目录
🦐博客主页:大虾好吃吗的博客
🦐MySQL专栏:MySQL专栏地址
生产环境中一台mysql主机存在单点故障,所以我们要确保mysql的高可用性,即两台MySQL服务器如果其中有一台MySQL服务器挂掉后,另外一台能立马接替其进行工作。 MySQL的高可用方案一般有如下几种:keepalived+双主,MHA,PXC,MMM,Heartbeat+DRBD等,比较常用的是keepalived+双主,MHA和PXC。本节主要介绍了利用 keepalived 实现 MySQL 数据库的高可用。 Keepalived+mysql双主来实现MySQL-HA,我们必须保证两台MySQL数据库的数据完全一样,基本思路是两台MySQL互为主从关系,通过Keepalived配置虚拟IP,实现当其中的一台MySQL数据库宕机后,应用能够自动切换到另外一台MySQL数据库,保证系统的高可用。
打开三台MySQL服务器,8.1为测试机,8.2和8.3先配置双主,而后安装keepalived实现高可用。

该过程的第一部分就是master记录二进制日志,在每个事务更新数据完成之前,master在二日志记录这些改变。MySQL将事务写入二进制日志,在事件写入二进制日志完成后,master通知存储引擎提交事务。 下一步就是slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经同步了master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志, SQL slave thread(SQL从线程)处理该过程的最后一步。SQL线程从中继日志读取事件,并重放其中的事件而更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。 主主同步就是两台机器互为主的关系,在任何一台机器上写入都会同步。 若mysql主机开启了防火墙,需要关闭防火墙或创建规则。
两台MySQL均要开启binlog日志功能,开启方法:在MySQL配置文件[MySQLd]段中加上log-bin=MySQL-bin选项,两台MySQL的server-ID不能一样,默认情况下两台MySQL的serverID都是1,需将其中一台修改为2即可。
1、master中有关复制的配置如下:
[root@master ~]# vim /etc/my.cnf
#添加下面内容
log-bin=mysql-bin
binlog_format=mixed
server_id=1
relay-log=relay-bin
relay-log-index=slave-relay-bin.index
auto-increment-increment=2
auto-increment-offset=1
[root@master ~]# service mysqld restart
Shutting down MySQL.. [ 确定 ]
Starting MySQL. [ 确定 ]2、 slave中有关复制的配置如下:
[root@slave ~]# vim /etc/my.cnf
#添加下面内容
log-bin=mysql-bin
binlog_format=mixed
server_id=2
relay-log=relay-bin
relay-log-index=slave-relay-bin.index
auto-increment-increment=2
auto-increment-offset=2
[root@slave ~]# service mysqld restart
Shutting down MySQL.. [ 确定 ]
Starting MySQL..... [ 确定 ]注意:master和slave只有server-id不同和 auto-increment-offset不同。mysql中有自增长字段,在做数据库的主主同步时需要设置自增长的两个相关配置:auto_increment_offset和auto_increment_increment。 auto-increment-increment表示自增长字段每次递增的量,其默认值是1。它的值应设为整个结构中服务器的总数,本案例用到两台服务器,所以值设为2(可以理解为有几台服务器做集群就设为几)。 auto-increment-offset是用来设定数据库中自动增长的起点(即初始值),因为这两能服务器都设定了一次自动增长值2,所以它们的起点必须得不同,这样才能避免两台服务器数据同步时出现主键冲突,注:可以在my.cnf文件中添加“binlog_do_db=数据库名”配置项(可以添加多个)来指定要同步的数据库。
1、将master设为slave的主服务器
在master主机上创建授权账户,允许在slave(192.168.8.3)主机上连接。
[root@master ~]# mysql -uroot -p123
#省略登录信息
mysql> grant replication slave on *.* to rep@'192.168.8.%' identified by '123';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)2、查看master的当前binlog状态信息
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 608 | | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)3、在slave上将master设为自已的主服务器并开启slave功能。
[root@slave ~]# mysql -uroot -p123
#省略登录信息
mysql> change master to
-> master_host='192.168.8.2',
-> master_user='rep',
-> master_password='123',
-> master_log_file='mysql-bin.000001',
-> master_log_pos=608;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)4、设置master防火墙
模拟环境中关闭防火墙即可,生产环境中需要配置防火墙策略,允许3306端口。
[root@master ~]# firewall-cmd --permanent --add-port=3306/tcp
success
[root@master ~]# firewall-cmd --add-port=3306/tcp
success此刻查看8.3的状态,show slave status\G;以下两个值必须为yes,代表从服务器能正常连接主服务器。
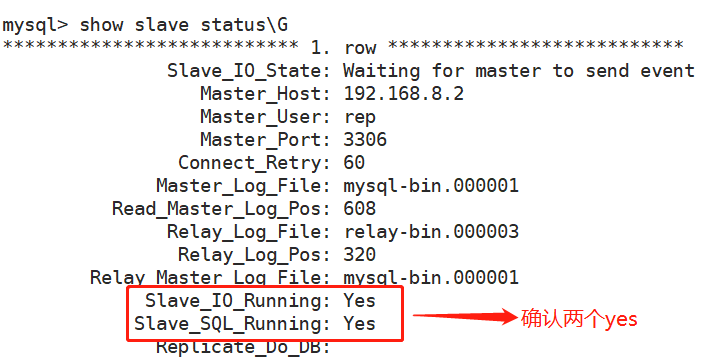
5、将slave设为master的主服务器
在slave主机上创建授权账户,允许在master1(192.168.8.2)主机上连接
mysql> grant replication slave on *.* to rep@'192.168.8.%' identified by '123';
Query OK, 0 rows affected, 1 warning (0.02 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)6、查看slave的当前binlog状态信息
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 608 | | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)7、在master上将slave设为自已的主服务器并开启slave功能。
[root@master ~]# mysql -uroot -p123
#省略登录信息
mysql> change master to
-> master_host='192.168.8.3',
-> master_user='rep',
-> master_password='123',
-> master_log_file='mysql-bin.000001',
-> master_log_pos=608;
Query OK, 0 rows affected, 2 warnings (0.03 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)8、设置slave防火墙
[root@slave ~]# firewall-cmd --permanent --add-port=3306/tcp
success
[root@slave ~]# firewall-cmd --add-port=3306/tcp
success查看8.2的状态,以下两个值必须为yes,代表从服务器能正常连接主服务器
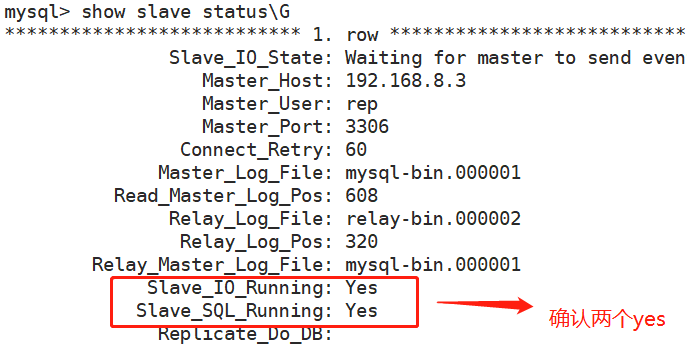
1、在master上创建要同步的数据库如bbs,并在bbs中创建一张测试表如tb1
mysql> create database bbs character set utf8;
Query OK, 1 row affected (0.01 sec)
mysql> use bbs;
Database changed
mysql> create table tb1(
-> id int,
-> name varchar(20));
Query OK, 0 rows affected (0.02 sec)2、查看master2主机是否同步了master1上的数据变化
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| bbs |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.02 sec)
mysql> use bbs;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+---------------+
| Tables_in_bbs |
+---------------+
| tb1 |
+---------------+
1 row in set (0.00 sec)3、从上面可以看出slave同步了master的数据变化,测试在slave主机上向tb1表中插入数据
mysql> insert into tb1 values(1,'z3'),(2,'l4');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 04、查看master主机是否同步了slave上的数据变化
mysql> select * from tb1;
+------+------+
| id | name |
+------+------+
| 1 | z3 |
| 2 | l4 |
+------+------+
2 rows in set (0.01 sec)通过查看master可以看到slave更新的数据,现在在任何一台mysql上更新数据都会同步到另一台mysql中,双主同步完成。
注意:若主MYSQL服务器已经存在,只是后期才搭建从MYSQL服务器,在置配数据同步前应先将主MYSQL服务器的要同步的数据库拷贝到从MYSQL服务器上(如先在主MYSQL上备份数据库,再用备份在从MYSQL服务器上恢复)
keepalived是集群管理中保证集群高可用的一个软件解决方案,其功能类似于heartbeat,用来防止单点故障 keepalived是以VRRP协议为实现基础的,VRRP全称Virtual RouterRedundancy Protocol,即虚拟路由冗余协议。 虚拟路由冗余协议,可以认为是实现路由器高可用的协议,即将N台提供相同功能的路由器组成一个路由器组,这个组里面有一个master和多个backup,master上面有一个对外提供服务的vip,master会发组播(组播地址为224.0.0.18),当backup收不到vrrp包时就认为master宕掉了,这时就需要根据VRRP的优先级来选举一个backup当master。这样的话就可以保证路由器的高可用了。keepalived主要有三个模块,分别是core 、check和vrrp。core模块为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析。check负责健康检查,包括常见的各种检查方式。vrrp模块是来实现VRRP协议的。
1、在master和slave上安装软件包keepalived与服务控制
在编译安装Keepalived之前,必须先安装内核开发包kernel-devel以及openssl-devel、popt-devel等支持库。
[root@master ~]# wget https://www.keepalived.org/software/keepalived-2.0.20.tar.gz
[root@master ~]# yum -y install kernel-devel openssl-devel popt-devel若没有安装则通过rpm或yum工具进行安装 编译安装Keepalived
[root@master ~]# tar zxf keepalived-2.0.20.tar.gz
[root@master ~]# cd keepalived-2.0.20/
[root@master keepalived-2.0.20]# ./configure --prefix=/ && make && make install注意:如不知道keepalived需要哪些依赖包,可到下载后的源码解压目录下查看INSTALL 文件内容, 执行makeinstall操作之后,会自动生成/etc/init.d/keepalived脚本文件,但还需要手动添加为系统服务,这样就可以使用service、chkconfig工具来对keepalived服务程序进行管理了。
slave主机也完成keepalived安装,与master一样,安装过程略,两台mysql如果开启防火墙需要添加防火墙规则.
[root@slave ~]# firewall-cmd --direct --permanent --add-rule ipv4 filter OUTPUT 0 --in-interface ens33 --destination 224.0.0.18 --protocol vrrp -j ACCEPT
success
[root@slave ~]# firewall-cmd --direct --permanent --add-rule ipv4 filter INPUT 0 --in-interface ens33 --destination 224.0.0.18 --protocol vrrp -j ACCEPT
success
[root@slave ~]# firewall-cmd --reload
success2、修改Keepalived的配置文件
keepalived只有一个配置文件keepalived.conf,里面主要包括以下几个配置区域,分别是global_defs、vrrp_instance和virtual_server。 global_defs:主要是配置故障发生时的通知对象以及机器标识。 vrrp_instance:用来定义对外提供服务的VIP区域及其相关属性。 virtual_server:虚拟服务器定义
keepalived.conf文件解释如下:
! Configuration File for keepalived #!表示注释
global_defs {
router_id LVS_DEVEL #router_id名称(唯一)
}
vrrp_instance VI_1 {
state MASTER #指定keepalived的角色, (分别为MASTER|BACKUP)本次实验两台配置均是BACKUP,设为BACKUP将根据优先级决定主或从
interface eth0 #指定HA监测网络的接口
virtual_router_id 51 #虚拟路由标识,这个标识是一个数字(取值在0-255之间,用来区分多个instance的VRRP组播),同一个vrrp实例使用唯一的标识,确保和slave相同,同网内不同集群此项必须不同,否则发生冲突。
priority 100 #用来选举master的,要成为master,该项取值范围是1-255(在此范围之外会被识别成默认值100),此处slave上设置为50
advert_int 1 #发VRRP包的时间间隔,即多久进行一次master选举(可以认为是健康查检时间间隔)
nopreempt #不抢占,即允许一个priority比较低的节点作为master,即使有priority更高的节点启动
authentication { #认证区域,认证类型有PASS和HA(IPSEC),推荐使用PASS(密码只识别前8位)
auth_type PASS
auth_pass 1111
}
virtual_ipaddress { #VIP区域,指定vip地址
192.168.200.16
192.168.200.17
192.168.200.18
}
}
virtual_server 192.168.200.100 443 { #设置虚拟服务器,需要指定虚拟IP地址和服务端口,IP与端口之间用空格隔开
delay_loop 6 #设置运行情况检查时间,单位是秒
lb_algo rr #设置后端调度算法,这里设置为rr,即轮询算法
lb_kind NAT #设置LVS实现负载均衡的机制,有NAT、TUN、DR三个模式可选
persistence_timeout 50 #会话保持时间,单位是秒。这个选项对动态网页是非常有用的,为集群系统中的session共享提供了一个很好的解决方案。有了这个会话保持功能,用户的请求会被一直分发到某个服务节点,直到超过这个会话的保持时间。
protocol TCP #指定转发协议类型,有TCP和UDP两种
real_server 192.168.201.100 443 { #配置服务节点1,需要指定real server的真实IP地址和端口,IP与端口之间用空格隔开注(即本机ip)
weight 1 #配置服务节点的权值,权值大小用数字表示,数字越大,权值越高,设置权值大小为了区分不同性能的服务器
notify_down /etc/keepalived/bin/mysql.sh #检测到realserver的mysql服务down后执行的脚本
TCP_CHECK {
connect_timeout 3 #连接超时时间
nb_get_retry 3 #重连次数
delay_before_retry 3 #重连间隔时间
connect_port 3306 #健康检查端口
}
}
}master主机配置修改如下:(其他没用的节点推荐删掉)
[root@master ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lb1
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
nopreempt
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.8.100
}
}
virtual_server 192.168.8.100 3306 {
delay_loop 6
lb_algo rr
lb_kind DR
persistence_timeout 50
protocol TCP
real_server 192.168.8.2 3306 {
weight 1
notify_down /etc/keepalived/bin/mysql.sh
TCP_CHECK {
connect_port 3306
connect_timeout 3
retry 3
delay_before_retry 3
}
}
}
[root@master ~]# systemctl start keepalived
[root@master ~]# mkdir /etc/keepalived/bin
[root@master ~]# vim /etc/keepalived/bin/mysql.sh #创建脚本文件
#!/bin/bash
pkill keepalivedslave主机上的keepalived.conf文件的修改: 可以使用scp命令把master主机上配置好的keepalived.conf文件拷贝到slave主机,只要做简单修改即可,如下所示:
[root@master ~]# scp /etc/keepalived/keepalived.conf root@192.168.8.3:/etc/keepalived/
#省略传输过程
[root@slave ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lb2 #修改
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
nopreempt
virtual_router_id 51
priority 50 #修改
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.8.100
}
}
virtual_server 192.168.8.100 3306 {
delay_loop 6
lb_algo rr
lb_kind DR
persistence_timeout 50
protocol TCP
real_server 192.168.8.3 3306 { #修改
weight 1
notify_down /etc/keepalived/bin/mysql.sh
TCP_CHECK {
connect_port 3306
connect_timeout 3
retry 3
delay_before_retry 3
}
}
}
[root@slave ~]# systemctl start keepalived
[root@slave ~]# mkdir /etc/keepalived/bin
[root@slave ~]# vim /etc/keepalived/bin/mysql.sh
#!/bin/bash
pkill keepalived在master和slave分别执行命令查看master和slave对VIP(群集虚拟IP)的控制权。
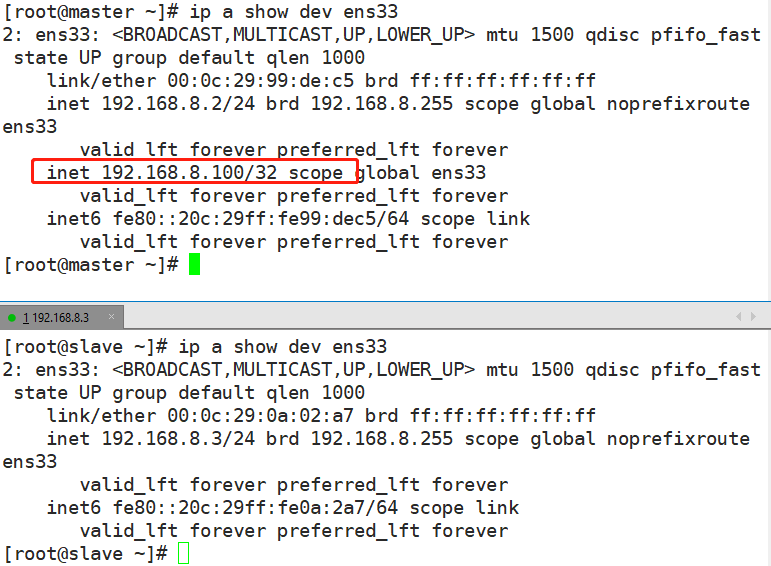
从上图可以看出master是主服务器,slave为备用服务器。 停止MySQL服务,看keepaliv ed健康检查程序是否会触发我们编写的脚本。
关闭master上的mysql服务,使用测试机连接vip地址尝试远程连接,验证是否成功,成功后插入数据测试。
Keepalived+mysql双主一般来说,中小型规模的时候,采用这种架构是最省事的。 在master节点发生故障后,利用keepalived的高可用机制实现快速切换到备用节点。 在这个方案里,有几个需要注意的地方:
采用keepalived作为高可用方案时,两个节点最好都设置成BACKUP模式,避免因为意外情况下(比如脑裂)相互抢占导致往两个节点写入相同数据而引发冲突;
把两个节点的auto_increment_increment(自增步长)和auto_increment_offset(自增起始值)设成不同值。其目的是为了避免master节点意外宕机时,可能会有部分binlog未能及时复制到slave上被应用,从而会导致slave新写入数据的自增值和原先master上冲突了,因此一开始就使其错开;当然了,如果有合适的容错机制能解决主从自增ID冲突的话,也可以不这么做;
slave节点服务器配置不要太差,否则更容易导致复制延迟。作为热备节点的slave服务器,硬件配置不能低于master节点;
如果对延迟问题很敏感的话,可考虑使用MariaDB分支版本,或者直接上线MySQL 5.7最新版本,利用多线程复制的方式可以很大程度降低复制延迟;
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
我的rails3.1.6应用程序中有一个自定义访问器方法,它为一个属性分配一个值,即使该值不存在。my_attr属性是一个序列化的哈希,除非为空白,否则应与给定值合并指定了值,在这种情况下,它将当前值设置为空值。(添加了检查以确保值是它们应该的值,但为简洁起见被删除,因为它们不是我的问题的一部分。)我的setter定义为:defmy_attr=(new_val)cur_val=read_attribute(:my_attr)#storecurrentvalue#makesureweareworkingwithahash,andresetvalueifablankvalueisgiven
我正在尝试绕过rails配置这个极其复杂的迷宫。到目前为止,我设法在ubuntu上设置了rvm(出于某种原因,ruby在ubuntu存储库中已经过时了)。我设法建立了一个Rails项目。我希望我的测试项目使用mysql而不是mysqlite。当我尝试“rakedb:migrate”时,出现错误:“!!!缺少mysql2gem。将其添加到您的Gemfile:gem'mysql2'”当我尝试“geminstallmysql”时,出现错误,告诉我需要为安装命令提供参数。但是,参数列表很大,我不知道该选择哪些。如何通过在ubuntu上运行的rvm和mysql获取rails3?谢谢。
有没有办法在liquidtemplate中输出(用于调试/信息目的)可用对象和对象属性??也就是说,假设我正在使用jekyll站点生成工具,并且我在我的index.html模板中(据我所知,这是一个液体模板)。它可能看起来像这样{%forpostinsite.posts%}{{post.date|date_to_string}}»{{post.title}}{%endfor%}是否有任何我可以使用的模板标签会告诉我/输出名为post的变量在此模板(以及其他模板)中可用。此外,是否有任何模板标签可以告诉我post对象具有键date、title、url、摘录、永久链接等
我尝试在我的应用中只使用:symbols作为关键词。我尝试在:symbol=>logic或string=>UI/languagespecific之间做出严格的决定但我也得到了每个JSON的一些“值”(即选项等),因为JSON中没有:symbols,所以我调用的所有哈希都具有“with_indifferent_access”属性。但是:数组是否有相同的东西?像那样a=['std','elliptic',:cubic].with_indifferent_accessa.include?:std=>true?编辑:将rails添加到标签 最佳答案
我进行了一些谷歌搜索,似乎缺少用于jRuby的IDE。我读过TextMate和Sublime,但它们不提供调试或代码完成功能。有人可以提出建议吗(或者这项技术还处于起步阶段)? 最佳答案 有几个选项;我更喜欢JetBrains'IntelliJ(RubyMine).AptanahasanEclipseplugin.NetBeansusedtohaveofficialsupport,不确定currentstate是什么是。 关于ruby-哪些IDE可用于jRuby?,我们在StackOve
我将guard与rspec和cucumber一起使用。要连续运行选定的规范,我只需使用focus标记来确定我要处理的内容。但问题是,如果没有带有该标签的规范,我想运行所有规范。我该怎么做?注意::我知道所有RSpec选项。因此,请仅在阅读问题后回复。 最佳答案 我通过以下配置实现了您描述的行为:#torunonlyspecificspecs,add:focustothespec#describe"foo",:focusdo#OR#it"shouldfoo",:focusdoconfig.treat_symbols_as_metada
