文章目录
我们做数据分析的时候经常会遇到去重问题,下面总结 sql 去重的几种方式,后续如果还有再补充,大数据分析层面包括 hive、clickhouse 也可参考。
本文以 mysql 作为作为例子进行 sql 去重的实现。首先准备一张表:
t_score
create table t_score(
ts datetime,
id varchar(10),
name varchar(255),
score int(3)
)
datetime: 入库时间
id :学号
name:姓名
soce :分数
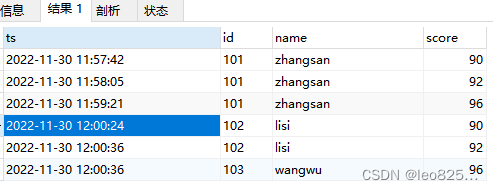
insert into t_score value(now(), '101','zhangsan', 90);
insert into t_score value(now(), '101','zhangsan', 92);
insert into t_score value(now(), '101','zhangsan', 96);
insert into t_score value(now(), '102','lisi', 90);
insert into t_score value(now(), '102','lisi', 92);
insert into t_score value(now(), '103','wangwu', 96);
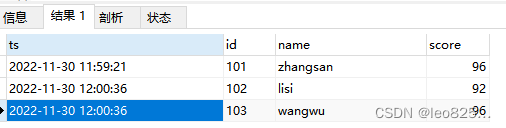
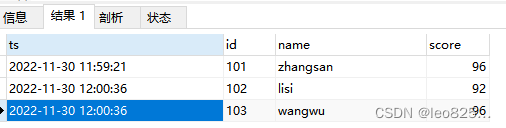
最终目标是根据时间去重,将入库时间最新的数据留下,id 重复的认为是重复数据。
最终期望得到的结果为:
首先想到的就是 distinct 关键字去重,先要了解一下这个关键字的含义和用法。
含义:distinct用来查询不重复记录的条数,即distinct来返回不重复字段的条数(count(distinct id)),其原因是distinct只能返回他的目标字段,而无法返回其他字段。
用法注意:
1.distinct【查询字段】,必须放在要查询字段的开头,即放在第一个参数;
2.只能在SELECT 语句中使用,不能在 INSERT, DELETE, UPDATE 中使用;
3.DISTINCT 表示对后面的所有参数的拼接取不重复的记录,即查出的参数拼接每行记录都是唯一的
4.不能与all同时使用,默认情况下,查询时返回的就是所有的结果。
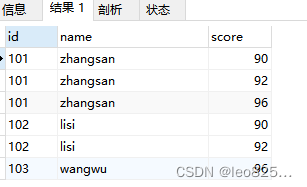
使用 distinct 不能满足我们的去重需求:
SELECT DISTINCT
( id ),
NAME,
score
FROM
t_score
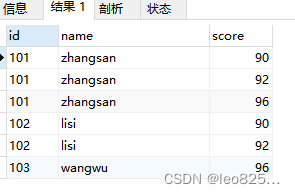
group by 是分组去重,但是仅仅使用group by 也达不到去重求最新的目的
SELECT
id,
name,
score
FROM
t_score
GROUP BY
id,
name,
score
首先,取出来每行数据的最大时间(即最新时间),然后让原表数据和最大时间做右连接,得到的就是最新的数据。
SELECT
a0.*
FROM
t_score a0
RIGHT JOIN (
SELECT
max(ts) tsMax,
id
FROM
t_score
GROUP BY
id
) b0 ON a0.ts = b0.tsMax
AND a0.id = b0.id
方案二为方案一的变种,使用了exists 关键字来获取时间上最新的数据
SELECT
a0.*
FROM
t_score a0
WHERE
EXISTS (
SELECT
*
FROM
(
SELECT
max(ts) tsMax,
id
FROM
t_score
GROUP BY
id
) b0
WHERE
b0.tsMax = a0.ts
AND b0.id = a0.id
)
使用 row_number() over (parttion by 分组列 order by 排序列) 方式
SELECT
*
FROM
( SELECT *, row_number() over ( PARTITION BY id ORDER BY ts DESC ) num FROM t_score ) a0
WHERE
a0.num = 1
需要注意的是:MySQL从8.0开始支持窗口函数
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
question的一些答案关于redirect_to让我想到了其他一些问题。基本上,我正在使用Rails2.1编写博客应用程序。我一直在尝试自己完成大部分工作(因为我对Rails有所了解),但在需要时会引用Internet上的教程和引用资料。我设法让一个简单的博客正常运行,然后我尝试添加评论。靠我自己,我设法让它进入了可以从script/console添加评论的阶段,但我无法让表单正常工作。我遵循的其中一个教程建议在帖子Controller中创建一个“评论”操作,以添加评论。我的问题是:这是“标准”方式吗?我的另一个问题的答案之一似乎暗示应该有一个CommentsController参
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
这是针对我无法破坏的现有公共(public)API,但我确实希望对其进行扩展。目前,该方法采用字符串或符号或任何其他在作为第一个参数传递给send时有意义的内容我想添加发送字符串、符号等列表的功能。我可以只使用is_a吗?数组,但还有其他发送列表的方法,这不是很像ruby。我将调用列表中的map,所以第一个倾向是使用respond_to?:map。但是字符串也会响应:map,所以这行不通。 最佳答案 如何将它们全部视为数组?String的行为与仅包含String的Array相同:deffoo(obj,arg)[*arg].eac
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我创建了一个由于“在运行时执行的单例元类定义”而无法编码的对象(这段代码的描述是否正确?)。这是通过以下代码执行的:#defineclassXthatmyusesingletonclassmetaprogrammingfeatures#throughcallofmethod:break_marshalling!classXdefbreak_marshalling!meta_class=class我该怎么做才能使对象编码正确?是否可以从对象instance_of_x的classX中“移除”单例组件?我真的需要一个建议,因为我们的一些对象需要通过Marshal.dump序列化机制进行缓存。