Flink SQL 批模式下 ClickHouse 批量写入
内置使用
JdbcBatchingOutputFormat批量处理类
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.3.1-patch</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>${hutool.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
public class ClickHouseDynamicTableFactory implements DynamicTableSinkFactory {
public static final String IDENTIFIER = "clickhouse";
private static final String DRIVER_NAME = "ru.yandex.clickhouse.ClickHouseDriver";
public static final ConfigOption<String> URL = ConfigOptions
.key("url")
.stringType()
.noDefaultValue()
.withDescription("the jdbc database url.");
public static final ConfigOption<String> TABLE_NAME = ConfigOptions
.key("table-name")
.stringType()
.noDefaultValue()
.withDescription("the jdbc table name.");
public static final ConfigOption<String> USERNAME = ConfigOptions
.key("username")
.stringType()
.noDefaultValue()
.withDescription("the jdbc user name.");
public static final ConfigOption<String> PASSWORD = ConfigOptions
.key("password")
.stringType()
.noDefaultValue()
.withDescription("the jdbc password.");
public static final ConfigOption<String> FORMAT = ConfigOptions
.key("format")
.stringType()
.noDefaultValue()
.withDescription("the format.");
@Override
public String factoryIdentifier() {
return IDENTIFIER;
}
@Override
public Set<ConfigOption<?>> requiredOptions() {
Set<ConfigOption<?>> requiredOptions = new HashSet<>();
requiredOptions.add(TABLE_NAME);
requiredOptions.add(URL);
return requiredOptions;
}
@Override
public Set<ConfigOption<?>> optionalOptions() {
return new HashSet<>();
}
@Override
public DynamicTableSink createDynamicTableSink(Context context) {
// either implement your custom validation logic here ...
final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
final ReadableConfig config = helper.getOptions();
// validate all options
helper.validate();
// get the validated options
JdbcOptions jdbcOptions = getJdbcOptions(config);
// derive the produced data type (excluding computed columns) from the catalog table
final DataType dataType = context.getCatalogTable().getResolvedSchema().toPhysicalRowDataType();
// table sink
return new ClickHouseDynamicTableSink(jdbcOptions, dataType);
}
private JdbcOptions getJdbcOptions(ReadableConfig readableConfig) {
final String url = readableConfig.get(URL);
final JdbcOptions.Builder builder = JdbcOptions.builder()
.setDriverName(DRIVER_NAME)
.setDBUrl(url)
.setTableName(readableConfig.get(TABLE_NAME))
.setDialect(new ClickHouseDialect());
readableConfig.getOptional(USERNAME).ifPresent(builder::setUsername);
readableConfig.getOptional(PASSWORD).ifPresent(builder::setPassword);
return builder.build();
}
}
public class ClickHouseDialect implements JdbcDialect {
private static final long serialVersionUID = 1L;
@Override
public String dialectName() {
return "ClickHouse";
}
@Override
public boolean canHandle(String url) {
return url.startsWith("jdbc:clickhouse:");
}
@Override
public JdbcRowConverter getRowConverter(RowType rowType) {
return new ClickHouseRowConverter(rowType);
}
@Override
public String getLimitClause(long l) {
return "limit num : " + l;
}
@Override
public Optional<String> defaultDriverName() {
return Optional.of(ClickHouseDriver.class.getName());
}
@Override
public String quoteIdentifier(String identifier) {
return "`" + identifier + "`";
}
}
public class ClickHouseDynamicTableSink implements DynamicTableSink {
private final JdbcOptions jdbcOptions;
private final DataType dataType;
private static final JdbcExecutionOptions DEFAULT_EXECUTION_OPTIONS = JdbcExecutionOptions.builder()
// 写入触发数据量阈值
.withBatchSize(2000)
// 写入触发时间阈值
.withBatchIntervalMs(1000)
// 重试次数
.withMaxRetries(3)
.build();
public ClickHouseDynamicTableSink(JdbcOptions jdbcOptions, DataType dataType) {
this.jdbcOptions = jdbcOptions;
this.dataType = dataType;
}
@Override
public ChangelogMode getChangelogMode(ChangelogMode requestedMode) {
return requestedMode;
}
@SneakyThrows
@Override
public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
ClickHouseTableEnum tableEnum = ClickHouseTableEnum.valueOf(jdbcOptions.getTableName());
TableService tableService = new TableServiceImpl(dataType, tableEnum);
return SinkFunctionProvider.of(new GenericJdbcSinkFunction<>(
new JdbcBatchingOutputFormat<>(
new SimpleJdbcConnectionProvider(jdbcOptions),
DEFAULT_EXECUTION_OPTIONS,
thisContext -> JdbcBatchStatementExecutor.simple(
tableService.getInsertSql(),
tableService.getStatementBuilder(),
Function.identity()),
// 批模式下,数据对象重复利用,会发生覆盖问题,需要深拷贝对象
new RowDataConventFunction())));
}
@Override
public DynamicTableSink copy() {
return new ClickHouseDynamicTableSink(jdbcOptions, dataType);
}
@Override
public String asSummaryString() {
return "ClickHouse Table Sink";
}
@Slf4j
static class RowDataConventFunction implements JdbcBatchingOutputFormat.RecordExtractor<RowData, RowData>, Serializable {
@Override
public RowData apply(RowData rowData) {
BoxedWrapperRowData newRowData = null;
try {
newRowData = new BoxedWrapperRowData(rowData.getArity());
// 利用反射拷贝旧对象的值
Field field = ReflectUtil.getField(BoxedWrapperRowData.class, "fields");
Object[] fields = (Object[]) ReflectUtil.getFieldValue(rowData, field);
Object[] newFields = new Object[fields.length];
for (int i = 0; i < fields.length; i++) {
newFields[i] = Objects.isNull(fields[i]) ? null : ReflectUtil.invoke(fields[i], "copy");
}
ReflectUtil.setFieldValue(newRowData, "fields", newFields);
} catch (Exception e) {
log.error("convert error,data:{},", rowData, e);
}
return newRowData;
}
}
}
public class ClickHouseRowConverter extends AbstractJdbcRowConverter {
private static final long serialVersionUID = 1L;
public ClickHouseRowConverter(RowType rowType) {
super(rowType);
}
@Override
public String converterName() {
return "ClickHouse";
}
}
支持序列化的BiFunction
@FunctionalInterface
public interface MyBiFunction<T, U, R> extends Serializable {
R apply(T t, U u);
}
public class TableServiceImpl {
private final List<LogicalType> logicalTypeList;
private final String insertSql;
public TableServiceImpl(DataType dataType, ClickHouseTableEnum tableEnum) {
this.logicalTypeList = dataType.getLogicalType().getChildren();
this.insertSql = initInsertSql(tableEnum);
}
private static final Map<Class<? extends LogicalType>, MyBiFunction<RowData, Integer, Object>> FUNCTION_MAP = Maps.newHashMap();
static {
// 我的业务中用到的类型,可根据自己的业务,进行增加
FUNCTION_MAP.put(IntType.class, RowData::getInt);
FUNCTION_MAP.put(VarCharType.class, RowData::getString);
FUNCTION_MAP.put(DoubleType.class, RowData::getDouble);
FUNCTION_MAP.put(BigIntType.class, RowData::getLong);
FUNCTION_MAP.put(CharType.class, RowData::getString);
}
public String getInsertSql() {
return insertSql;
}
public JdbcStatementBuilder<RowData> getStatementBuilder() {
return (statement, value) -> {
for (int i = 0; i < logicalTypeList.size(); i++) {
LogicalType logicalType = logicalTypeList.get(i);
Object realValue = FUNCTION_MAP.get(logicalType.getClass()).apply(value, i);
statement.setObject(i + 1, realValue);
}
};
}
// 根据枚举字段配置,生成 insert sql
public static String initInsertSql(ClickHouseTableEnum tableEnum) {
List<String> columns = tableEnum.getColumns().stream().map(ClickHouseTableEnum.ColumnObj::getColumnName).collect(Collectors.toList());
return String.format("insert into %s (%s) values (%s)"
, tableEnum.name()
, StrUtil.join(",", columns)
, StrUtil.repeatAndJoin("?", columns.size(), ","));
}
public static void main(String[] args) {
System.out.println(initInsertSql(ClickHouseTableEnum.attr_order_group));
}
}
@Getter
public enum ClickHouseTableEnum {
/**
* 测试表,因为业务需要,我定义的 ColumnObj 类,实际用个字符串就ok
*/
test(Lists.newArrayList(
ColumnObj.of("name")
, ColumnObj.of("age")
)),
;
private final List<ColumnObj> columns;
ClickHouseTableEnum(List<ColumnObj> columns) {
this.columns = columns;
}
@Getter
@Setter
@ToString
public static class ColumnObj {
/**
* clickHouse 中字段名称
*/
private String columnName;
/**
* flink sql 中获取字段的key
*/
private String sqlColumnKey;
/**
* 两个值相同的情况,使用此构造函数
*/
private ColumnObj(String columnName) {
this.columnName = columnName;
this.sqlColumnKey = columnName;
}
}
}
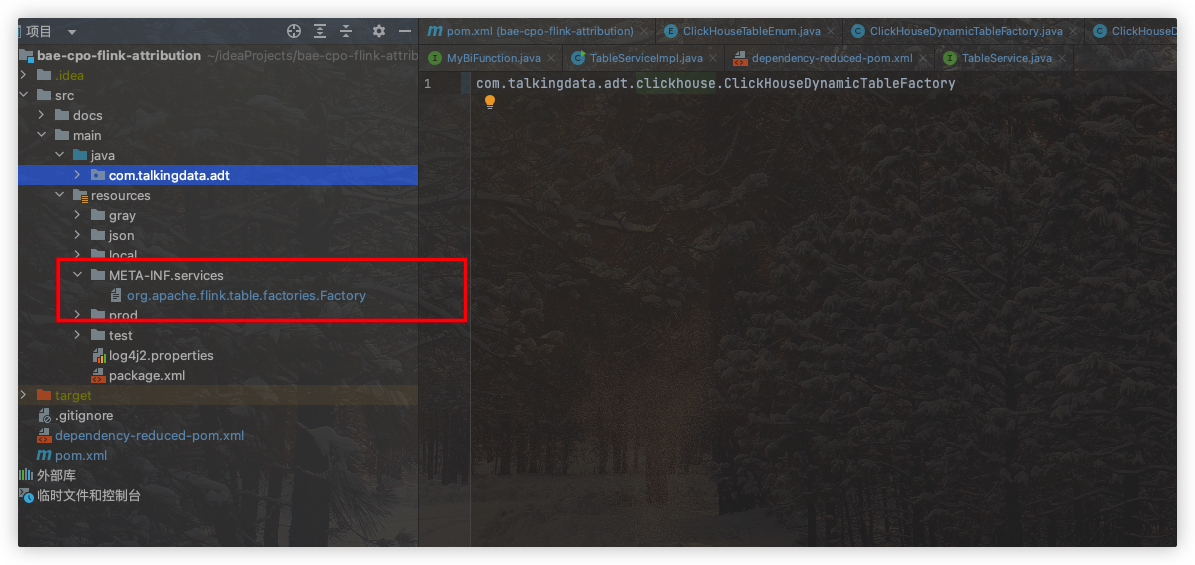
resources目录下,创建META-INF/services目录创建文件:
org.apache.flink.table.factories.Factory
内容如下:指向自己的工厂类全路径
com.xxx.xxx.xxx.ClickHouseDynamicTableFactory
public class Test {
public static void main(String[] args) {
// 初始化 批模式环境
EnvironmentSettings settings = EnvironmentSettings.newInstance().inBatchMode().build();
Configuration configuration = settings.toConfiguration();
configuration.set(CoreOptions.DEFAULT_PARALLELISM, 5);
TableEnvironment tableEnv = TableEnvironment.create(configuration);
// 创建 clickHouse 输出表
// 注意,WITH 后面的参数,table-name 需要跟 clickHouseTable 枚举类中对应上
tableEnv.executeSql("CREATE TABLE out_table_test (\n" +
" `name` STRING,\n" +
" `age` INT\n" +
") WITH (\n" +
" 'connector' = 'clickhouse',\n" +
" 'url' = 'jdbc:clickhouse://172.23.4.32:8123/test',\n" +
" 'table-name' = 'test'\n" +
")");
Table table = tableEnv.sqlQuery("select 'alice',18 ");
table.executeInsert("out_table_test");
// 打印日志
printLog(tableEnv, table, "test");
}
private static void printLog(TableEnvironment tableEnv, Table endTable, String outTableName) {
String outPrint = "consolePrint_" + outTableName;
tableEnv.executeSql("CREATE TABLE " + outPrint + " " + endTable.getResolvedSchema() + " WITH (\n" +
" 'connector' = 'print'\n" +
")");
endTable.executeInsert(outPrint);
Table countTable = tableEnv.sqlQuery("select count(*) from " + endTable);
tableEnv.executeSql("CREATE TABLE " + outPrint + "_count " + countTable.getResolvedSchema() + " WITH (\n" +
" 'connector' = 'print'\n" +
")");
countTable.executeInsert(outPrint + "_count");
}
}
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我想知道Ruby用来在命令行打印这些东西的输出流:irb(main):001:0>a="test"=>"test"irb(main):002:0>putsatest=>nilirb(main):003:0>a=>"test"$stdout是否用于irb(main):002:0>和irb(main):003:0>?而且,在这两次调用之间,$stdout的值是否有任何变化?另外,有人能告诉我打印/写入这些内容的Ruby源代码吗? 最佳答案 是的。而且很容易向自己测试/证明。在命令行试试这个:ruby-e'puts"foo"'>test.
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl
我正在编写一个ruby程序,它应该执行另一个程序,通过stdin向它传递值,从它的stdout读取响应,然后打印响应。这是我目前所拥有的。#!/usr/bin/envrubyrequire'open3'stdin,stdout,stderr=Open3.popen3('./MyProgram')stdin.puts"helloworld!"output=stdout.readerrors=stderr.readstdin.closestdout.closestderr.closeputs"Output:"puts"-------"putsoutputputs"\nErrors:"p
我正在处理http://prepwork.appacademy.io/mini-curriculum/array/中概述的数组问题我正在尝试创建函数my_transpose,它接受一个矩阵并返回其转置。我对写入二维数组感到很困惑!这是一个代码片段,突出了我的困惑。rows=[[0,1,2],[3,4,5],[6,7,8]]columns=Array.new(3,Array.new(3))putscolumns.to_s#Outputisa3x3arrayfilledwithnilcolumns[0][0]=0putscolumns.to_s#Outputis[[0,nil,nil],[
我经常迷上ruby的一件事是递归模式。例如,假设我有一个数组,它可能包含无限深度的数组作为元素。所以,例如:my_array=[1,[2,3,[4,5,[6,7]]]]我想创建一个方法,可以将数组展平为[1,2,3,4,5,6,7]。我知道.flatten可以完成这项工作,但这个问题是作为我经常遇到的递归问题的一个例子-因此我试图找到一个更可重用的解决方案。简而言之-我猜这种事情有一个标准模式,但我想不出任何特别优雅的东西。任何想法表示赞赏 最佳答案 递归是一种方法,它不依赖于语言。您在编写算法时要考虑两种情况:再次调用函数的情