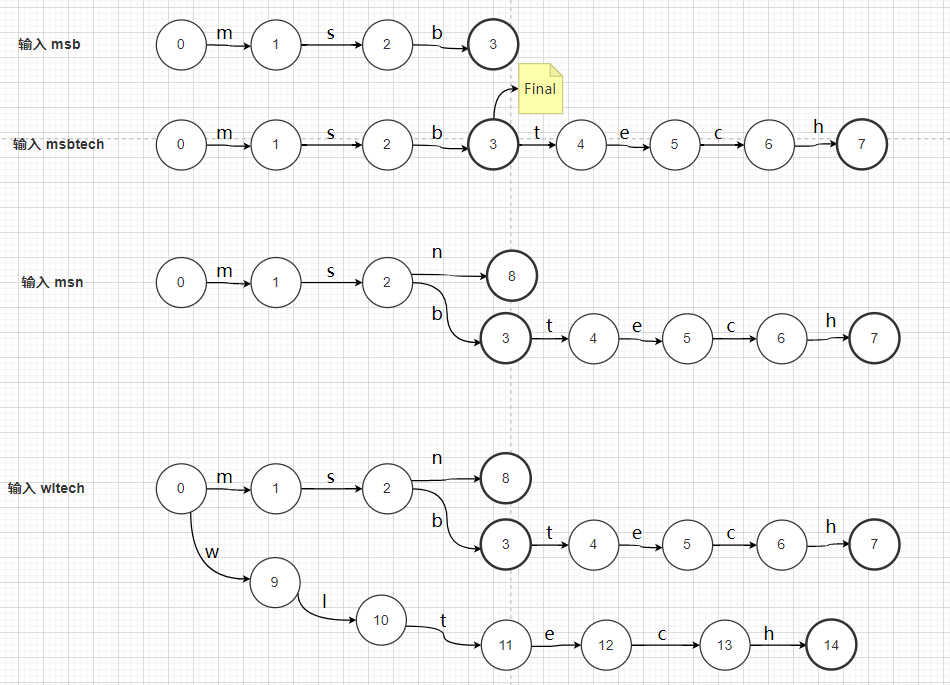
Term Dictionary是字典序非重复的K-V结构的,而通常搜索引擎级别的倒排索引,Term Dictionary动辄以“亿”起步,这势必要求我们在做数据存储时对其数据结构有极其高的要求。假设下图中英汉词典片段就是我们要存储的词项字典,遵循“通用最小化算法”对其进行数据压缩,我们就必须要考虑如何以最小的代价换区最高的效率。通过观察不难发现,无论任何一个Term,无外乎由26个英文字母组成,这也就意味越多的词项就会造成的越多的数据“重复”。这里所说的重复指的是词项之间会有很多个公共部分,如“abandon”和“abandonment”就共享了公共前缀“abandont”。我们是否可以像Java开发过程中对代码的封装那样,重复利用这一部分公共内容呢?答案是肯定的!Lucene在存储这种有重复字符的数据的时候,只会存储一次,也就是哪怕有一亿个以abandon为前缀的词项,“abandom”这个前缀也只会存储一次。这里就用到了一种我们经常用到的一种数据结构:Trie即字典树,也叫前缀树(Prefix Tree)。

下面我们以Term Dictionary:(msb、msbtech、msn、wltech)为例,演示一下Trie是如何存储Term Dictionary的。
更多精彩讲解,后续更新
关注博主,获得第一手更新!
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a