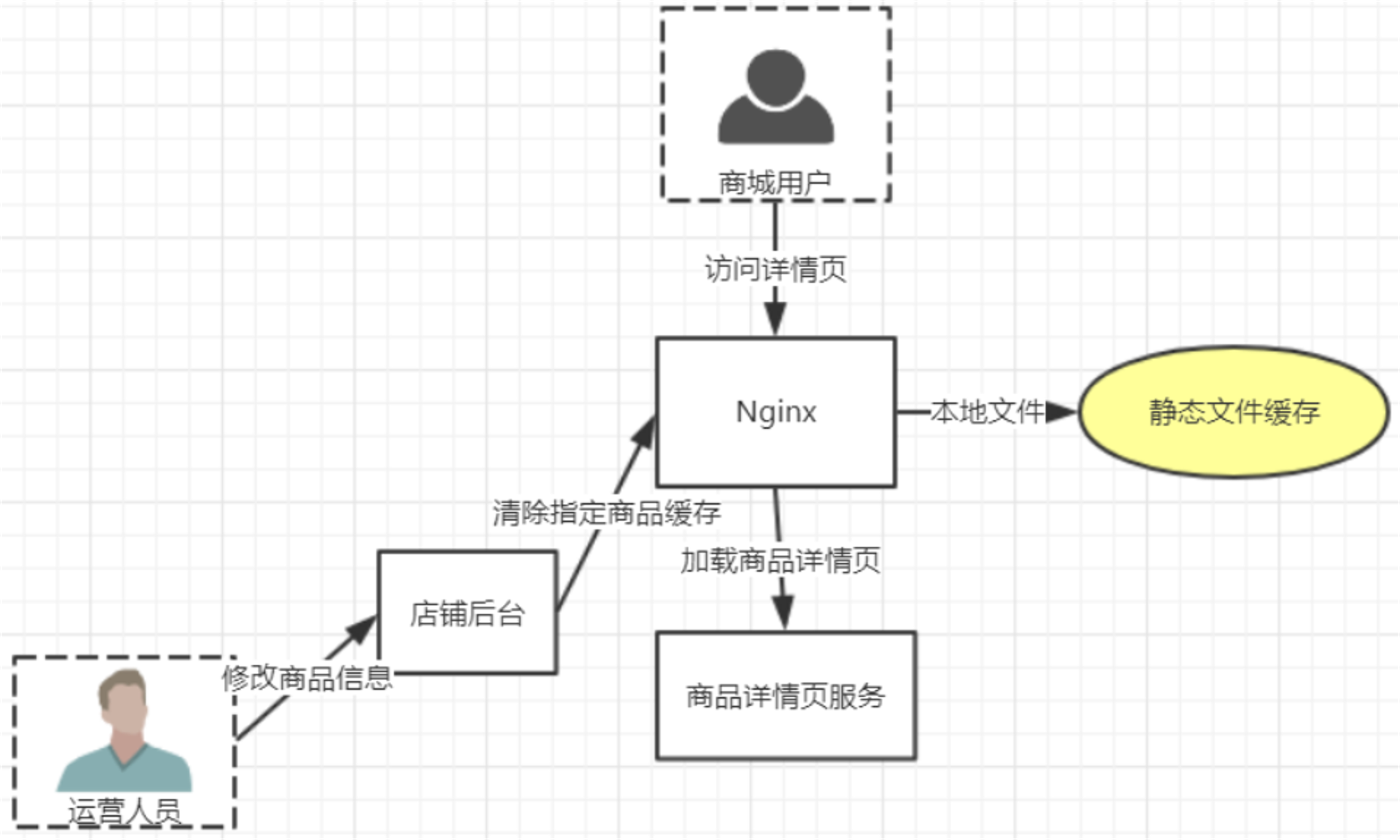
假设某电商平台商品详情页需要实现 700 QPS(假设宽带是千兆宽带)
千M局域网宽带网卡速率按照1000进位,所以1Gbps=1,000,000,000bps=125,000,000Bps≈119.21MB/s
当达到500QPS 的时候很难继续压测上去。
假设每个页面主体渲染所需要的图片的占用150KB,那么500QPS,500 x 150 / 1000 = 75M/s,再加上各种网络请求和网络传输,几乎达到宽带的性能瓶颈,所以必须减少内网通信。
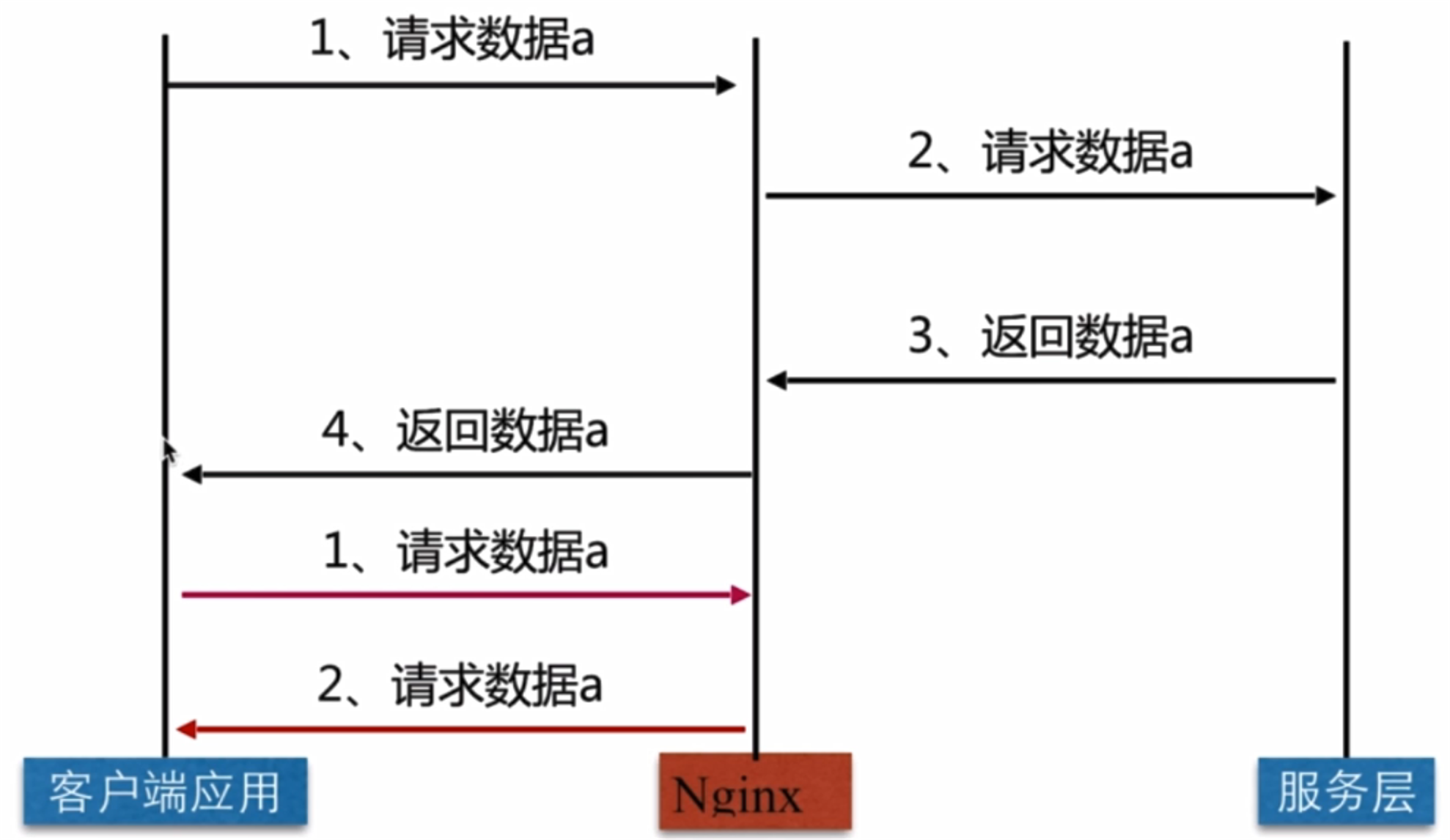
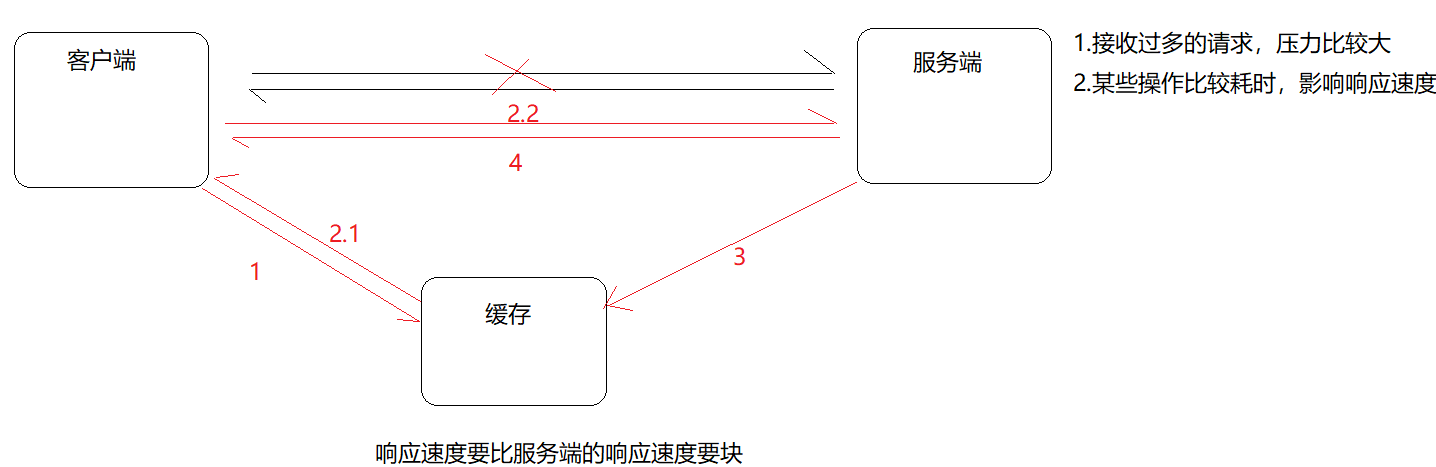
缓存就是数据交换的缓冲区(称作:Cache),当用户要获取数据的时候,会先从缓存中去查询获取数据,如果缓存中有就会直接返回给用户,如果缓存中没有,则会发请求从服务器重新查询数据,将数据返回给用户的同时将数据放入缓存,下次用户就会直接从缓存中获取数据。
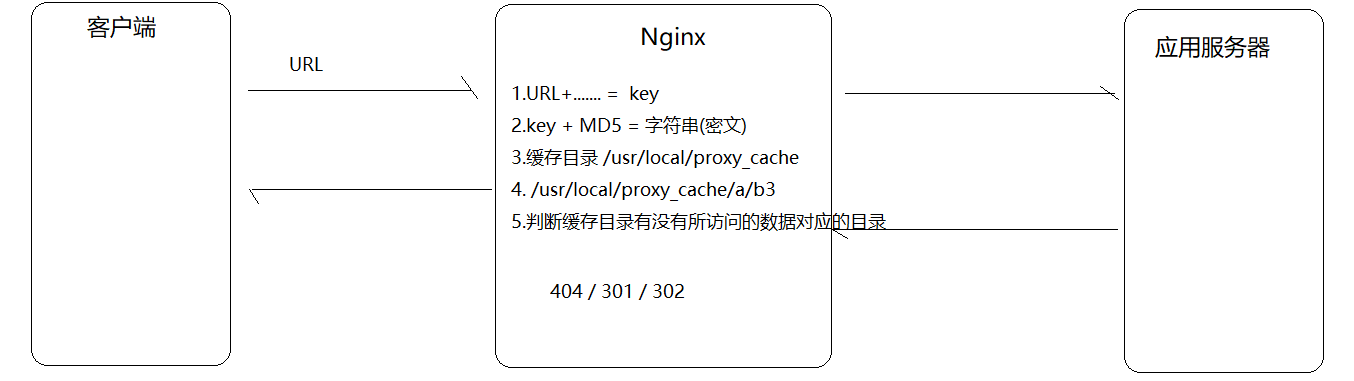
Nginx是从0.7.48版开始提供缓存功能。Nginx是基于Proxy Store来实现的,其原理是把URL及相关组合当做Key,在使用MD5算法对Key进行哈希,得到硬盘上对应的哈希目录路径,从而将缓存内容保存在该目录中。它可以支持任意URL连接,同时也支持404/301/302这样的非200状态码。Nginx即可以支持对指定URL或者状态码设置过期时间,也可以使用purge命令来手动清除指定URL的缓存。
Nginx的web缓存服务主要是使用ngx_http_proxy_module模块相关指令集来完成。
该指定用于设置缓存文件的存放路径
| 语法 | proxy_cache_path path [levels=number] keys_zone=_name_:_size_ [inactive=time][max_size=size]; |
|---|---|
| 默认值 | — |
| 位置 | http |
/home/nginx/proxy_cache
levels: 指定该缓存空间对应的目录,最多可以设置3层,每层取值为1|2
如 : levels=1:2 缓存空间有两层目录,第一层是1个字母,第二层是2个字母
举例说明:
song通过MD5加密以后的值为 683eb609607a439b0561dcbb4c8329e8
levels=1:2 最终的存储路径为/usr/local/proxy_cache/8/9e
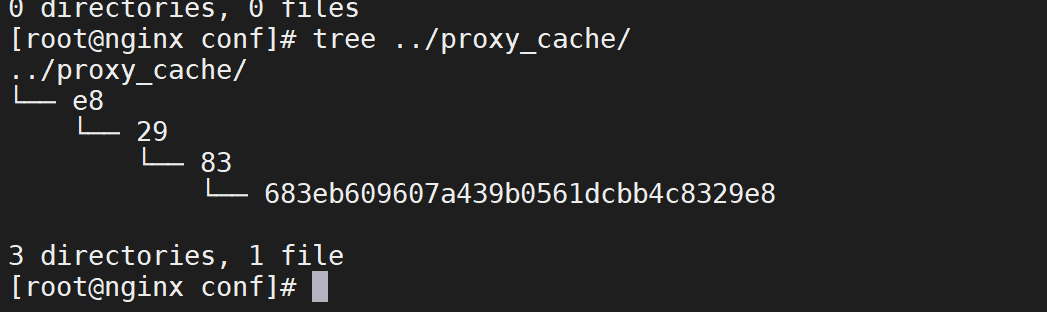
levels=2:1:2 最终的存储路径为/usr/local/proxy_cache/e8/9/32
levels=2:2:2 最终的存储路径为??/usr/local/proxy_cache/e8/29/83
keys_zone=song:200m 缓存区的名称是song,大小为200M,1M大概能存储8000个keys
inactive:指定缓存的数据多次时间未被访问就将被删除,如:
inactive=1d 缓存数据在1天内没有被访问就会被删除
max_size:设置最大缓存空间,如果缓存空间存满,默认会覆盖缓存时间最长的资源,如:
max_size=20g
proxy_cache_path /home/nginx/proxy_cache levels=2:2:2 keys_zone=song:200m inactive=20m max_size=1k;
用来开启或关闭代理缓存,如果是开启则自定使用哪个缓存区来进行缓存。
| 语法 | proxy_cache zone_name|off; |
|---|---|
| 默认值 | proxy_cache off; |
| 位置 | http、server、location |
zone_name:指定使用缓存区的名称
用来设置web缓存的key值,Nginx会根据key值MD5哈希存缓存。
| 语法 | proxy_cache_key key; |
|---|---|
| 默认值 | proxy_cache_key s c h e m e scheme schemeproxy_host$request_uri; |
| 位置 | http、server、location |
用来对不同返回状态码的URL设置不同的缓存时间
| 语法 | proxy_cache_valid [code …] time; |
|---|---|
| 默认值 | — |
| 位置 | http、server、location |
如:proxy_cache_valid 200 302 10m;
proxy_cache_valid 404 1m;
为200和302的响应URL设置10分钟缓存,为404的响应URL设置1分钟缓存
proxy_cache_valid any 1m;
对所有响应状态码的URL都设置1分钟缓存
用来设置资源被访问多少次后被缓存
| 语法 | proxy_cache_min_uses number; |
|---|---|
| 默认值 | proxy_cache_min_uses 1; |
| 位置 | http、server、location |
用来设置缓存哪些HTTP方法
| 语法 | proxy_cache_methods GET|HEAD|POST; |
|---|---|
| 默认值 | proxy_cache_methods GET HEAD; |
| 位置 | http、server、location |
默认缓存HTTP的GET和HEAD方法,不缓存POST方法。
Nginx代理tomcat访问静态资源,访问到的资源缓存到指定目录
http{
proxy_cache_path /home/nginx/proxy_cache levels=2:2:2 keys_zone=song:200m inactive=20m max_size=1k;
server {
listen 8079;
server_name localhost;
# 缓存配置
proxy_cache song;
proxy_cache_key song;
proxy_cache_min_uses 1;
proxy_cache_methods HEAD GET POST;
proxy_cache_valid 200 1d;
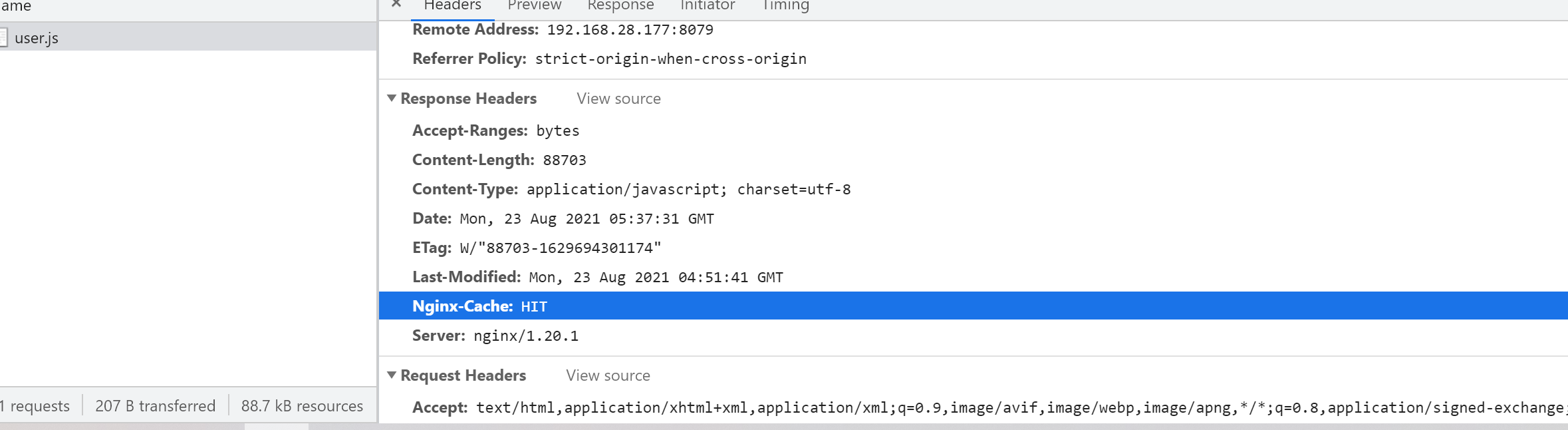
# 加一个头,方便在header中观察是否命中缓存
add_header Nginx-Cache "$upstream_cache_status";
# 反向代理配置
upstream tomcat{
server 192.168.28.177:8080;
}
location /proxy {
proxy_pass http://tomcat/js;
}
}
}
访问http://192.168.28.177:8079/proxy/user.js
观察/home/nginx/proxy_cache目录结构
rm -rf /home/nginx/proxy_cache/...
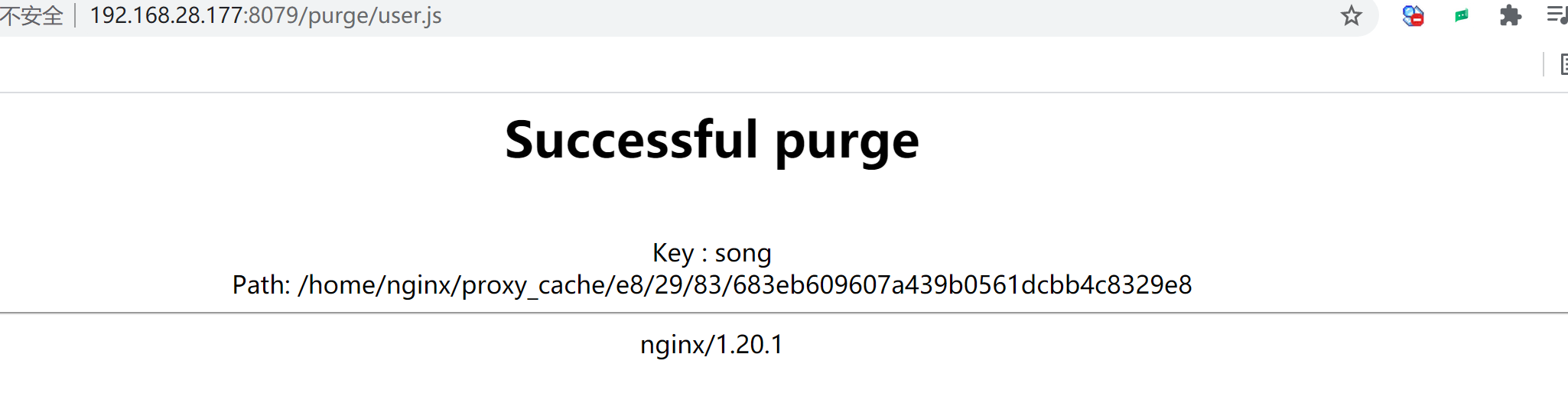
使用ngx_cache_purge删除Nginx缓存.
安装ngx_cache_purge模块
wget http://labs.frickle.com/files/ngx_cache_purge-2.3.tar.gz
tar -xvf ngx_cache_purge-2.3.tar.gz
参考《Nginx基本概念》热部署
不是所有的数据都适合进行缓存。对于一些经常发生变化的数据。如果进行缓存的话,就很容易出现访问到的数据不是服务器真实的数据。所以对于这些资源在缓存的过程中就需要进行过滤,不进行缓存。
用来定义数据不缓存的条件。
| 语法 | proxy_no_cache string …; |
|---|---|
| 默认值 | — |
| 位置 | http、server、location |
proxy_no_cache $cookie_nocache $arg_nocache $arg_comment;
用来设置不从缓存中获取数据的条件。
| 语法 | proxy_cache_bypass string …; |
|---|---|
| 默认值 | — |
| 位置 | http、server、location |
proxy_cache_bypass $cookie_nocache $arg_nocache $arg_comment;
上述两个指令都有一个指定的条件,这个条件可以是多个,并且多个条件中至少有一个不为空且不等于"0",则条件满足成立(或关系)。里面使用到了三个变量,分别是
c
o
o
k
i
e
n
o
c
a
c
h
e
、
cookie_nocache、
cookienocache、arg_nocache、$arg_comment
这三个参数分别代表的含义是
当前请求的**cookie中键的名称**为nocache对应的值
当前请求的参数中**属性名****为nocache和comment对应的属性值**
log_format params $cookie_nocache | $arg_nocache | $arg_comment;
server{
listen 8081;
server_name localhost;
location /{
access_log logs/access_params.log params;
# 设置cookie的nocache属性
add_header Set-Cookie 'nocache=999';
root html;
index index.html;
}
}
http://192.168.28.177:8069/?nocache=111&comment=222日志打印:999|111|222
http://192.168.28.177:8069/?nocache=111日志打印:999|111|-
http://192.168.28.177:8069/日志打印:999|-|-
设置访问的文件是js,不缓存资源
server{
listen 8080;
server_name localhost;
location / {
if ($request_uri ~ /.*\.js$){
# 如果访问的文件是js,设置一个变量nocache
set $nocache 1;
}
proxy_no_cache $nocache $cookie_nocache $arg_nocache $arg_comment;
proxy_cache_bypass $nocache $cookie_nocache $arg_nocache $arg_comment;
}
}
我的瘦服务器配置了nginx,我的ROR应用程序正在它们上运行。在我发布代码更新时运行thinrestart会给我的应用程序带来一些停机时间。我试图弄清楚如何优雅地重启正在运行的Thin实例,但找不到好的解决方案。有没有人能做到这一点? 最佳答案 #Restartjustthethinserverdescribedbythatconfigsudothin-C/etc/thin/mysite.ymlrestartNginx将继续运行并代理请求。如果您将Nginx设置为使用多个上游服务器,例如server{listen80;server
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我试过重新启动apache,缓存的页面仍然出现,所以一定有一个文件夹在某个地方。我没有“公共(public)/缓存”,那么我还应该查看哪些其他地方?是否有一个URL标志也可以触发此效果? 最佳答案 您需要触摸一个文件才能清除phusion,例如:touch/webapps/mycook/tmp/restart.txt参见docs 关于ruby-如何在Ubuntu中清除RubyPhusionPassenger的缓存?,我们在StackOverflow上找到一个类似的问题:
尝试在我的RoR应用程序中实现计数器缓存列时出现错误Unknownkey(s):counter_cache。我在这个问题中实现了模型关联:Modelassociationquestion这是我的迁移:classAddVideoVotesCountToVideos0Video.reset_column_informationVideo.find(:all).eachdo|p|p.update_attributes:videos_votes_count,p.video_votes.lengthendenddefself.downremove_column:videos,:video_vot
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
注意:本文主要掌握DCN自研无线产品的基本配置方法和注意事项,能够进行一般的项目实施、调试与运维AP基本配置命令AP登录用户名和密码均为:adminAP默认IP地址为:192.168.1.10AP默认情况下DHCP开启AP静态地址配置:setmanagementstatic-ip192.168.10.1AP开启/关闭DHCP功能:setmanagementdhcp-statusup/downAP设置默认网关:setstatic-ip-routegeteway192.168.10.254查看AP基本信息:getsystemgetmanagementgetmanaged-apgetrouteAP配
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模