此项目是跟随狂神ES课程入门所做的SpringBoot+ES+Vue实战项目,在视频的基础上,已实现前后端分离。功能比较简单,实现的基本的爬虫+储存+搜索+高亮
此项目涉及以下功能
运行环境
前期准备
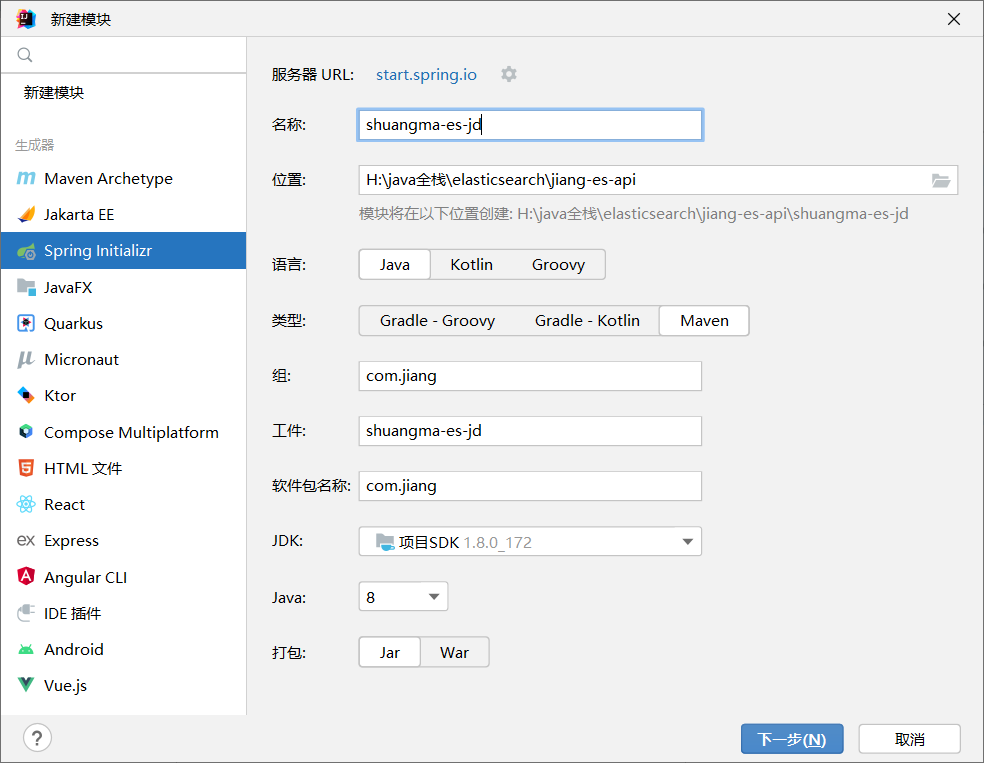
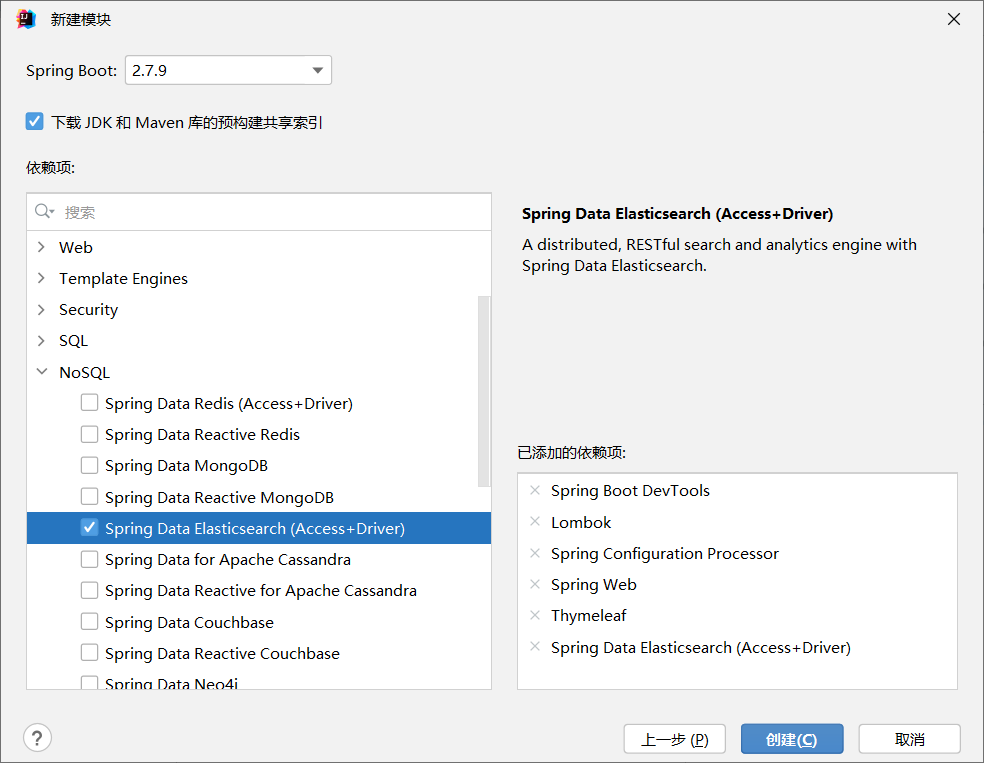
<properties>
<java.version>1.8</java.version>
<!--自定义版本和本地版本一致-->
<elaticsearch.version>7.6.1</elaticsearch.version>
</properties> <dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.23</version>
</dependency>server.port=9090
# 关闭thymeleaf缓存
spring.thymeleaf.cache=false
这里直接去我的gitee下载
@Controller
public class IndexController {
@GetMapping({"/", "/index"})
public String index() {
return "index";
}
}
爬取数据: (获取请求返回的页面信息,筛选出我们想要的数据就可以了! )
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>@Component
public class HtmlParseUtil {
public static void main(String[] args) throws IOException {
String url = "https://search.jd.com/Search?keyword=java";
Document document = Jsoup.parse(new URL(url), 30000);
Element element = document.getElementById("J_goodsList");
System.out.println(element.html());
}
}
public static void main(String[] args) throws IOException {
String url = "https://search.jd.com/Search?keyword=java";
Document document = Jsoup.parse(new URL(url), 30000);
Element element = document.getElementById("J_goodsList");
Elements elements = element.getElementsByTag("li");
for (Element el : elements) {
//关于这种图片特别多的网站,所有的图片都是延迟加载的
String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
System.out.println("=====================");
System.out.println(img);
System.out.println(price);
System.out.println(title);
}
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Content {
private String title;
private String img;
private String price;
}@Component
public class HtmlParseUtil {
public List<Content> parseJD(String keywords) throws Exception {
//获取请求
String url = "https://search.jd.com/Search?keyword=" + keywords;
//解析网页。(Jsoup返回Document就是浏览器Document对象)
Document document = Jsoup.parse(new URL(url), 30000);
//所有你在js中可以使用的方法,这里都能用
Element element = document.getElementById("J_goodsList");
//获取所有的li元素
Elements elements = element.getElementsByTag("li");
ArrayList<Content> goodsList = new ArrayList<>();
//获取元素中的内容,这里el 就是每一个li标签了
for (Element el : elements) {
//关于这种图片特别多的网站,所有的图片都是延迟加载的
String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
Content content = new Content();
content.setTitle(title);
content.setImg(img);
content.setPrice(price);
goodsList.add(content);
}
return goodsList;
}
}
public static void main(String[] args) throws Exception {
new HtmlParseUtil().parseJD("java").forEach(System.out::println);
}
解析数据放入到es索引中
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("127.0.0.1", 9200, "http")
)
);
return client;
}
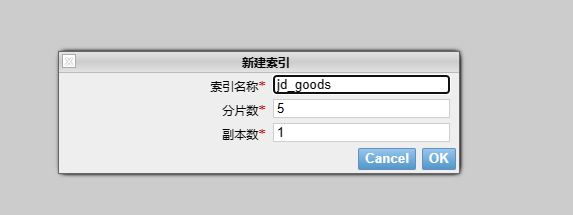
}
// 业务编写
@Service
public class ContentService {
@Autowired
RestHighLevelClient restHighLevelClient;
//1、解析数据放入 es 索引中
public boolean parseContent(String keyword) throws Exception {
List<Content> contents = new HtmlParseUtil().parseJD(keyword);
// 把查询到的数据放入es 中
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("2m");
for (int i = 0; i < contents.size(); i++) {
bulkRequest.add(
new IndexRequest("jd_goods")
.source(JSON.toJSONString(contents.get(i)), XContentType.JSON));
}
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
return !bulk.hasFailures();
}
}// 请求编写
@RestController
public class ContentController {
@Autowired
private ContentService contentService;
@GetMapping("/parse/{keyword}")
public boolean parse(@PathVariable("keyword")String keyword) throws Exception {
return contentService.parseContent(keyword);
}
}网页是没有数据的
es-head也没有数据



这里解析需要点时间,可能后面的内容没有加载出来,稍等一下,两分钟后刷新一下网页就可以如图所示
获取es中的数据实现搜索功能
//2、获取这些数据实现搜索功能
public List<Map<String,Object>> searchPage(String keyword, int pageNo, int pageSize) throws IOException {
if(pageNo<=1){
pageNo = 1;
}
// 条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分页
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
//精准匹配
TermQueryBuilder title = QueryBuilders.termQuery("title", keyword);
sourceBuilder.query(title);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
ArrayList<Map<String,Object>> list = new ArrayList<>();
for (SearchHit documentFields: search.getHits().getHits()) {
list.add(documentFields.getSourceAsMap());
}
return list;
} @GetMapping("/search/{keyword}/{pageNo}/{pageSize}")
public List<Map<String,Object>> search(@PathVariable("keyword") String keyword,
@PathVariable("pageNo") int pageNo,
@PathVariable("pageSize") int pageSize) throws IOException {
return contentService.searchPage(keyword,pageNo,pageSize);
}
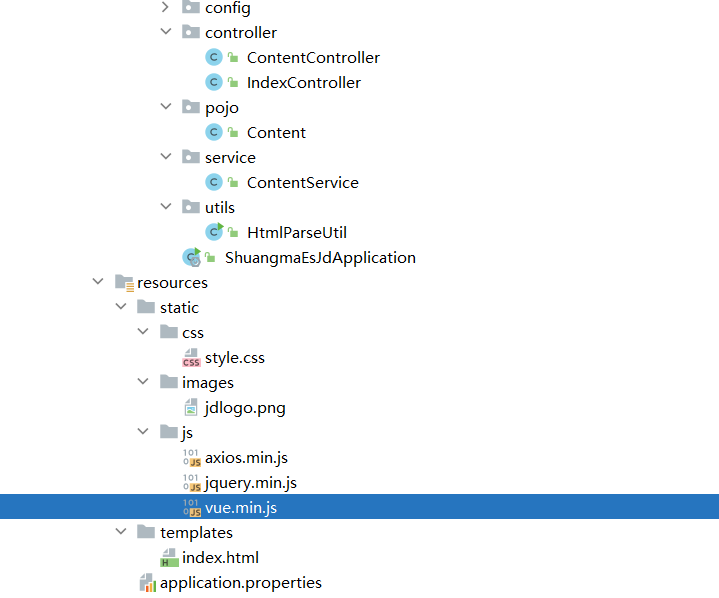
导入axios.min.js、vue.min.js(这两个资源在这里就不发送了,去官网下载或者查看我开始说的gitee开源项目下载)
页面代码
资源放入的结构
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="utf-8"/>
<title>狂神说Java-ES仿京东实战</title>
<link rel="stylesheet" th:href="@{/css/style.css}"/>
</head>
<body class="pg">
<div class="page" id="app">
<div id="mallPage" class=" mallist tmall- page-not-market ">
<!-- 头部搜索 -->
<div id="header" class=" header-list-app">
<div class="headerLayout">
<div class="headerCon ">
<!-- Logo-->
<h1 id="mallLogo">
<img th:src="@{/images/jdlogo.png}" alt="">
</h1>
<div class="header-extra">
<!--搜索-->
<div id="mallSearch" class="mall-search">
<form name="searchTop" class="mallSearch-form clearfix">
<fieldset>
<legend>天猫搜索</legend>
<div class="mallSearch-input clearfix">
<div class="s-combobox" id="s-combobox-685">
<div class="s-combobox-input-wrap">
<input v-model="keyword" type="text" autocomplete="off" value="dd" id="mq"
class="s-combobox-input" aria-haspopup="true">
</div>
</div>
<button @click.prevent="searchPage" type="submit" id="searchbtn">搜索</button>
</div>
</fieldset>
</form>
<ul class="relKeyTop">
<li><a>狂神说Java</a></li>
<li><a>狂神说前端</a></li>
<li><a>狂神说Linux</a></li>
<li><a>狂神说大数据</a></li>
<li><a>狂神聊理财</a></li>
</ul>
</div>
</div>
</div>
</div>
</div>
<!-- 商品详情页面 -->
<div id="content">
<div class="main">
<!-- 品牌分类 -->
<form class="navAttrsForm">
<div class="attrs j_NavAttrs" style="display:block">
<div class="brandAttr j_nav_brand">
<div class="j_Brand attr">
<div class="attrKey">
品牌
</div>
<div class="attrValues">
<ul class="av-collapse row-2">
<li><a href="#"> 狂神说 </a></li>
<li><a href="#"> Java </a></li>
</ul>
</div>
</div>
</div>
</div>
</form>
<!-- 排序规则 -->
<div class="filter clearfix">
<a class="fSort fSort-cur">综合<i class="f-ico-arrow-d"></i></a>
<a class="fSort">人气<i class="f-ico-arrow-d"></i></a>
<a class="fSort">新品<i class="f-ico-arrow-d"></i></a>
<a class="fSort">销量<i class="f-ico-arrow-d"></i></a>
<a class="fSort">价格<i class="f-ico-triangle-mt"></i><i class="f-ico-triangle-mb"></i></a>
</div>
<!-- 商品详情 -->
<div class="view grid-nosku">
<div class="product" v-for="item in results">
<div class="product-iWrap">
<!--商品封面-->
<div class="productImg-wrap">
<a class="productImg">
<img :src="item.img">
</a>
</div>
<!--价格-->
<p class="productPrice">
<em>{{item.price}}</em>
</p>
<!--标题-->
<p class="productTitle">
<a >{{item.title}}</a>
</p>
<!-- 店铺名 -->
<div class="productShop">
<span>店铺: 狂神说Java </span>
</div>
<!-- 成交信息 -->
<p class="productStatus">
<span>月成交<em>999笔</em></span>
<span>评价 <a>3</a></span>
</p>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
<script th:src="@{/js/vue.min.js}"></script>
<script th:src="@{/js/axios.min.js}"></script>
<script>
new Vue({
el:'#app',
data:{
keyword:'', //搜索关键字
results:[], //搜索结果
},
methods:{
searchPage(){
let keyword = this.keyword;
console.log(keyword)
axios.get("/search/"+keyword+"/1/10").then(res=>{
console.log(res)
this.results = res.data;//绑定数据
})
}
}
})
</script>
</body>
</html> //3、获取这些数据实现高亮功能
public List<Map<String,Object>> searchPageHighlightBuilder(String keyword,int pageNo,int pageSize) throws IOException {
if(pageNo<=1){
pageNo = 1;
}
// 条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分页
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
//精准匹配
TermQueryBuilder title = QueryBuilders.termQuery("title", keyword);
sourceBuilder.query(title);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.requireFieldMatch(false); //多个高亮显示!
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
sourceBuilder.highlighter(highlightBuilder);
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
ArrayList<Map<String,Object>> list = new ArrayList<>();
for (SearchHit hit: search.getHits().getHits()) {
//解析高亮的字段
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField title1 = highlightFields.get("title");
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
//解析高亮的字段,将原来的字段换位我们高亮的字段即可
if(title1 != null){
Text[] fragments = title1.fragments();
String n_title = "";
for (Text text : fragments) {
n_title += text;
}
sourceAsMap.put("title",n_title);//高亮字段替换掉原来的内容
}
list.add(sourceAsMap);
}
return list;
} @GetMapping("/search/{keyword}/{pageNo}/{pageSize}")
public List<Map<String,Object>> search(@PathVariable("keyword") String keyword,
@PathVariable("pageNo") int pageNo,
@PathVariable("pageSize") int pageSize) throws IOException {
return contentService.searchPageHighlightBuilder(keyword,pageNo,pageSize);
}
<!--标题-->
<p class="productTitle">
<a v-html="item.title"></a>
</p>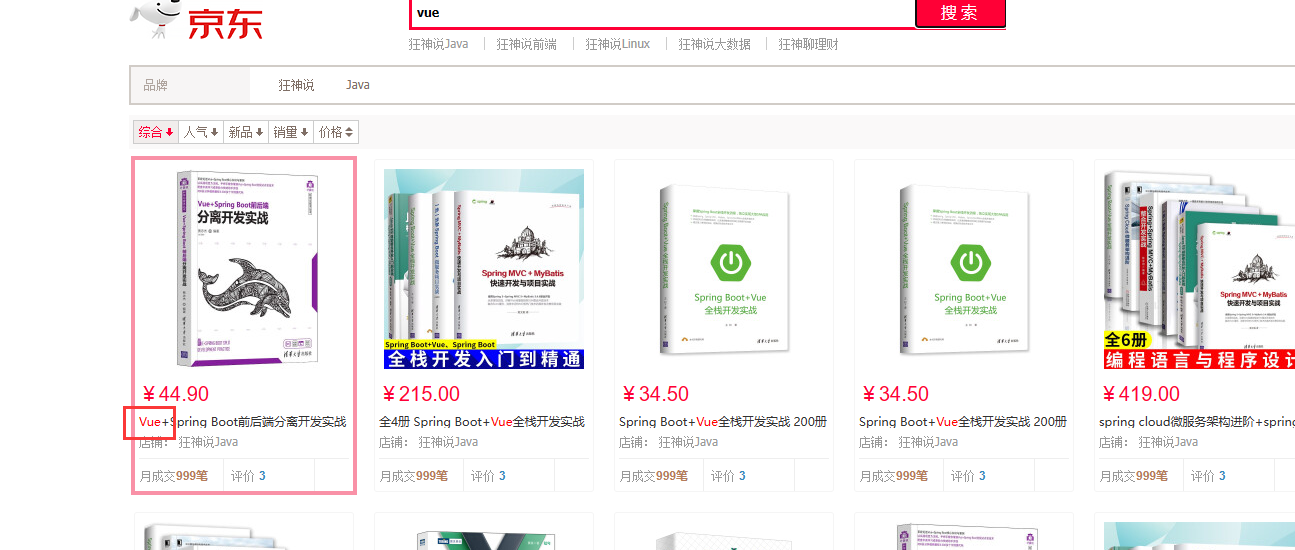
我使用Nokogiri(Rubygem)css搜索寻找某些在我的html里面。看起来Nokogiri的css搜索不喜欢正则表达式。我想切换到Nokogiri的xpath搜索,因为这似乎支持搜索字符串中的正则表达式。如何在xpath搜索中实现下面提到的(伪)css搜索?require'rubygems'require'nokogiri'value=Nokogiri::HTML.parse(ABBlaCD3"HTML_END#my_blockisgivenmy_bl="1"#my_eqcorrespondstothisregexmy_eq="\/[0-9]+\/"#FIXMEThefoll
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
寻找有用的ruby的好网站是什么? 最佳答案 AgileWebDevelopment列出插件(虽然不是rubygems,我不确定为什么),并允许人们对它们进行评级。RubyToolbox按类别列出gem并比较它们的受欢迎程度。Rubygems有一个搜索框。StackOverflow对最有用的rails插件和rubygems有疑问。 关于ruby-如何搜索有用的ruby,我们在StackOverflow上找到一个类似的问题: https://stacko
我有很多这样的文档:foo_1foo_2foo_3bar_1foo_4...我想通过获取foo_[X]的所有实例并将它们中的每一个替换为foo_[X+1]来转换它们。在这个例子中:foo_2foo_3foo_4bar_1foo_5...我可以用gsub和一个block来做到这一点吗?如果不是,最干净的方法是什么?我真的在寻找一个优雅的解决方案,因为我总是可以暴力破解它,但我觉得有一些正则表达式技巧值得学习。 最佳答案 我(完全)不懂Ruby,但类似这样的东西应该可以工作:"foo_1foo_2".gsub(/(foo_)(\d+)/
我读了"BingSearchAPI-QuickStart"但我不知道如何在Ruby中发出这个http请求(Weary)如何在Ruby中翻译“Stream_context_create()”?这是什么意思?"BingSearchAPI-QuickStart"我想使用RubySDK,但我发现那些已被弃用前(Rbing)https://github.com/mikedemers/rbing您知道Bing搜索API的最新包装器(仅限Web的结果)吗? 最佳答案 好吧,经过一个小时的挫折,我想出了一个办法来做到这一点。这段代码很糟糕,因为它是
给定一个元素和一个数组,Ruby#index方法返回元素在数组中的位置。我使用二进制搜索实现了我自己的索引方法,期望我的方法会优于内置方法。令我惊讶的是,内置的在实验中的运行速度大约是我的三倍。有Rubyist知道原因吗? 最佳答案 内置#indexisnotabinarysearch,这只是一个简单的迭代搜索。但是,它是用C而不是Ruby实现的,因此自然可以快几个数量级。 关于Ruby#index方法VS二进制搜索,我们在StackOverflow上找到一个类似的问题:
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
我有一个表,'jobs'和一个枚举字段'status'。status具有以下枚举集:enumstatus:[:draft,:active,:archived]使用ransack,我如何过滤表,比如说,所有事件记录? 最佳答案 你可以像这样在模型中声明自己的掠夺者:ransacker:status,formatter:proc{|v|statuses[v]}do|parent|parent.table[:status]end然后您可以使用默认的搜索语法_eq来检查相等性,如下所示:Model.ransack(status_eq:'ac
我一直在使用postgres关注railscast的全文搜索,但我不断收到以下错误#的未定义局部变量或方法“作用域”我关注了railscast确切地。我安装了所有正确的gem。(pg_search,pg)。这是我的代码文章Controller(我在这里也使用acts_as_taggable)defindex@articles=Article.text_search(params[:query]).page(params[:page]).per_page(3)ifparams[:tag]@articles=Article.tagged_with(params[:tag])else@art
我想使用部分字符串搜索数组,然后获取找到该字符串的索引。例如:a=["Thisisline1","Wehaveline2here","andfinallyline3","potato"]a.index("potato")#thisreturns3a.index("Wehave")#thisreturnsnil使用a.grep将返回完整的字符串,使用a.any?将返回正确的true/false语句,但都不会返回匹配的索引找到了,或者至少我不知道该怎么做。我正在编写一段代码,该代码读取文件、查找特定header,然后返回该header的索引,以便它可以将其用作future搜索的偏移量。如果