 Easy!SQL随手一写:
Easy!SQL随手一写:
 为避免全表扫描,给 city 字段加个索引,再explain验证:
为避免全表扫描,给 city 字段加个索引,再explain验证:
explain select city, name, age from citizen where city = '上海' order by name limit 1000;
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | citizen | NULL | ALL | city | NULL | NULL | NULL | 32 | 100.00 | Using where; Using filesort |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
1 row in set, 1 warning (0.00 sec)
Extra的 Using filesort 表示需要排序,MySQL会给每个线程分配一块内存(sort_buffer)用于排序。
那么MySQL底层到底是如何执行order by的呢?
首先看city索引:
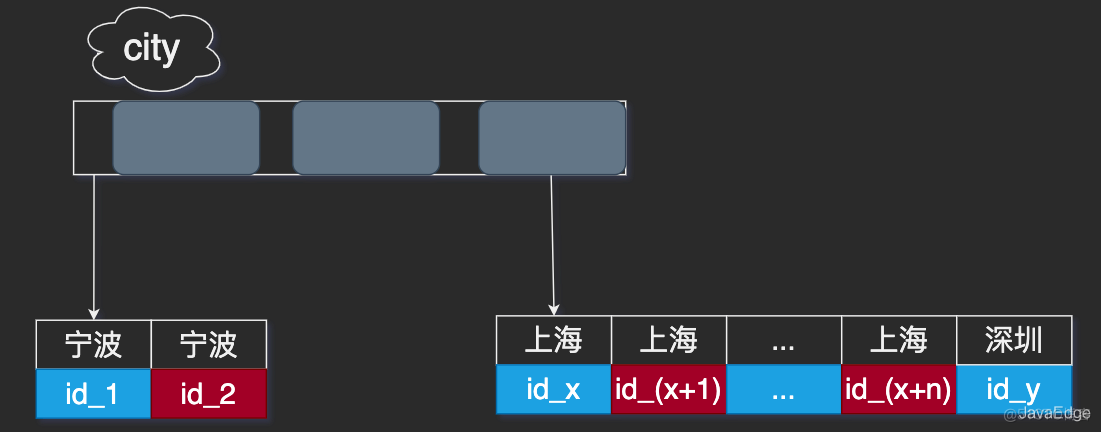 这里
这里 id_x ~ id_(x+n) 的数据都满足city=上海。
city, name, age三字段city找到第一个满足city=上海的主键id, 即id_xcity, name, age三个字段的值,存入sort_buffercity取下一个记录的主键idid_yname做快排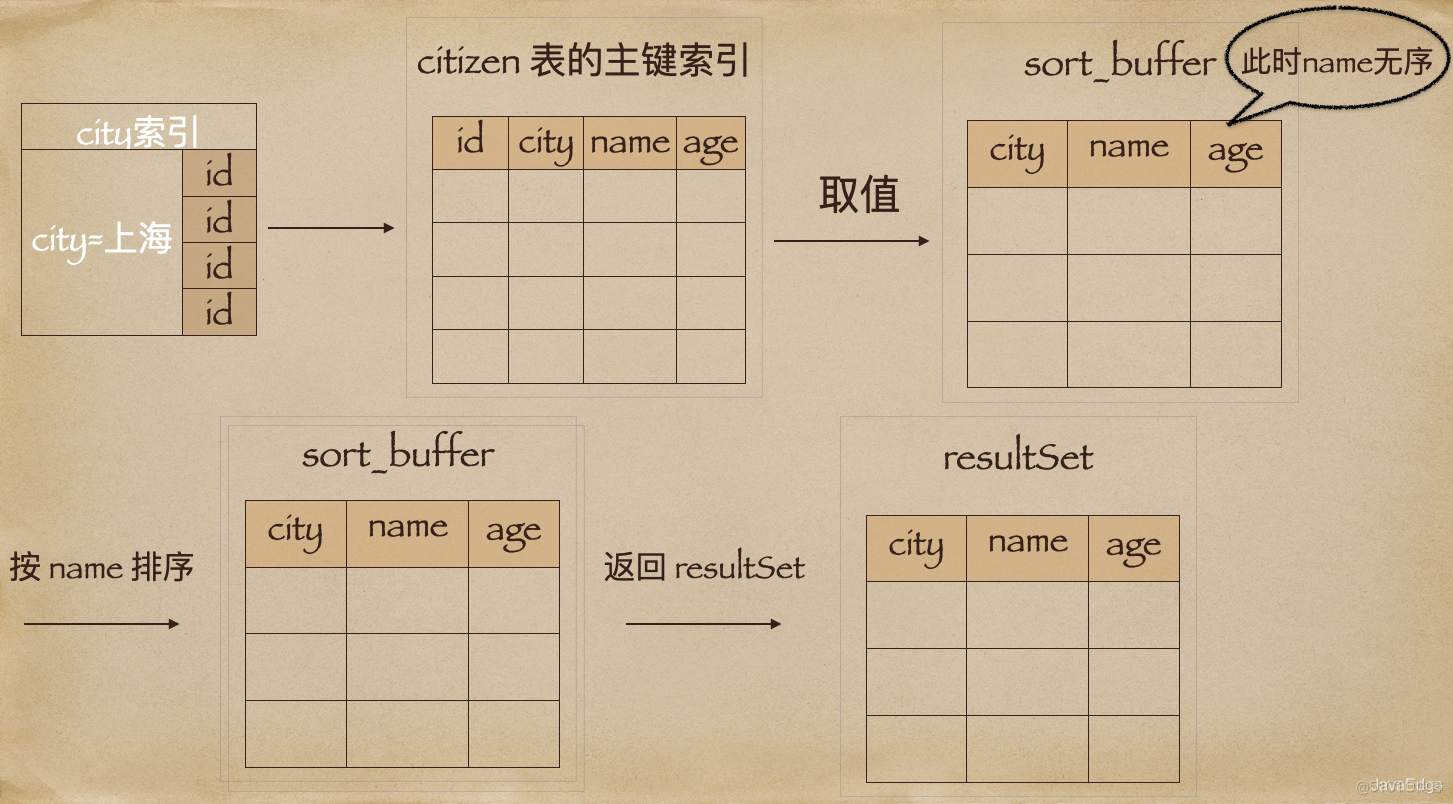 按name排序 这一操作可能:
按name排序 这一操作可能:
待排序数据量 < sort_buffer_size,就在内存中排序。order by语句何时会使用临时文件?
SET optimizer_trace='enabled=on';
/* 使用 @a 保存 Innodb_rows_read 的初始值 */
select VARIABLE_VALUE into @a
from performance_schema.session_status
where variable_name = 'Innodb_rows_read';
select city, name,age
from citizen
where city='上海'
order by name
limit 1000;
/* 查看 OPTIMIZER_TRACE 输出 */
SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G
/* 使用 @b 保存 Innodb_rows_read 的当前值 */
select VARIABLE_VALUE into @b
from performance_schema.session_status
where variable_name = 'Innodb_rows_read';
/* 计算 Innodb_rows_read 的差值 */
select @b-@a;
查看 OPTIMIZER_TRACE 结果中的 number_of_tmp_files 字段确认是否使用临时文件。
"filesort_execution": [
],
"filesort_summary": {
"rows": 4000
"examined_rows": 4000,
"number_of_tmp_files": 12,
"sort_buffer_size": 32664 ,
"sort_mode": "<sort_key, packed_additional_fields>"
select @b-@a 的结果4000,即整个执行过程只扫描了4000行。
为避免对结论造成干扰,我把internal_tmp_disk_storage_engine设置成MyISAM。否则,select @b-@a的结果会显示为4001。
因为查询OPTIMIZER_TRACE表时,需要用到临时表,而internal_tmp_disk_storage_engine的默认值是InnoDB。若使用InnoDB,把数据从临时表取出时,会让Innodb_rows_read的值加1。

 产品老大又开始发难,那你知道若MySQL认为排序的单行长度太大,它会咋样?
现在修改个参数,让MySQL采用另外一种算法。
产品老大又开始发难,那你知道若MySQL认为排序的单行长度太大,它会咋样?
现在修改个参数,让MySQL采用另外一种算法。
SET max_length_for_sort_data = 16;
city、name、age 三字段的定义总长度36,那你看我把max_length_for_sort_data设为16会咋样?
新的算法放入sort_buffer的字段,只有待排序列(name字段)和主键id。
但这时,排序的结果就因少了city和age字段值,不能直接返回了,整个执行流程变成如下:
sort_buffer,确定放入两个字段,即name和idcity找到第一个满足 city=上海 的主键id,即id_xid取出整行,取name、id这俩字段,存入sort_buffercity取下一个记录的主键idid_ysort_buffer数据按name排序 听到这里,感觉明白了一些:产品你别急,你看我画下这个
听到这里,感觉明白了一些:产品你别急,你看我画下这个rowid排序执行过程的示意图,对不对?
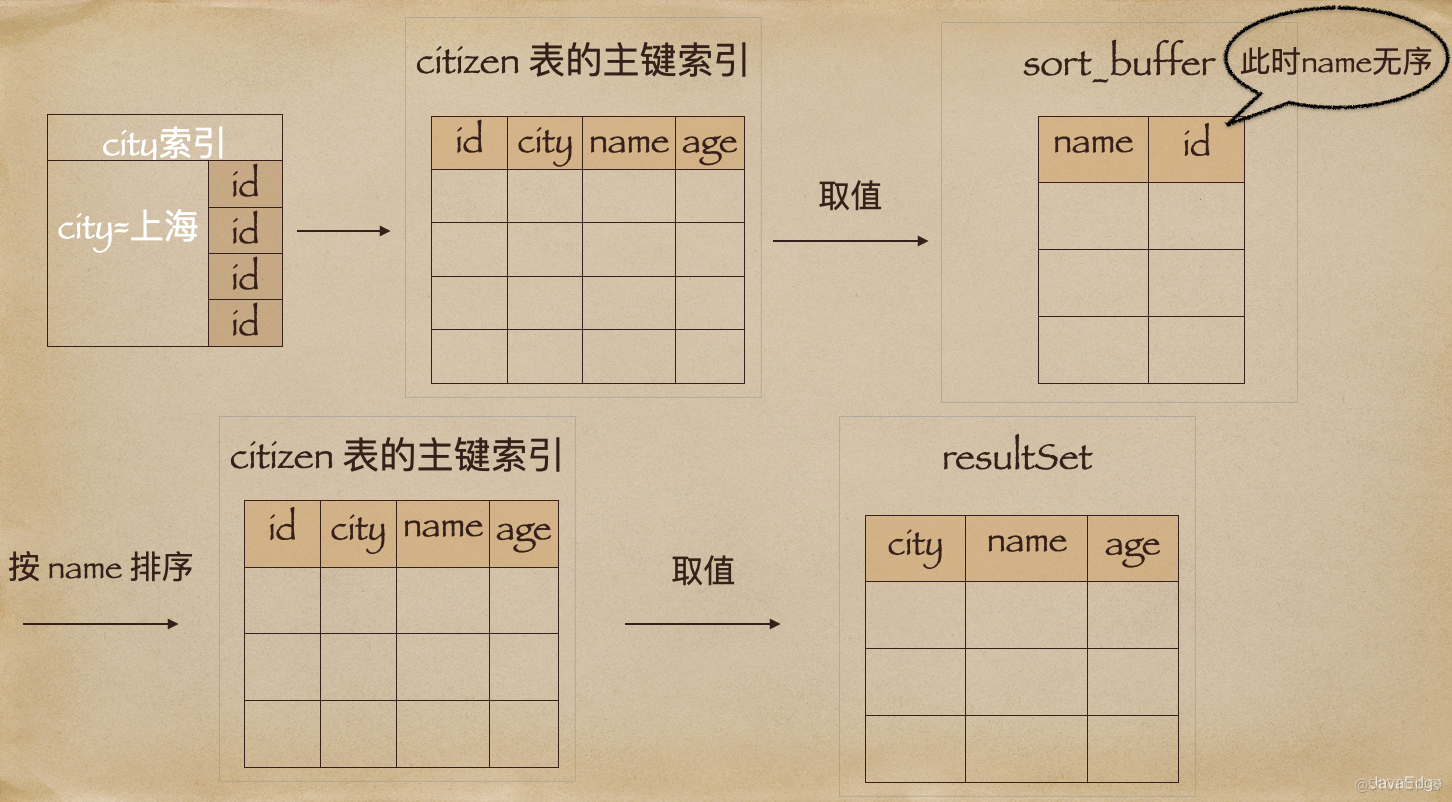 你看这个和你之前画的全字段排序示意图对比,其实就是多访问了一次表citizen的主键索引,即step7。
你看这个和你之前画的全字段排序示意图对比,其实就是多访问了一次表citizen的主键索引,即step7。
resultSet是个逻辑概念,实际上MySQL服务端从排序后的sort_buffer中依次取出id,然后到原表查到city、name和age这三字段的结果,无需在服务端再耗费内存存储结果,而是直接返回给client。这时查看rowid排序的OPTIMIZER_TRACE结果:
"filesort_execution": [
],
"filesort_summary": {
"rows": 4000
"examined_rows": 4000,
"number_of_tmp_files": 10,
"sort_buffer_size": 32728 ,
"sort_mode": "<sort_key, rowid>"
select @b-@a结果变成5000
因为这时除了排序过程,在排序完成后,还要根据id去原表取值。由于语句是limit 1000,因此会多读1000行。city,name联合索引:
alter table t add index citizen(city, name);
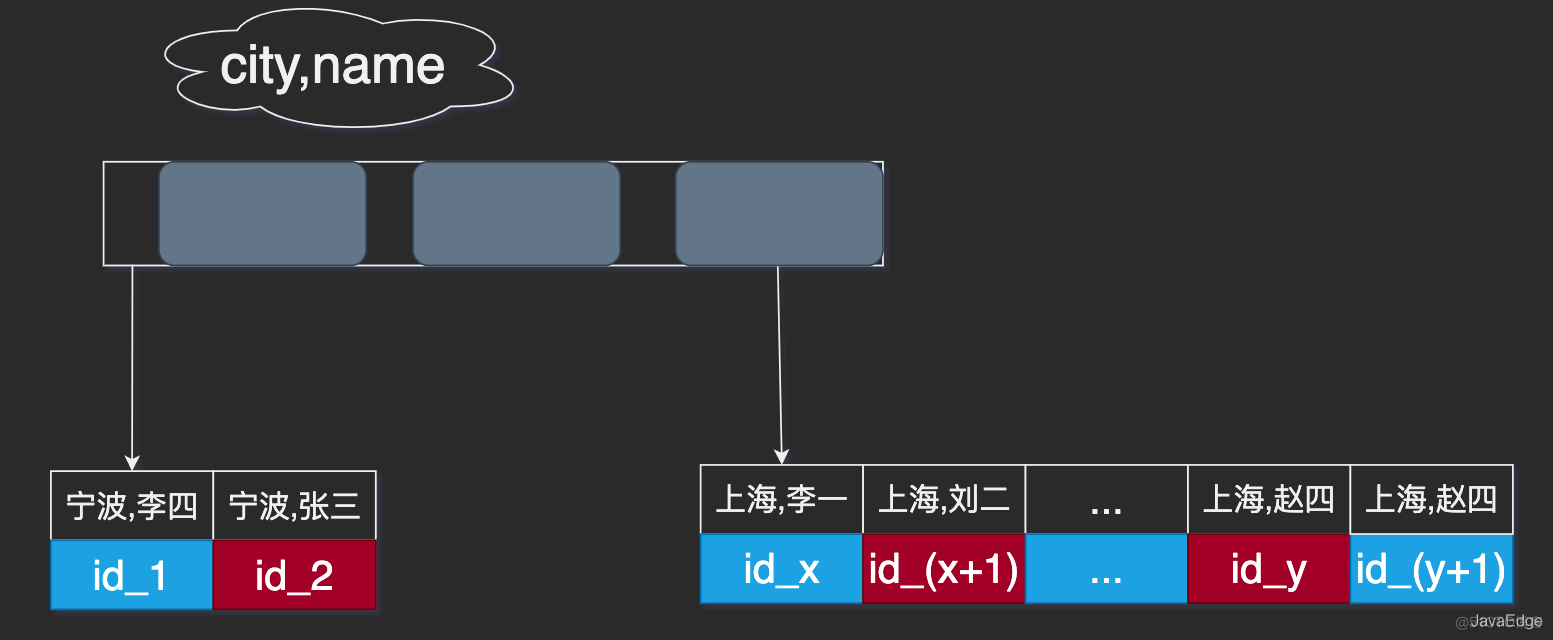 依然可以用树搜索定位到第一个满足city='上海’的记录,并且能确保接下来按顺序取“下一条记录”的遍历过程,只要city是上海,name值一定有序。
这样整个查询过程的流程就变成:
依然可以用树搜索定位到第一个满足city='上海’的记录,并且能确保接下来按顺序取“下一条记录”的遍历过程,只要city是上海,name值一定有序。
这样整个查询过程的流程就变成: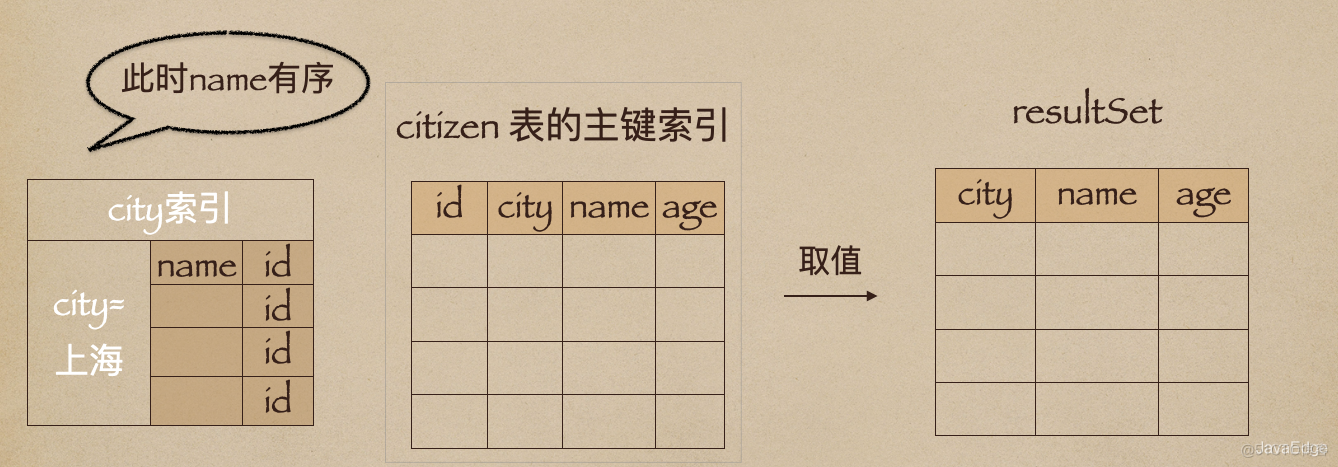
explain select city, name, age from citizen where city = '上海' order by name limit 1000;
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | citizen | NULL | ref | city,name | name | 51 | const | 4000 | 100.00 | Using index condition |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
1 row in set, 1 warning (0.00 sec)
可见Extra字段中没有Using filesort了,也就是不需要排序了。而且由于(city,name)这个联合索引本身有序,所以该查询也不用把4000行全都读一遍,只要找到满足条件的前1000条记录即可退出。在这个例子里,只需扫描1000次。
该语句的执行流程有没有可能进一步简化呢?
alter table t add index city_user_age(city, name, age);
这时,对于city字段的值相同的行来说,还是按照name字段的值递增排序的,此时的查询语句也就不再需要排序了。这样整个查询语句的执行流程就变成了:
(city,name,age) 联合索引,查询语句的执行流程
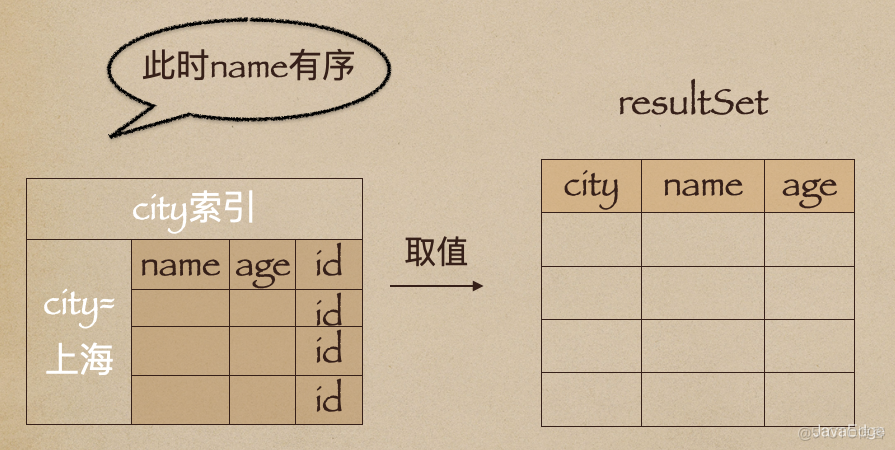
(city,name,age)联合索引查询语句的执行计划explain select city, name, age from citizen where city = '上海' order by name limit 1000;
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | citizen | NULL | ref | city,name,age | age | 51 | const | 4000 | 100.00 | Using where; Using index |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
1 row in set, 1 warning (0.00 sec)
Extra字段里面多了“Using index”,说明使用了覆盖索引,性能上会快很多。
但这并非说要为了每个查询能用上覆盖索引,就要把语句中涉及的字段都建上联合索引,毕竟索引也很占空间,而且修改新增都会导致索引改变,还是具体业务场景具体分析。
参考
- “order by”是怎么工作的?
- https://blog.csdn.net/Linuxhus/article/details/112672434?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242
- 天天写order by,你知道Mysql底层执行原理吗?
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
我有一大串格式化数据(例如JSON),我想使用Psychinruby同时保留格式转储到YAML。基本上,我希望JSON使用literalstyle出现在YAML中:---json:|{"page":1,"results":["item","another"],"total_pages":0}但是,当我使用YAML.dump时,它不使用文字样式。我得到这样的东西:---json:!"{\n\"page\":1,\n\"results\":[\n\"item\",\"another\"\n],\n\"total_pages\":0\n}\n"我如何告诉Psych以想要的样式转储标量?解