目录

🛰️博客主页:✈️努力学习的銮同学
🛰️欢迎关注:👍点赞🙌收藏✍️留言
🛰️系列专栏:💐【进阶】C语言学习
家人们更新不易,你们的👍点赞👍和👉关注👈真的对我真重要,各位路过的友友麻烦多多点赞关注,欢迎你们的私信提问,感谢你们的转发!
关注我,关注我,关注我,你们将会看到更多的优质内容!!!
🏡🏡本文重点 🏡🏡:
🚅 字符串处理函数 🚃 模拟库函数🚏🚏
期末考试将至,不知道各位小伙伴们都准备的怎么样了呢?在紧张的复习生活之余,也不要忘记了专业课的学习哟!前面三篇文章我们完整的将我们的指针技术进行了全面的升级,各位小伙伴们又向着大佬之路迈出了坚实的一步。
本文我门将进入到下一部分的学习中去。通过本课,我们将更加深刻的理解各种字符串函数的处理方式和使用方法,助你工作面试一臂之力!
我们在C语言的从程序代码编写中,对字符和字符串的处理相当频繁,但是我们还知道,C语言本身并没有字符串类型。而字符串通常放在【常量字符串】或者【字符数组】中。其中,字符串常量适用于那些对它不做修改的字符串函数。
知道了字符串在计算机中的储存原理之后,我们就正式开始介绍字符串的使用。
strlen 函数是大家的老朋友了,想必大家也都不陌生了。
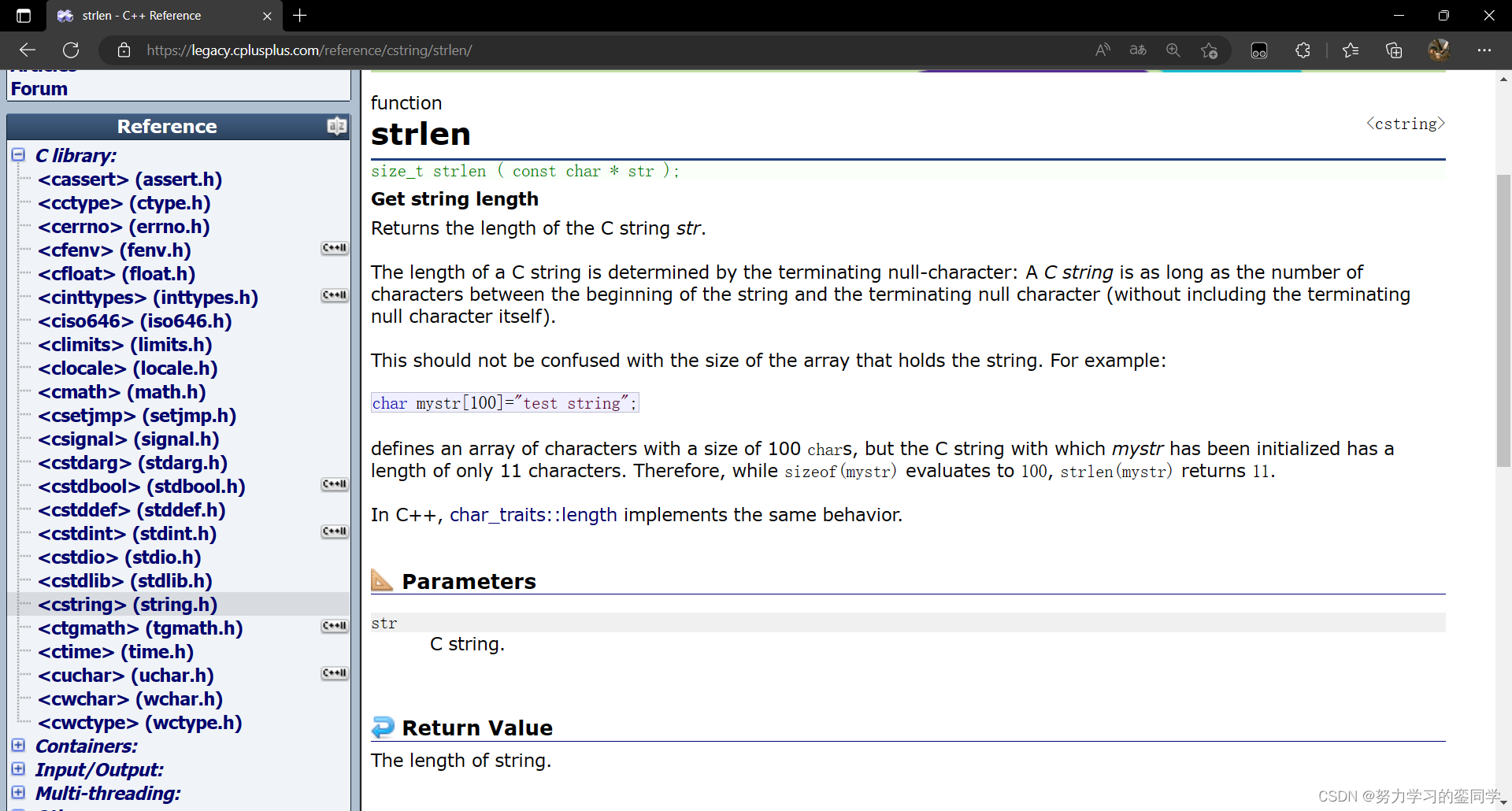
strlen 函数(string length)的作用是用于返回字符串中结束标识符 ' \0 ' 之前出现的的字符个数,因此,strlen函数所处理的字符串对象必须是以结束标识符 ' \0 ' 结尾的字符串。其返回值类型为 size_t 类型,该类型为无符号类型。
我们来看 strlen 函数的基本使用方式:
#include<stdio.h>
#include<string.h>
int main()
{
//两中可行的初始化方式:
char arr1[]="Hellow!";
char arr2[] = { 'H','e','l','l','o','w','!','\0' };
int ret1 = strlen(arr1);
int ret2 = strlen(arr2);
printf("The length of arr1 is %d\n", ret1);
printf("The length of arr2 is %d\n", ret2);
return 0;
}我们使用字符型数组将字符串储存起来,接着使用 strlen 函数计算字符串 " Hellow! " 中所有字符的数量(使用双引号初始化字符串时,编译器将会自动在最后添加上结束标识符),并可以使用使用一个整型变量接收 strlen 函数的返回值,进行打印。
并且我们还说到,strlen 函数的返回类型为无符号数,因此 strlen 函数不可以直接用来比较两个字符串的大小。例如:
#include<stdio.h>
#include<string.h>
int main()
{
const char* str1 = "abcdef";
const char* str2 = "bbb";
if (strlen(str2) - strlen(str1) > 0)
{
printf("str2 > str1\n");
}
else
{
printf("srt1 < str2\n");
}
return 0;
}我们可能会认为计算出的结果为 3 - 6 为 -3,结果会执行 else 语句。但事实上,因为 strlen 函数的返回类型为无符号类型,得出的结果也是无符号类型,于是原本第一位即符号位上的数字也将被作为数据的一部分,因而实际得出的结果为一个非常大的整数,执行了 if 语句。
于是如果我们想要使用 strlen 函数来判断字符串的大小,可以通过让它的返回值由无符号数变为有符号数即可,即强制类型转换来实现:
#include<stdio.h>
#include<string.h>
int main()
{
const char* str1 = "abcdef";
const char* str2 = "bbb";
if ((int)strlen(str2) - (int)strlen(str1) > 0)
{
printf("str2 > str1\n");
}
else
{
printf("srt1 < str2\n");
}
return 0;
}在之前的学习中,strcpy 函数也是我们经常使用的字符串处理函数之一。
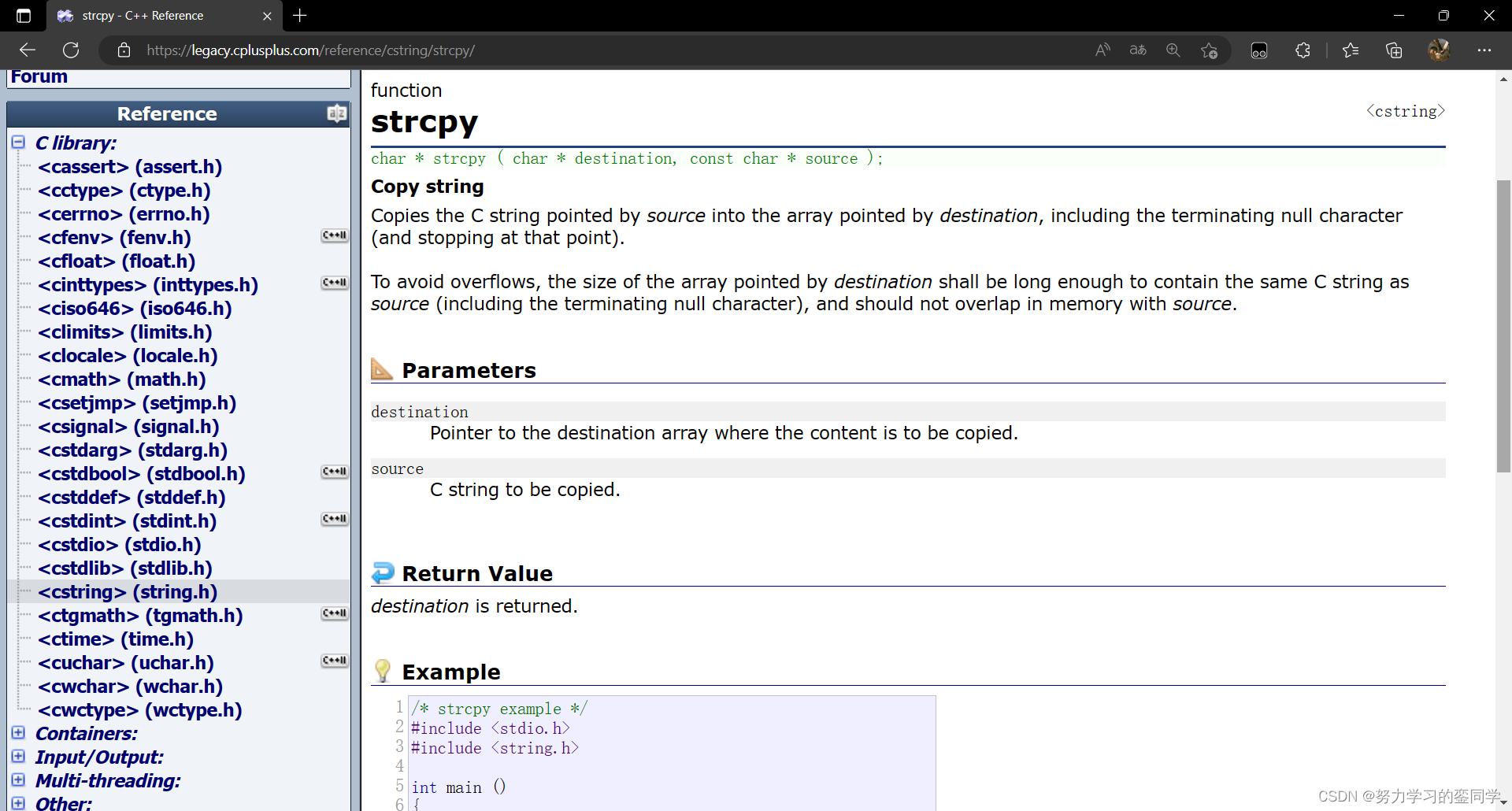
strcpy 函数(string copy)的作用是,可以将字符串从源地址复制至目的地址,通俗来讲就是用来实现字符串的复制和拷贝。并且它会将源地址内的结束标识符 ' \0 ' 一并拷贝过去,因此源地址必须以 ' \0 ' 结尾,且目的地址也将以结束标识符结尾。并且,因为其作用为拷贝字符串,因此目标地址内的空间必须足够大,要有足够的空间容纳下源地址内的字符串,同时目的地址的空间必须是可变、可修改的。
我们来看 strcpy 函数的基本使用方式:
#include<stdio.h>
#include<string.h>
int main()
{
const char arr1[] = "Hellow!";
const char arr2[10] = { 0 };
printf("Before copy , the char inside arr1 are %s\n", arr1);
printf("Before copy , the char inside arr2 are %s\n", arr2);
printf("\n");
strcpy(arr2, arr1);
//strcpy函数使用格式为:strcpy(目的地址, 源地址);
printf("After copy , the char inside arr1 are %s\n", arr1);
printf("After copy , the char inside arr2 are %s\n", arr2);
return 0;
}我们初始化字符数组 arr 中的内容,并使 arr2 中内容为空。首先我们将两个字符串进行打印,验证拷贝前两字符串中的存储内容。接着我们使用 strcpy 函数将字符数组 arr1 中的字符串拷贝至 arr2 中,并在此打印两数组中的内容对拷贝结果进行验证。
我们要特别注意的是 strcpy 函数返回的是目标空间的起始地址,该函数设置返回值值类型的目的是为了实现链式访问(以后会讲到,这里仅做了解)。
这个字符串处理函数就比较陌生了,在我们之前的学习中没有用到过,甚至不曾见过,我们现在就来一起学习它。
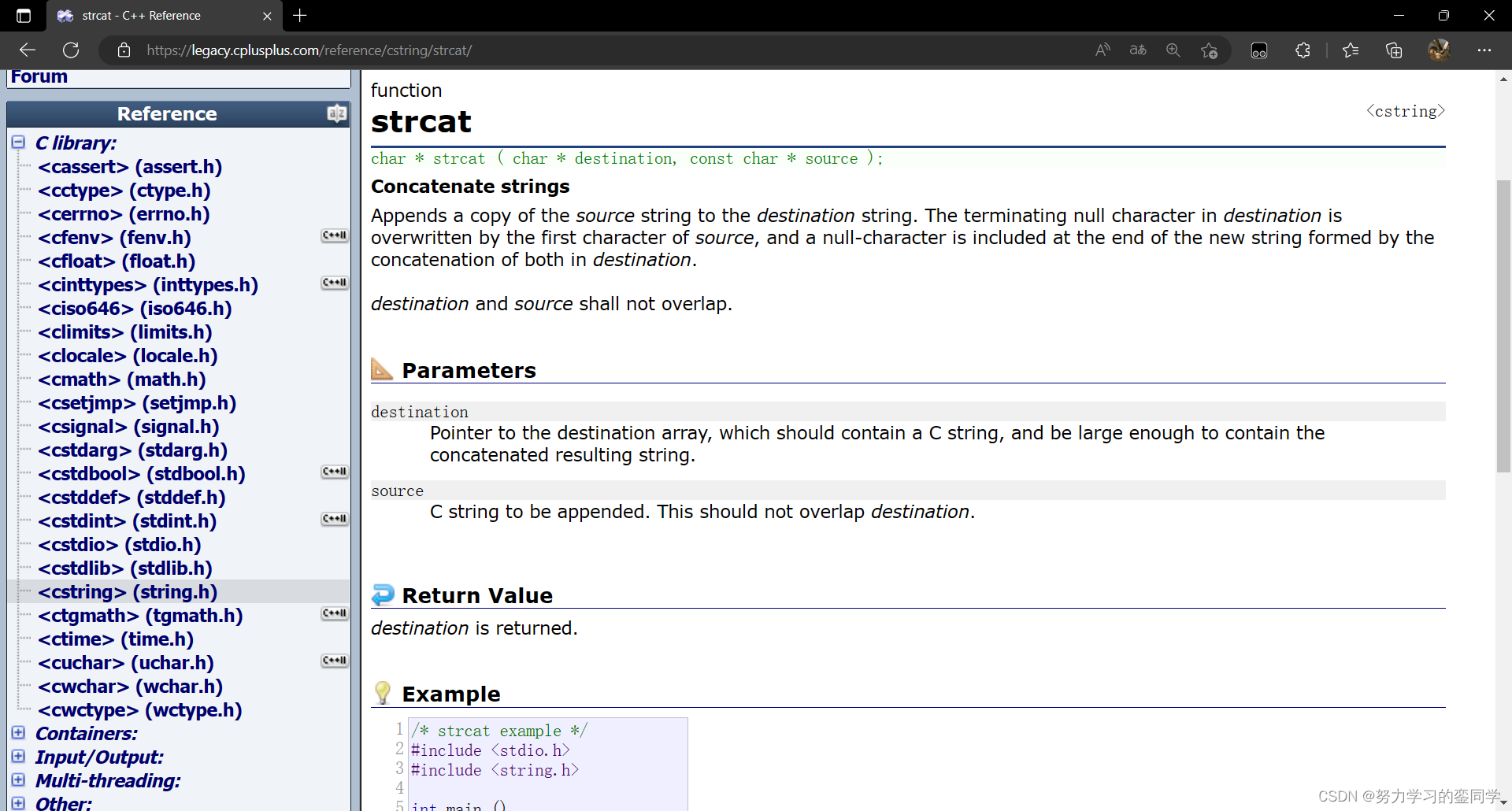
strcat 函数(string catenate)的作用是,将源地址的字符串追加补充至目的地址处。与字符串拷贝函数相同,它在进行补充追加时是从目的地址的结束标识符处 ' \0 ' 开始追加的,追加至源地址的结束标识符处停止。且它同样要求目标地址内的空间必须足够大,要有足够的空间容纳下源地址内的字符串,同时目的地址的空间必须是可变、可修改的。
我们来看 strcat 函数的基本使用方式:
#include<stdio.h>
#include<string.h>
int main()
{
const char arr1[20] = "Hellow!";
const char arr2[20] = "Welcome!";
printf("Before catenate , the char inside arr1 are %s\n", arr1);
printf("Before catenate , the char inside arr2 are %s\n", arr2);
printf("\n");
strcat(arr2, arr1);
printf("After catenate , the char inside arr1 are %s\n", arr1);
printf("After catenate , the char inside arr2 are %s\n", arr2);
return 0;
}我们同样首先定义并初始化两个字符数组,接着打印他们验证他们各自内部的存储内容。然后通过使用stract 函数,我们将字符数组 arr21中的内容,成功的追加补充到了字符数组 arr1 中,并再次进行了打印,验证追加补充的结果。
注意,strcat 函数无法追加自己。原因很好理解,我们在定义时就已经固定了字符数组的储存空间了,当追加自己时,相当于将自己与和与自己相同大小的字符数组,即两倍自身大小的数据放入自己的储存空间中,可想而知一定是不可行的。
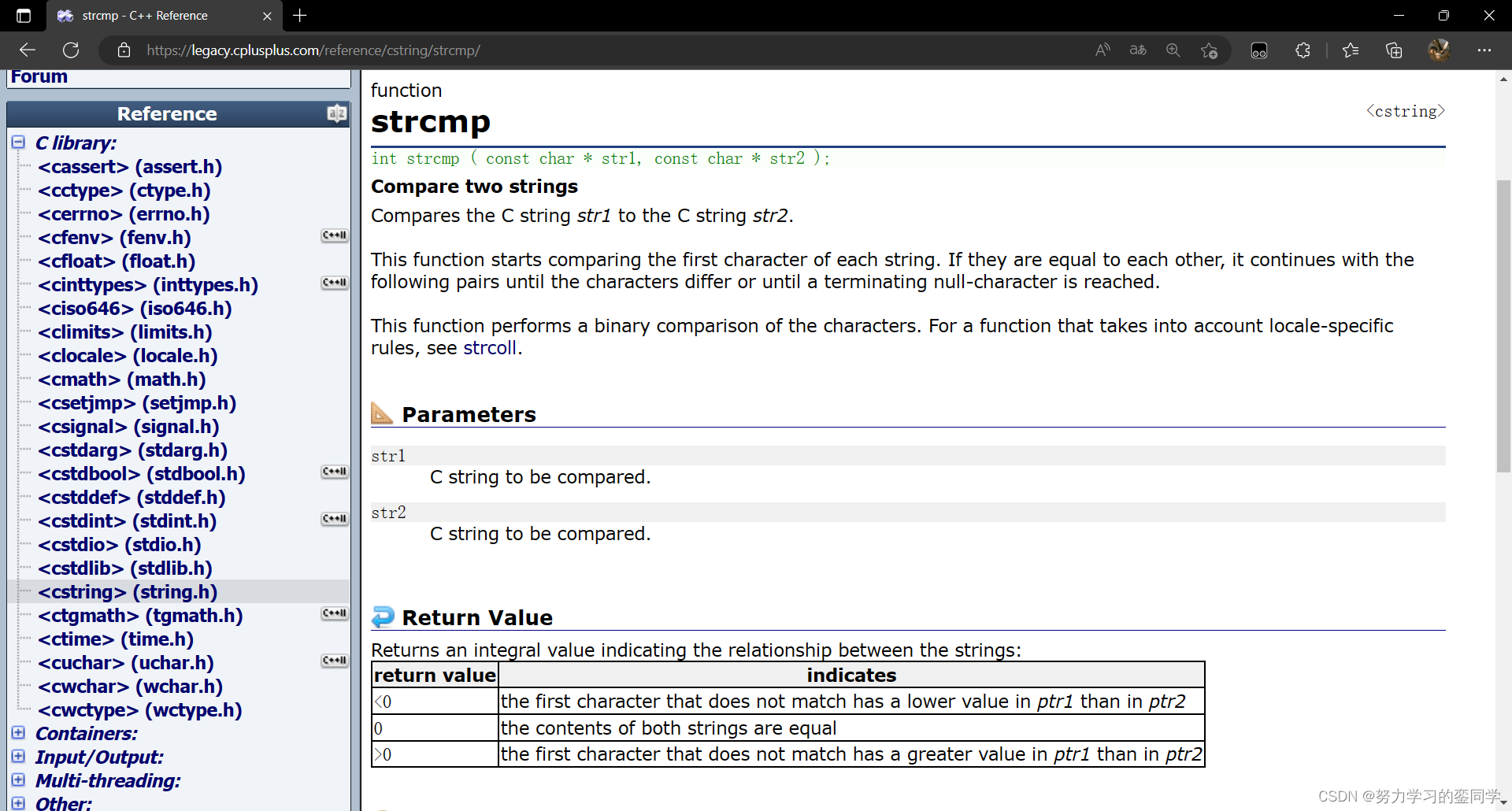
strcmp 函数(string compare)的作用为按照顺序依次比较两字符串对应位置字符的 ASCII 码值(注意不是比较两字符串的长度),直到结束标识符 ' \0 ' 或对应位置的字符不同。若比较至结束标识符都没有不同则两字符串相等,若两字符串对应位置字符有不同,对应位置上字符 ASCII 码值小的字符串小于另一个字符串。
我们来看 strcmp 函数的基本使用方式:
#include<stdio.h>
#include<string.h>
int main()
{
const char arr1[] = "abcd";
const char arr2[] = "abz";
int ret = strcmp(arr1, arr2);
//若arr1大于arr2,则返回大于零的数
//若arr1等于arr2,则返回等于零的数
//若arr1小于arr2,则返回小于零的数
if (ret > 0)
{
printf("arr1 > arr2\n");
}
else if (ret = 0)
{
printf("arr1 = arr2\n");
}
else
{
printf("arr1 < arr2\n");
}
return 0;
}首先我们定义并初始化两个字符数组,接着对两个数组进行比较,根据 strcmp 函数的比较结果得到返回值,再根据返回值反馈我们想要的字符串比较结果。
这里的要点是,该函数的作用并不是比较字符串的长短,而是比较对应位置字符 ASCII 码值的大小。
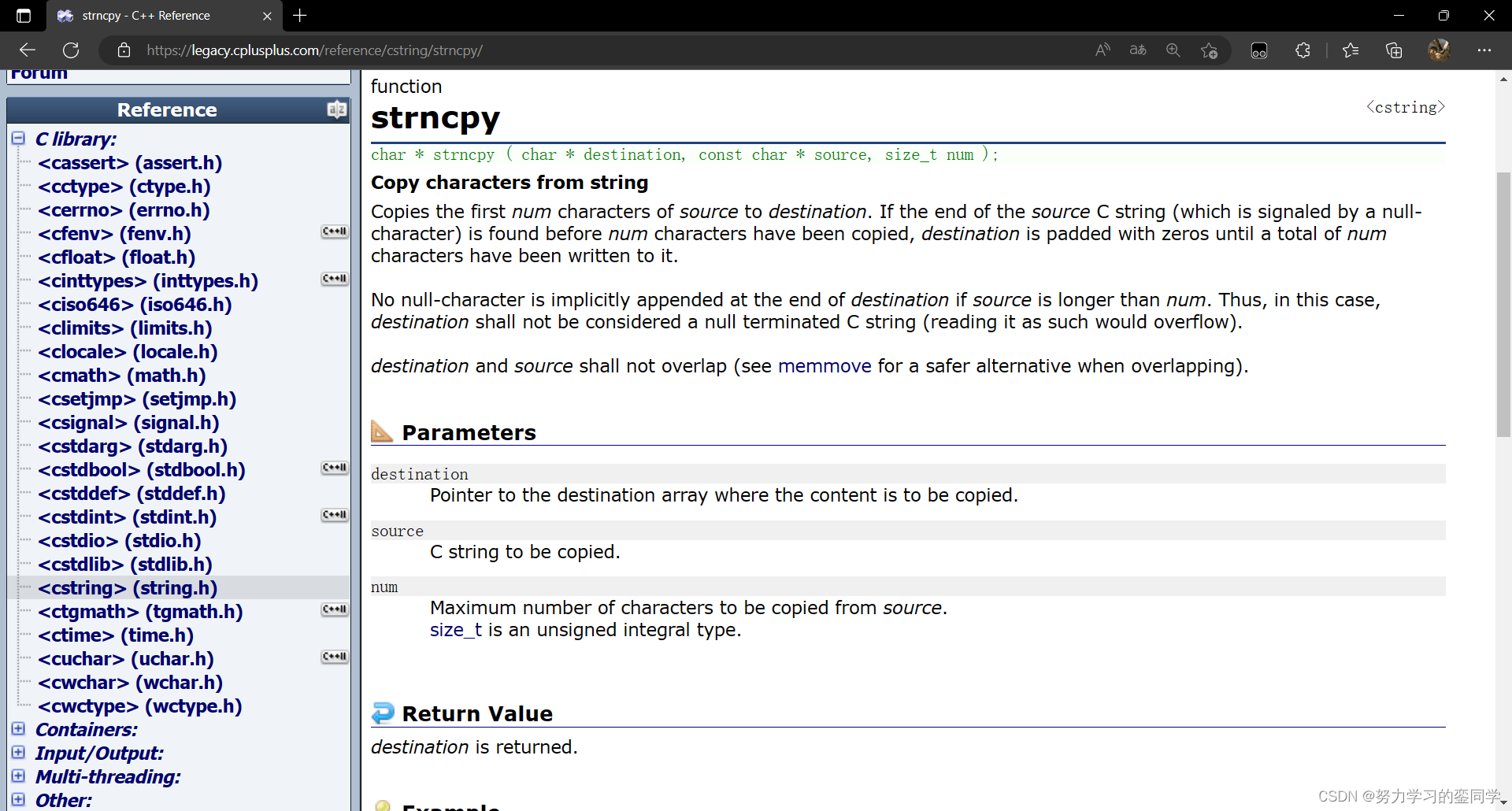
strncpy函数(string number copy)的作用为将指定长度的字符串复制到字符数组中,即表示把源地址中字符串开始的前n个字符拷贝到目的地址中。与 strcpy 相同,它同样会将源地址内的结束标识符 ' \0 ' 一并拷贝过去,因此源地址必须以 ' \0 ' 结尾,且目的地址也将以结束标识符结尾。并且,因为其作用为拷贝字符串,因此目标地址内的空间必须足够大,要有足够的空间容纳下源地址内的字符串,同时目的地址的空间必须是可变、可修改的。
我们来看 strncpy 函数的基本使用方式:
#include<stdio.h>
#include<string.h>
//strncpy函数的使用:
int main()
{
const char arr1[] = "Hellow!Welcome!";
const char arr2[10] = { 0 };
printf("Before copy , the char inside arr1 are %s\n", arr1);
printf("Before copy , the char inside arr2 are %s\n", arr2);
strncpy(arr2, arr1, 7);
printf("After catenate , the char inside arr1 are %s\n", arr1);
printf("After catenate , the char inside arr2 are %s\n", arr2);
return 0;
}我们看到,使用该函数,我们成功的将字符数组 arr1 中的前七个字符拷贝到了 字符数组 arr2 中,并且通过前后两次的反馈打印验证了按指定长度拷贝操作成功完成。
注意:若源字符串的长度小于我们传递过去的参数,则拷贝完源字符串之后,将会在目标后追加字符 ' 0 ',直到拷贝至参数规定个数。
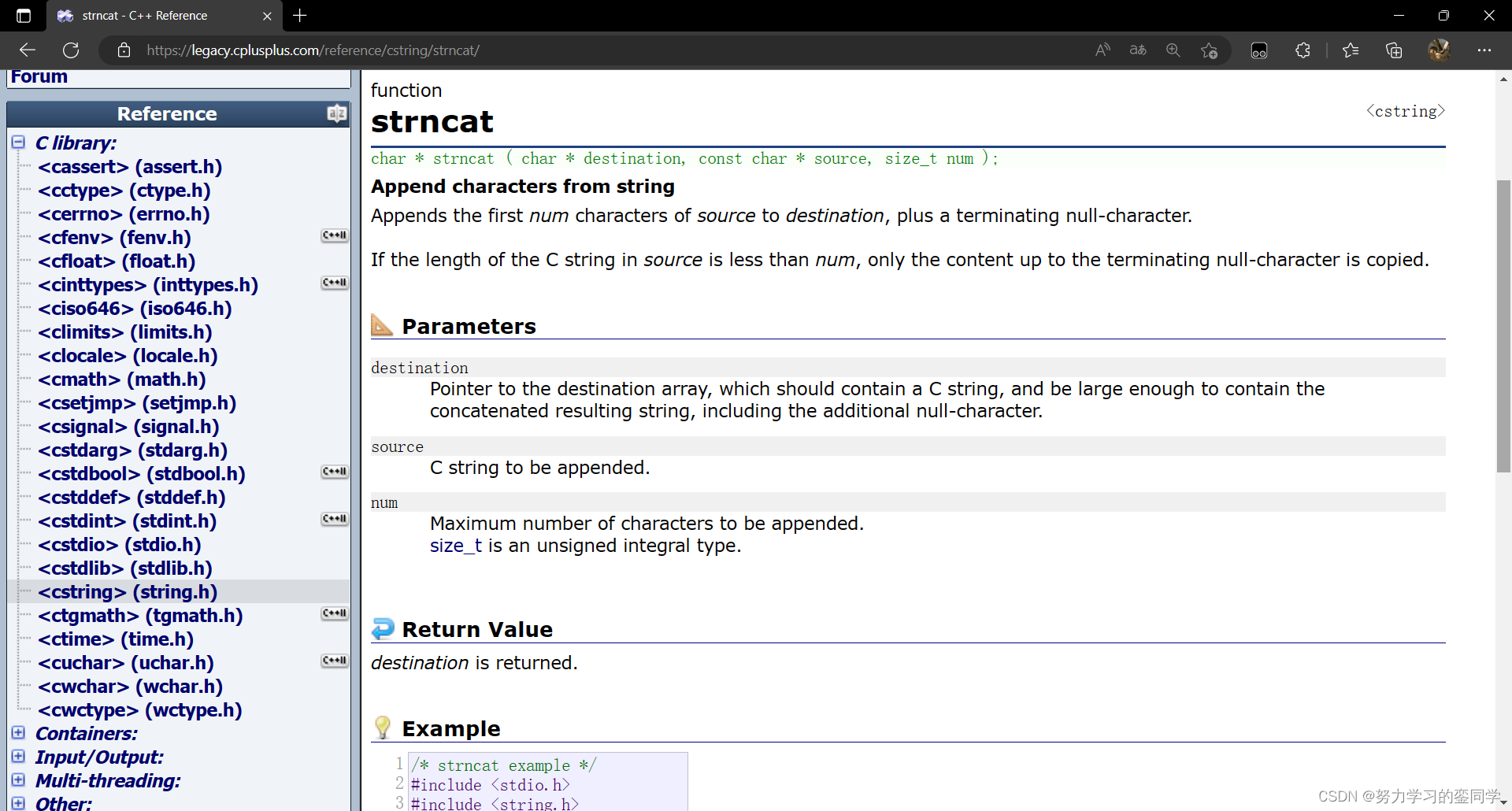
strncat 函数(string num catenate)的作用为从源地址处将指定长度的字符串追加补充到目的地址中。与 strcat 函数类似,它在进行补充追加时也是从目的地址的结束标识符处 ' \0 ' 开始追加的,不同的是追加至参数限制的字符数处停止。但它同样要求目标地址内的空间必须足够大,要有足够的空间容纳下出家补充的字符串,同时目的地址的空间必须是可变、可修改的。
我们来看 strncat 函数的基本使用方式:
#include<stdio.h>
#include<string.h>
int main()
{
const char arr1[] = "Hellow!Welcome!";
const char arr2[20] = "Welcome!";
printf("Before copy , the char inside arr1 are %s\n", arr1);
printf("Before copy , the char inside arr2 are %s\n", arr2);
strncat(arr2, arr1, 7);
printf("After catenate , the char inside arr1 are %s\n", arr1);
printf("After catenate , the char inside arr2 are %s\n", arr2);
return 0;
}我们可以看到,首先定义并初始化两个字符数组,接着打印追加补充之前它们各自空间内的内容进行确认,然后我们使用了 strncat 函数有限制的从数组 arr1 向 arr2 中追加补充了七个字符,最后进行了打印反馈,验证了我们的有限制追加补充结果。
并且我们可以想到,通过限制长度我们就可以实现字符数组对自己的追加补充了。
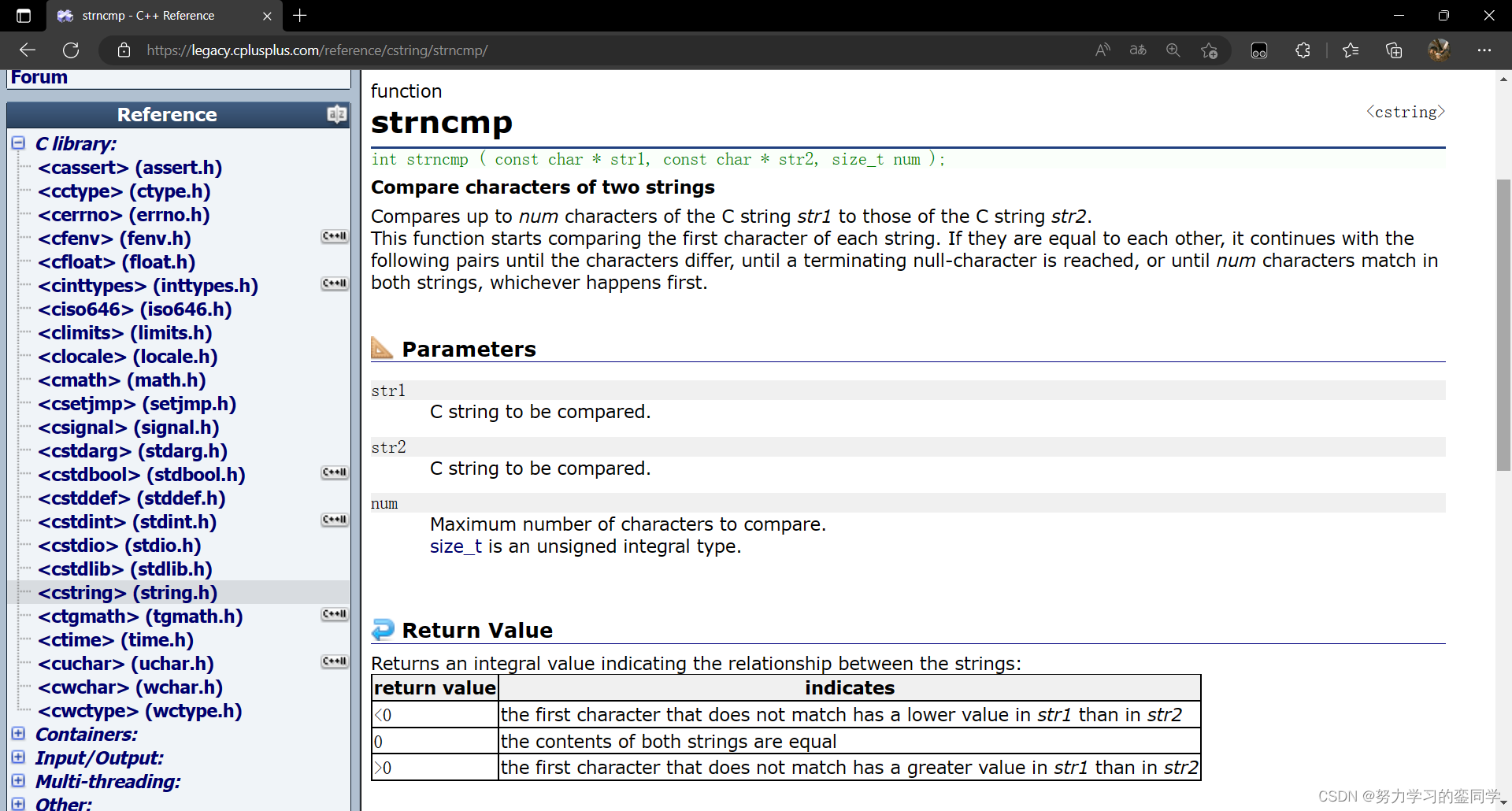
strncmp 函数(string number compare)的作用为有限制的按照顺序依次比较两字符串对应位置字符的 ASCII 码值(注意不是比较两字符串的长度),直到参数限制位数位置上全部比较结束或对应位置的字符不同。若参数限制位数位置上的字符都比较结束且都没有不同则两字符串相等,若两字符串对应位置字符有不同,对应位置上字符 ASCII 码值小的字符串小于另一个字符串。
我们来看 strncmp 函数的基本使用方式:
#include<stdio.h>
#include<string.h>
int main()
{
const char arr1[] = "abcd";
const char arr2[] = "abz";
int ret = strncmp(arr1, arr2, 3);
//比较前 3 个字符
//若arr1大于arr2,则返回大于零的数
//若arr1等于arr2,则返回等于零的数
//若arr1小于arr2,则返回小于零的数
if (ret > 0)
{
printf("arr1 > arr2\n");
}
else if (ret = 0)
{
printf("arr1 = arr2\n");
}
else
{
printf("arr1 < arr2\n");
}
return 0;
}其作用原理与作用过程,与 strncmp 函数十分类似,唯一不同便是限制了字符比较的位数,所以在此不再做过多的阐述,可以参考 strncmp 函数进行理解。
但是同样要注意是,该函数的作用也不是比较字符串的长短,而是比较对应位置字符 ASCII 码值的大小。
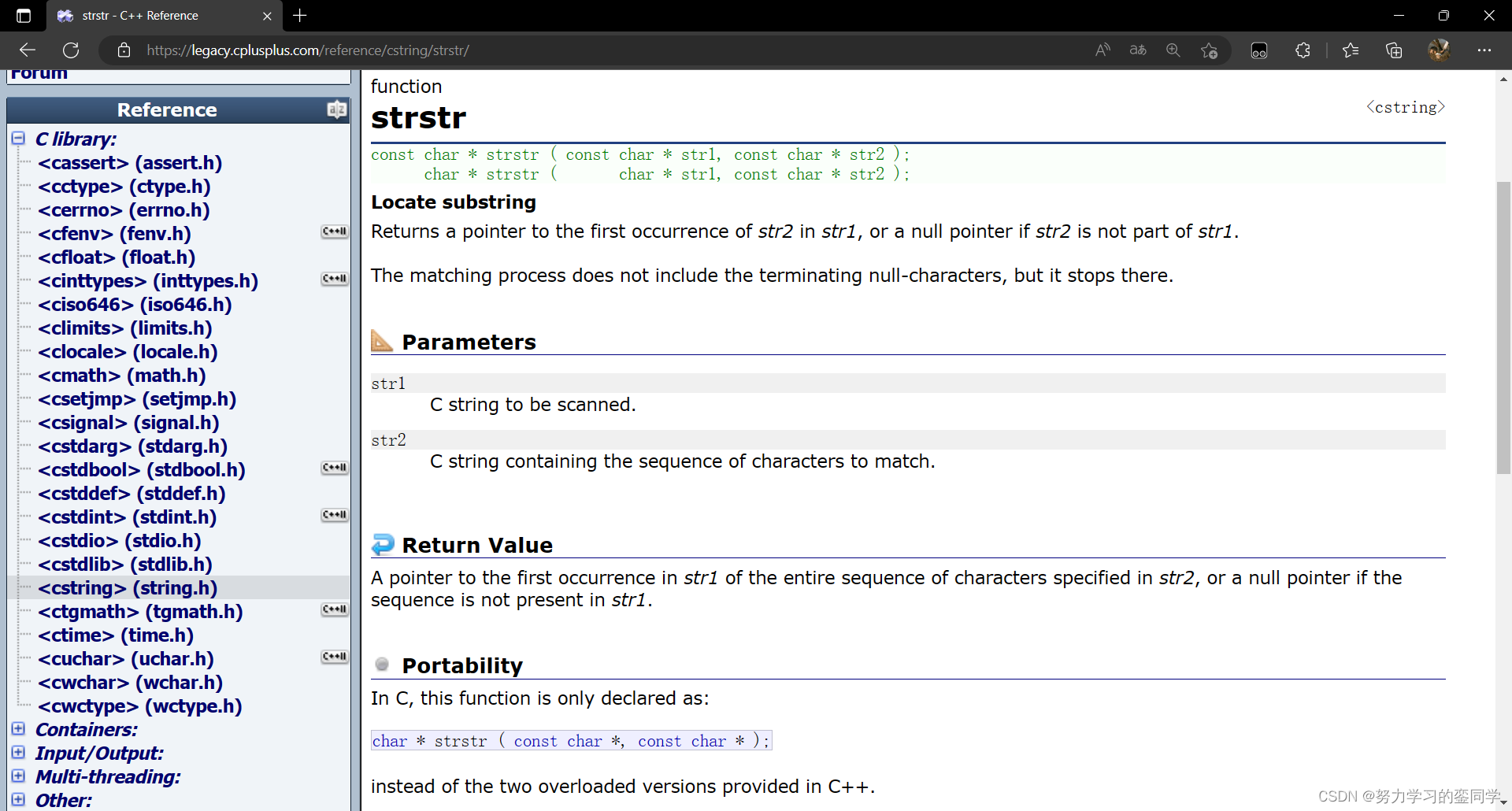
strstr 函数(string string)的作用为从一个字符串中寻找其字串,通俗来讲就是从一个字符串中寻找另一个字符串。若找到目标字串则返回指向目标字串的指针,若没有找到目标字串则返回空指针(不返回)。
我们来看 strstr 函数的基本使用方式:
#include<stdio.h>
#include<string.h>
int main()
{
const char arr1[] = "abcdefg";
const char arr2[] = "cde";
char* ret = strstr(arr1, arr2);
//从ar1中寻找arr2
if (ret == NULL)
{
printf("找不到该字符串!\n");
}
else
{
printf("成功找到该字符串'%s'!\n", ret);
}
return 0;
}我们定义并初始化了两个字符数组,并使用 strstr 函数进行字串寻找处理,并使用字符型指针接收汉函数的返回值,最后,对接收了返回值的指针 ret 进行判断,若为空则确定为没有从数组 arr1 中找到字串 arr2,否则便通过返回值,使用指针对字串地址内的数据进行访问。
该函数数有返回值,支持进行函数的链式访问。

strtok 函数(string token)的作用为将字符串分解为一组字符串。听起来似乎很难理解,其实很简单。该函数有两个数组作为参数,它的实际作用便是将其中一个数组组为分割数组,在另一个数组中寻找这些“分割符”,并在分割符处将这个数组内的字符串加上结束标识符 ' \0 ' ,将其分割成一组(多个)字符串。若第一个参数不为 NULL ,将找到字符数组中的第一个标记并保存它在字符串中的位置;若第一个参数为 NULL ,将在同一个字符串中被保存的位置开始,查找下一个标 记。
我们来看 strtok 函数的基本使用方式:
#include<stdio.h>
#include<string.h>
int main()
{
char arr1[] = "1254594572@QQ.COM";
char arr2[30] = { 0 };
strcpy(arr2, arr1);
const char* arr3 = "@.";
printf("账号:%s\n", strtok(arr2, arr3));
//找到第一个标记停止
printf("服务商:%s\n", strtok(NULL, arr3));
//从保存好的位置开始往后找
printf("网址后缀:%s\n", strtok(NULL, arr3));
//从保存好的位置开始往后找
return 0;
}首先我们要知道,strtok 函数是会对数组本身进行操作的,所以我们为了保护原始数据,在定义并初始化好字符数组之后,又定义了一个新的数组并将原始数据拷贝过去,作为临时拷贝供我们进行操作。接着我们定义并初始化了分割符数组,函数将根据分割符数组 arr3 对 临时拷贝 arr2 进行分割。第一次执行函数时之前没有标记,于是直接进行操作找到第一个标记并分割打印。此时就已经存在标记了,再连续两次找到前一次执行作下的标记按照分割符将数组分割完毕并打印。
但是上面的代码风格较为简陋、复杂,我们可以将上面段代码优化为:
#include<stdio.h>
#include<string.h>
int main()
{
char arr1[] = "1254594572@QQ.COM";
char arr2[30] = { 0 };
strcpy(arr2, arr1);
const char* arr3 = "@.";
char* str = NULL;
for (str = strtok(arr2, arr3); str != NULL; str = strtok(NULL, arr3))
{
printf("%s\n", str);
}
return 0;
}注意,若字符串中不存在更多的标记,则返回 NULL 指针。
strerror函数(string error)的作用为返回错误码对应的信息。即根据接收到的错误码(错误码 errno 为全局变量),返回错误原因的详细信息。
我们来看 strerror 函数的基本使用方式:
#include<stdio.h>
#include<string.h>
int main()
{
int i = 0;
for (i = 0; i <= 4; i++)
{
printf("错误原因为:%s\n", strerror(i));
}
return 0;
}
memcpy函数(memory copy)的作用为从源内存空间向目的内存空间拷贝限制数量(单位是字节)的数据。它与 strcpy 函数类似,作用均为拷贝数据,不同的是 strcpy 仅仅只操作字符串故会在结束标识符 ' \0 ' 处停止,而 memcpy 函数操作的是内存,内存中的数据是相邻的,故不会在结束标识符处停止。
我们来看 memcpy 函数的基本使用方式:
#include<stdio.h>
#include<string.h>
int main()
{
int arr1[10] = { 1,2,3,4,5,6,7,8,9 };
int arr2[5] = { 0 };
printf("Before copy , the char inside arr2 are :>");
int i = 0;
for (i = 0; i < 5; i++)
{
printf(" %d", arr2[i]);
}
printf("\n");
memcpy(arr2, arr1, 20);
printf("After copy , the char inside arr2 are :>");
for (i = 0; i < 5; i++)
{
printf(" %d", arr2[i]);
}
printf("\n");
return 0;
}我们首先创建并初始化了两个整形数组,接着打印出数组 arr2 内数据的存放情况。紧接着我们通过内存拷贝函数,将数组 arr1 内的前20个字节的数据拷贝给了 arr2数组。整型数组内每个数据元素所占的内存空间为4个字节,20个字节即将数组 arr1 中的前五个数据元素拷贝给了数组 arr2。最后再次打印数组 arr2 中的数据,验证拷贝结果。
在这里各位小伙伴们要注意了,如果源内存空间和目标内存空间有任何的重叠,复制的结果都是未定义的。
memmove函数(memory move)的作用为弥补 memcpy 函数的不足,主要用于处理内存的重叠部分。即如果源空间和目标空间出现重叠,就得使用 memmove 函数来进行处理。
我们来看 memcpy 函数的基本使用方式:
#include<stdio.h>
#include<string.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9 };
printf("Before copy , the char inside arr are :>");
int i = 0;
for (i = 0; i < 5; i++)
{
printf(" %d", arr[i]);
}
printf("\n");
memmove(arr+2, arr, 20);
printf("After copy , the char inside arr are :>");
for (i = 0; i < 5; i++)
{
printf(" %d", arr[i]);
}
printf("\n");
return 0;
}这个函数与 memcpy 函数除处理对象不同外,语法结构和使用场景等都极其类似,这里也就不再做过多赘述。
memcmp 函数(memory compare)的作用与 strcmp 函数的作用类似,不过 memcmp 函数是从内存的角度以字节为单位进行处理,故 memcmp 函数同样需要第三个参数进行限制,而不会在结束标识符 ' \0 ' 处停止比较。其它方面也就不再做过多赘述。
我们来看 memcmp 函数的基本使用方式:
#include<stdio.h>
#include<string.h>
int main()
{
int arr1[] = { 1,2,3,4,5,6,7,8,9 };
int arr2[] = { 1,2,3,4,5,9,6,7,8 };
int ret = memcmp(arr2, arr1, 24);
if (ret > 0)
{
printf("arr1 < arr2\n");
}
else if (ret == 0)
{
printf("arr1 = arr2\n");
}
else
{
printf("arr1 > arr2");
}
return 0;
}这个函数比较简单,也没有什么需要特别注意的地方,故不再做赘述。
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<assert.h>
size_t my_strlen(const char* p)
{
int count = 0;
assert(p != NULL);
//进行空指针校验,防止出现空指针
while (*p != '\0')
{
count++;
p++;
}
return count;
}
int main()
{
const char arr[] = "Welcome!";
int ret = my_strlen(arr);
printf("The length of arr is %d\n", ret);
return 0;
}#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<assert.h>
char* my_strcpy(char* p2, const char* p1)
{
assert(p2 != NULL);
assert(p1 != NULL);
//等价于assert(p2 && p1);
char* ret = p2;
//将目的地址作为返回值
while (*p2++ = *p1++)
{
;
}
//返回目的地址的作用是为了实现链式访问
return ret;
}
int main()
{
const char arr1[] = "Welcome!";
const char arr2[10] = { 0 };
printf("Before copy , the char inside arr1 are %s\n", arr1);
printf("Before copy , the char inside arr2 are %s\n", arr2);
printf("\n");
my_strcpy(arr2, arr1);
printf("After copy , the char inside arr1 are %s\n", arr1);
printf("After copy , the char inside arr2 are %s\n", arr2);
return 0;
}#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<assert.h>
char* my_strcat(char* p2, char* p1)
{
assert(p2 && p1);
char* ret = p2;
//查找目标空间中的结束标识符,找到后停止
while (*p2)
{
p2++;
}
//从结束标识符开始追加
//追加:
while (*p2++ = *p1++)
{
;
}
return ret;
}
int main()
{
const char arr1[20] = "Hellow!";
const char arr2[20] = "Welcome!";
printf("Before catenate , the char inside arr1 are %s\n", arr1);
printf("Before catenate , the char inside arr2 are %s\n", arr2);
printf("\n");
my_strcat(arr2, arr1);
printf("After catenate , the char inside arr1 are %s\n", arr1);
printf("After catenate , the char inside arr2 are %s\n", arr2);
return 0;
}#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<assert.h>
//模拟实现strcmp函数:
int my_strcmp(const char* p1, const char* p2)
{
assert(p1 && p2);
//找到字符不同的对应位:
while (*p1 == *p2)
{
if (*p1 == '\0')
{
return 0;
}
p1++;
p2++;
}
if (*p1 > *p2)
{
return 1;
}
else
{
return -1;
}
}
int main()
{
const char arr1[] = "abcd";
const char arr2[] = "abz";
int ret = my_strcmp(arr1, arr2);
//若arr1大于arr2,则返回大于零的数
//若arr1等于arr2,则返回等于零的数
//若arr1小于arr2,则返回小于零的数
if (ret = 1)
{
printf("arr1 > arr2\n");
}
else if (ret = 0)
{
printf("arr1 = arr2\n");
}
else
{
printf("arr1 < arr2\n");
}
return 0;
}#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<assert.h>
char* my_strstr(char* p1, char* p2)
{
assert(p1 && p2);
char* pp1 = p1;
char* pp2 = p2;
char* cur = p1;
while (*cur)
{
pp1 = cur;
pp2 = p2;
while (*pp1 && *pp2 && (*pp1 == *pp2))
{
pp1++;
pp2++;
}
if (*pp2 == '\0')
{
return cur;
}
cur++;
}
return NULL;
}
//模拟strstr函数的实现:
int main()
{
const char arr1[] = "abcdefg";
const char arr2[] = "cde";
char* ret = my_strstr(arr1, arr2);
//从ar1中寻找arr2
if (ret == NULL)
{
printf("找不到该字符串!\n");
}
else
{
printf("成功找到该字符串'%s'!\n", ret);
}
return 0;
}#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<assert.h>
void* my_memcpy(void* p2, const void* p1, size_t count)
{
assert(p2 && p1);
void* ret = p2;
while (count--)
{
*(char*)p2 = *(char*)p1;
p2 = (char*)p2 + 1;
p1 = (char*)p1 + 1;
}
return ret;
}
int main()
{
int arr1[10] = { 1,2,3,4,5,6,7,8,9 };
int arr2[5] = { 0 };
printf("Before copy , the char inside arr2 are :>");
int i = 0;
for (i = 0; i < 5; i++)
{
printf(" %d", arr2[i]);
}
printf("\n");
my_memcpy(arr2, arr1, 20);
printf("After copy , the char inside arr2 are :>");
for (i = 0; i < 5; i++)
{
printf(" %d", arr2[i]);
}
printf("\n");
return 0;
}#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<assert.h>
void* my_memmove(void* p2, const void* p1, size_t count)
{
assert(p2 && p1);
void* ret = p2;
if (p2 < p1)
{
while (count--)
{
*(char*)p2 = *(char*)p1;
p2 = (char*)p2 + 1;
p1 = (char*)p1 + 1;
}
}
else
{
while (count--)
{
*((char*)p2 + count) = *((char*)p1 + count);
}
}
return ret;
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9 };
printf("Before copy , the char inside arr are :>");
int i = 0;
for (i = 0; i < 5; i++)
{
printf(" %d", arr[i]);
}
printf("\n");
my_memmove(arr + 2, arr, 20);
printf("After copy , the char inside arr are :>");
for (i = 0; i < 5; i++)
{
printf(" %d", arr[i]);
}
printf("\n");
return 0;
}今日爆肝十小时,一万三千余字💦💦,呕心沥血为大家整理并讲解了所有常用字符串操作函数,以及其中部分库函数的自定义模拟实现,希望对大家的学习有所帮助。各位小伙伴们课下也不要过于放松喔,勤加练习才能造就我们夯实的基础和精进的编程技术💯💯。感谢大家的阅读,我们下节课再见叭🍸🍸
🔥🔥在真实的生命里,每桩伟业都由信心开始,并由信心跨出第一步🔥🔥
更新不易,辛苦各位小伙伴们动动小手,👍三连走一走💕💕 ~ ~ ~ 你们的点赞和关注对我真的很重要!最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
在我的Rails(2.3,Ruby1.8.7)应用程序中,我需要将字符串截断到一定长度。该字符串是unicode,在控制台中运行测试时,例如'א'.length,我意识到返回了双倍长度。我想要一个与编码无关的长度,以便对unicode字符串或latin1编码字符串进行相同的截断。我已经了解了Ruby的大部分unicode资料,但仍然有些一头雾水。应该如何解决这个问题? 最佳答案 Rails有一个返回多字节字符的mb_chars方法。试试unicode_string.mb_chars.slice(0,50)
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack