鲁棒是Robust的音译,也就是健壮和强壮的意思。它也是在异常和危险情况下系统生存的能力。比如说,计算机软件在输入错误、磁盘故障、网络过载或有意攻击情况下,能否不死机、不崩溃,就是该软件的鲁棒性。所谓“鲁棒性”,也是指控制系统在一定(结构,大小)的参数摄动下,维持其它某些性能的特性。根据对性能的不同定义,可分为稳定鲁棒性和性能鲁棒性。以闭环系统的鲁棒性作为目标设计得到的固定控制器称为鲁棒控制器。
鲁棒性包括稳定鲁棒性和品质鲁棒性。一个控制系统是否具有鲁棒性,是它能否真正实际应用的关键。因此,现代控制系统的设计已将鲁棒性作为一种最重要的设计指标。
AI模型的鲁棒可以理解为模型对数据变化的容忍度。假设数据出现较小偏差,只对模型输出产生较小的影响,则称模型是鲁棒的。 Huber从稳健统计的角度给出了鲁棒性的3个要求:
- 模型具有较高的精度或有效性。
- 对于模型假设出现的较小偏差(noise),只能对算法性能产生较小的影响。
- 对于模型假设出现的较大偏差(outlier),不能对算法性能产生“灾难性”的影响。

鲁棒性即稳健性,外延和内涵不一样;稳定性只做本身特性的描述。鲁棒性指一个具体的控制器,如果对一个模型族中的每个对象都能保证反馈系统内稳定,那么就称其为鲁棒稳定的。稳定性指的是系统在某个稳定状态下受到较小的扰动后仍能回到原状态或另一个稳定状态。
鲁棒性是控制论中的词语,主要指在某些参数略微改变或控制量稍微偏离最优值时系统仍然保持稳定性和有效性。泛化能力指根据有限样本得到的网络模型对其他变量域也有良好的预测能力。根据泛化能力好的网络设计的神经网络控制器的鲁棒性也会有所改善。鲁棒性指自己主动去改变网络中的相关参数,细微地修改(破坏)模型,也能得到理想的效果;而泛化能力是指,在不主动修改(破坏)模型的前提下,被动接受不同的外界输入,都能得到相应的理想的效果。
为了提升模型的鲁棒性, 现在主流的研究大致分为三个方向:
1、修改模型输入数据, 包括在训练阶段修改训练数据以及在测试阶段修改输入的样本数据。
2、修改网络结构, 比如添加更多的网络层数,改变损失函数或激活函数等方法。
3、添加外部模块作为原有网络模型的附加插件, 提升网络模型的鲁棒性。
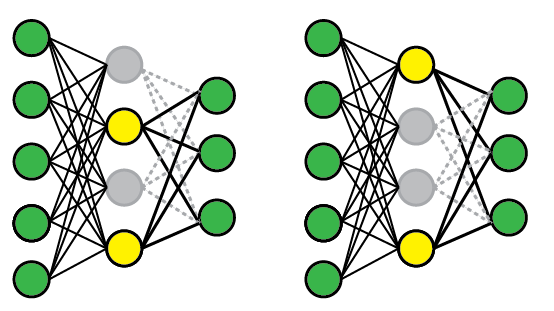
解决的问题:co-adaptation(在神经网络中,隐藏层单元之间有很高的相关性)。Dropout可以看作一个噪声 [公式] 和全连接矩阵 [公式] 作乘积,随机导致一部分连接权重为0。Dropout能够有效缓解神经元之间的co-adaptation(之前一起发挥作用的神经元现在可能单独出现了)。训练时,每次dropout都会得到一个新的子网络。预测时,所有的神经元都会发生作用,可以看作多个子网络的平均。因此dropout类似于bagging和 [公式] 正则,不同之处在于dropout的多个子网络之间共享参数,同时神经元是被随机丢弃的。
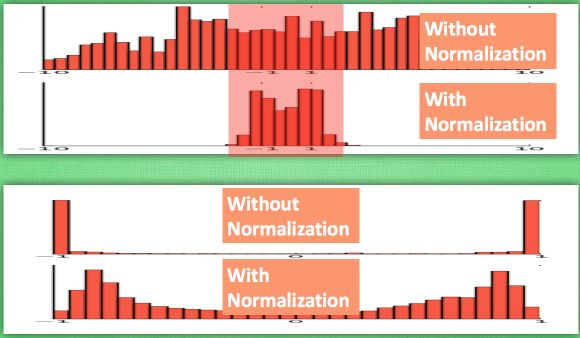
Normalization将激活层的输入标准化,使得标准化后的输入能够落在激活函数的非饱和区。
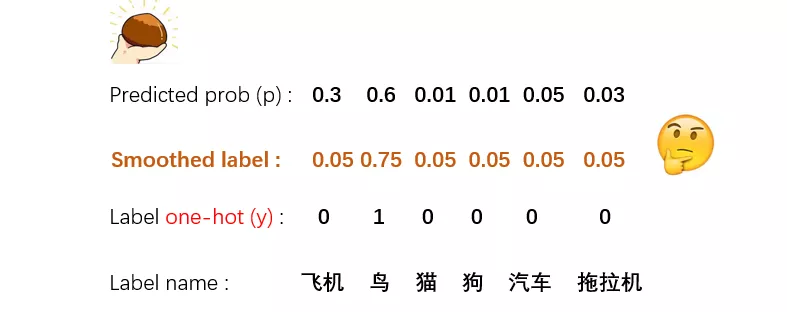
label smoothing就是把原来的one-hot表示,在每一维上都添加了一个随机噪音。这是一种简单粗暴,但又十分有效的方法,目前已经使用在很多的图像分类模型中了。
Label Smoothing 优势:
1、一定程度上,可以缓解模型过于武断的问题,也有一定的抗噪能力
弥补了简单分类中监督信号不足(信息熵比较少)的问题,增加了信息量;
2、提供了训练数据中类别之间的关系(数据增强);
3、可能增强了模型泛化能力
4、降低feature norm (feature normalization)从而让每个类别的样本聚拢的效果(文章[10]提及)
5、产生更好的校准网络,从而更好地泛化,最终对不可见的生产数据产生更准确的预测。(文章[11]提及)
Label Smoothing 劣势:
1、单纯地添加随机噪音,也无法反映标签之间的关系,因此对模型的提升有限,甚至有欠拟合的风险。
2、它对构建将来作为教师的网络没有用处,hard 目标训练将产生一个更好的教师神经网络。(文章[11]提及)
mixup是一种非常规的数据增强方法,一个和数据无关的简单数据增强原则,其以线性插值的方式来构建新的训练样本和标签。最终对标签的处理如下公式所示,这很简单但对于增强策略来说又很不一般。
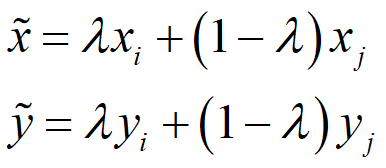
( x i , y i ) \left ( x_{i},y_{i} \right ) (xi,yi), ( x j , y j ) \left ( x_{j},y_{j} \right ) (xj,yj)两个数据对是原始数据集中的训练样本对(训练样本和其对应的标签)。其中 λ \lambda λ是一个服从B分布的参数, λ ∼ B e t a ( α , α ) \lambda\sim Beta\left ( \alpha ,\alpha \right ) λ∼Beta(α,α) 。Beta分布的概率密度函数如下图所示,其中 α ∈ [ 0 , + ∞ ] \alpha \in \left [ 0,+\infty \right ] α∈[0,+∞]
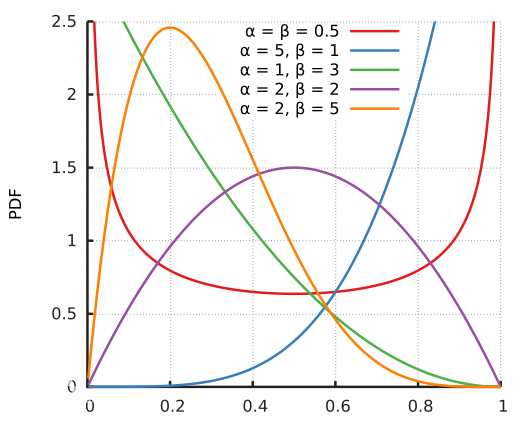
因此 α \alpha α是一个超参数,随着 α \alpha α的增大,网络的训练误差就会增加,而其泛化能力会随之增强。而当 α → ∞ \alpha \rightarrow \infty α→∞时,模型就会退化成最原始的训练策略。参考:https://www.jianshu.com/p/d22fcd86f36d
Focal loss 主要是为了解决目标检测中正负样本比例严重失衡的问题,并不是通常的正则化化方法。该损失函数降低了大量简单样本在训练中所占的权重,让模型更加关注困难、错分的样本。
上面的几种方式,是我常用的几种方法,更多的可以参考:
https://zhuanlan.zhihu.com/p/434106564
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何