博客昵称:架构师Cool
最喜欢的座右铭:一以贯之的努力,不得懈怠的人生。
作者简介:一名退役Coder,软件设计师/鸿蒙高级工程师认证,在备战高级架构师/系统分析师,欢迎关注小弟!
博主小留言:哈喽!各位CSDN的uu们,我是你的小弟Cool,希望我的文章可以给您带来一定的帮助
个人百万笔记知识库, 所有基础的笔记都在这里面啦,点击左边蓝字即可获取!助力每一位未来架构师!
欢迎大家在评论区唠嗑指正,觉得好的话别忘了一键三连哦!😘
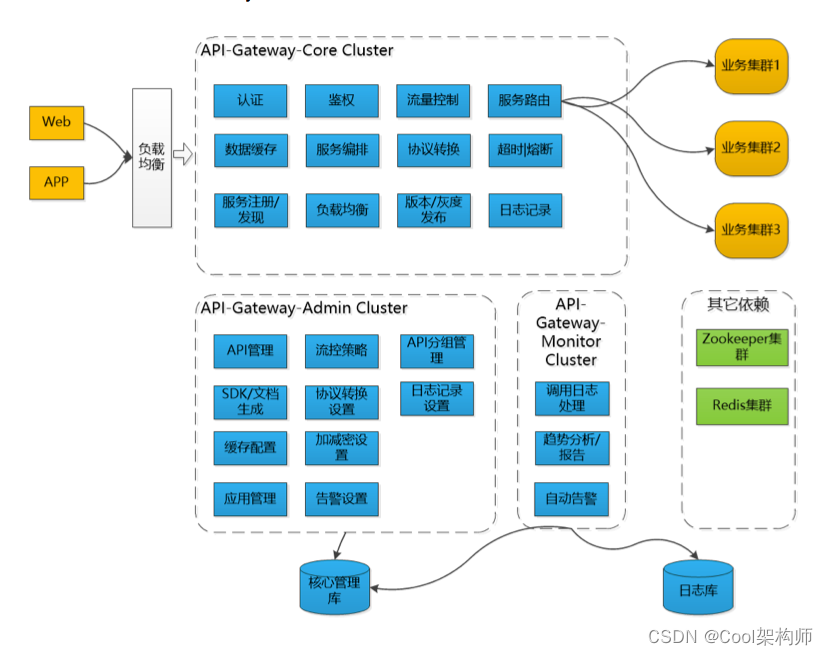
网关策略
请求安全是API网关非常重要的能力,集成了丰富的安全相关的系统组件,包括有基础的请求签名、SSO单点登录、基于SSO鉴权的UAC/UPM访问控制、用户鉴权Passport、商家鉴权EPassport、商家权益鉴权、反爬等等。业务研发人员只需要简单配置,即可使用。
API网关按业务线维度进行集群隔离,也支持重要业务独立部署。如下图所示:

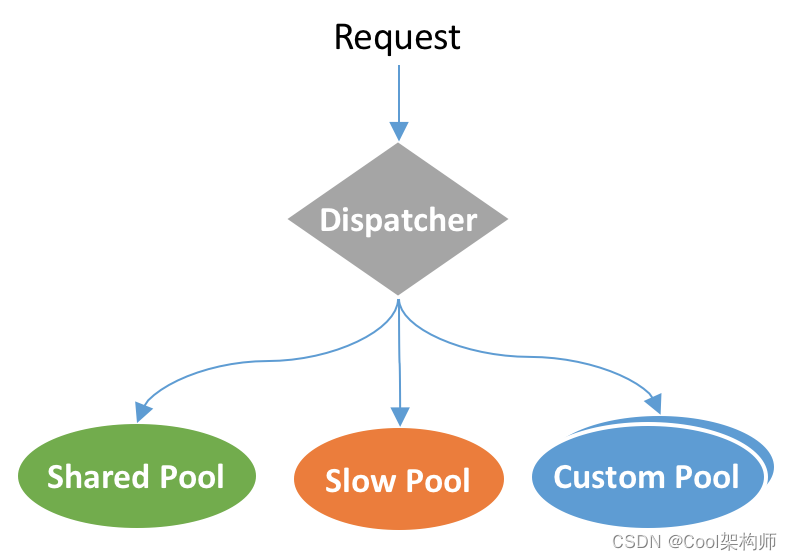
服务节点维度,API网关支持请求的快慢线程池隔离。快慢线程池隔离主要用于一些使用了同步阻塞组件的API,例如SSO鉴权、自定义鉴权等,可能导致长时间阻塞共享业务线程池。快慢隔离的原理是统计API请求的处理时间,将请求处理耗时较长,超过容忍阈值的API请求隔离到慢线程池,避免影响其他正常API的调用。除此之外,也支持业务研发人员配置自定义线程池进行隔离。具体的线程隔离模型如下图所示:
API网关作为请求入口,往往肩负着请求流量灰度验证的重任。
灰度场景
在灰度能力上,支持灰度API自身逻辑,也支持灰度下游服务,也可以同时灰度API自身逻辑和下游服务。如下图所示:
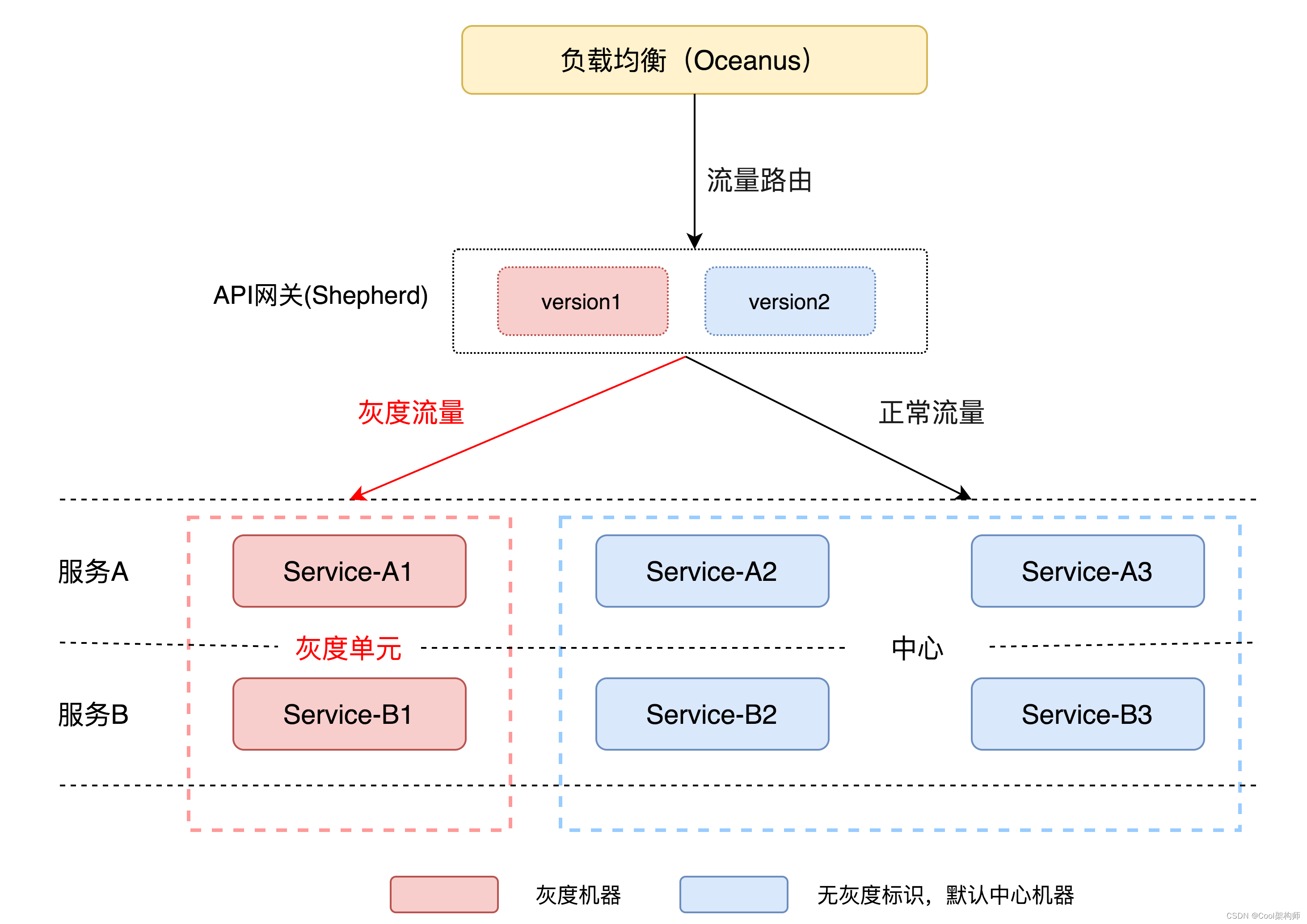
灰度API自身逻辑时,通过将流量分流到不同的API版本实现灰度能力;灰度下游服务时,通过给流量打标,分流到指定的下游灰度单元中。
灰度策略
支持丰富的灰度策略,可以按照比例数灰度,也可以按照特定条件灰度。
API网关提供360度的立体化监控,从业务指标、机器指标、JVM指标提供7x24小时的专业守护,如下表:
| 监控模块 | 主要功能 | |
|---|---|---|
| 1 | 统一监控Raptor | 实时上报请求调用信息、系统指标,负责应用层(JVM)监控、系统层(CPU、IO、网络)监控 |
| 2 | 链路追踪Mtrace | 负责全链路参数透传、全链路追踪监控 |
| 3 | 日志监控Logscan | 监控本地日志异常关键字:如5xx状态码、空指针异常等 |
| 4 | 远程日志中心 | API请求日志、Debug日志、组件日志等可上报远程日志中心 |
| 5 | 健康检查Scanner | 对网关节点进行心跳检测和API状态检测,及时发现异常节点和异常API |
有了全面的监控体系,自然少不了配套的告警机制,主要的告警能力包括:
| 告警类型 | 触发时机 | |
|---|---|---|
| 1 | 限流告警 | API请求达到限流规则阈值触发限流告警 |
| 2 | 请求失败告警 | 鉴权失败、请求超时、后端服务异常等触发请求失败告警 |
| 3 | 组件异常告警 | 自定义组件处理耗时长、失败率高告警 |
| 4 | API异常告警 | API发布失败、API检查异常时触发API异常告警 |
| 5 | 健康检查失败告警 | API心跳检查失败、网关节点不通时触发健康检查失败告警 |
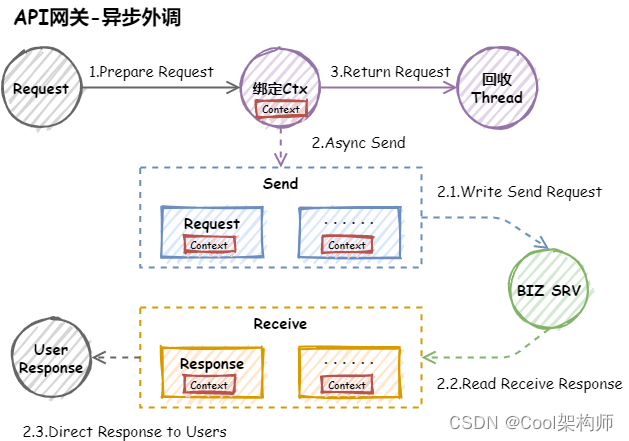
基于Netty实现异步外调主要有两种方式可以实现:
方式一需要独立维护一个全局映射表,同时需要考虑请求超时和丢失的情况,否则会出现内存不断增长问题。
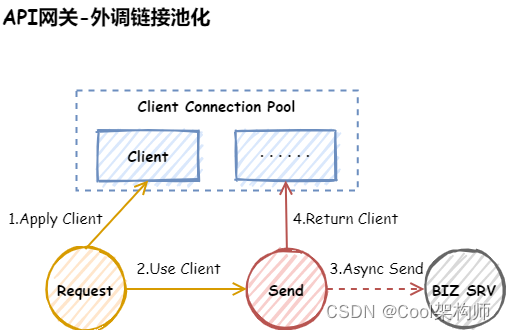
使用Netty实现API网关外调微服务时,因建立连接需要极度消耗资源,所以需要考虑将外调的链接进行池化管理,设计时需要注意以下几点:
http的链接是独占的,所以在释放的时候要特别小心,一定要等服务端响应完了才能释放,还有就是链接关闭的处理也要小心,总结如下几点:
Connection:close
空闲超时,关闭链接
读超时关闭链接
写超时,关闭链接
Fin,Reset
写超时:writeAndFlush包含Netty的encode时间和从队列里把请求发出去即flush的时间。因此后端超时开始需要在真正flush成功后开始计时,这样才最接近服务端超时时间(还有网络往返时间和内核协议栈处理时间)
针对高并发系统,频繁创建对象不仅有分配内存开销,还对gc会造成压力。因此在实现时,会对频繁使用的对象(如线程池的任务task,StringBuffer等)进行重写,减少频繁的申请内存的开销。
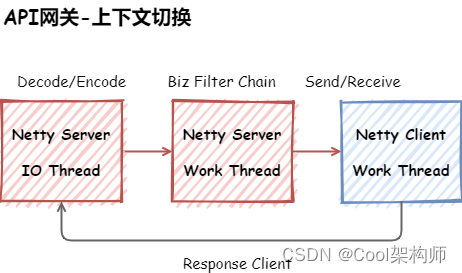
整个网关没有涉及到IO操作,但在IO编解码和业务逻辑都用了异步,是有两个原因
在突发的情况下,但是我们在push线程时,支持用Netty的IO线程替代,这里做的工作比较少,这里由异步修改为同步后(通过修改配置调整),CPU的上下文切换减少20%,进而提高了整体的吞吐量,就是不能为了异步而异步,Zuul2的设计类似。
协议层
应用层

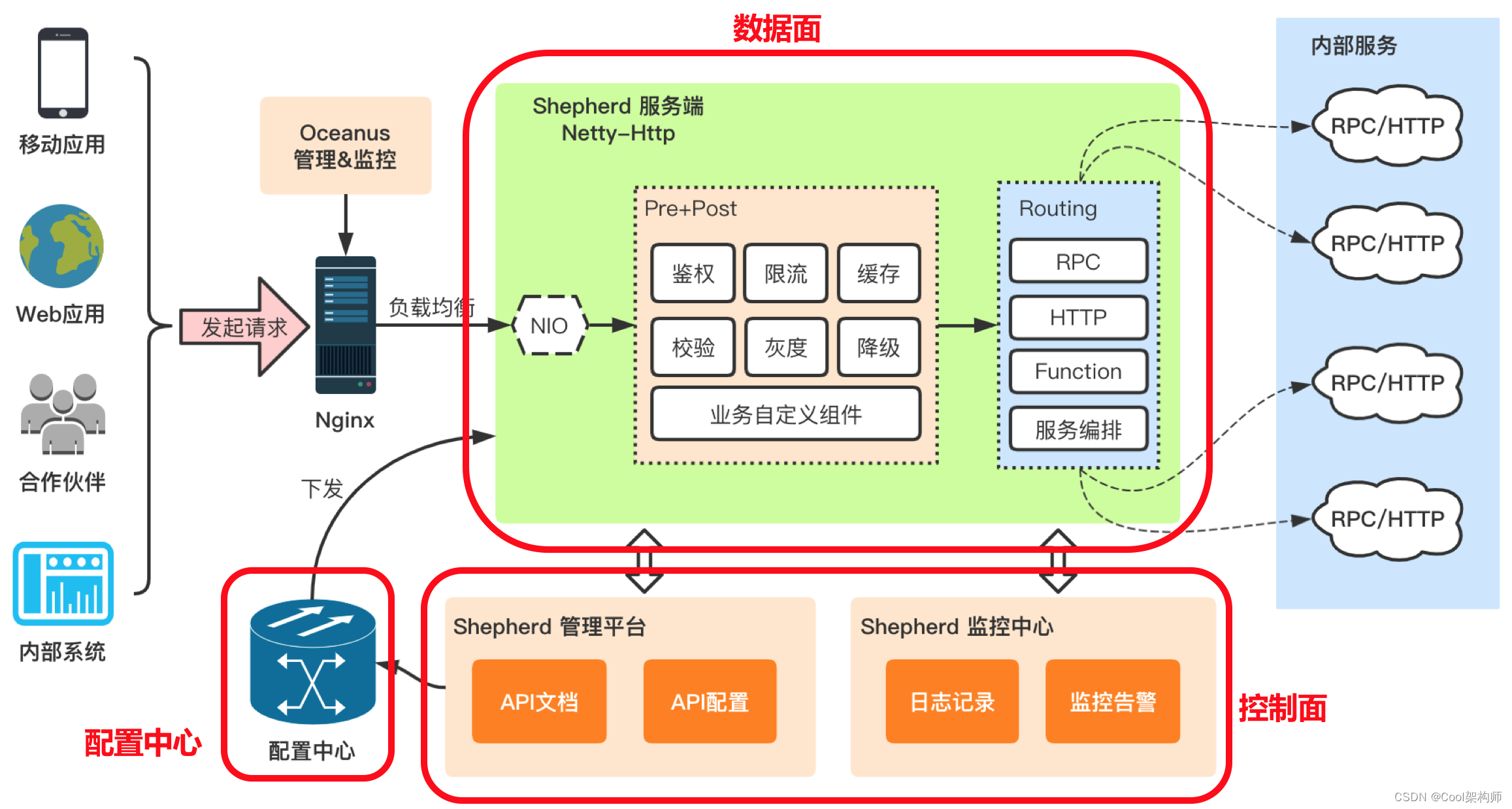
访问地址:https://github.com/Kong/kong
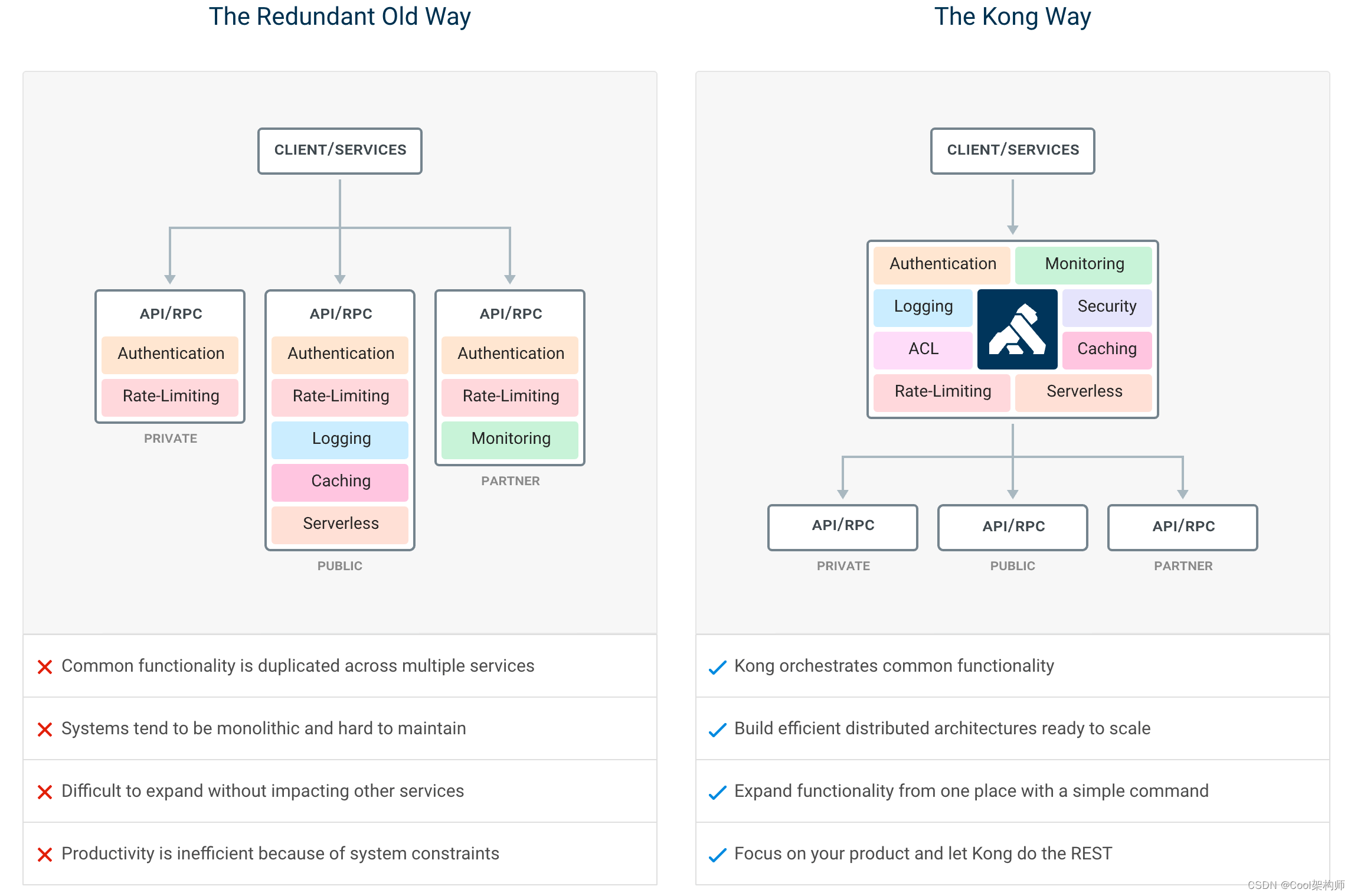
访问地址:https://github.com/Dromara/soul

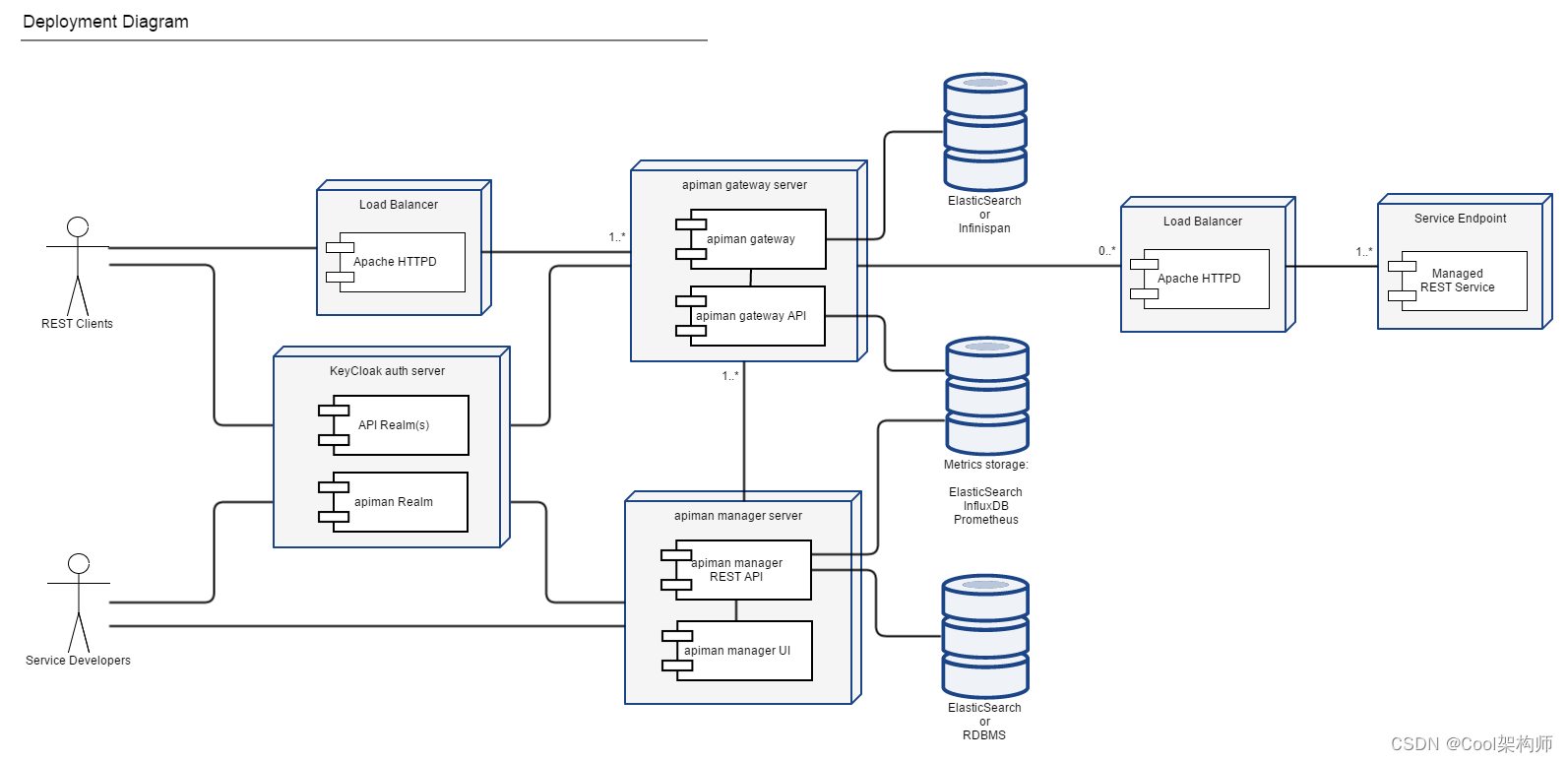
访问地址:https://apiman.gitbooks.io/apiman-user-guide/user-guide/gateway/policies.html
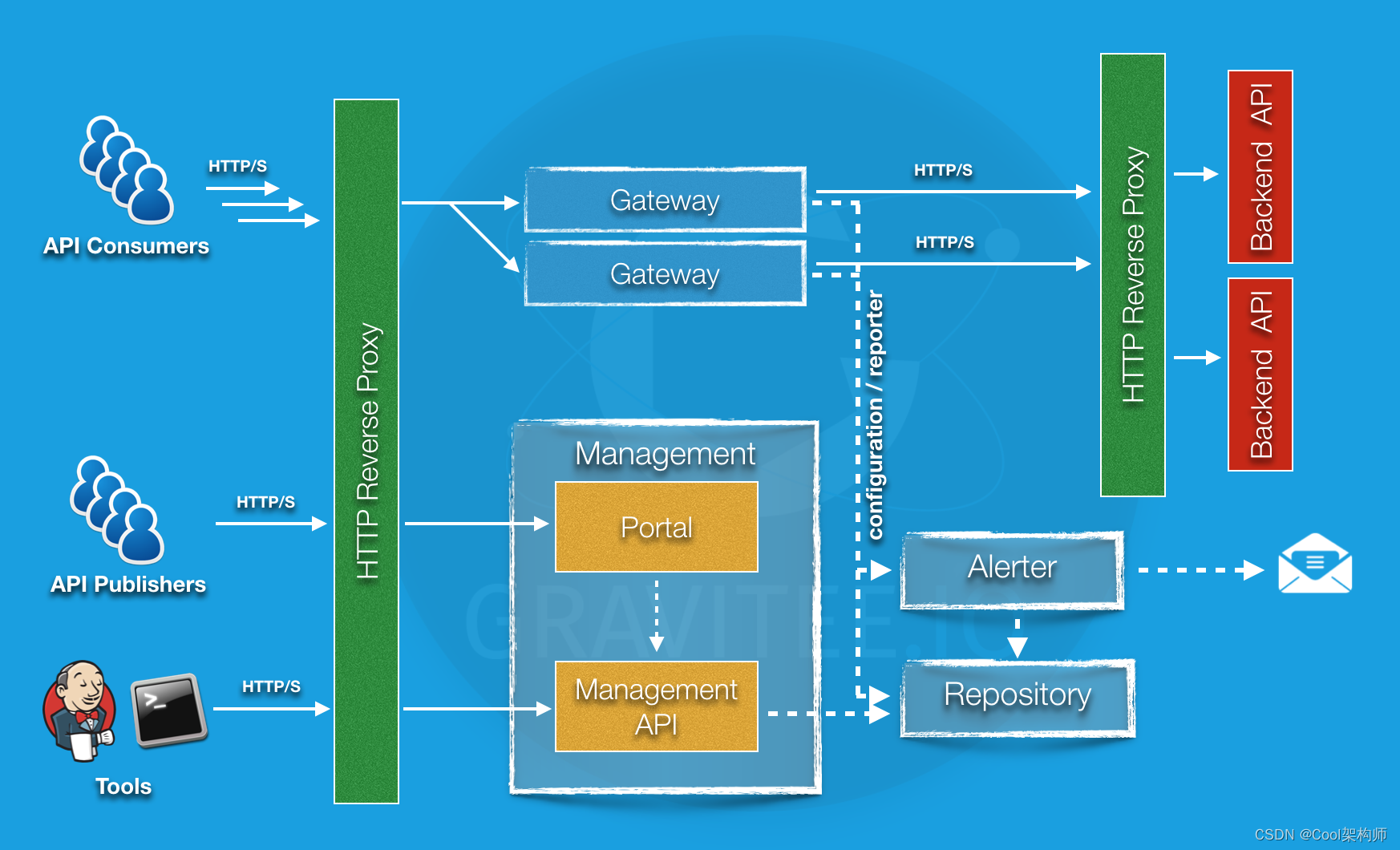
访问地址:https://docs.gravitee.io/apim_policies_latency.html
访问地址:https://tyk.io/docs
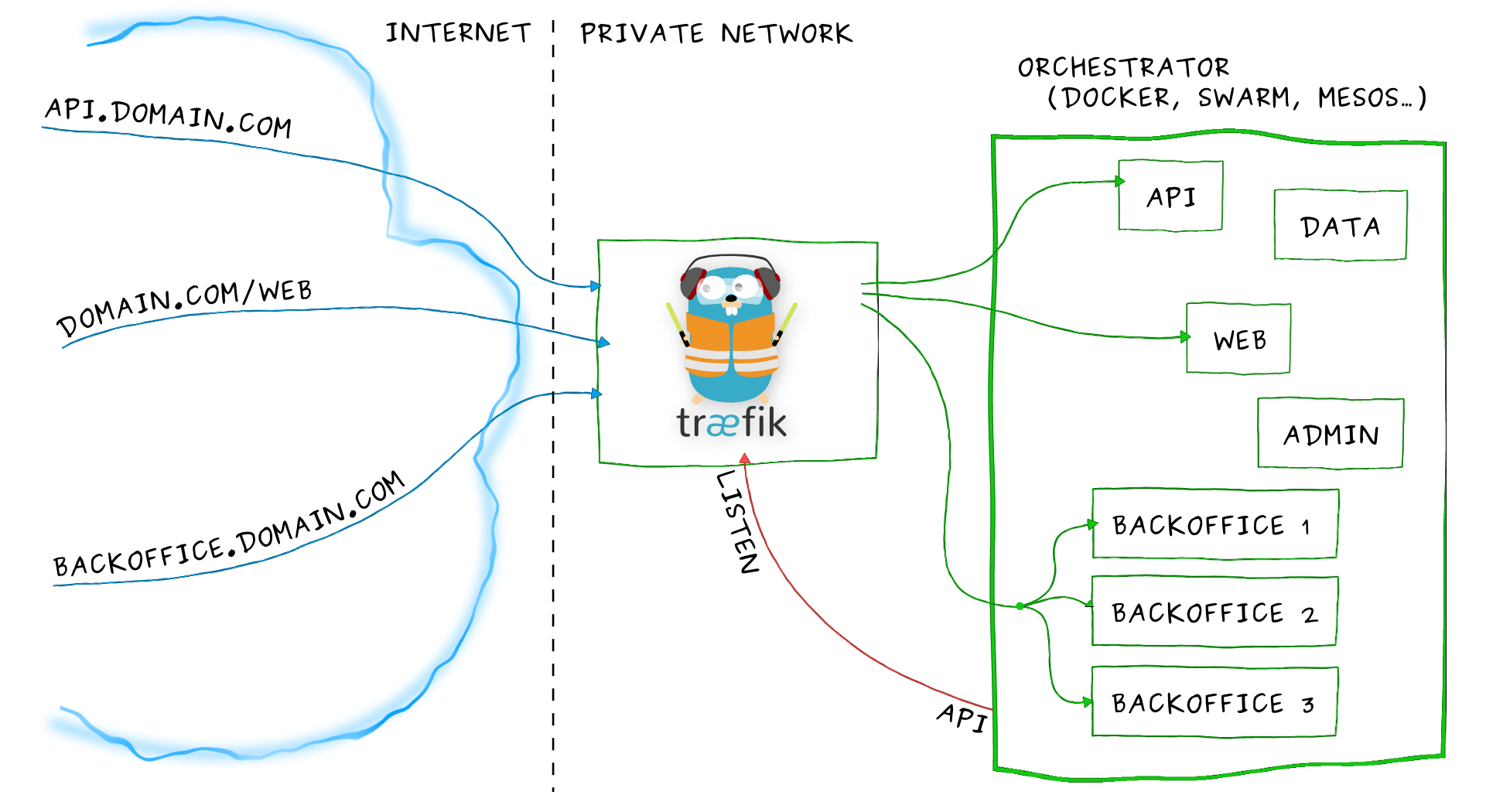
访问地址:https://traefik.cn
Træfɪk 是一个为了让部署微服务更加便捷而诞生的现代HTTP反向代理、负载均衡工具。 它支持多种后台 (Docker, Swarm, Kubernetes, Marathon, Mesos, Consul, Etcd, Zookeeper, BoltDB, Rest API, file…) 来自动化、动态的应用它的配置文件设置。
功能特性
访问地址:http://www.xbgateway.com
小豹API网关(企业级API网关),统一解决:认证、鉴权、安全、流量管控、缓存、服务路由,协议转换、服务编排、熔断、灰度发布、监控报警等。
我需要使用ActiveMerchant库在我们的一个Rails应用程序中设置支付解决方案。尽管这个问题非常主观,但人们对主要网关(BrainTree、Authorize.net等)的体验如何?它必须:处理定期付款。有能力记入个人帐户。能够取消付款。有办法存储用户的付款详细信息(例如Authotize.netsCIM)。干杯 最佳答案 ActiveMerchant很棒,但在过去一年左右的时间里,我在使用它时发现了一些问题。首先,虽然某些网关可能会得到“支持”——但并非所有功能都包含在内。查看功能矩阵以确保完全支持您选择的网关-http
我是一名决定学习Ruby和RubyonRails的ASP.NETMVC开发人员。我已经有所了解并在RoR上创建了一个网站。在ASP.NETMVC上开发,我一直使用三层架构:数据层、业务层和UI(或表示)层。尝试在RubyonRails应用程序中使用这种方法,我发现没有关于它的信息(或者也许我只是找不到它?)。也许有人可以建议我如何在RubyonRails上创建或使用三层架构?附言我使用ruby1.9.3和RubyonRails3.2.3。 最佳答案 我建议在制作RoR应用程序时遵循RubyonRails(RoR)风格。Rails
我想使用两种不同的protect_from_forgery策略构建一个Rails应用程序:一种用于Web应用程序,一种用于API。在我的应用程序Controller中,我有这行代码:protect_from_forgerywith::exception为了防止CSRF攻击,它工作得很好。在我的API命名空间中,我创建了一个继承self的应用程序Controller的api_controller,它是API命名空间中所有其他Controller的父类,我将上面的代码更改为:protect_from_forgery:null_session.遗憾的是,我在尝试发出POST请求时遇到错误:“
我尝试用Ruby设计一个基于Web的应用程序。我开发了一个简单的核心应用程序,在没有框架和数据库的情况下在六边形架构中实现DCI范例。核心六边形中有小六边形和网络,数据库,日志等适配器。每个六边形都在没有数据库和框架的情况下自行运行。在这种方法中,我如何提供与数据库模型和实体类的关系作为独立于数据库的关系。我想在将来将框架从Rails更改为Sinatra或数据库。事实上,我如何在这个核心Hexagon中实现完全隔离的rails和mongodb的数据库适配器或框架适配器。有什么想法吗? 最佳答案 ROM呢?(Ruby对象映射器)。还有
HTTP缓存是指浏览器或者代理服务器将已经请求过的资源保存到本地,以便下次请求时能够直接从缓存中获取资源,从而减少网络请求次数,提高网页的加载速度和用户体验。缓存分为强缓存和协商缓存两种模式。一.强缓存强缓存是指浏览器直接从本地缓存中获取资源,而不需要向web服务器发出网络请求。这是因为浏览器在第一次请求资源时,服务器会在响应头中添加相关缓存的响应头,以表明该资源的缓存策略。常见的强缓存响应头如下所述:Cache-ControlCache-Control响应头是用于控制强制缓存和协商缓存的缓存策略。该响应头中的指令如下:max-age:指定该资源在本地缓存的最长有效时间,以秒为单位。例如:Ca
“架设一个亿级高并发系统,是多数程序员、架构师的工作目标。许多的技术从业人员甚至有时会降薪去寻找这样的机会。但并不是所有人都有机会主导,甚至参与这样一个系统。今天我们用12306火车票购票这样一个业务场景来做DDD领域建模。”开篇要实现软件设计、软件开发在一个统一的思想、统一的节奏下进行,就应该有一个轻量级的框架对开发过程与代码编写做一定的约束。虽然DDD是一个软件开发的方法,而不是具体的技术或框架,但拥有一个轻量级的框架仍然是必要的,为了开发一个支持DDD的框架,首先需要理解DDD的基本概念和核心的组件。一.什么是领域驱动设计(DDD)首先要知道DDD是一种开发理念,核心是维护一个反应领域概
我正在开发一个将XML发布到某些网络服务的小型应用程序。这是使用Net::HTTP::Post::Post完成的。但是,服务提供商建议使用重新连接。类似于:第一个请求失败->2秒后重试第二个请求失败->5秒后重试第三次请求失败->10秒后重试...这样做的好方法是什么?简单地在循环中运行以下代码,捕获异常并在一定时间后再次运行?或者还有其他聪明的方法吗?也许Net包甚至有一些我不知道的内置功能?url=URI.parse("http://some.host")request=Net::HTTP::Post.new(url.path)request.body=xmlrequest.con
我有这个原始文本:________________________________________________________________________________________________________________________________PosCarCompetitor/TeamDriverVehicleCapCLLapsRace.TimeFastest...Lap16JasonClementsJasonClementsBMWM33200109:48.571030:57.3228*242DavidSkillenderDavidSkillenderHo
我在当前项目中使用由Oracle数据库和memcached支持的RubyonRails。有一个非常常用的功能,它依赖于单个数据库View作为数据源,并且该数据源内部有其他数据库View和表。这是一个虚拟数据库View,能够从一个地方访问所有内容,而不是物化数据库View。大多数情况下,如果用户正在使用他们希望更新的功能,那么让数据保持最新很重要。从这个View获取数据时,我将安全表内部连接到View(安全表不是View本身的一部分),其中包含一些我们用来在更细粒度级别上控制数据访问的字段。例如,安全表有user_id,prop_1,prop_2列,其中prop_1,prop_2是数据库
现在已经为此奋斗了一段时间,不确定为什么它不起作用。要点是希望将Devise与LDAP结合使用。除了身份验证外,我不需要做任何事情,所以除了自定义策略外,我不需要使用任何东西。我根据https://github.com/plataformatec/devise/wiki/How-To:-Authenticate-via-LDAP创建了一个据我所知,一切都应该正常工作,除了每当我尝试运行服务器(或rake路由)时,我得到一个NameErrorlib/devise/models.rb:88:in`const_get':uninitializedconstantDevise::Models: